基于时间序列的山区风向预测方法研究
2022-03-08焦瑞莉夏江江
武 略 焦瑞莉* 夏江江
(1北京信息科技大学信息与通信工程学院,北京 100101;2中国科学院大气物理研究所,北京 100029;3中国科学院大学,北京 100049)
山岭地区地形条件复杂,受背风坡和迎风坡的影响,气温、风和能见度等要素在水平范围变化剧烈。其中,风向作为常见的预报要素,具有重要的实际意义和很高的研究价值,尤其对山区的风力发电、基础设施建设等具有重要意义。风向是2022年北京冬季奥运组委会十分关注的气象条件之一[1],具有较大的波动性和不可预测性,对运动员的成绩和安全有关键影响。
目前,风向主要通过物理建模、统计学和数据驱动3种方法进行预测。物理方法主要为模式的预报,例如欧洲中期天气预报中心针对全球格点所做的预测数据,原理通常为分析大气运动规律,构建物理学方程模拟地理环境和天气状况,从而推演风场的变化规律。此类预测方法需要掌握大气的物理相互作用,并建立合理规范的重现方程,但是由于模式的物理化方案尚存在欠缺,许多计算参数也不确定,使近地面风场预报存在较大的误差[2]。在统计学方法方面,Erdem等[3]利用自回归滑动平均模型(auto regressive moving average,ARMA)对风向序列进行了分析和预测,曾晓青等[4]利用传统的模式输出统计法进行了风向矢量预测,祝 牧等[5]使用随机Markov链拟合了风向的时间序列,并建立模型进行预测。近年来,更高效的数据驱动算法如机器学习和深度学习开始应用于风向预测。Mohandes等[6]提出利用支持向量机对风向进行预测,张东东等[7]将BP神经网络应用在风力发电机的风向预测中,唐振浩等[8]基于SWLSTM算法对超短期风向进行了预测。
为满足风向预报的需求,算法应有较高的准确率,还应易于操作维护、复杂度低、建模快。结合山区的地形条件和气候变化,所选用的预测方法需对山脉地区的数据变化足够敏感,既能分析突变的风向数据,又可解决预测不准确的问题,还需及时使用最新数据再次搭建模型反馈结果,实现灵活准确的预报目标。本文分别使用ARMA统计方法、XGBoost机器学习算法、LSTM深度学习算法对选定山区4个气象站的时间观测序列进行预测,比较3种算法的优劣,并在此基础上添加风速序列,将风速和风向拆分为U、V风向,并对其分别进行预测,将结果合成后能更好地预测高山站风向,进而为2022年冬奥会的风向预测探索一种新方法。
1 数据与方法
1.1 数据来源
为了更好地模拟山区风向的预测实况,选择北京延庆燕山山脉的4个气象观测站作为试验站点,站点信息见表1。观测站记录的风向数据以时间序列的形式每小时记录1次,将此数据作为后续的分析数据。

表1 山区4个气象观测站点信息
1.2 算法模型
1.2.1 自回归滑动平均模型。自回归滑动平均模型(ARMA)作为研究时间序列的经典方法,由自回归模型(简称AR模型)与滑动平均模型(简称MA模型)根据数据自身结构特点组合而成[9]。一般用ARMA模型拟合时间序列,预测该时间序列的未来值[10]。ARMA模型可表示为ARMA(p,q),其中 p是自回归阶数,q是移动平均阶数,如式(1)所示:
式中:xt-1、xt-2、 ……、xt-p为不同时间点记录的指标数值;Ø1、Ø2、……、Øp为自回归系数;μt、μt-1、……、μt-q为不同时间点的白噪声项;θ1、θ2、……、θq为移动回归方程系数;xt表示时间点t指标数值。
使用ARMA时,需要先判断所使用的序列是否平稳:若平稳,可直接使用ARMA模型;若非平稳,需要对原序列进行差分直至平稳,再使用ARIMA模型,其中I代表差分次数。根据序列自相关和偏相关系数来确定模型的选择,需要定阶来确定p和q。其中:p代表时间序列是否存在周期,比如气温和降水随季节变化,就存在明显的年周期性,在气温预测中,往年同期数据有着很高的参考价值;q则代表白噪声项。常用的定阶方法为AIC[11]或BIC准则,AIC准则(akaike information criterion)是拟合精度和参数个数的加权函数,BIC(bayesian information criterion)则改善了AIC准则在大样本情况下模型不收敛的问题。在确定模型之后还需要检验模型,具体包括观察残差序列的随机性、是否符合正态分布、是否为白噪声。
在Python的使用中,通常从statsmodels包中调用ARMA,statsmodels是一个包含多种统计模型、适用于数据分析的Python模块;也可使用其中的plot_acf和plot_pacf绘制序列的自相关与偏相关图。预测结束后,对预测出来的数据进行逆差分操作,即得到最终预测结果。
1.2.2 极端梯度提升算法。极端梯度提升算法(extreme gradient boosting,XGBoost)是 Boosting 算法的其中一种,Boosting作为一种提升方法,通过拟合残差进而优化目标函数,从而将一组弱分类器集合成强分类器。为防止过拟合,基于提升算法,XGBoost对损失函数进行二阶泰勒展开,并且加入正则项,衡量目标函数的下降和模型的复杂水平[12]。模型公式如式(2)所示:
式中,yˆi为输出的预测值,K 为树的数量,fk表示第k棵树模型。
对每一棵树进行训练时,目标函数如式(3)所示:
式中:L为损失函数;N为样本数;t表示训练第t棵树;ft表示第 t轮所生成的树模型;Ω(fi)表示正则项。
树的复杂度如式(4)所示:
XGBoost的主要参数:eta,即学习率参数,值越小,模型对数据的学习越精细;max_depth,树的最大深度,用来避免过拟合,值越大,模型对局部样本的学习更具体;min_child_weight,同样避免过拟合;gamma控制节点分裂的标准,值越大,算法越保守;subsample,采样率,用于调节模型拟合程度;colsample_bytree,用于选择所生成树的特征;n_estimators,迭代次数,即生成树的个数。
调整参数时,使Python软件中的GridSearchCV来寻找模型的最佳参数:先调节n_estimators,范围从400到800,步长为100,确定最优值后缩小步长再次寻找。然后调节控制树结构的min_child_weight和max_depth这2个参数;之后依次调节gamma、subsample和colsample_bytree;最后调节学习率,因为其数值较小,所以从0.01开始调节。由于分别预测了风速和风向,因而需要在每次使用新数据前开始调参,从而获得最好结果。
1.2.3 长短期记忆网络。长短期记忆网络(long short memory network,LSTM)作为一种特殊的循环神经网络,用于解决对较长序列训练过程中的出现梯度消失与爆炸问题[13]。LSTM通过输入门、输出门和遗忘门的门控状态来控制传输状态,有选择地记住、遗忘或更新历史信息。其结构如图1所示。
LSTM的遗忘门用来决定遗弃细胞状态中的哪些信息,数学模型为:
式中:ft为遗忘门的输出;σ为激活函数,取值范围为[0,1];xt为 t时刻输入;ht-1为 t-1 时刻输出;Wf和bf为参数矩阵,下同。
输入门的作用是选择信息放入细胞状态中,数学模型如式(6)(7)所示:
式中:it为输入门输出;tanh同为激活函数,取值范围[0,1]。
在每次输出之前,需要更新信息,丢弃旧状态的某些信息,即:
式中:Ct为t时刻细胞状态。
最后,输出门控制信息输出,ot代表输出门的输出,数学模型为:
基于输入门、输出门和遗忘门组成的结构特点,LSTM具有了对历史信息选择性遗忘或更新的能力,能够更好地分析时间序列的变化趋势,从而实现筛选过去信息并且结合当前信息,预测未来时刻信息的功能[14]。
1.3 预测难点
在传统的时间序列预测中,多采用单时间序列,即预测某个要素就采用该要素的时间序列进行分析。而风向作为记录风吹来方向的气象要素,如图2所示,被划分为16个方位,数值变化呈圆形循环,正是由于其360°变化的特征导致了风向预测的困难。例如,0°~22.5°的风向和 337.5°~360.0°的风向在实际中差别不大,都可称为北风,但从算法的数值上看相差巨大。
在之前对风向预测的试验中,尝试了将标识的风向作为Label应用于机器学习,其得出的结果在实际中不符合逻辑:相差最远的标签在实际中却拥有相距最近的角度。使用时间序列分析,则避免了设置Label这一尴尬问题,算法分析均是基于历史数据,从变化趋势得到预测值。
为了进一步解决风向预测的难点并尝试新的预测方法,本研究针对风向的特殊性加入了风速序列,结合气象学中风向风速的转化公式,将其拆分成U、V风并分别进行预测,再将结果结合,以避免风向数值差异过大,进而与使用单一的风向序列预测结果进行对比。
1.3.1 风的U、V分量。传统的风向以东、南、西、北作为标识,转化到数值上为0°表示北风、90°表示东风。在气象领域,风场是由U、V风速分量来组成的二维场[15]。因此,可将传统的风进行转换,分别为U风和V风。U为东西风,即用U的正负来代表风为东风或者西风,绝对值代表此方向上风速的大小,U为正,代表传统意义上的西风,为负则代表东风;而V为南北风,正为南,负为北。在风速上,则是对传统风进行矢量分解。具体公式如下:
式中:S为风速;D为风向。
1.3.2 风向评分。为检验风向预测的效果,本文将16个风向方位简化为 8个, 即 0°~22.5°和 337.5°~360.0°记 为 北 风 、22.5°~67.5°记 为 东 北 风 、67.5°~112.5°记为东风,以此类推。这样既能满足需求,也简化了数据量,并采用了风向的预报评分FaWD,计算公式为:
式中:SCr为该站点预报的风向预报得分(表2),例如实况风向为90°、预测风向为30°,则得分为0.6,Nf为预报的总次数。这样既可以避免使用传统预测中的均方根误差进行评估而导致的结果混乱,还可以简化计算过程,在得出结果后就可以获得算法的评价。
为了使预测目标更具实际意义,同时更好地模拟冬奥会期间的实况,将风向的预测目标定为2019年2月4—20日共17 d每天8:00—17:00共10 h的风向,并将每天的预测得分进行平均再比较。

表2 8个风向的预报评分对照
2 结果与分析
2.1 单时间序列
对4个站点分别进行预测,结果如图3所示。将每天的评分进行平均(表3),可以看到XGBoost在4个站中都获得了最好的效果,相对ARMA最高可取得125%的提升效果(A1490),并且XGBoost在连续17 d中评分曲线较为平滑,相对ARMA在A1489中的评分呈上升趋势,却在A1490的2月4—10日中呈现极低的准确率,表明XGBoost相比传统的时间序列预测方法不仅在精度上有了较大提升,也更加稳定;LSTM在A1489和A1490明显优于ARMA,但在A1491和A1492的效果并不好,尤其在A1491的2月6日评分更是出现了0。具体分析这一日的预测结果,可以看到:此日的真实风向集中于230°~290°,属于设立的西风范围,而LSTM的预测结果包含多个方向,并不集中,从而导致评分为0;反而预测结果较为单一的ARMA却在此站获得了很好的效果,相对于在A1489和A1490低迷的表现,证明了ARMA方法在单一盛行风的站点可以获得较好的效果,而在复杂风场则效果不佳。
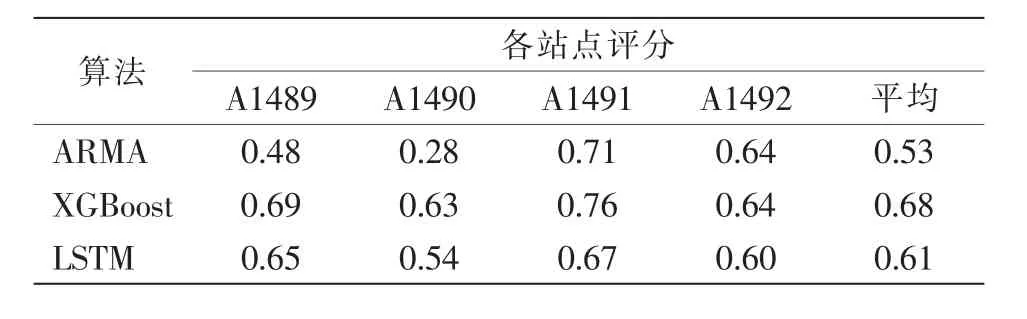
表3 单时间序列下不同算法在各站点的评分
从图3可以看出,随着海拔的升高,3种算法的效果越来越贴近,在海拔为2 099.8 m的A1492站点中3种算法的差别很小,折线几乎重合,证明结果与海拔存在关联。为进一步验证这种关系,将2月4—20日每小时的风向绘出散点图(图4)。可以看出,A1489站点的风向分布较为均匀,而A1491和A1492站点则在200°~350°分布较多,即站点盛行西风。这与李 炬等[16]在2020年对小海坨冬奥赛场的观测试验结果相符,同时也解释了3种算法的预测结果较为接近的原因:2个站点以西风为主导,在此基础上算法进行分析,预测结果会更加趋于西风,尤其是对ARMA这种非常依赖前期元素的预测模型。这也为后期的预测方法提供了思路,即先分析数据分布,探明数据规律,在算法预测基础上进行再次订正,从而进一步提高预测准确率。
2.2 双时间序列
双时间序列即将风向、风速序列转化为U、V风,使用算法对U、V风单独进行预测,再将其合成为风向,预测结果如图5所示。可以看出,采用双时间序列进行预测后,LSTM在A1491站点的2月6日评分为0的情况得到了解决并且获得了较高的评分,证明U、V风的转换对风向的预测有着积极作用。
将每天的评分进行平均得到表4,可以看到:XGBoost在风向预测中依旧拥有很大的优势,在A1489中相对ARMA最大能有115%的提升,4个站点平均后的得分达到了0.7,具有很好的效果;LSTM的效果优于ARMA、逊于XGBoost,这与使用单序列进行预测时相同。

表4 双时间序列下不同算法在站点的评分
相对于表3的单序列预测结果,使用双序列进行预测,XGBoost和LSTM都有提升,而ARMA基本没有变化。具体观察图3和图5可以看到,双序列预测A1489中ARMA评分在后几天的表现并不如单序列,但XGBoost在A1489和A1492中的评分相比单序列更为平滑。这表明将风速风向转化后,传统的时间序列统计方法过于依赖建模的数值,并不能分析出数据原来的变化规律,相对于ARMA来说U、V风是崭新的输入数据,而XGBoost和LSTM却可以采用这一方法得到提升,进而验证了此种方法的可行性。
3 结论与讨论
本文基于山区4个气象站点观测数据,结合时间序列分析方法,使用传统的ARMA分析、机器学习XGBoost方法和神经网络LSTM对4个站点特定时期的风速和风向进行了预测。为了获得更准确的结果,尝试将单一的风向风速序列转化成U、V风,分别预测,进而合成结果,从而避免风向的数值问题,结果表明:所使用的3种算法中,XGBoost不论是在预测精度还是稳定度上都优于传统的ARMA分析方法,而神经网络LSTM在时间序列的预测中并没有取得很好的效果,同时训练模型还需要耗费大量时间。风向散点图可以反映山区海拔较高的站点经常盛行一种风。由于山谷、山脊地形地势常形成这种盛行风,这也导致了在这几个站点算法预测评分的高度重叠。这同时也对风向预测提供了一种思路:在获得算法的预测结果后,可由预报员根据当地气候特征,对预测结果进行人工订正,以期获得更好的预报效果。将风向风速转化为U、V风并进行分析后发现,XGBoost和LSTM方法都有了提升,证明此种方法对提升风向的预测效果有着积极作用。尤其是XGBoost方法,在风的诸多试验中都表明了其可成为山区风向预报的可靠方法。
