基于BERT-RCNN的中文违规评论识别研究
2022-03-09潘善亮
吴 浩,潘善亮
(宁波大学 信息科学与工程学院,浙江 宁波 315211)
0 引言
随着移动互联网的普及,人们已经可以随时随地在互联网上进行广泛的社交活动,网上发言的便利性和匿名性让人们更容易在网络上宣泄情绪和攻击他人[1]。面对舆论影响较大的新闻,一部分人可能会跟随舆论趋势进行不理性的发言[2],甚至群起攻击某个特定用户,形成网络暴力。2018年一位女医生因维护自身权益而与未成年人发生纠纷,而后不堪网络暴力自杀。近年来,越来越多的新闻披露了网络暴力对社会和个人产生的严重危害。
违规评论表现为损害正常交流环境、触犯法律法规及对社会风气产生不良影响的恶性网络留言,包括人身攻击、歧视行为和色情信息等。如何有效识别违规评论是当前阻止网络暴力发生的研究热点,传统识别方法非常依赖词库的涵盖范围及敏感词的准确性,在无法及时更新词库时,识别违规评论的召回率将会不断下降。同时随着小众网络流行文化的兴起,各类词汇被赋予新的含义,一些常规词在特定语境下也会成为攻击、侮辱他人的手段,传统方法无法很好地结合语境识别出此类新的违规词。
本文根据留言内容识别违规评论,首先将文本信息向量化,再利用自己提出的文本分类模型来提取特征并进行分类工作,主要工作包括建立了一个中文违规评论数据集,提出了基于BERT和RCNN的检测中文违规评论的模型RBR(Recognition Model of Illegal Comments Based on BERT-RCNN),并对该模型与当前公认效果最佳的检测模型效果做了对比分析,验证了本文模型的有效性。
1 相关工作
传统违规评论检测模型检测的目标大多为低俗词语,可以分为跟踪用户行为和文本内容识别两大类。前者多采用算法统计用户一段时间内恶意发言频率及影响程度,如Kumar等[3]根据历史信用将用户分类后再对其言论进行检测,Kim等[4]通过追踪用户重复性转发等操作寻找潜在恶意言论;后者根据文本信息特征推断恶意评论,而不事先预设用户类别,如Hardaker等[5]通过分析不同恶意评论特征来判定进行,Cambria等[6]利用情感倾向来分析恶意行为。
实际上,普通用户在某些特定情况下也会发布一些恶意违规评论[7]。因此如何根据文本内容识别其是否违规,是目前研究的一个重点。文本内容识别主要包括文字编码和文本分类两部分工作。
针对文本内容的文字编码,早期多采用one-hot编码,但这种方式会丢失词序且忽略上下文语境承接关系,当字典过大时还会存在维度过高的问题。Mikolov等[8]提出了Word2Vec模型结构,该模型可以考虑上下文词序关系且在训练后可以实现词向量相似度计算。江承柱[9]通过Word2Vec做词嵌入,构建基于层次神经网络和多元特征的检测模型,取得了超过传统模型的分类效果。这种词嵌入方法虽然以词序的形式考虑了上下文关系,但仍无法对词与词之间的语义关系进行关联。Vaswani等[10]提出的Transformer模型采用自注意力机制在句子中建立了每个字词之间的联系,根据这种联系该模型可以学习到语义级别上的信息。与Word2Vec相比,其可以保留更多文本的潜在信息。Devlin等[11]提出了BERT模型,该模型在Transformer的基础上利用大规模未标记文本进行了预训练,其词嵌入包含了更多文本信息。BERT模型将文本转化为向量后,可使词义相近或关系接近的词向量在空间上相距较近,词义相反的词向量也会呈对称分布。Zhu等[12]采用BERT微调的方法检测推特上仇恨言论,利用原始BERT将句子拆分成单词单元,再将这些按照顺序进行词嵌入操作。
针对常用文本分类模型的研究,包括将词向量输入双向RNN中的TextRNN[13]、通过改进softmax计算方式快速进行文本多分类的FastText[14]和通过不同窗口大小捕捉文本上下文信息的TextCNN[15]等,可以借鉴到违规评论识别领域。在违规评论检测模型方面,因为需要依赖包含敏感词的词汇表[16],分类的性能受到词汇表内容广泛度的制约,对于不包含明显恶意词汇的攻击言论,通常无法有效识别。而针对一些不包含明显粗俗用语或恶意讥讽、歧视新型网络暴力用词,如“暴毙而亡”“赶紧糊”“你全家死了”。利用种子字建立字典就无法覆盖这些网络用语[17-18],对不包含明显粗俗用语的恶意评论的检测难度就更大[19]。
2 模型设计
本文构造了一个基于BERT的中文违规评论识别模型,基本框架如图1所示,主要构成为词向量转化模块和深层文本特征提取分类模块。
词向量转化模块是一个基于BERT的中文预训练模型,将文本转化为词向量并进行初步特征处理;深层文本特征提取分类模块利用RCNN网络对上下文深层特征进行提取,同时采用多任务学习方式,引入一个文本情感分类任务作为辅助模型,与违规评论分类模型联合训练,提升本文模型精度及泛化能力。加入标签平滑技术抑制在样本数量较少且可能存在标注错误时发生的过拟合现象,最后得到分类结果。
为了能够识别不包含明显低俗词语的违规评论,本文采用在语义关联上提取特征,通过预训练模型中各类词向量在空间中相对位置来判别其语义相似度。将易引发歧义的词汇结合不同语境共同训练,使模型可根据语境判断其是否违规。
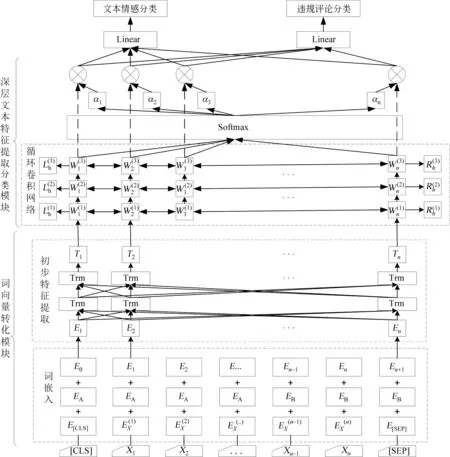
图1 RBR模型算法框架
2.1 词向量转化模块
在本模块中,先将文本信息转化为词向量E,再将其作为输入向量输入到由自注意力机制和前馈神经网络组成的Transformer结构当中,进行初步特征提取。
BERT预训练模型在大量语料上的预训练可以使其在文本与词向量转化时将语义相近的字或词转化为在特征向量空间中距离相近的一维词向量,可以保留更多有效信息及情感倾向,利于后续任务区分违规评论。中文语系存在分词不当造成句子产生歧义的可能,然而在BERT模型中字级别的词嵌入方式则可在一定程度上降低该问题对模型性能产生的负面影响。
通常情况下,带有负面情绪的词语与句子中人称代词关联程度的大小在很大程度上决定了该语句的恶意程度,例如,“坟都给你挖好了,怎么还不进去”。该例句中并无明显低俗词,但其中“坟”字带有较强的负面情感倾向,与人称代词“你”的关系很密切,达到了恶意中伤的效果。因此,将转化后的词向量输入到Transformer结构中,计算两者之间的关系密切程度,有利于判断该句是否违规,其过程如下:
(1) 将上述例句中“坟”等字进行词嵌入,如图2所示。

图2 BERT初步特征提取
在图2中,Input为中文文本内容,Token Embeddings为字向量,Segment Embeddings为段向量,Position Embeddings为位置向量,三组向量组合为词向量E。
(2) 将得到的词向量E作为输入量,通过一个包含了多层多个Transformer特征提取器可以提取到特征信息T1,T2,…,Tn,如图3所示。

图3 BERT预训练模型结构[11]
其中,Transformer的内部结构由自注意力机制、标准化和前馈神经网络组成,如图4所示。
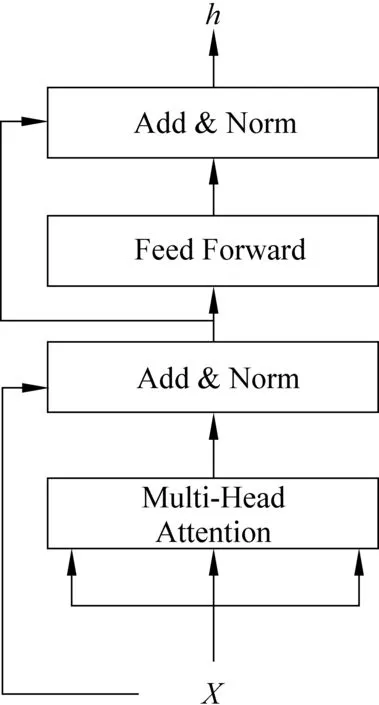
图4 Transformer结构[10]
在自注意力机制处理过程中会生成初始随机矩阵X,词向量与X矩阵相乘后生成三个新的向量Query、Key和Value,如Q1,K1,V1,多个词向量所对应的Q、K和V向量组成矩阵WQ、WK和WV。利用矩阵W可以简化计算过程。以“坟”和“你”字为例,如图5所示。

图5 生成关系向量
每个输入的字向量的Query都要和其他的字向量的Key做计算,同时两个字向量均拥有一个初始Value。Query与Key的运算结果会生成一个权重、并将两个字之间对应关系的分值融合到初始Value中,进而保存上下文语义信息。例如,得到“坟”与“你”的关系,需将Q坟与K你点积,得到分数S,如式(1)所示。
S=Q·K
(1)
以此类推可以得到一组分数S={S1,S2,…,Sn},它们表示文本中“坟”字与其他字两两之间关系密切程度。将该组分数除以一个常数后进行softmax运算,再乘以V,可以得到包含了字之间关系的特征T,常数通常取初始随机矩阵维数的算数平方根,如式(2)所示。
(2)
其中,dk为初始随机矩阵维数,V为Value向量,T为输出向量。输出向量中即包含了当前字与其他字之间关联程度的隐含特征,在后续训练过程中可以利用该特征辅助判别违规评论。
上述计算仅为计算一个字和其他字的关系,同时进行多个上述计算从而计算出每个字之间两两关系。这部分计算对于违规评论识别十分重要,在使用大量违规文本训练后,可以有效提升模型对不包含低俗词语的恶意评论识别能力。
2.2 深层文本特征提取分类模块
文本分类任务的关键在于特征包含的信息,Bert模型可以更好地处理上下文联系和语义信息等,从而提取到更有效的特征。但模型性能仍有提高的空间,在利用BERT提取文本特征后结合其他神经网络模型进一步提升整体分类精度。
递归卷积神经网络RCNN(Recurrent Convolutional Neural Networks)[20]结合了RNN与CNN的优点,具备更加出色的性能。同时该网络摆脱了RNN网络训练速度慢、无法保留长期记忆等问题,也弥补了CNN处理文本时窗口大小固定的不足,其结构如图6所示。
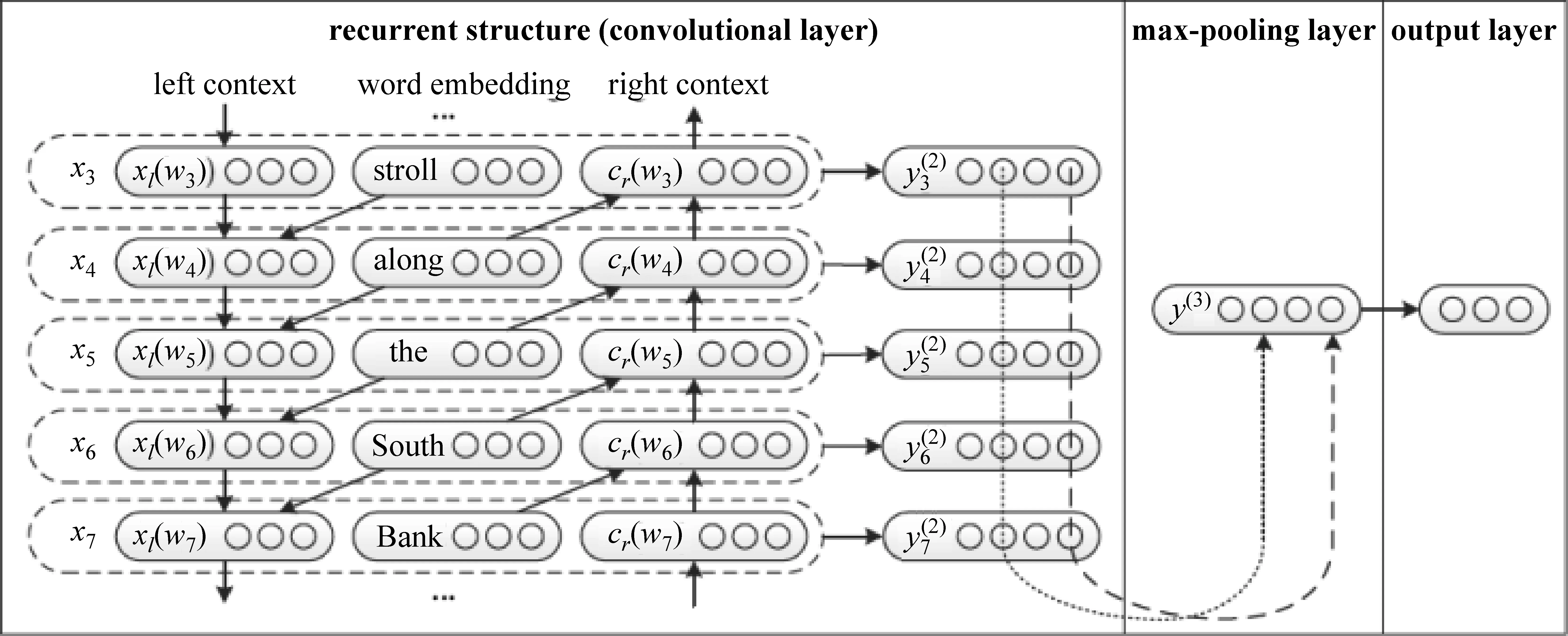
图6 RCNN结构图[20]
RCNN的前半部分是由双向循环神经网络组成的卷积层,其结构可以利用LSTM在两个方向上的循环来模拟上下文的位置关系,如式(3)、式(4)所示。
cl(wi)=f(w(l)cl(wi-1)+w(sl)e(wi-1))
(3)
cr(wi)=f(w(r)cr(wi+1)+w(sr)e(wi+1))
(4)
其中,cl(wi)和cr(wi)分别代表目标字左右的上下文,cl(wi-1)与cr(wi+1)分别表示目标字左侧上下文的前文和右侧上下文的后文。例如,cl(wi-1)为“都”及其前面所有上文的结合,cl(wi)为“给”与cl(wi-1)的结合,c(wi)为当前字“你”,cr(wi)为“挖”和cr(wi+1)的结合,cr(wi+1)为“好”及其后文的结合。在本模型中,c(wi)所存储向量不是词向量,而是经过BERT处理后的输出向量T。
W(l)是将上下文转化为下一个隐藏层的矩阵,W(sl)是用于将当前字语义与下一个字的左侧上下文结合的变换矩阵,右侧同理。f(·)为一个非线性激活函数。得到左右上下文的表示后,将它们和目标字的向量拼接到一起。目标字融合上下临近字后的表达形式,如式(5)所示。
xi=[cl(wi);e(wi);cr(wi)]
(5)
xi包含了“你”字及其上下文向量。在RCNN原网络中将多个xi输入池化层,取出各维度最大值得到新的组合向量。但文本中可能存在多个部分均为重要特征,仅使用最大值易丢失信息。故改进RCNN结构,将最后的池化层替换为注意力机制处理特征。
xi经过tanh()激活函数后与任务相关查询向量q做矩阵乘法后得到相关度分数score,再通过softmax函数得到注意力分布αi,xi与αi相乘得到新的向量s作为结果,处理过程如式(6)~式(8)所示。
在计算注意力分布时,我们采用了点乘模型(multiplicative attention),其利用矩阵乘积比经典注意力机制加性模型(additive attention)计算效率更高。
2.3 多任务学习
多任务学习(Multi-task Learning, MTL) 指多个任务共同学习、联合训练的学习过程,旨在通过任务间的信息共享提升单个任务的性能和泛化能力[21]。王崇屹[22]在车辆重识别任务中针对多个任务,设置不同监督信息,实验结果表明,本方法可有效提升模型识别精度。除此之外,在其他模型上[23-24]多任务学习也取得了良好的效果。
违规评论通常带有一定的情感倾向,因此可引入多任务学习思想训练一个文本情感分类模型,进而通过共享网络参数来提高违规评论分类模型的分类精度及其泛化能力。
多任务学习通常采用硬参数共享(hard sharing)、软参数共享(soft sharing)和分层共享(hierarchical sharing)三种方式。本文通过实验对比,采用了在当前数据集上效果最好的硬参数共享,其结构如图7所示。
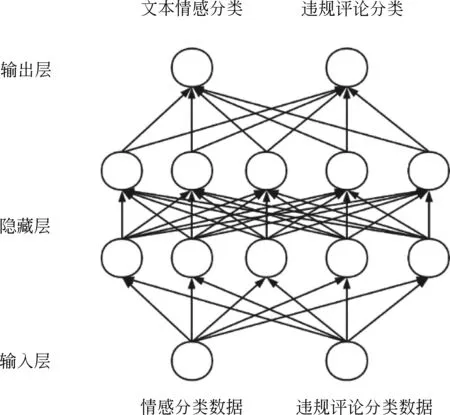
图7 硬参数共享
在硬参数共享模式下,两个任务的基础网络结构完全一致,它们共享输入层与隐藏层,在输出层拟合各任务的数据集,计算损失后共同调整网络参数。引入文本情感分类任务可有效挖掘相近任务中的共享特征,违规评论存在以下情况:
① 违规评论,情感正向。
② 违规评论,情感负向。
理论上,违规评论大多数情感倾向呈负向,因此引入文本情感分类任务对模型进行训练,使模型具备判断文本情感倾向的能力,进而增强对包含负向情感的违规评论的识别能力。在违规评论数据集中,将违规评论标签设置为1;在文本情感分类数据集中,将负向情感文本标签也设置为1。如此,在学习过程中模型会更倾向于将具备共同特征的文本分类为1。如“真尼玛气死了,你怎么还不去死?”,该例句既是违规评论,又是负向情感。通过多任务学习后,即使模型暂时未能捕捉到恶意词汇“尼玛”的特征,也可以依据负面情感“去死”很大概率地将其归类为违规。
但文本情感分类模型仅为辅助模型,在计算损失函数时,若直接叠加,则不利于提高违规评论分类模型性能(如违规评论带有正向情感或正常评论带有负向情感)。采用动态任务优先级[25]对损失函数计算结果进行加权,可以更好地提高本文模型的综合性能,其权重计算如式(9)所示。
wi(t)=-(1-ki(t))γilogki(t)
(9)
其中,wi(t)为不同任务权重,ki(t)为衡量指标,本文采用每轮epoch中验证集精确率作为ki(t)。γi用来为特定任务调整权重,我们通过其来为主要任务违规评论分类赋予更多权重。如果下一轮epoch比本轮精确率低,则会适度降低情感分类对共享网络参数修改的权重。
2.4 标签平滑处理
在标记数据集时,可能也存在标记不准确的人为失误。而在训练深度学习模型时,标签的one-hot编码方式会使模型过于相信标签[26]。此时错误的标签将会对模型带来很大的负面影响。加入标签平滑技术可有效降低错误标签对模型的影响,并提高模型的泛化性。
将原本的标签进行平滑处理需加入一个假设值ε(0<ε<1),如式(10)所示。
(10)
式(10)为原本交叉熵损失函数,在加入了标签平滑处理后将交叉熵损失函数形式调整为如式(11)、式(12)所示。
参数i为当前类别,y是目标类别。yi为真实值,pi为模型输出值。此时标签就从0与1转变为ε和1-ε,如式(13)所示。
(13)
式(13)中,zi是神经网络输出的对应i类的置信度分数,通过softmax得到pi对样本进行分类。在训练过程中,期望预测准确率不断升高,理论上会使zi趋于+∞(实际中只是个很大的值),pi会趋于1,即当i是y类时一定会分类正确。但当标签出现错误时,相似的特征依然会使zi趋于+∞,pi趋于1,此时计算交叉熵则会产生很大的损失,学习后对模型影响很大。
加入标签平滑技术后,zi在不同类别标签中的值如式(14)、式(15)所示,此时不同标签差值相对较小,当标签存在错误时也不会产生特别大的损失来影响模型。
其中,k为类别数,α为平滑率,取值一般为0.1,用于减少不同样本之间的差值。
3 数据集建立
3.1 利用爬虫爬取微博违规信息
模型的有效性需要数据集来检验,但当前关于恶意评论的研究多以英文材料作为数据集[27]。英文数据集的拉丁语系天然具备分隔符,而中文需进行分词等操作,不同的分词点会导致句子语义完全不同,同时中文存在一词多义、在特定环境有特定用意等情况,在英文训练集中表现出色的模型不一定在中文环境仍然出色。因社交平台管控敏感词和反爬虫机制,中文恶意评论数据获取难度较大,还没有公开的数据集。现阶段可查公开中文自然语言处理数据集多为情感倾向和新闻事件文本分类相关数据,故建立此数据集用于研究。
本文采用新浪微博2020年度引发社会舆论广泛关注的典型事件建立了违规评论中文数据集,典型事例如清华美院学姐网暴事件、某艺人因个人行为遭到网友谩骂、成都新冠疫情患者遭人肉攻击等。
3.2 数据处理
通过爬虫获取的数据包含网名、一级评论、二级评论、点赞数和转发数等。一级评论为针对博主的评论,二级评论为针对一级评论的评论。其中网名通常与评论内容无关,故去除。将一级评论和二级评论分别抽取并统一生成评论信息。点赞数与转发数包含了网民舆论支持度但与文本内容是否违规无关,也一并删除。
因采用多账号、多渠道爬取数据,故形成的数据文件为多个零散csv文件,且存在数据不完整的情况。BERT预训练模型存在最佳处理长度,过长和过短的文本均易影响其准确率,应当对文本进行切分。除此之外,还需要去除无意义符号、表情符等非文本信息,通过算法自动进行数据处理比较高效,算法如下:

算法: 爬虫数据提取算法输入: (1) 原始文本文件个数number(2) 爬取数据原始文本的多个csv文件(3) 一、二级评论所在列 one、two输出: 包含一、二级评论信息的无序号csv文本1. dataNumber=number;//文件个数,用于循环读取时忽略已读取过的文件。2. dataTemp=data.csv;//读取具体csv文件3. dataOne= dataTemp.iloc[: ,one];//one为输入的一级评论列数,不同爬虫获取格式有出入,该值需手动输入。4. dataTwo= dataTemp.iloc[: ,two];5. dataAll=process(dataOne,dataTwo);//将一级评论、二级评论进行筛查合并,去除空记录、无意义字符与Emoji表情等。6. dataCut=cut(dataAll);//将超长语句在标点符号处进行切分并去除标点。7. return dataCut;//获取训练数据
3.3 数据集标注
经过处理后的实验数据约6万条,采集到的评论中违规评论较少,几乎无明显粗俗用语,但符合现阶段新型网络暴力特征。同时在其他小众平台上也采集了一些包含恶俗词语的数据,一同并入数据集。
通过人工花费大量时间对文本进行逐条筛选,结合网络小众文化圈特定词语的新内涵,对文本进行标记。带有明显恶俗词语的评论可直接归类为违规评论,语义带有较强恶意但无恶俗词语的文本是否为恶意评论,在很大程度上取决于人类主观感受,暂无统一量化规则,故以多数人感受到恶意为标准。
本次数据集标注工作共三人参与,采用一人标记、两人审核的方式,保证前后数据评判标准的一致性。在评判意见不同时,通过投票决定分类结果。在英文推特的恶意评论数据集中,多个人对同一条评论进行标注,当对该条评论标注为恶意的人数超过参与标注总人数的一半时,认定该评论为恶意评论。本文数据集与其他开源数据集制作流程保持一致。
在采集的数据中明确可以判定为恶意或其他违规行为的评论大概占整体的13%,为使训练集数据分布平衡,本次训练采用19 960条作为数据集。数据集内容如表1所示,包括15 968条训练集,1 996条验证集,1 996条测试集,正常评论标签为0,违规评论标签为1。

表1 数据集构成
4 实验结果与分析
4.1 实验数据
表2为从第3节介绍的数据集中提取的典型违规评论示例,其中包含对人格的攻击侮辱及其他令人不适的信息。正常评论标签为0,违规评论标签为1。

表2 中文违规评论
从表2中可以看出,违规类别主要分人身攻击、歧视言论和违法信息三大类。其中人身攻击是中国社交媒体上网络暴力的主要表现方式,也是前人恶意评论检测任务的重点;歧视言论比较难以通过特定词来检测,只能让模型自己从语料中发现潜在规律并学习;违法信息则包括了色情信息、教唆犯罪和发布违反国家相关法律法规的言论。由于在数据集中各类违规信息数量并不均衡且数据总量较少,统一将其归类为违规评论并进行二分类任务。
开源情感分类数据集中的评论示例如表3所示,其包含正向和负向两种情感,正向情感标签为0,负向情感标签为1。
在多任务学习过程中,因违规评论识别任务无法获取开源数据,故采用本文自建数据集训练模型;文本情感分类任务采用开源数据集[28]进行模型训练,其示例数据如表3所示。

表3 情感分类评论
4.2 评价标准
本文使用精确率(Precision)、召回率(Recall) 和F1分数(F1-Score)作为衡量模型的分类性能的标准,其计算如式(16)~式(18)所示。
4.3 参数设置
本文实验基于Pytorch框架,训练时使用的GPU为NVIDIA GeForce RTX 2080 Ti,模型参数如表4所示。通过BERT预训练模型提取到的词向量维度为768,RCNN中RNN的hidden size为768,Dropout为0.1,学习率经多轮测试选择3e-5,batch size为64,BERT的文本统一处理长度pad size为32,优化器采用BERTAdam。
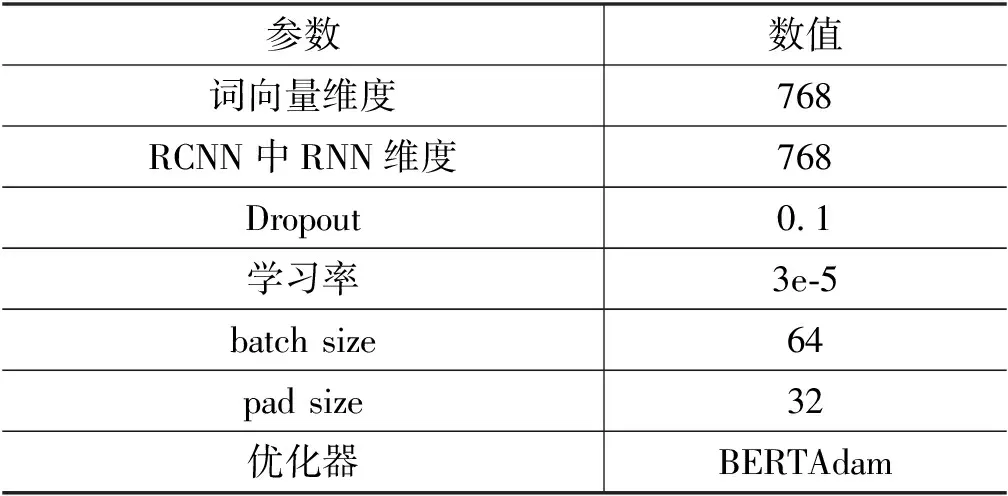
表4 模型参数设置
如图8所示,迭代前100次RBR损失变化较为剧烈,在450次之后基本趋于平稳。结合BERT未加入标签平滑技术的BERT_GRU和BERT_LSTM,则在550次之后才趋于稳定,收敛后的各方法中RBR损失最小。
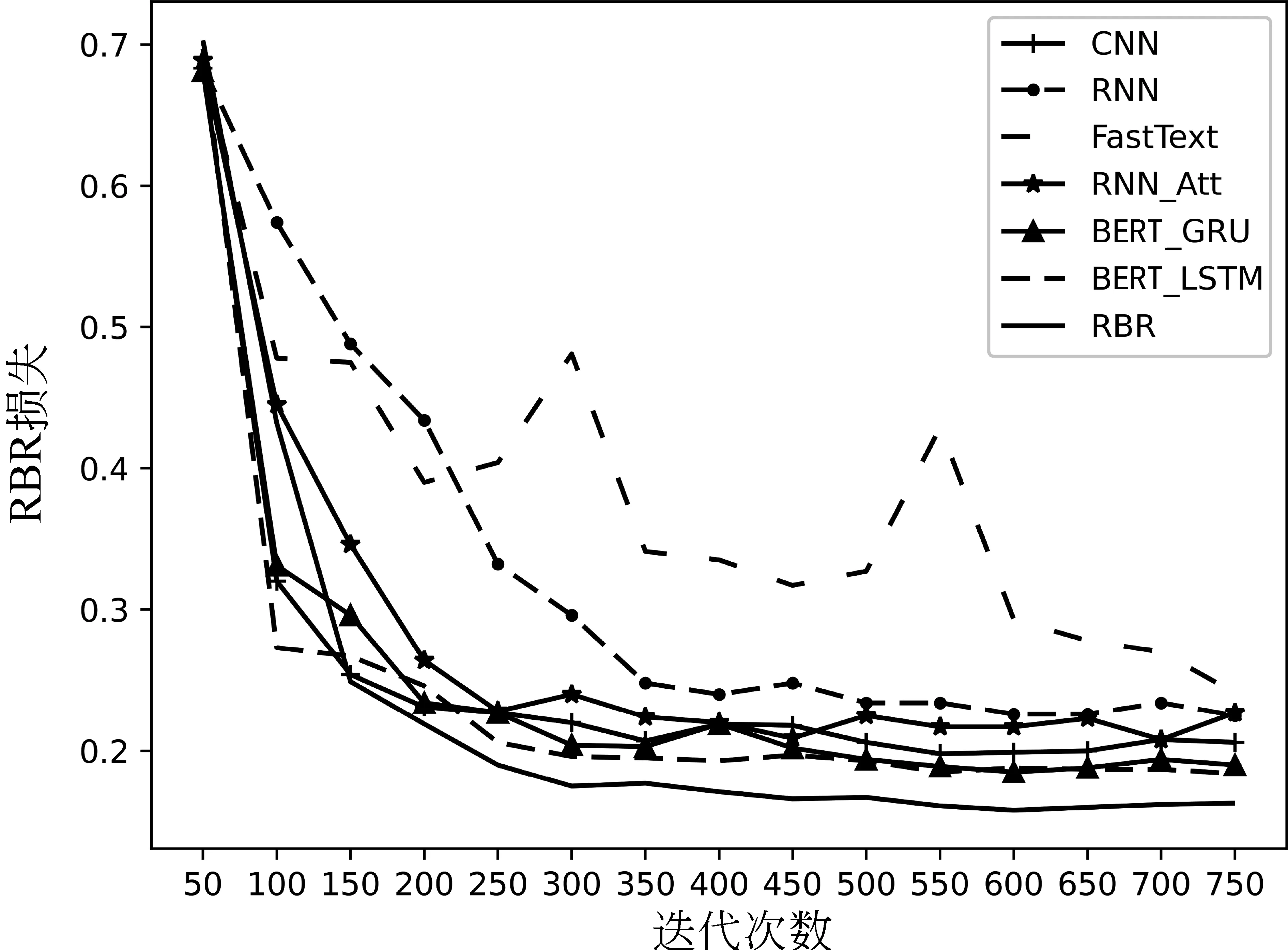
图8 各方法训练损失曲线
RBR模型采用了硬参数共享的多任务学习联合训练,因此仅输出主要模型即违规评论分类模型的损失曲线。
4.4 实验结果分析
为了判别本文方法的有效性,将RBR与部分效果较好的传统模型以及结合了BERT的RNN、GRU模型进行对照实验。传统模型均采用Word2Vec进行词向量转换,其余模型均使用BERT进行词向量转换,对比实验结果如表5所示。

表5 对比实验结果
由表5可以看出,本文方法RBR利用BERT预训练模型可以有效地保留更多的文本信息,RCNN的结构也更多地保存了邻近词之间的关系,从而获得更好的分类效果。其中,RBR (Single task)为单任务模型,RBR (Multi task)为多任务模型。结果表明,多任务学习为模型整体性能带来一定提升。与传统Text RNN比,精确率提升约8.42%,召回率提升4.67%,F1分数提升6.58%;与结合了注意力机制的TextRNN_Att相比,精确率提升6.92%,召回率提升4.18%,F1分数提升5.56%;与其余模型相比,RBR分类性能也有一定的提升。多任务模型RBR (Multi task)比单任务模型RBR (Single task)的精确率高,证明可利用情感分类任务辅助提高违规评论识别任务的性能。
为了更好地对比改进的各部分对整体模型的影响,设计一个消融实验来进行验证。消融实验以最终模型RBR (Multi task)为对照组,实验组1中将改进的RCNN替换成文献[20]的原始结构,命名为RBR (Multi Task-oriRCNN)。实验组2中去掉标签平滑,命名为RBR (Multi Task-no LM)。各实验组与对照组的实验结果如表6所示。

表6 消融实验结果
从表6可知,采用文献[20]结构的RBR (Multi Task-oriRCNN)虽然精确率与本文方法基本持平,但召回率明显下降,导致综合性能下降,我们改进部分提升了召回率。去掉标签平滑后会导致性能指标略微下降,说明该技术可将性能提升约1%左右。
RBR与传统方法相比,在精确率、召回率和F1分数上均有明显优势,可以更好地理解语义,如图9所示。
RBR与其他结合了BERT的方法相比,效果差距不大,但加入了多任务学习和标签平滑技术后有了1%~2%左右的性能改善,如图10所示。
4.5 分类错误案例分析
在使用测试集检测模型后,将部分分类错误评论分离出来,如表7所示。

表7 分类错误评论

续表
第一类错误为: 评论文本是违规评论,但其中无明显恶俗词语,模型将其误判为正常评论。如评论7中采用谐音词“你麻痹”来规避了恶俗词语。
第二类错误为:文本是正常评论,因某些词语与较多违规评论重复,模型将其误判为违规评论,如评论2、3。
第三类错误为:文本是违规评论,但含有情感正向词语,如“好啊”“谢谢”等,模型将其误判为正常评论。如评论1中可能存在教唆犯罪,评论4、5为隐式辱骂,评论6为制造性别冲突。
当前,我国网络社交环境不断恶化,男女性别对立、地域黑、学历歧视等问题层出不穷。本文模型分类错误的原因在于数据集不够庞大,无法实时获取覆盖整个中文互联网的语料。如“女拳”“国蛆”等新型恶意词汇已经出现,但数据集中包含该类新型恶意词汇的违规评论较少,模型无法很好捕捉其特征。
数据集质量及涵盖范围是违规评论识别相关研究的关键,可能的改进方向为利用众包或与网络搜索服务公司合作等形式,获得尽可能多的最新网络暴力评论数据。
5 总结
本文将BERT预训练模型与传统方法结合应用在违规评论识别任务上。与传统模型相比,RBR算法识别精确率有所提升。得益于预训练模型数百万次的训练基础,本文方法的词向量转换过程保留了更多语义信息,在一定程度上摆脱了过去传统模型依赖的违规词表。同时BERT也在词向量分布上包含了情感倾向,可以更好地检测出同义词,进而提升RCNN模型分类的综合性能。在日后的工作中,应当考虑进一步扩充新的数据集,引入不断产生的网络新词对模型重复训练,进一步提升违规评论识别效果。
