基于关键字的海报自动合成系统
2022-03-08关帅鹏于海阳杨震周明赖英旭
关帅鹏,于海阳,杨震,周明,赖英旭
(北京工业大学 信息学部,北京 100124)
海报被视为一种强有力的宣传载体,在大众日常生活、生产管理及科学研究等领域扮演着重要的角色。主题明确、精心设计的海报不但能够吸引观众的注意力,而且对于主题信息的表达,也能够准确完整的呈现。海报设计中,使用图像编辑工具辅助设计,这与图像合成的理念十分契合,即从一张或多张图像中分割场景项并将其无缝地粘贴到另一张背景图像内,通过对图像、文字、空间等要素进行完整的结合,使得背景图像获得额外的信息传递效果。与普通图像相比,合成的图像能在时间和空间上获得额外的表述,能够更加完整地表达图像需求者的意愿。Johnson等[1]实现了一种图像合成系统,通过定义文字标注和文本元素区域的方式,把标注后的图像存入数据库,在数据库内检索相关图像并根据画布提供的位置信息合成目标图像,该方法从标注的数据库中检索图像,仅适用于风景类的图像合成,适用范围小,且用户无法自适应地改变图像合成结果。Chen等[2]使用手绘草图和文字标注的组合信息从互联网搜索引擎中检索图像,并将图像元素按照手绘草图中的布局信息拼接至背景的对应位置实现图像合成,该方法忽略了前景图像间的布局信息,最终合成结果中不可避免地会出现肉眼可见的逻辑错误。
海报图像合成主要涉及2个问题,即如何准确地获取目标图像,以及如何分割将其无缝地糅合到目标图像中。根据图像检索中启发性信息的不同,可将图像检索大致分为基于文本和基于内容的检索方法。基于文本的检索方法实质上把图像检索映射成文本检索的方式,对图像内容反映的信息理解进行文本标注,实现图像与文本的信息等价,通过文本检索实现图像检索。基于内容的图像检索方法不再使用文本信息作为描述符,而是结合特定算法提取图像颜色、纹理、轮廓等一系列内容特征,根据图像本身的内容进行检索,这种对图像检索的处理技术更准确。世界上第一个基于内容的商用图像检索系统是IBM的QBIC系统[3],该系统的语义识别是通过人工完成的,导致许多图像的度量化比较差。麻省理工学院也在基于内容图像检索领域研发了图像检索系统,即Photobook[4]。针对从源图像中分割场景项并将其无缝地粘贴到目标图像的问题,Agarwala等[5]提出了一个经典的、交互式的计算机辅助图像合成框架,框架包括2部分:使用图像分割(image segmentation)提取候选图形,紧接着使用图像融合实现无缝融合(seamless cloning)。在图像检索完之后,如何对图像进行分割处理也是重要的研究热点之一。Bezdek[6]在图像分割中使用了聚类的方法,通过图像像素间的相似程度把图像划分成若干区域子集,该方法的缺点在于大多数算法需要事先定义簇的个数(图像分割块数),并且特征选择单一,没有考虑像素的细节结构,分割效果不尽人意。Boykov和Jolly[7]利用图分割模型对能量函数进行最优化求解,提出了一种交互式图像分割算法,通过用户手动指定像素所属类,来实现图像的二值分割。在此基础上,Rother等[8]提出了GrabCut算法,该算法引入高斯混合模型对前景、背景元素进行建模,进一步简化了使用者的操作难度,降低了对图像分割的计算量。Felzenszwalb和Huttenlocher[9]在图论的基础上研究如何进行图像分割,提出了一种基于最小生成树的改进算法,将同一子图内部的差异性和子图之间的差异性相组合,实现像素在聚类时的自适应阈值选择,形成若干个彼此差异最大的临界子图,完成对图像的分割处理。图像无缝融合是指将2个或者2个以上的源图像进行糅合,达到对同一场景图像的完美表达。目前,比较流行的有基于Alpha和基于梯度场的无缝融合算法。Wang和Cohen[10]利用掩码分割目标区域,并将目标图像区域与背景图像根据α分量(图像透明度)进行叠加获得无缝的融合结果。在前景和背景图像光照和纹理特征相差较大时,Alpha融合算法将会产生明显的人工融合间隙。为了解决上述问题,Fattal等[11]提出了梯度域的图像编辑方法,通过求解图片梯度场和对比值的压缩,构建泊松方程的形式,实现在动态范围内图像的压缩。在此基础上,Pérez等[12]提出了泊松图像编辑方法,通过狄利克雷边界条件达到对泊松方程的求解。在保留前景图像梯度信息的同时,保证图像在梯度域上的连续,这样就保证了前景和背景图像间光照和纹理特征一致。
除上述2个典型问题,本文在系统中额外加入人像布局推荐来辅助对以人像为主题的图像进行构图设计。人像布局推荐是一个新兴的研究领域,前景人像区域和背景区域之间的位置、大小等布局信息关系到合成图像是否真实合理。人像布局推荐的目标是通过调整前景图像、背景图像间相对的大小、位置信息将前景图像毫无违和感地嵌入另一张背景图像中,使图像合成更真实。在图像编辑中,设计图像的布局结构属于开放性问题,具有一定的难度。Inaba等[13]利用场景间关系确定元素项位置,通过计算数据库中111个场景标签间距离,统计出关键字标签的概率分布,达到生成元素位置的效果。Bhattacharya等[14]通过学习大量用户数据来获取图像美学的支持向量回归模型,通过空间重组来提高照片的视觉美感,用于辅助用户改进图像的构图选择。Zhang等[15]通过构建大量专业照片提取代表美学空间构图的人像注意力和几何构图特征。根据背景的相似性,为新的背景自适应地挑选相似背景下的人像作为参考图像,实现人像姿态和位置的推荐。Wang[16]和Rawat[17]等在此基础上,收集上千幅构图良好的人像照片,从构图良好的图像中学习人像的审美构图规律,结合美学构图规则,同时利用背景内动态视觉元素实现版面平衡的方法,构建了一个辅助摄影系统来实现针对不同背景下的人像布局推荐。
1 系统描述
本文设计了一个基于关键字的海报自动合成系统,其整体框架如图1所示。按照合成流程可将系统分为以下3个阶段。

图1 海报自动合成系统流程Fig.1 Procedure of automatic poster synthesis system
1)图像检索阶段。主要是对目标图像的前景、背景图像的准备,用户通过提供关键字标签或文本信息来进行相关目标图像的提取,为后续图像融合提供素材。
2)图像布局设计阶段。用于辅助用户对人像元素进行布局设计,优化图像构图,保证图像信息准确快速的表达。考虑使用基于统计的正规则和基于美学的负规则进行双向的线性组合来量化背景下的人像布局评分,实现人像布局推荐。
3)图片融合阶段。是系统的最后一步,按照布局设计的方案将图像素材检索提供的前景和背景图像进行无缝融合即可实现图像合成。将无缝融合的结果返回给用户,以供用户选择。
系统需要建立2个数据库:第1个是通过互联网搜索引擎实时获取前景、背景图像的在线数据库,用于图像检索阶段;另1个是事先建立的离线海报数据库,用于图像布局设计阶段。根据上述对系统的分析,基于关键字的海报自动合成系统主要由以下模块组成:
1)图像下载。图像下载模块负责对目标图像、背景元素等的获取。系统依托互联网搜索引擎,根据用户提供的文本信息下载对应的图像数据,按照特定规则将图像存储建立数据库,为后续的复杂性过滤和一致性排序提供数据源。
2)复杂性过滤。复杂性过滤模块设置的目的是:一方面可以过滤错误图像,提升检索效率;另一方面还能消除内容复杂的图像,保证在后续图像分割和融合过程中产生更好的效果。
3)一致性排序模块。一致性排序通过提取图像内容的多维度特征,并对图像特征进行内容一致性排序来达到二次检索的效果,进一步提升检索的性能。
4)人像布局推荐模块。人像布局推荐可辅助用户进行海报的布局设计。从构图规律和美学常识的角度,为不同的人像与背景的组合生成恰当的布局备选。
5)图像融合模块。图像融合是将从前景目标区域无缝融合至背景图像中的过程,提供最终的海报合成结果。
本文将自动的图像检索和人像布局推荐作为系统的重点核心内容,将围绕上述各模块进行深入的分析和人性化的设计。
2 基于关键字的图像检索与融合
本文采用基于信息熵差的关键字提取算法[18]进行文本处理。该算法提出文章关键词是以聚类的形式存在的,按照每个词出现间距是否大于阈值划分为内外2种模式,通过计算2种模式下的信息熵差来实现关键字提取。
关键词标签一旦确定,通过互联网搜索引擎下载对应图像。在后续的工作中,将按照特定的标准分别处理背景和前景图像。首先,是内容一致性,即不论是前景还是背景图像,图像内容都应该与对应的关键字标签一致;其次,考虑内容复杂性,对于背景图像,图像内容应该尽可能保持简单,为前景元素的加入保留足够的开放空间;而前景图像涉及后续目标区域的自动分割,应该尽量选择算法自动分析相对可靠的图像。在图像下载过程的同时,对收集到的所有图像进行预处理,删除下载失败或像素较低的模糊图像,为最终的图像合成提供高质量的图像素材。
2.1 复杂性过滤算法设计
在进行复杂性过滤算法设计时,本文使用图的分割算法[9]来进行语义分割。该算法是一种基于图的贪心聚类算法,不仅考虑了同一子图内部的差异性,还考虑了子图与子图间的差异性。算法的关键在于像素聚类时能够实现自适应阈值。然后使用一种基于短连接的深度学习显著性检测算法[19]。该算法通过在HED(holisticallynested edge detection)架构内引入跳层结构的短连接,充分利用了从全卷积网络提取的多层次和多尺度特征,为每一层提供更高级的表征,实现在复杂区域捕获较为显著的物体。
对于背景图像,直接根据全图分割的段数对图像进行排序,返回复杂性得分。对于前景图像,首先判断显著性检测结果,如果图像内显著区域的数量大于3,则会被认定为过于复杂,将会直接被删除。然后将语义分割得到的结果和显著性检测得到的结果相组合,计算显著区域边缘的分割段数。前景图像的复杂性检测效果如图2所示。在这种情况下,若图像内任意一个显著区域边缘段数大于20,系统认为该图像背景复杂,直接丢弃。

图2 复杂性过滤过程Fig.2 Process of complexity filtering
对于前景图像而言,每个图像中可能包含一个或多个对象,因此对图像全局提取特征是不合适的。如果只对图像的目标区域提取内容特征,便可获取更为准确的特征描述。系统使用Grab-Cut来实现图像目标区域和背景的二值分割。GrabCut是以GraphCut图分割算法为基础改进而得到的交互式图像分割算法,其在分割初始化时加入了大量的用户先验知识和主观需求,从而实现更加准确的目标区域分割效果。图3展示了GrabCut的基本用法。用户需要使用矩形框手动标记前景区域即可实现图像分割,在分割的过程中,用户可根据主观需求对前景和背景像素进行额外的标注,以改善分割结果。
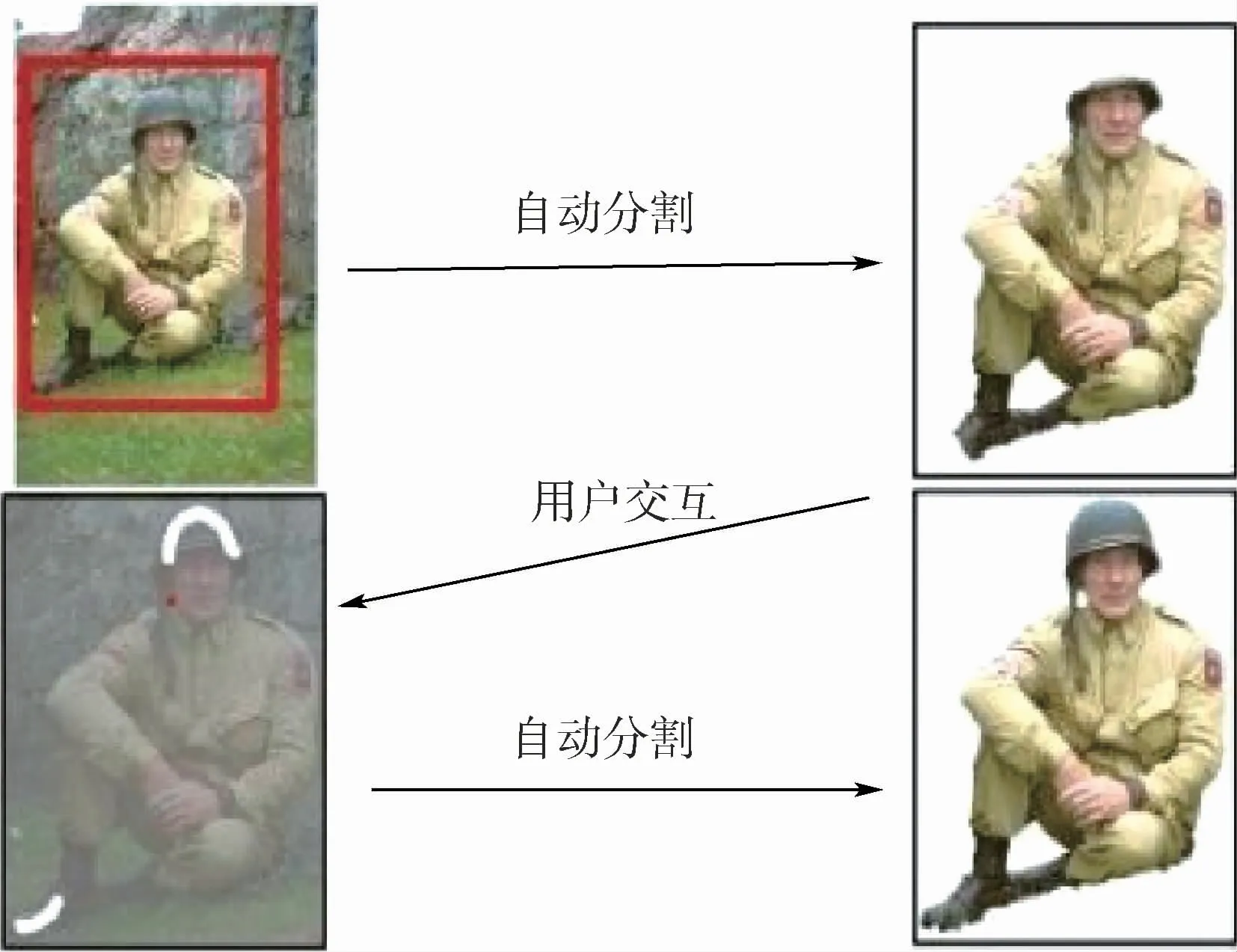
图3 GrabCut算法交互过程Fig.3 Interaction process of GrabCut algorithm
GrabCut采取RGB颜色空间,通过高斯混合模型对图像前景及图像背景中的像素进行建模。GrabCut算法用于分割的Gibbs能量函数定义为

式中:α为透明度系数,当像素为前景时取值1,为背景时取值0;k∈{1,2,…,k},k为GMM 中高斯分量的个数;θ={πk,uk,Σk},元素分别为每个高斯分量对应的权重系数、均值和协方差;U和V分别表示区域项和能量边界惩罚,计算式如下:
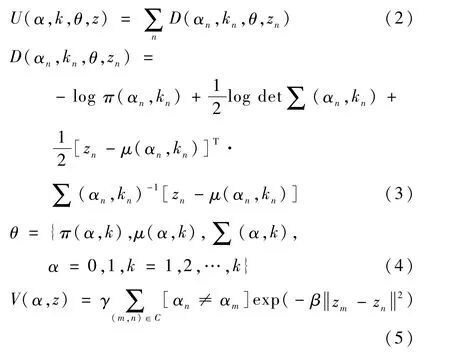
式中:参数γ=50;β由图像的对比度决定;区域项U用于表示透明度系数α对于像素的相似程度,可由所有像素D(αn,kn,θ,zn)求和得到,D(αn,kn,θ,zn)由式(3)计算得到,具体表示为该像素属于前景或背景的概率负对数;边界惩罚项V表示为邻域像素m和n之间由于不连续所带来的惩罚,通过像素m与n之间的欧氏距离,来对像素之间的相似性进行衡量,如果两邻域像素的相似性越大,说明领域像素处于同一背景或同一前景的概率越大,所对应的边界项表示的能量值则越小。通过不断进行分割估计和模型参数的学习,将Gibbs能量函数E降低到最小值实现最佳分割。
GrabCut是一种和用户可以交互的图像分割算法,考虑到该算法无法满足实时性要求比较高的场合,本文将显著性检测和GrabCut结合来实现图像自动分割[20]。首先,对原始图像进行显著性检测,通过设定适当的阈值获取显著区域二值图像。对于背景简单的图像,显著性检测的结果往往聚集在目标前景区域上,这也是使用复杂性检测过滤图像的目标之一。然后,使用图像的显著区域对GrabCut算法进行初始化,并重复迭代运行分割算法,实现目标区域的分割。基于GrabCut的自动分割算法训练过程可以总结如下:
1)使用显著性检测得到目标前景区域,并将目标区域形态学扩张10次。
2)使用目标区域对高斯混合模型进行初始化,目标区域外的其他区域设定为背景区域,区域内设置为待定的未知区域。
3)使用K-means算法将标定的图像前景和图像背景像素聚为k类,k为GMM中高斯分量个数,一般情况取5,初始化GMM参数θk={πk,uk,Σk}的值。
4)以最小化D(αn,kn,θ,zn)的规则判断每个像素所属的GMM分量。
5)根据式(2)计算区域项U(α,k,θ,z)。
6)根据式(5)计算边界项惩罚V(α,z),其中参数γ=50,β由图像的对比度决定。
7)构建s-t图,对图像使用最大流、最小割算法进行处理,得到能量函数E最小峰值。
8)迭代执行步骤3)和步骤7)直至收敛。
9)使用bordermatting平滑图像分割后的边缘,这样就实现了结合显著性检测和GrabCut的图像目标区域自动提取,目标区域的提取结果将会同源图像一并返回给用户,用户可以通过手动指定背景及前景像素的方式来修正图像提取结果。
GrabCut算法伪代码如下:

1:输入图像{I1,I2,…,IH}2:AimReg:rect←Significance detection method 3:Repeat:4:do:5:class k←clustering(foreground&background)6:GMM←initialize 7:Reg:U(α,k,θ,z),Bp:V(α,z)←calculate 8:cut_graph←maximum_flow(gr,source,sink)9:E←mix 10:while:函数收敛或达到迭代次数11:end循环12:使用bordermatting平滑图像分割后的边缘13:输出结果
2.2 一致性排序算法设计
在一致性排序算法设计中,检索结果的准确性取决于对特征的精确描述,特征提取的重点在于全面性和准确性。针对不同的应用场景,提出了以下3种图像特征提取方法:HSV颜色直方图特征、HOG特征及人像姿态特征。
2.2.1 HSV颜色直方图
本文基于HSV色彩空间建立颜色直方图。如图4所示,HSV颜色空间可以通过一个倒立的圆锥体来形象地解释说明,其包含感知三要素:色调(H)、饱和度(S)、亮度(V)。亮度对应图中长轴,从黑到白顺序表示像素明暗度;饱和度对应离开长轴的距离,是颜色的深淡度的体现;色调对应围绕长轴的角度,是影响人的视觉判断重要元素。

图4 HSV颜色空间Fig.4 Space of HSV color
颜色直方图是对图像的不同颜色区间统计的像素数量分布[21],其不考虑像素颜色的所处位置,仅与颜色在整幅图像中所占的比例相关。颜色直方图方法可定义为
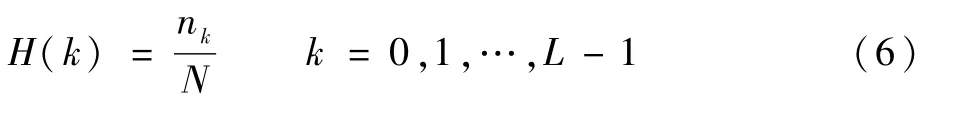
式中:N为在图像内的所有像素点总数量;nk为相同区间内的像素数量。使用HSV颜色直方图量化颜色空间可以按照以下步骤[22]:
1)根据人眼对颜色近似程度的视觉辨别能力,将色调划分为8个不同的区间,饱和度和亮度空间分别划分为3个量化区间。
2)根据像素所属色彩的范围对图像进行量化,此时每个小区间成为直方图的一个簇,这样色彩空间被量化成有限的离散级数。
3)按照转换式(7)将颜色空间三要素对应的向量参数合并至一维特征向量之中。

式中:Qs和Qv分别为分量S和V的量化级数,本文Qs=3,Qv=3。
式(7)即变化为

构成了 72 维向量的一维直方图:L[0,1,…,71]。之后进行归一化处理,就可以通过向量L来衡量图像的颜色特征。
2.2.2 HOG特征
梯度方向直方图(histogram of oriented gradients,HOG)算子是Dalal和Triggs[23]提出的一种基于统计图像局部梯度走向和梯度强度分布的特征描述符。HOG核心思想是:图像中目标物体边缘位置通常能够直观地反映像素梯度。利用梯度做直方图来进行信息的统计,这种方法能够直观地对区域目标的外在特征进行合理的反映。以64×64像素的图像I为例,对应的HOG特征提取步骤如下[24-25]:
1)图像分割。将初始图像等分为8×8的cell,并把4个相邻2×2的cell组成block。
2)色彩和伽马归一化。采用gamma校正方法对图像进行归一化,该操作能减低光线变化和图像的局部阴影所造成的影响。
3)计算每个像素的梯度方向和大小。该方法能有效地捕获了图像的轮廓和纹理信息,同时进一步弱化光照、阴影等因素的干扰。图像中像素点(x,y)的横向梯度H(x,y)及纵向梯度V(x,y)计算如下:
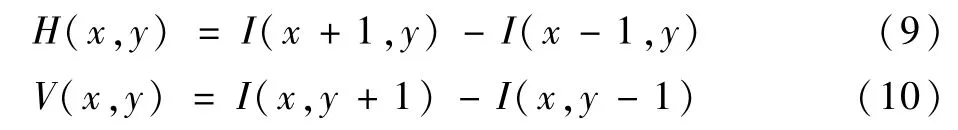
该点梯度大小G(x,y)和梯度方向θ(x,y)分别为
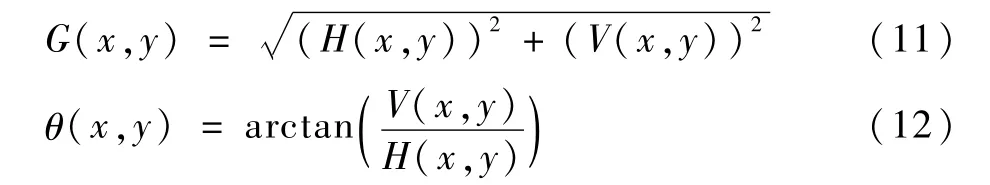
4)根据每个像素点的梯度方向,利用双线性内插法将cell内像素幅值累加到直方图中,并以block为单位把特征向量首尾相连。当把梯度方向均分为9块,即可得到一个64×9维的HOG特征向量。
2.2.3 人像姿态特征
人像姿态识别对于描述人体姿态、区分人体行为至关重要。姿态估计使用人体骨架的形式对一个人的体态进行描述。骨架是一组坐标点,通过对躯干、头部等的关键点识别,将其连接起来用于描述人物的姿态。为了提升人像图像的检索效率,本文使用开源人体姿态识别项目 Open-Pose[26-28]进行二维姿态检测。OpenPose是基于深度学习开发的开源库,可以实现对人脸关键点、人手的关键点及人身体的主要关节点的实时多人定位。图5为人体关键点示意图。每个人像的二维的姿态特征可由36维特征向量表示:
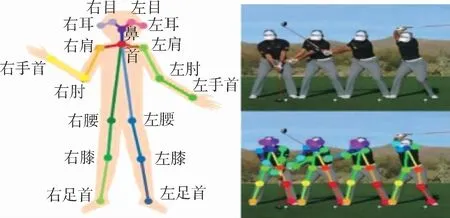
图5 人像姿态特征Fig.5 Feature of human pose
2.2.4 基于Meanshift的一致性排序
为了提高检索的精度和准确性目标,通过对图片内容一致性重新排序来达到目标。不同于常规的基于内容的图像检索方法,本文通过对候选图像进行聚类,使用簇中心代替示例图像,用户无需额外提供任何示例图像,即可通过关键字标签实现图像检索。
系统选择均值漂移(Meanshift)聚类算法进行聚类操作。Meanshift算法[29]是局部密度最大值的迭代梯度上升法,使用均值漂移向量代表样本中心点局部密度增长的最快方向,将收敛于同个局部密度最大处的样本划分为同一簇类实现数据聚类。Meanshift算法先在特征空间中随机初始化超球面,在每次迭代中,超球面都朝着均值偏移矢量的方向移动,移动过程中,所有出现在超球面内的数据属于此类的访问频率加1。均值偏移矢量的计算如下:

式中:yt为第t次迭代的球面中心;x为属于集合内Θ半径为λ的球面中的特征点。图6表示了Meanshift算法超球面初始化到收敛的过程。Meanshift算法通过引入窗口半径λ,避免事先定义聚类数量k,故Meanshift算法仅需定义参数λ即可实现聚类。超球面最终将收敛于局部密度极大值点,并通过判断当前簇中心在阈值范围内是否已经存在其他簇中心确定数据所属簇类,如果存在其他簇,将2类数据合并,否则当前簇中心成为新的聚类。当所有数据均被标记访问时算法停止,并按照簇类的访问频率划分数据归属簇类。通过Meanshift算法得到最大簇后,计算得到簇中心。按照簇内图像与簇中心之间的距离排序。对于颜色直方图而言,使用卡方距离相较于欧氏距离能够获得更好的检索效果。故针对颜色特征使用卡方距离重排序,卡方距离为
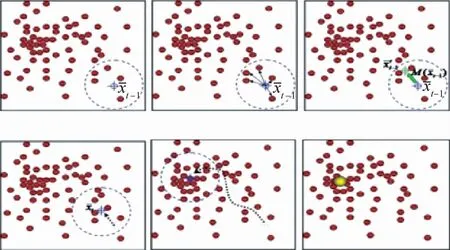
图6 Meanshift算法迭代过程Fig.6 Iterative process of Meanshift algorithm
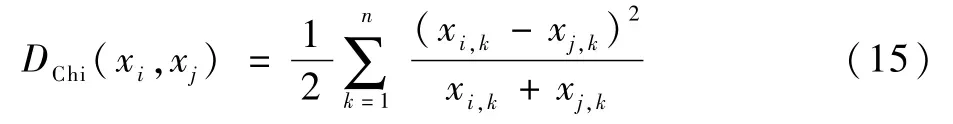
对其他特征使用欧氏距离排序,计算如下:

使用对应距离公式来表示内容一致性评分,将一致性得分标准化为介于(0,1)之间的值。这样每张图像都被赋予对应特征下的一致性得分。根据不同情况获取对应特征下的分数:对于背景图像使用颜色特征获取一致性得分,并与复杂性得分相结合作为背景图像排序的最终评分依据;对于前景图像同时建立HSV颜色直方图特征和HOG特征,如果目标对象是人物还将额外使用姿态特征,将图像特征对应的一致性分数线性组合,对数据集内图像进行一致性排序,按照排序结果返回图像,这样就实现了“从无到有”的图像检索。
2.3 图像融合算法设计
图像的无缝融合应该尽可能地保证合成的图像真实自然,减少明显的拼接痕迹。本文提供了Alpha融合和泊松图像编辑2种无缝融合方案供用户选择。
2.3.1 Alpha融合算法
Alpha融合是按照α向量(图像透明度)来混合前景像素和背景像素的图像处理技术。首先,把背景像素BP和前景像素FP按照RGB三个颜色通道分离,分别对各个颜色进行以下处理:将前景像素乘上α的值,同时把背景像素与α的反值相乘。然后,在对应的颜色通道上,将处理结果相叠加。最后,把求得的叠加结果除以α的最大值获取融合图像的像素值CP:

Alpha融合算法的效果很大程度上取决于前景图像的掩膜mask值,当前景图像的掩膜不够精确时,会导致前景图像边缘处的错误结果。此外,Alpha融合算法是在像素级别对图像进行操作,无法处理图像之间的色彩和纹理变化。当背景与前景图像的纹理差别很大,以及在不同的光照条件下,往往会出现明显的边界,产生不真实融合效果。
2.3.2 泊松图像编辑
泊松图像编辑是在梯度域求解前景和背景重叠区域的像素,利用前景区域的梯度和背景图像的边界值构造求解带Dirichlet边界条件的泊松方程,利用拉普拉斯算子插值重构重叠部分的像素。如图7所示,B和Ω分别代表背景图像和背景中的重叠区域,泊松图像编辑的目标是将前景图像的目标区域U无缝融合至背景B中,即求解融合后重叠区域Ω的像素值f。通过使边界∂Ω处梯度变换尽可能小,避免因过渡不自然而出现明显的融合间隙,实现真实自然的融合效果。
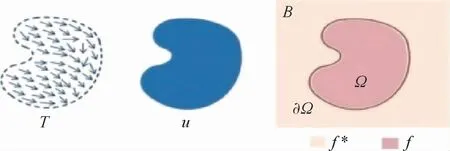
图7 泊松图像编辑原理Fig.7 Schematic diagram of Poisson image editing
为了保证图像融合后重叠区域内变化平滑及无明显的可见边界,重叠区域Ω内梯度变换应尽可能得平缓,即梯度应尽可能得小。因此,Ω内的像素值f应满足:

式中:Δ表示拉普拉斯算子。为了保持原图像的纹理特征,需要将梯度矢量场T加入到式(19)中,对当前的梯度域加以限制,这样就得到了扩展的最小值问题。公式更新为

最优解满足Dirichlet边界条件下的泊松方程:

式(22)是T=(u,v)的离散形式。在彩色图像的泊松编辑方程求解中,合成图像的颜色在不同通道将被独立构成一个泊松方程求解。Ω的边界满足:
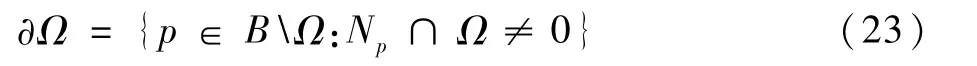
式中:Np为背景内像素p的四连通邻居集;<p,q>为p和Np内q的像素对。泊松方程就转化为了离散的二次最优化问题,如下:
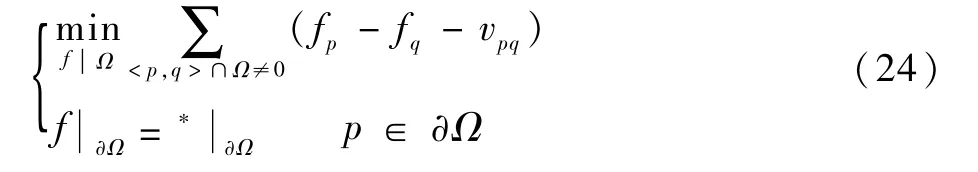
式中:vpq为T在[p,q]上的投影。根据最优性条件,其最优解满足:
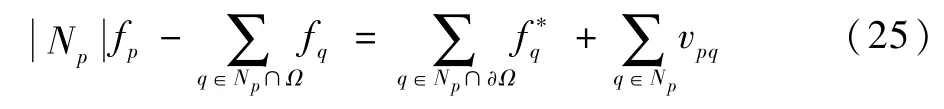
通过对线性方程求得的解为目标区域内的像素值,这样就实现了图像的无缝融合。
3 基于双向规则的人像布局推荐
同类型的电影海报具有相似的人像分布规律。基于这种考虑,本文建立基于统计的正规则,即从构图良好的图像中提取共通的构图规律。正规则建立的过程可概括为海报分类、使用高斯混合模型对各类别下人像分布建模和高斯混合模型参数估计3部分。
3.1 基于背景的海报聚类
先对海报进行聚类,再对不同类别的人像进行单独的位置建模,提取电影海报的布局分布规律。在此,考虑了多个方面的分类准则,如不同电影类别的海报应该具备独特的风格,大众审美会随着时间的推移发生变化,电影海报也会随着改变。电影的类别和时间线都可以作为电影分类的标准,但不论是电影类别的差异还是艺术认知的改变,人像分布和背景图像的内容特征都是紧密相关的。海报制作者在进行人像布局设计时,前景人像与背景图像之间的协调搭配都是应该考虑的第一要素。故选择依据图像背景内容特征对电影海报进行分类。首先,切除海报内人像和其他前景元素,使用内容感知算法填充背景上的空白区域。然后,建立背景图像的内容特征。考虑到有些海报内可能没有明显的显著元素,故考虑依据图像颜色特征进行分类。建立背景的HSV颜色直方图特征,并使用K-means聚类算法[30]对填充的背景分类。该算法的一个特征是每次迭代都需要计算所有样本与质心之间的相似度,在数据规模较大时,算法的时间开销比较大。
3.2 高斯混合模型构建
海报分类完成后,分别对每类背景的人像布局关系进行分析,在这里同时考虑人像的位置坐标和尺寸。建立一个生成概率模型来训练每个场景类别的位置、大小分布,使用高斯混合模型来拟合人像布局分布。高斯混合模型作为广泛应用的聚类模型之一,使用多个高斯分布作为参数模型,并将其线性组合来刻画数据的一般分布。对于任何场景类别I,本文将人像布局信息表示为x(I)=(x,y,r)T,其中(x,y)表示人物在图像中的平均位置,r表示人像的面部尺寸。给定场景Ik的人像布局x(Ik)的概率分布可以表示为
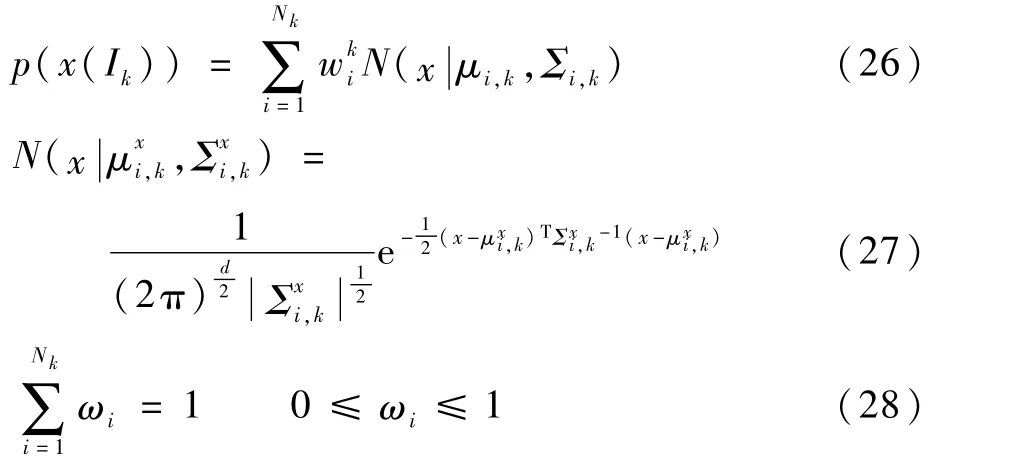
式中:N(x|μ,Σ)为高斯概率密度函数;wk、μk、Σk分别为混合模型中的第k维高斯向量的权重、均值、协方差矩阵。
3.3 高斯混合模型参数估计
本文使用贝叶斯信息准则[31](Bayesian information criterion)来估计高斯混合分量的数量。使用 最 大 期 望(expectation-maximization,EM)算法[32]估计所有背景类别的高斯混合模型参数(wk,μk,Σk)。EM算法是通过迭代进行极大似然估计(maximum likelihood estimation)的优化算法,通常用于对包含隐变量或缺失数据的概率模型进行参数估计。EM 算法包括2个步骤:E-step和M-step。在E-step计算中,通过评估对隐藏变量的现有估计值,计算E-step中最大似然估计值:

在M-step计算中,通过把E-step上求得的最大似然值最大化操作后,来计算参数的值。每个类的潜在变量平均值μk、协方差Σk和先验值wk更新如下:
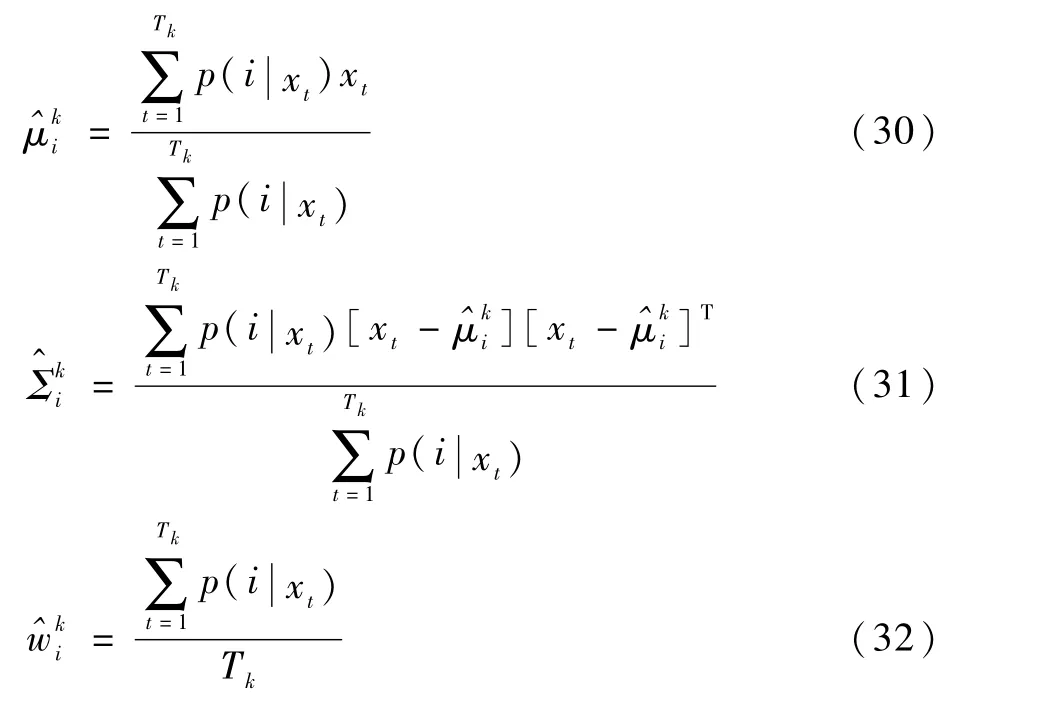
式中:Tk为给定场景类别Ik的海报总数量。Mstep计算更新的参数结果将被重新应用于E-step的计算中,2个步骤迭代的交替运行,模型收敛时的结果即可表示人像概率分布.
3.4 基于美学的负规则
不同的背景图像具备独特的特点,这些特点决定了不适合人像的位置区域。对于不同前景和背景的组合,人像布局推荐应该随之改变。本文受到摄影中美学常识的启发,总结建立了3条负规则[33]。
1)区域规则。指人像图像应尽可能少地覆盖其他前景元素和背景中的显著区域。区域规则确保了在构图设计时的前景元素间主次分明、简洁明了。如果前景元素间出现相互覆盖的情况,图像可能会出现视觉上的逻辑错误;而背景中的显著区域往往是相对重要的部分,表现了图像的视觉特点,人像与背景显著区域保留一定的空间。首先,使用本文设计的显著性检测方法检测图中显著区域。然后,通过式(33)量化显著区域负规则以评估显著区域与人像布局间的合理性。
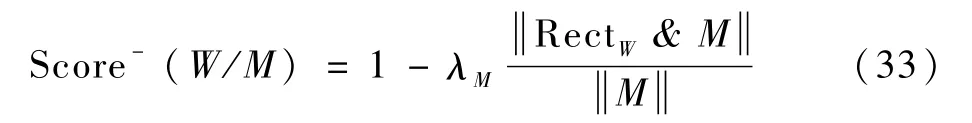
式中:M为显著区域的二元掩码,可由3.1节的方法生成,或者由用户手动标注;RectW为在位置W处放置时对象所占据的矩形区域;符号&为与操作,该操作计算对象所覆盖的突出区域。
2)直线规则。直线规则是指背景内的直线不应穿透人像的头部。画面中线条是构图的骨架,是整个画面造型的经络。画面中线条结构的走势能够很好地衬托照片内容的表现,起到美化照片的作用。本文采用霍夫变换(Hough transform)[34]检测背景中的长直线。霍夫变化被认为是目前最通用也是效果最好的直线检测算法。
图8展示了霍夫直线检测流程。首先,将图像中的所有像素点(坐标值)投影到参数坐标系下;然后,在参数坐标系中搜索极值点,确定代表直线的峰值点个数和坐标。当候选的线段被识别出来时,将归属于同一条直线的线段相连接,检测直线的起始点和终点。这样就实现了霍夫变换下的直线检测:
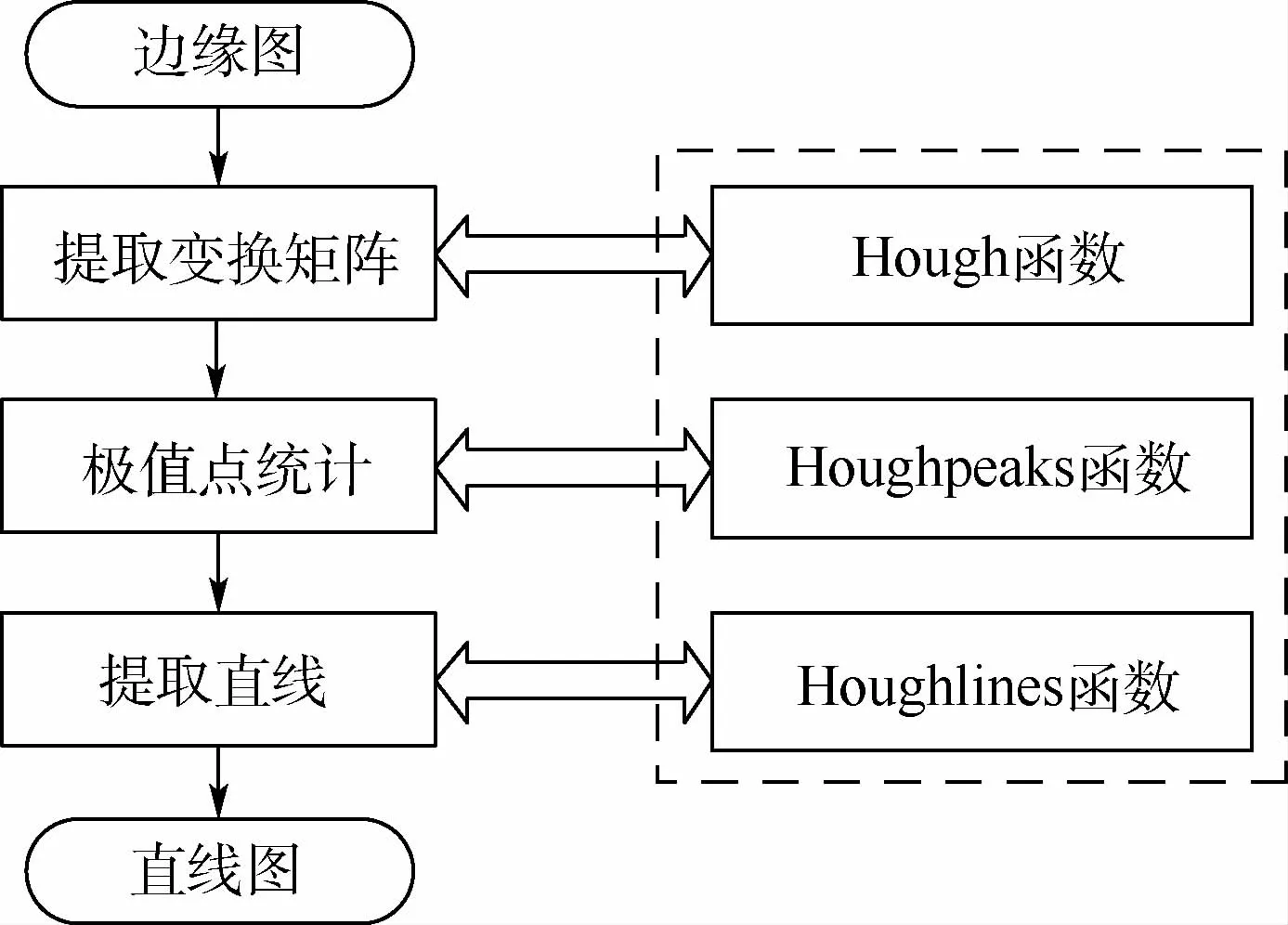
图8 霍夫直线检测流程Fig.8 Process of Hough line detection
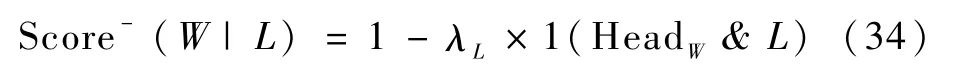
3)灭点规则。灭点规则是指人像主体不应该覆盖背景的灭点。在线性延展中,从起点出发,如果多条平行线向远处延展时,最终总是近似相交于一点,该点称之为灭点。灭点反映了图像深度的渐变和透视表现力,如果背景出现灭点,应尽量减少人像源点和背景灭点间的相互覆盖,避免影响以视觉感官为线性走势的空间次序。
二维空间中的灭点概念如图9所示,场景中的每一个灭点都有其对应的灭线,这样灭点检测就能转换为同组的直线检测。本文在进行灭点检测时,采用了J-Linkage算法。J-Linkage算法最初由Toldo和Fusiello[35]提出,属于多模型点聚类算法,是现阶段灭点检测中最优的算法。算法核心在于构造优先集矩阵及对矩阵的优化计算。优先集矩阵一般为N×M 的布尔矩阵,假定有N条直线集合和M 个灭点集合。优先级矩阵描述了每条直线和每个假设灭点之间的连续性关系。优先级矩阵优化迭代的过程就是对直线分类的过程。首先,判断不同直线间的优先级是否相交,将相交的直线直接划分为同类直线。然后,使用Jaccard距离合并不同类别下的直线。Jaccard距离可用于判断2个集合间的差异性,表达式如下:

图9 灭点概念Fig.9 Concept of vanishing point
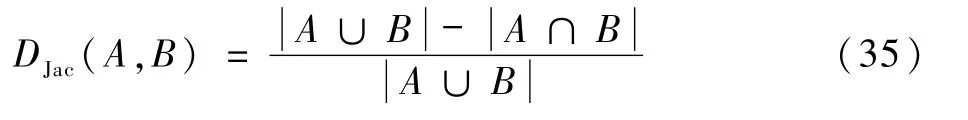
式中:A、B为2个不同的直线集合。通过计算优先集矩阵内所有直线集合间的Jaccard距离,将Jaccard距离最小的集合组合为同一集合。重复迭代上述操作,直到优先集矩阵内所有直线集合间的Jaccard距离均为1。这种情况下,所有直线集合间的差异化达到最大,也就实现了直线间的分类。

通过式(36)量化灭点规则以评估显著区域与人像布局间合理性。其中,Z表示灭点的二维坐标。
3.5 双向规则的组合
对于用户自己确定的背景图像,首先,提取图像像的HSV颜色直方图特征L,通过比较特征L与背景簇中心Ik,选择距离最小的簇Ik作为该图像的类别,根据该类别下的人像分布概率,根据式(37)计算出正规则得分。然后,检测图像内显著区域、直线和灭点,根据式(38)将3条负向规则组合构成负规则得分。
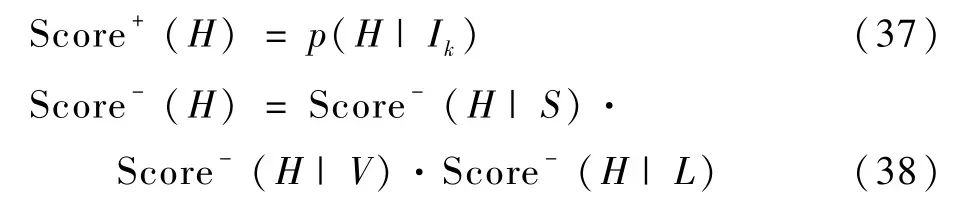
最终将正负规则结合起来,即可获得该背景下的人像布局得分:

只有当一个位置同时满足正规则和负规则,该位置才会获得一个相对较高的双向规则总分数,这个位置才会被推荐给用户。
4 实验与分析
4.1 基于关键字的检索与融合实验
4.1.1 图像检索效果测试
从互联网社交媒体中准确地发现图像是一个极富挑战性的研究热点。本文为了对系统进行有效的评估,采取人工分别对互联网直接返回的结果、复杂性方案过滤后的结果及内容一致性排序后的结果的假阳率(false positive rate,FPR)进行评估。假阳率计算式为

假阳率表示为负样本被识别为真样本事件发生的概率。为了验证基于互联网的图像检索方法的有效性,使用几个例子测试了图像检索系统。图10展示了本文方法检索的结果。本文的图像均来源于互联网搜索引擎,对于每个关键字标签,使用Google Image自动下载500张图像,经过复杂性过滤、一致性排序后返回前100张图像作为图像素材用于后续图像合成。如表1所示,在使用搜索引擎返回的前100张图像中,假阳率平均约为81%,即只有约19%的图像是符合目标预期的。经过图像复杂性过滤、和一致性排序后,假阳率分别降低至71%、26%。

图10 图像检索结果Fig.10 Results of image retrieval
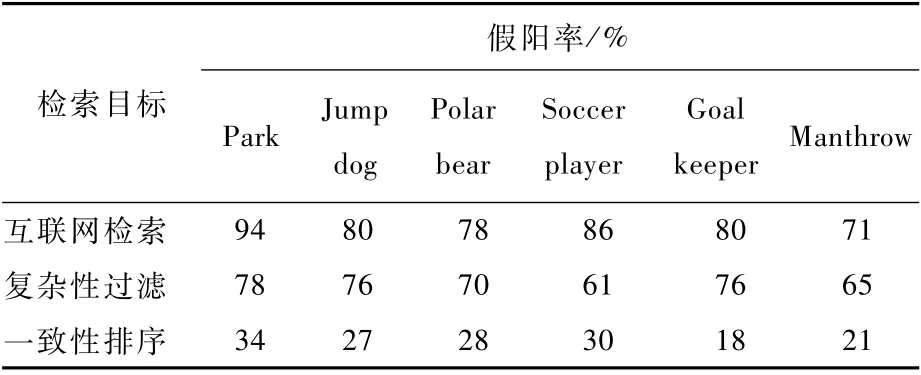
表1 图像检索结果Table 1 Results of image retrieval
对于前景图像,观察到复杂性过滤主要筛除了一些拼接的图像和少量背景复杂的图像,对于提升准确率而言表现的并不出色。然而,它对于一致性排序的提升却非常重要,因为它保证图像在自动分析时可以获得良好的分割效果,这对于内容一致性排序的提升是非常显著的。由于本文加入了姿态估计,在检索具有特定动作的人物,如“Goalkeeper”时检索效果也有所提升。另外,在使用互联网引擎进行图像检索时,适当的对关键字标签添加适当的动词或并列词,如“Manthrow frisbee”和“Jump dog”来获取目标图片是非常有帮助的。由于所有数据是依托互联网搜索引擎获取的,系统依然受制于初步检索的结果。例如,在检索某类人物时,将关键字标签定义为“Prince”,检索结果多是明星或现代皇室成员,这显然与用户预期不同。因此,推荐用户在检索过程中同时添加多个并列的关键字标签或根据返回的结果交互性地修正关键字标签来提高检索的准确率。
4.1.2 图像无缝融合效果测试
本节主要对图像融合算法的效果进行测试。图像合成包括图像目标区域的分割和无缝融合2步,本文提供了自动的图像提取,系统根据抓取结果主动生成前景掩码。如果用户对自动提取的结果不满意,可手动实现图像抓取。
图11为Cheetah和Polar bear的源图像、Alpha融合结果和泊松图像编辑的融合效果。可以发现,在面对不同的前景、背景组合时,2个算法都表现出了各自的特点。Alpha融合能保证源图像本身的特点不被改变,在图像的纹理或光照条件相差较大,会产生不真实的融合效果。泊松图像编辑能保持前景和背景之间保持一致的纹理及光照条件,这会导致图像发生失真的现象。在给出的2例融合结果中,采用的不同融合算法各有各自的优势,用户可以根据不同需求选择适合的场景进行融合,从而达到更好的融合效果。

图11 图像无缝融合结果Fig.11 Results of seamless integration of image
4.2 基于双向规则的人像布局推荐实验
4.2.1 人像布局推荐效果测试
在图像合成中,进行人像布局推荐是新研究的问题,采用了基于双重规则的人像布局推荐系统对背景图像生成人像布局推荐。首先,使用TMDB官方API收集海报10 000张,共收集以人像为主题的海报3 574张。然后,提取图像背景的HSV颜色直方图特征,并使用K-means将海报分为8类,利用高斯混合模型进行建模,对应类别下的人像概率分布如图12所示。

图12 人像分布Fig.12 Distribution of human position
根据3条反向规则,检测背景的显著区域、直线和灭点。图13展示了显著区域、直线和灭点的检测结果。需要说明的是,系统提供了手动标注的方式来修正检测结果。

图13 负规则检测结果Fig.13 Results of negative rule detection
将双向规则的最终结果得分图相加即可得到最终的推荐结果。目前,没有明确的指标衡量人像推荐结果,只能通过人工来评判推荐结果的合理性。系统将人像推荐的结果直接应用于图像合成中,辅助用户进行图像布局设计。
图14展示了正规则、负规则及双向规则组合下的推荐结果。默认情况下,系统会根据给定的前景人像关键字标签数量,自动实现对应的人像布局推荐。用户可在手动地添加非人像元素或对人像元素位置进行自定义的修改。每当一张前景图像加入到背景内,背景图像下的该区域将被定义为显著区域。这样就避免了人像之间与物体之间的相互重叠,预防最终合成结果由于图像间的覆盖而出现的逻辑错误。

图14 人像布局推荐结果Fig.14 Results of human position recommendation
4.2.2 系统整体测试
将图像检索、人像布局推荐和图像融合组合在一起,对整个系统的使用效果进行了测试。对系统的多个应用场景示例进行测试。最终生成结果如图15所示。①用户输入Cinderella的文本故事,根据关键字筛选结果,使用“Royalprince”和“Bride”作为关键字人物标签,将“Garden”作为背景标签。检索到对应图像后,将所需的物体抠取出来,并通过人像布局推荐结果将目标图像粘贴到了新的背景中。②用户直接输入“Manthrow”和“Jump dog”前景关键字标签,以及“Park”的背景关键字标签。其中,“Manthrow”为前景人物标签,“Jump dog”为普通的前景标签。③用户将“Ski man”设置为前景人物标签,“Polar bear”作为普通的前景标签,“Snow field”作为背景标签。④用户输入The Wonderful Wizard of Oz的文本故事信息,系统将“Little girl dorothy”、“Tin woodman robot”和“Scarecrow”作为前景关键字,将“Forest”作为背景关键字。其中,将“Little girl dorothy”设定为人物标签,其他均为普通标签。用户需要手动为普通的前景元素定义位置和大小信息,随着普通前景元素的加入,人像布局推荐结果也会随之改变。系统会自适应地为所有的前景人物推荐布局信息,并根据人脸的尺寸自动缩放图像,实现前景人物元素的自动拼接。从上述4个例子中可以发现,依靠本文系统能够根据文本信息“从无到有”地实现目标图像合成,并且所合成的图像十分真实自然。

图15 系统整体结果Fig.15 Final result of system
5 结 论
本文提出了一种基于关键字的海报自动合成系统,并设计了图像检索、图像布局及图像融合的具体方案。在图像检索阶段,本文设计了文本和内容的双重过滤方案,该方案采用复杂性过滤和一致性排序的方法实现从海量的图像库中准确快捷地检索图像的目的,降低了检索过程中的假阳率,为用户提供了精准快捷的图像检索手段。在图片布局设计阶段,本文设计了一种基于双向规则的人像布局推荐方案,该方案采用正负规则组合的方法提升了海报设计中人像布局中前景人像与背景图像之间的协调度。在图片融合阶段,采用显著性检测和GrabCut相结合的算法解决了GrabCut算法不能实时处理的问题,实现了图像实时高效的自动分割,并且提供了Alpha融合结果和泊松图像编辑的融合2种融合方法供不同场景选择。
