低CPU开销的低延迟存储引擎
2022-03-09廖晓坚杨洪章屠要峰舒继武
廖晓坚 杨 者 杨洪章 屠要峰 舒继武
1(清华大学计算机科学与技术系 北京 100084)
2(中兴通讯股份有限公司 南京 210012)
随着新型存储如NVMe SSD(non-volatile memory express solid-state drive)以及网络如infiniband技术的出现,计算机系统正在进入“微秒级延迟”时代.这使得原先针对毫秒级延迟的I/O设备设计的系统软件需要被重新设计,以充分发挥新型高速I/O设备的低延迟优势.本文关注低延迟的存储系统.固态存储(solid-state drive, SSD)技术近10年发展迅猛.例如,Intel公司于2020年公开销售的高性能固态存储[1],硬件带宽高达7.2 GB/s,读写4 KB数据的延迟低至5 μs,较传统的磁盘存储(hard disk drive, HDD)和5年前的SATA(serial advanced technology attachment)固态存储均有多个数量级的改良.对于这些超低延迟的固态存储,主机端存储系统的延迟开销逐渐凸显.
主机端存储系统的延迟主要分为3个部分:系统调用延迟、系统软件延迟例如文件系统层和块设备层延迟,以及I/O收割延迟.已有工作通过在用户态实现存储系统以及简化或绕开块设备层,以优化系统调用和系统软件延迟.伴随着硬件性能提升以及这些软件优化,I/O收割延迟高以及抖动的问题逐渐凸显.本文主要关注I/O收割延迟.
收割I/O请求,即探测并处理存储设备完成I/O请求的信号,是存储系统的一项重要基本功能.传统存储系统依赖硬件中断(interrupt)机制收割I/O请求.然而,硬件中断会引入额外的上下文切换开销,带来额外的延迟.对于高性能固态存储,中断开销变得不可忽视.为此,一些工作提出采用轮询(polling)机制[2]替代中断,以完全消除上下文切换.然而,轮询机制要求主机端CPU一直处于查询I/O完成信号的状态,使得CPU占用率高达100%,严重浪费了CPU的计算资源.
为了解决上述I/O延迟高和CPU开销大的问题,本文提出一种低CPU开销的低延迟存储引擎NIO(nimble I/O).NIO的核心思想是动态地混合使用中断和轮询机制,从而以低CPU开销取得较低的I/O延迟.NIO的主要架构是将“大”“小”I/O的处理路径分离:对于大I/O采用中断机制,因为在此类情况下I/O的传输和硬件处理时间占比较重,中断和轮询的延迟无显著差别;对于小I/O使用惰性轮询机制,先让CPU睡眠一段时间再持续轮询,以此来减少持续轮询带来的巨大CPU开销.在该架构之上,NIO设计和实现了事务感知的I/O收割机制,即以一个事务(一组需要同时完成的I/O请求)为单位判断请求大小,因为一个事务的完成时间取决于最慢的I/O.此外,为了应对应用负载以及存储设备内部活动的变化,NIO提出了动态调整机制,在不影响现有NVMe[3]存储系统高并发和低延迟的前提下,动态调整小I/O的睡眠等待时间.
本文工作的主要贡献包括3个方面:
1) 提出了大小I/O处理路径分离的存储架构NIO,对不同的路径采用不同的I/O收割机制,以同时优化CPU占用率和I/O延迟.
2) 提出了事务感知的I/O收割机制和动态调整机制,以应对应用负载和存储设备内部活动的变化.
3) 在Linux内核中实现了NIO和以上机制,动态负载测试显示,NIO与基于轮询的存储引擎性能相当,并能减少至少59%的CPU占用率.
1 背景介绍与研究动机
本节主要介绍现有高性能固态存储及其软件存储系统的相关背景,并分析现有中断和轮询机制.
1.1 高性能固态存储
固态存储是一种新型的非易失存储.不同于磁头式结构的传统磁盘存储,固态存储内部为电子式结构,因此能提供更高的硬件带宽和更低的读写延迟.
早期的固态存储直接兼容传统的硬盘接口和协议如SATA.然而,传统的磁盘接口和协议带宽受限,存储协议开销大,使得系统软件难以发挥固态存储高带宽和低延迟的优势.因此,一种新型的针对高性能固态存储设计的存储协议NVMe[3]被提出并广泛应用于固态存储.相比于传统的SATA协议,NVMe协议显著地降低了处理1个I/O所需要的CPU指令.同时,NVMe提供多硬件队列抽象,在现代多CPU的计算机上具有更好的多核扩展性,从而降低核间竞争和同步机制带来的额外延迟.以上优势使得基于NVMe的存储设备能提供更低的延迟.
近几年来,固态存储的平均延迟有了显著的降低,如表1所示.例如2014年Samsung公司推出的850pro SATA SSD,平均延迟以及延迟标准差均超过50 μs.然而,2018年Intel公司推出的905P NVMe SSD能在10 μs内处理4 KB随机读,延迟标准差也能控制在2 μs内.另一方面,从表1中“99.9%延迟”列中可以看出,固态存储也能提供越来稳定的延迟.
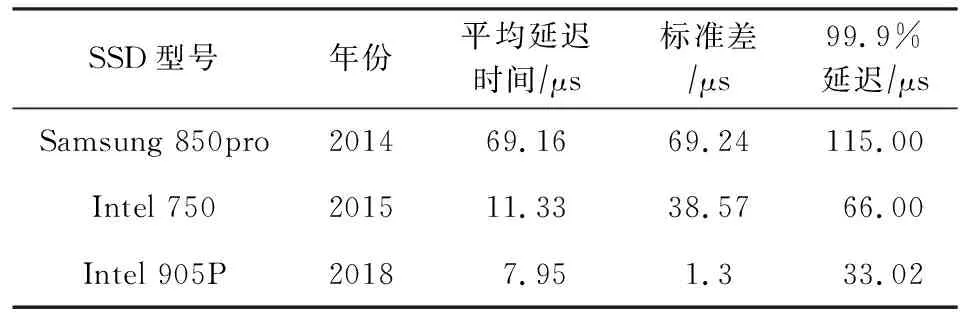
Table 1 Comparison of SSDs Latency (4 KB random read)
1.2 I/O收割机制——中断和轮询机制
固态存储越来越低及越来越平稳的延迟,促使系统软件设计者重新思考存储软件的设计.其中,如何提供高效的I/O收割机制,即以低开销快速探测并处理存储设备完成I/O请求的信号,成为系统软件关注的热点问题[2-6].本节将具体介绍硬件中断和轮询2种广泛应用于存储系统的I/O收割机制,并分析它们的优劣.
硬件中断机制依赖硬件发出完成信号,由CPU暂停正在执行的任务,将原先的I/O处理任务调度回CPU执行,以完成I/O处理的最后阶段,如通知应用程序.中断机制在主机端CPU不繁忙时,会因为任务上下文切换或CPU运行模式切换引入1 μs左右的延迟;在主机端CPU繁忙时,CPU任务调度和缓存失效等使得中断机制带来的延迟变得更加不可预测.中断开销在高性能固态存储上显得愈发严重.
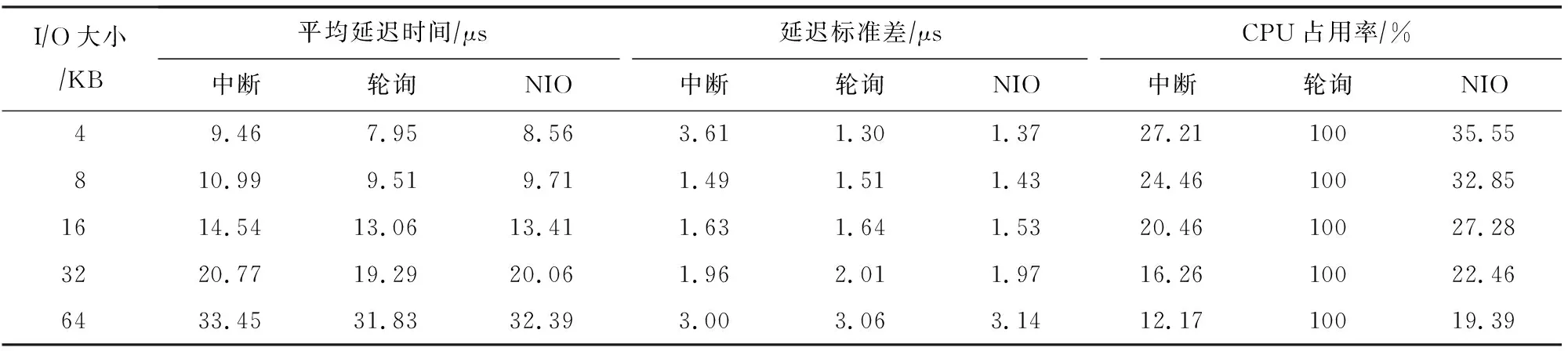
为此,部分系统如SPDK[2]提供了轮询机制以消除中断开销.轮询机制使得I/O任务所在CPU无休止地查看完成信号.这种极端的I/O收割机制能缩减I/O延迟,却需要付出100%的CPU开销.如表2所示,对于现代一块超低延迟的固态存储盘,轮询的延迟低于中断延迟,尤其是I/O请求大小较小时.然而,随着I/O请求变大,轮询带来的I/O延迟低的优势逐渐变得不明显.这是因为大I/O请求的硬件处理时间明显高于I/O收割延迟,使得中断的上下文开销变得不明显.另一方面,随着I/O请求变大,中断的CPU开销越来越低,而轮询却需要独占CPU.
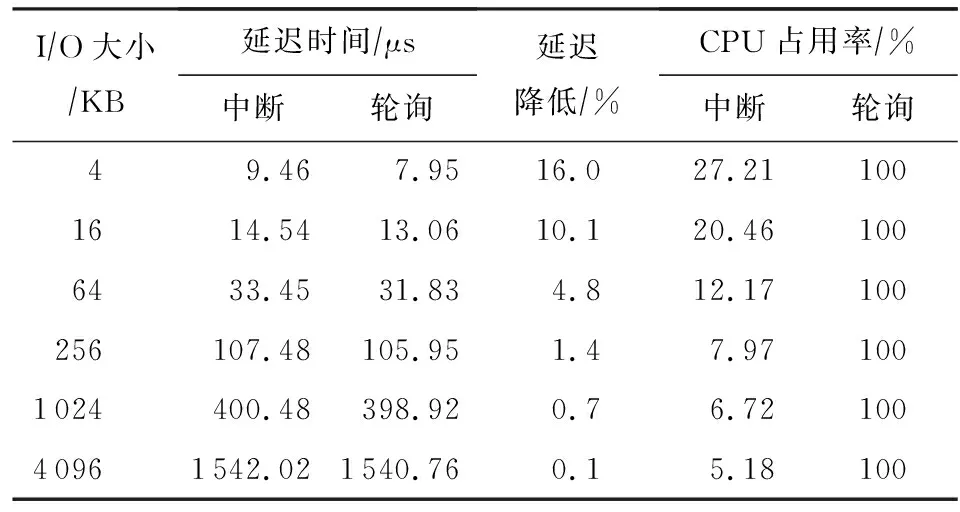
Table 2 Comparison of the Latency and CPU Consumption of Interrupt Against Polling
通过分析,我们发现轮询机制在I/O请求较小时延迟低的优势明显;在I/O请求较大时,中断机制CPU开销低的优势显著,延迟与轮询机制相当.
2 NIO设计
本文提出一种低CPU开销的低延迟存储引擎NIO,旨在提供与轮询接近的低延迟,同时降低I/O收割过程中的CPU占用率.
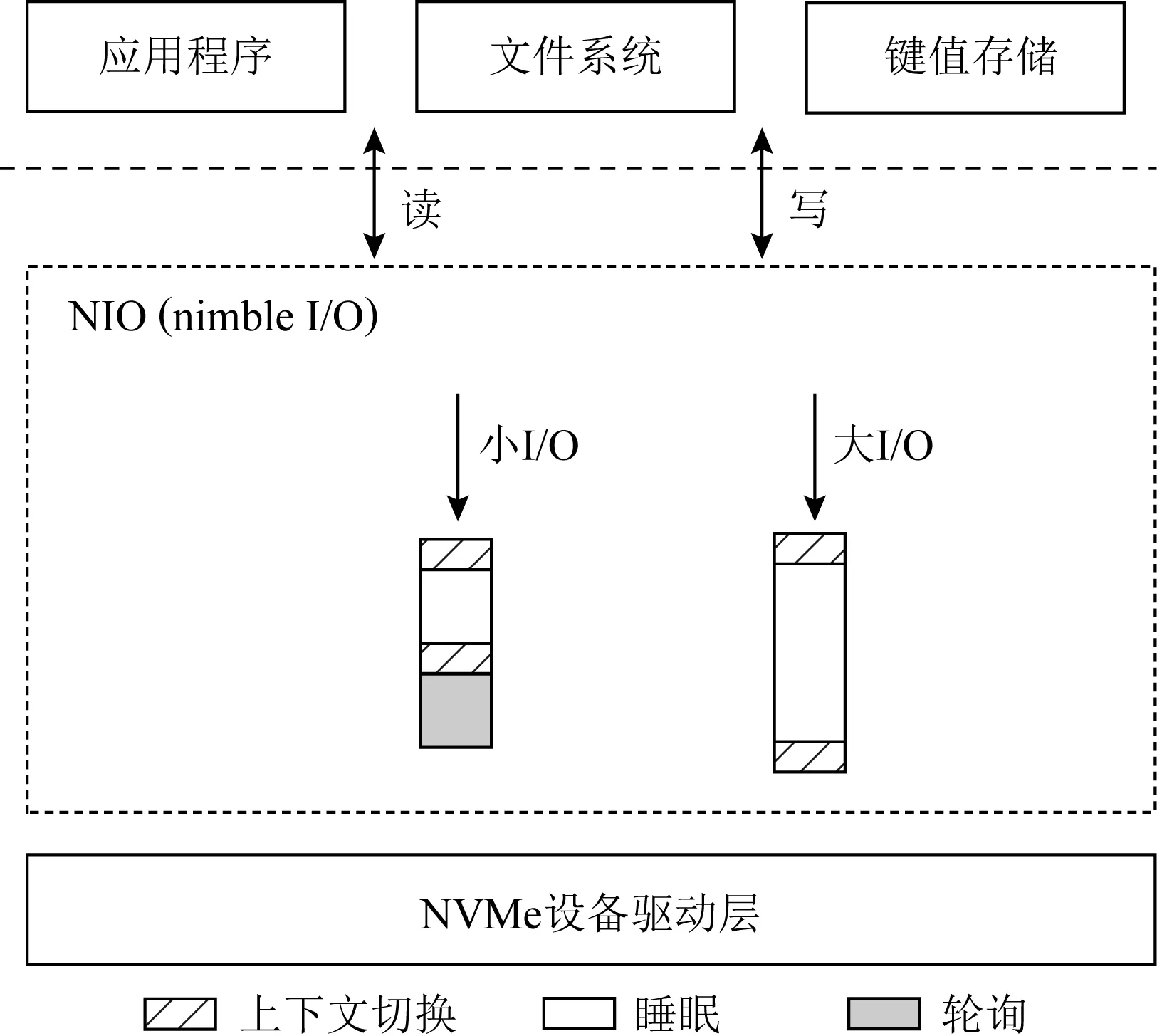
Fig. 1 Overall architecture of NIO图1 NIO的整体架构图
2.1 NIO架构
图1显示了NIO的架构图.NIO是介于NVMe设备驱动层和应用层之间的基本存储引擎(类似于块设备层).应用程序、文件系统或者键值存储系统通过读写接口将I/O请求发送给NIO.受到表2的启发,NIO将大小I/O路径分离,并采取不同的I/O收割机制以低CPU开销获取低I/O延迟.如图1和算法1所示,在提交I/O到设备后,对于小I/O,使用惰性轮询机制,先让出CPU一段时间,再接着轮询I/O请求的完成信号(算法1的行②~④).对于大I/O,NIO仍然使用传统的硬件中断机制(算法1的行⑤⑥).
算法1.NIO处理I/O请求算法.
输入:发送到存储设备端的I/O请求bio,I/O大小io_size;
输出:函数返回值void.
①submit_bio(bio); /*提交I/O到设备*/
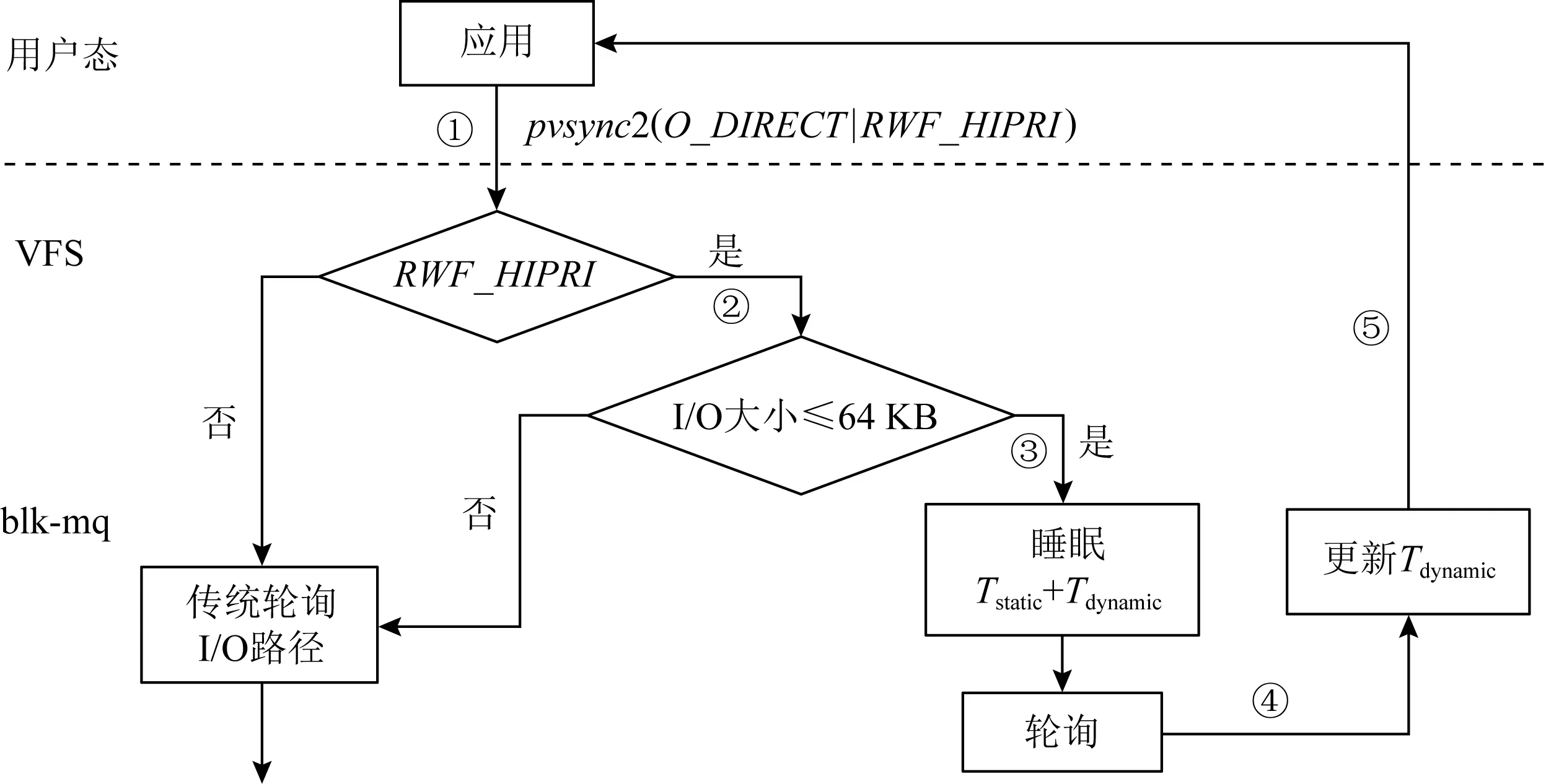
② ifio_size /*THRESHOLD为界定的大小I/O的阈值*/ ③sleep(INTERVAL); /*让出CPU,INTERVAL为小I/O睡眠时间*/ ④wake_up()并轮询; /*被高精度定时器hrtimer唤醒并进入轮询*/ ⑤ else /*大I/O处理路径*/ ⑥io_schedule()并等待中断; /*让出CPU并等待中断信号*/ ⑦ end if NIO的架构面临着2个基本问题:如何区分大小I/O以及如何确定惰性轮询的睡眠等待时间. NIO通过系统预设的分界阈值区分大小I/O.分界阈值可通过对比存储设备在带宽利用率不高的情况下,中断和轮询5类规整大小I/O的延迟确定.如表2所示,在读请求大小低于64 KB时,轮询的优势显著;而在≥64 KB时,轮询优势不明显.故NIO对于同种型号的SSD的读请求采用64 KB为分界阈值,写请求的情况类似.这种静态切分的方法能有效应对复杂的应用I/O.首先,虽然应用I/O大小可能不规整(即非4 KB的整数倍),操作系统在提交I/O请求一般通过填充操作将其对齐,故在确定分界阈值只需要测量少数5种规整大小的I/O.其次,在确定分界阈值时,只需考虑存储设备带宽未被充分利用的极端情况.因为在这种情况下设备的硬件延迟较低,能确定在所有设备状态下小I/O的一个超集,使得小I/O总是能被准确判定.本文将在2.3节讨论在设备带宽充分利用情况下,通过动态调整机制调整惰性轮询睡眠间隔以应对小I/O被误判的情况. NIO通过系统静态预设和动态调整的方法,为每一种规整大小的小读和小写请求都设定一个睡眠阈值.NIO静态睡眠阈值综合考虑了I/O的平均延迟、延迟抖动以及睡眠开销,其确定式为 Tstatic=Tavg-Tstdev-Tsleep, (1) 其中,Tavg为轮询该类型该大小I/O的平均延迟,例如表2中的第3列轮询延迟.Tstdev为该类型该大小I/O耗时的标准差.式(1)之所以减去标准差,是为了缓解I/O延迟抖动带来的影响.最后,静态睡眠时间Tstatic还除去了睡眠机制带来的开销Tsleep,如睡眠前后的上下文切换.睡眠开销可动态配置,在NIO中为1 μs. 以上NIO的基本架构涵盖了I/O收割过程中的静态属性.然而,如何应对上层应用以及底层存储设备的动态变化依然存在难题.因此,NIO提出事务感知的I/O收割机制和动态调整机制. 在存储系统中,一组需要同时完成的I/O请求被称为一个事务.事务的响应延迟由事务中处理最慢的I/O请求确定,它对系统的性能表现有很大的影响.在现有的存储系统中,I/O的处理和收割都是以单个I/O为单位,无法感知上层系统的事务语义,从而可能无法发挥NIO大小I/O分离的架构优势.例如,文件系统在处理用户通过文件接口存储的数据时,可能需要写入2个数据,即文件元数据(描述文件存放位置)以及用户数据.文件元数据一般较小,例如低于64 KB,而用户数据视应用情况可能较大,例如高于64 KB.在最基本的NIO设计中,文件元数据被划分为小I/O处理,而用户数据被划分为大I/O.即使文件元数据被快速收割,用户请求的快慢还是取决于较大的I/O,即用户数据;这使得小I/O优化失效. 为了解决上述问题,NIO提出了事务感知的I/O收割机制,即判断I/O大小是以整个事务为基本单位.若一个事务中存在大I/O,则该事务被判定为大I/O;事务中的小I/O也还是以中断的方式收割.若一个事务中的请求均为小I/O,则该事务被判定为小I/O;事务中的所有I/O以惰性轮询的方式收割. 事务感知的I/O收割机制还面临2个问题:1)上层系统如何传达事务语义给NIO;2)事务内部的请求依赖在NIO架构下如何处理. 上层系统或应用需要显示地指定某些I/O属于同一个事务.事务指定方式可以通过为I/O请求标上同一个事务ID(identity)或者通过同一个系统调用实现.在NIO的具体实现中,我们通过后者,即同一个系统调用,传达事务语义.NIO通过矢量化的I/O系统调用pvsync2,实现事务感知的I/O收割机制.应用程序可以通过pvsync2指定多个不连续的I/O请求,并将这些I/O请求标记为高优先级(例如携带RWF_HIPRI标志),以触发NIO的事务感知的I/O收割机制. 事务内部的I/O请求可能存在依赖.如文件系统中日志数据块和日志提交块存在写依赖,即日志提交块需要在日志数据块之后持久化.NIO通过分阶段的思想,将有依赖的请求划分成多个阶段处理,从而在保证原先事务写依赖的前提下,尽可能加速每一阶段的I/O请求.如一个事务中A和B这2组请求,A需要在B之前持久化,则第1阶段先使用对A组请求整体收割.在A组请求完成后,B组请求接着以类似的方式处理. 现代的存储设备一般具有多个硬件队列,且1个硬件队列可同时处理多个I/O请求.所以,一个I/O预期的完成时间不仅仅取决于存储系统中的静态因素(即式(1)),也受到其他硬件队列以及本队列上I/O的影响.为了应对上述问题,NIO提出动态调整机制,在保留现有NVMe存储系统高并发低延迟的特点前提下,动态调整小I/O处理的睡眠时间. I/O请求可能由于有限设备资源和设备内部活动如垃圾回收而遭受额外的排队时间.NIO通过启发式算法确定I/O的排队时间,并将该排队时间加上式(1)的时间确定小I/O的总体睡眠时间: Toverall=Tstatic+Tdynamic. (2) NIO为每个硬件队列上的每类请求大小的读和写请求维护1个排队时间Tdynamic.例如NIO系统中有32个硬件队列,5种请求大小,则每个队列有10(=2×5)个排队时间,总共有320(=2×5×32)个排队时间.NIO为每个硬件队列都维护1个排队时间,从而不影响硬件队列的并行性. 排队时间在每一次I/O请求完成时动态更新.排队时间为当前队列当前I/O前N个I/O请求等待时间的算数平均数: (3) Δti=max(0,Treal-Texpect), (4) 其中,Treal为I/O从NIO发出至I/O被NIO收割的时间间隔,Texpect为该I/O在轮询机制下的平均延迟,例如表2的第3列轮询延迟. 为了维护排队时间,NIO需要额外的内存空间记录前N个I/O请求的排队时间.例如对于32个硬件队列,2种I/O和5种请求大小,N=1 024,每个排队时间用8 B记录,则需要额外2.5 MB(=32×2×5×1 024×8 B)内存空间.现代计算机一般拥有4 GB以上的内存空间,故本工作认为该内存空间开销可以接受. 同时,为了实时更新排队时间,NIO需要追踪每个I/O的实际完成时间,该追踪和实时更新开销在NIO可忽略不计.现有Linux NVMe存储系统自身已经追踪每个I/O的生命周期(如完成时间),向上层系统提供这些信息供程序分析、服务质量控制等功能.NIO构建于NVMe存储系统之上,天然地利用每个I/O的实际完成时间,故无额外的追踪开销.在更新排队时间时,NIO采用递归增量更新的方式而非每次都重新计算平均值: (5) NIO每次只需计算最近I/O的排队时间,即ΔtN+k,并根据式(5)以常数时间复杂度递归更新排队时间,极大地降低了更新排队时间的开销. 本工作通过修改Linux 4.18.20内核中的多队列块设备层(blk-mq)实现了NIO. Fig. 2 The implementation of NIO图2 NIO的实现 图2展示了NIO的具体实现以及流程图.为了方便阐述,图2的每次系统调用即步骤①为只包含1个I/O请求的事务,I/O大小的判断即步骤③也是以事务为单位.如图2步骤①所示,应用程序需要通过pvsync2接口,并将该请求标记成O_DIRECT和RWF_HIPRI,以调用NIO的功能.这2个标志存在于原生Linux内核中,分别表示绕开VFS页缓存和高优先级请求.NIO利用这2个标志实现低延迟的I/O收割机制,从而无需改动除blk-mq之外的其他内核模块如VFS.如步骤②所示,VFS检查请求标志,若不携带RWF_HIPRI,则将请求直接派发到传统基于中断机制的I/O路径中,否则进入blk-mq模块进一步判断大小I/O.如步骤③所示,若为小I/O,即I/O大小≤64 KB,则采用惰性轮询机制.NIO首先睡眠间隔为Tstatic+Tdynamic,其中Tstatic为式(1)所定义.本工作在blk-sysfs.c中添加了新的结构体和函数以支持Tstatic的手动配置.在操作系统启动完成时,系统管理员可以通过Linux sysfs向NIO传入Tstatic相关数值.Tdynamic为式(3)定义.由于NIO通过式(5)计算Tdynamic,NIO维护了2个排队时间以及N个Δt.这些变量的初始值为0. NIO在睡眠之后持续轮询,直到接收到I/O完成信号,如步骤④所示.之后,NIO根据式(5)更新Tdynamic.其中需要计算当前请求的实际完成时间与预期完成时间的差值,即ΔtN+k.NIO在睡眠之前通过函数ktime_get_ns记录初始时间T1,在步骤④记录完成时间T2.实际完成时间Treal=T2-T1.预期完成时间需要系统管理员手动配置.与Tstatic相似,系统管理员在操作系统启动完成时通过sysfs向NIO传入各种大小的读写请求在轮询机制下的完成时间,例如表2的第3列轮询延迟.NIO通过式(4)计算出ΔtN+k,并通过式(5)更新排队时间.如步骤⑤所示,请求被成功处理并返回用户应用. 本节将通过实验对比和分析NIO与现有系统的性能差异.首先,通过对比NIO与现有系统在不同I/O大小下的性能表现和CPU占用率验证NIO的架构和整体设计.其次,通过对比测试事务处理下的性能验证事务感知的I/O收割机制.最后,通过动态负载,分析和验证动态调整机制. 本实验使用的实验平台配置信息如表3所示.本实验使用的测试设备为Intel公司于2018年推出的傲腾SSD[7],其在本实验平台的延迟如表2所示.NIO的配置参数如表4所示.这些参数通过FIO[8]单线程测量原生Linux NVMe存储栈在不同I/O大小(如表4中第1列所示)对整盘进行随机读写的延迟确定.静态睡眠时间通过式(1)确定,其中延迟平均值和延迟标准差为基于轮询的对应延迟.预期完成时间为基于轮询的平均延迟.在操作系统启动完成后,这些参数通过sysfs传递到NIO系统中. Table 4 NIO Parameters 本实验将NIO与基于中断机制和轮询机制的Linux NVMe存储系统对比.本实验使用性能测试工具FIO对整块存储设备区域进行读写.为了测试公平,所有测试均使用pvsync2接口发送I/O请求,以控制存储系统其他部分的影响.整个测试过程开启O_DIRECT标志,以绕开操作系统缓存直接对设备读写.如无特别说明,测试的数据量为整个盘的大小. 本节测试启动单个线程持续发送各种大小的I/O.测试过程中io_depth被设置为1.表5显示了测试结果.I/O大小>64 KB的结果未显示,是由于在这之后3个对比系统的性能无明显差异.从表5中可知,综合各I/O大小的平均值,NIO的平均延迟为中断的92.9%,为轮询的103.6%.这是因为对于小I/O,NIO使用了惰性轮询机制,使得绝大部分I/O能消除中断带来的上下文开销.进一步分析发现,对于少部分快速完成的I/O,NIO睡眠时间过长导致总体平均延迟比轮询I/O的平均延迟高. Table 5 Microbenchmark Results (Random Read) NIO也能提供更稳定的延迟,其延迟标准差为中断的86.6%,为轮询的98.8%.相比于中断,NIO需要额外7%的CPU占用.此外,相比于轮询,NIO在优化I/O延迟的同时能极大地降低系统的CPU占用率.这是因为相比于极端的轮询,NIO会主动让出CPU进入睡眠状态,降低CPU占用率的同时保留当前程序的可用时间片,从而降低下次CPU周期调度(10 ms 1次)将该任务调度出去的概率. 本节测试使用FIO的pvsync2接口模拟事务处理.测试过程从4 KB~64 KB区间随机选择事务内各I/O请求的大小.本实验设置事务大小即事务内I/O个数分别为4和64,以分别模拟大小事务.由于pvsync2接口单个操作只支持1个操作数(即读或写),因此目前NIO的具体实现也只支持纯读和纯写事务.因此,本实验仅展示了纯读和纯写事务的性能.测试结果如表6所示.从表6可知,当事务大小为4时,相比于中断,NIO能平均降低约3.4%的事务处理延迟.当事务大小为64时,NIO的优势更明显,事务处理延迟相比中断平均降低了4%.另一方面,NIO相比于中断需要付出额外50%的CPU开销,相比于轮询减少了约82%的CPU占用.进一步分析发现,在本实验的SSD上,I/O的硬件处理时间还是占了相当重的比例,导致中断机制与轮询机制的平均延迟相差不大.相信在下一代更快的设备上,如Intel公司2020年推出的4 KB读写延迟仅为5 μs(比当前测试设备快了将近1倍)的PCIe 4.0 SSD[1]上,NIO的延迟和CPU占用率的降低将更加明显. Table 6 Results of Transaction Performance 本节实验通过动态变化测试过程中的I/O大小、I/O线程以测试NIO的动态调整机制.实验过程分为3个阶段,以分别模拟系统在频繁小I/O、频繁大I/O以及高并发情况下的场景以及这些场景间的切换.每个阶段向测试设备上随机写入20 GB的数据. 阶段1,FIO启动2个进程随机写入I/O大小在4~8 KB的数据;阶段2,测试进程增加为4个,随机写入128 KB~1 MB的数据;阶段3,进程数量进一步增加至13个,并向设备写入4~8 KB的数据.测试结果如表7所示.从表7可知,写入等量数据时,NIO几乎能和轮询同时间完成,比最慢的中断时间缩短约5%. Table 7 Results of Dynamic Workloads 本实验进一步分析了测试过程中各阶段的平均延迟、归一化到轮询的延迟标准差和CPU占用率.在3个阶段,NIO的延迟标准差分别为中断的7%,100%,9%,为轮询的105%,143%,142%;NIO的平均CPU占用率分别为中断的125%,110%,110%,为轮询的41%,7%,21%.可以看出,NIO在高并发小I/O场景下(即第3阶段)表现尤其优异.高并发小I/O场景不仅考察存储系统的I/O处理能力,也考验CPU利用效率;NIO能以更小的CPU代价获取较低的I/O延迟,故NIO在CPU竞争的频繁小I/O场景下优于中断和轮询. 本节将从I/O收割机制及低延迟存储系统2个方面介绍相关工作. 1) I/O收割机制.传统存储系统通过中断收割I/O,然而会引入额外的上下文切换开销.因此,某些存储系统[2-4]使用轮询取代中断以消除上下文切换,从而获取低延迟.Linux内核进一步提出了混合轮询机制[9](hybrid polling)以降低轮询带来的CPU开销.混合轮询与本文提出的惰性轮询类似,都是先让线程睡眠等待一段时间再持续轮询.不同之处在于:①混合轮询不区分大小I/O均使用同种轮询策略,使得大I/O的收割效率低下.②混合轮询不区分读写、不区分I/O大小,均使用同一睡眠时间,使得小I/O可能受大I/O的影响睡眠过长而效率低下.③混合轮询在计算睡眠时间时,采用的是自机器启动以来所有I/O的平均完成时间的一半;这种方法会导致睡眠时间的不准确以及破坏NVMe存储系统的并行性.④混合轮询无法动态调整.以上混合轮询的种种局限使得其默认在Linux内核中被禁用;本文提出的NIO可能是内核中混合轮询的一种更高效的替代系统.cinterrupt[6]动态地合并中断请求,从而减少主机端CPU占用.cinterrupt的设计和本文的NIO互补,能共同促进高效的I/O收割机制. 2) 低延迟存储系统.为了充分发挥新型固态存储设备的超低延迟,Linux NVMe存储系统默认不进行主机端I/O调度.FLIN[10]和D2FQ[11]提出在设备端进行I/O请求调度以保证公平性及控制尾延迟.asyncio[12]在存储系统中将CPU和I/O操作并行,从而降低单个文件系统调用的整体延迟.CoinPurse[13]将文件系统中的小写通过字节接口直接写入设备的控制器缓冲区,从而加速了小写操作.HORAE[14]提出将存储系统中的顺序性保证分离,由快速旁路保证,从而使得一连串序列化的写请求能并行执行,缩短了事务的延迟.Max[15]通过优化读写锁和数据结构组织方式,降低多进程在文件系统层的同步和竞争,从而能降低高并发场景下请求的延迟.以上低延迟存储系统关注更上层系统(如文件系统)的I/O延迟,能进一步利用NIO缩短I/O收割阶段的延迟. 另一类优化存储延迟的系统基于开放通道固态存储(open-channel SSD, OCSSD),利用OCSSD的白盒优势,通过精简软件栈以及提供存储隔离等方法缩减延迟.ParaFS[16]将主机端存储软件与设备端具有类似功能的闪存转换层协同设计,与文献[17-21]中所述的设计类似.ParaFS通过精简存储栈、主机端I/O调度以及主机设备协同的垃圾回收机制等方式优化I/O延迟.FlashBlox[22],DC-Store[23],OCVM[24]通过将不同应用、容器或虚拟机以隔离的方式运行在不同的物理存储通道(channel)中,以消除不同应用I/O的互相干扰,从而提供稳定的延迟.此类系统通过软硬件协同提供端到端的延迟保证,能进一步利用NIO优化I/O收割延迟. 高性能固态存储支持较大的并发,且硬件控制器可能会对并发I/O进行调度,导致I/O乱序执行,从而影响NIO的优化效果.I/O乱序会导致2种结果:请求提前完成和请求延后完成.对于请求提前完成的情况,NIO针对小I/O的惰性轮询设计可能失效.但由于NIO保留了中断机制,NIO仍能准时捕获I/O完成的信号.对于请求延后完成的情况,NIO针对小I/O的惰性轮询设计仍能起作用,但惰性轮询的睡眠时间相比于无乱序场景是次优的. 针对I/O乱序问题,利用白盒、灰盒存储或机器学习技术,NIO能在将来被进一步优化.在白盒和灰盒存储例如开放通道固态存储中,主机端软件能控制I/O调度,使得I/O完成时间能被更准确地预测,如文献[16,25]所述.在黑盒存储例如商用的标准NVMe SSD中,已有工作[26]利用机器学习模型预测I/O请求的完成时间,此类技术也可用于确定NIO的睡眠等待时间. 高性能固态存储I/O处理速率越来越快,其单个I/O的延迟已低于10 μs.因此,构建低延迟存储引擎具有重要意义.本文提出一种低CPU开销的低延迟存储引擎NIO.通过将大小I/O路径分离并提出事务感知的I/O收割和动态调整机制,NIO以低CPU开销快速探测并处理存储设备完成I/O请求的信号.实验显示,相比于传统的基于中断或轮询的存储引擎,NIO能取得与轮询接近的延迟并大幅降低CPU占用率. 作者贡献声明:廖晓坚进行了该论文相关实验设计、编码及测试、论文撰写等工作;杨者进行了前期实验方案的讨论设计与论文修改;杨洪章进行了论文结构讨论和修改;屠要峰进行了实验补充设计讨论及论文修改;舒继武进行了论文修改以及新型固态并发乱序研究讨论.2.2 事务感知的I/O收割机制
2.3 动态调整机制
3 NIO实现
4 实 验
4.1 实验平台和方法

4.2 基准测试
4.3 事务处理测试

4.4 动态负载测试

5 相关工作
6 讨 论
7 结 论
