基于改进自适应聚类的无线传感器目标跟踪算法*
2022-03-08元昌安
苗 丽,元昌安,覃 晓
(1.广西经贸职业技术学院,南宁 530021;2.广西教育学院,南宁 530021;3.南宁师范大学,南宁 530001)
0 引言
随着传感器技术的发展,微机电系统和无线通信极大地促进了现代无线传感器网络(Wireless Sensor Networks,WSNs)的出现和发展。WSNs 通常由大量体积小、低功率、低成本的传感器节点组成,这些节点配备小容量、不可充电电池。WSNs 将人类、机器和环境之间的交互引入一个新的范式,WSNs 的快速发展促使其在许多领域得到应用,如环境监测、生物医学健康监测和军事目标跟踪和监视等。目标跟踪是WSNs 中最基本的应用之一。它的目的是检测目标的存在并对目标位置进行估计和持续跟踪。为了提高目标跟踪的精度,需要两个以上的传感器节点跟踪一个目标,这就需要一个协调策略,同时,要实现高精度的跟踪并保持能源效率是非常具有挑战性的,通常存在传感器节点能量有限,通信距离短,带宽低,处理和存储有限、大多数用于目标跟踪应用的WSNs 是密集的、稀疏的,并且部署复杂的环境中、相邻的传感器节点通常具有相似的数据、各种各样的噪声降低了目标的精度等问题。因此,如何尽可能地在降低能量消耗延长网络生命周期的同时提高跟踪精度是亟需解决的问题。
现有文献中用于无线传感器目标跟踪的算法和协议,基本上分为基于树的、基于预测的和基于簇的跟踪协议。在基于树的跟踪方法中,移动目标被传感器节点包围,当目标移动时,动态地配置树来添加和删除一些节点。文献[5]中提出的基于动态前馈生成树的跟踪算法,在预测目标方向上形成前馈树,目的是减少快速移动目标丢失的次数。基于预测的方法,基于历史数据来预测移动对象的下一个位置。文献[4]提出了一个基于预测的能源节约方案,该方案包括预测模型、唤醒机制和恢复机制。文献[6]中提出了一种扩展版本的KFs(EKFs)用于非线性目标跟踪。
基于聚类的跟踪方法中,网络被分成称为簇的小子集,一般分为静态跟踪和动态跟踪两种。在静态方法中,簇是在网络部署时静态地构建的。每个簇的属性(例如簇的大小、它所覆盖的区域以及它拥有的成员)是静态的。文献[7](EET)通过提出一个事件驱动的睡眠机制来降低能量消耗。但是,该算法存在调度消息带来的通信开销大的问题。在文献[8](GSCTA)定义了所有成员节点及其相关的leader 节点。虽然这种预先构建的簇为目标跟踪带来了简单性,但由于不同簇中的节点无法相互协作,对成员关系的约束会导致容错问题。在动态方法中,当事件发生时就会触发簇的构造,并且簇的属性没有限制。现有的基于动态簇的目标跟踪方法可分为分布式预测跟踪、自适应动态簇跟踪协议、动态簇头选择与条件再聚类、自适应簇头聚类算法。文献[9]提出了一种基于节点和簇头分离算法的运动目标分布式预测跟踪协议,算法为了保证能源效率和可扩展性,基于需要选择聚类形式。簇头使用一个目标描述符来识别目标并预测它的下一个位置。文献[10]提出了一种分布式的、可扩展的基于簇的无线传感器网络移动目标跟踪协议,该协议选择距离目标预测位置最近的传感器节点作为簇头。簇头根据数据有用性和能量消耗相结合的最优选择函数,形成具有合适传感器节点数的簇。文献[11]允许每个传感器节点根据数据检测和传输将消耗的能量来确定自己的激励。该激励值表示当新簇头持续存在时,传感器节点不考虑簇头的轮数。当前簇头节点根据每个传感器节点建议的激励机制重新调度下一轮将使用的簇头序列,从而减少能量消耗。自适应簇头聚类算法被提出,以解决资源约束和跟踪精度之间的权衡,通过利用聚类架构和可行的功率控制机制来实现。然而,自适应簇头聚类算法中主节点的选择机制仅基于检测传感器节点与移动目标之间的距离,不考虑节点的能量以及节点到基站的距离。事实上,这可能会导致传感器节点的提前死亡,从而降低网络的生存期。该算法的另一个缺点是当目标速度提高到10 m/s 以上时,随着目标的快速移动,形成的簇频繁地偏离目标,导致跟踪误差急剧增加。
针对这些问题,本文提出改进算法来优化自适应聚类算法。该算法首先采用动态聚类算法,通过考虑节点剩余能量、传感器节点到汇聚的距离和传感器节点到运动目标的距离3 个参数,最大限度地减少簇头与基站之间的远程通信,从而节约网络能量,延长网络寿命,降低目标漏失概率。在此基础上,加入预测机制,采用线性预测的方法预测运动目标的下一个位置,继而根据得到的预测误差,改变集群的大小和形状,从而减少参与跟踪过程的传感器节点数量,节约网络能量,保持合理的跟踪精度。仿真实验对网络能源消耗、跟踪误差和网络寿命进行分析,实验结果表明,与现有算法相比,该算法在考虑随机运动速度的情况下仍能准确地跟踪目标,且能耗更低,大大延长了网络的生命周期,从而表明本文所提算法的有效性和可行性。
1 系统模型建立
1.1 无线电波能量和信道传播模型
在本文中,假设使用与文献[13]相同的无线电能量模型。传感器无线电能量模型由微控制器处理、无线电发射和无线电接收组成。在发射机中,能量在运行无线电电子设备和功率放大器时消耗,在接收机中,能量在运行无线电电子设备时消耗。
在无线信道中,电磁波的传播可以被建模为发射机和接收机之间距离的幂律函数。此外,接收功率随着发射机和接收机之间距离的增加而减小。在模拟中,自由空间(视线直线)和多径衰落(双射线地面)信道模型的使用取决于发射和接收之间的距离。简而言之,如果发射机和接收机之间的距离小于一定的交叉距离(dcrossover),则使用自由空间传播模型(d衰减);否则,采用双射线地面传播模型(d衰减)。因此,k 比特数据包传输距离d 所需的总能量计算如下:

1.2 系统假设
对于本文所提出的算法,对网络模型的假设如下:1)无线传感器网络由大量的传感器节点和簇节点构成;2)传感器节点均匀分布在固定长度距离的正方形网格上;3)所有传感器节点具有相同的处理能力;4)簇节点位于无线传感器网络的中间;5)传感器和基站是静止的,传感器节点知道它们的位置坐标;6)每个传感器节点具有相同的传感和通信能力,所有节点的时钟是同步的;7)传感器节点使用双向链路在彼此之间和接收器之间中继数据;8)目标的运动行为是随机选择的,每个传感器节点一次只能检测到一个目标。
2 本文提出的算法
2.1 改进的簇头自适应算法
为更有效、更精确地跟踪移动目标,本文提出了改进的簇头自适应算法。该算法考虑了一个基于动态簇的架构,其中簇是根据移动目标的存在而动态形成的。算法的操作分为两组,一组低能量适应聚类层。每一轮有两个阶段:建立阶段和稳定阶段。在设置阶段,根据选举技术选择簇头,将在本节中进一步讨论。在稳态阶段,簇中的每个成员节点将数据传输到其簇头,簇头再将数据聚合并报告给基站。为了减少能量消耗,稳态阶段通常较长,然而,轮转时间是由基站在网络部署的初始时刻指定的。改进算法包括以下3 个阶段:初始阶段、目标跟踪阶段和主选阶段。
2.1.1 初始阶段
在此阶段,传感器节点均匀分布在网络区域内。在初始时刻,所有传感器节点都处于睡眠状态。它们只是定期唤醒并在短时间内(设置时间)进行检测。如果什么都没有发生,那么它们将在另一段时间内保持睡眠状态。如果任何传感器节点检测到目标,则启动目标跟踪过程。
2.1.2 目标跟踪阶段
在这个阶段,第1 个探测到目标的节点将使用多址访问(CSMA)协议向网络中其他节点或者更远的节点广播一条广告消息。此消息使检测目标的其他节点知道该节点被选为第1 轮的主节点,从而阻止这些节点发送其他广告消息。因此,主节点发送请求信息给其他所有与主节点一跳距离的邻居节点,将其作为从节点并直接形成一个簇。每个相邻的传感器节点发送1 个加入请求消息到主节点,其中包含位置信息,通知主节点将它作为从节点。簇形成后,主节点建立一个时分多址(TDMA)计划,并相应地发送给它的从节点,这一机制避免了发送消息的冲突。在所有从节点都知道TDMA 调度之后,每个检测目标的从节点会找到它的剩余能量并使用到TOA 方法计算它到目标的距离。该数据在分配的TDMA 时隙通过从节点数据消息发送到主节点。另一方面,主节点在从节点消息中获得数据且聚合自己的数据,从而计算探测传感器节点与基站之间的距离。主协议基本维护3 个列表:第1 个列表包含目标到检测传感器节点的距离;第2 种包含检测传感器节点的剩余能量;第3 个包含所述检测传感器节点与接收节点之间的距离。主协议使用这些列表根据以下公式来查找权重最大的传感器节点:

在weight表示检测待选为主节点的传感器节点的权重,E表示检测传感器节点的剩余能量,D表示检测传感器节点到基站的距离,D表示检测传感器节点到目标的距离。如果当前的主节点仍然拥有最高的权值,那么在下一轮中它仍将是主节点,并重新分配相同的从节点。否则,必须选择一个新的主节点。此外,在主节点中维护的第1个列表在定位算法中用于估计目标位置,稍后将对此进行讨论。估计目标位置后,主节点将估计的目标位置记录在目标存档中,然后通过簇节点消息发送给基站。
2.1.3 主选举阶段
主节点的选择非常重要,也就是说,它不仅仅影响目标跟踪的精度,同时影响簇的能量效率。因此,整个网络的生命周期可能会受到严重影响。在这个阶段,主协议选择拥有最高权值的节点作为新的主节点。当前的主节点向新选择的主节点发送一个MigrateMaster 消息,其中包含目标位置历史记录。然后由新的主节点执行从节点邀请、目标定位以及向接收器发送目标位置等操作。
下面显示了在选择主节点时使用的参数的描述:
1)节点剩余能量。任何节点的剩余能量都是基于节点在发送和接收过程中消耗的能量。因此,每轮传感器节点的平均能量计算公式如下:

主节点消耗更多的能量,因为它会传送3 类信息,包括InviteSlave,SinkData 和MigrtateMaster。第1个用于邀请从服务器,第2 个用于向接收发送目标估计位置,最后一个用于将主节点迁移到新的主节点。另一方面,从节点传输两种消息,即JoinRequest和slavedata。第1 个用于通知主节点,它将作为簇中的从节点,另一个用于向主节点发送从数据。据此,主节点和从节点两类传感器节点的剩余能量可以表示为:


其中,E和E分别表示主从节点的剩余能量,(n)表示从节点的数量,d、d和d分别表示主节点与从节点、接收器和新选出的主节点间的距离。
2)探测传感器节点与汇聚节点之间的距离,利用欧几里得距离公式:

其中,点(x,y)表示检测传感器节点的位置,(x,y)表示接收器的位置。
3)为了计算运动目标与检测传感器节点之间的距离,本文采用了TOA 方法。在本文提出的算法中,TOA 表示信号从检测传感器节点到运动目标的时间。因此,考虑到信号速度约为340 m/s,目标与探测传感器节点的距离可直接根据式(11)计算:
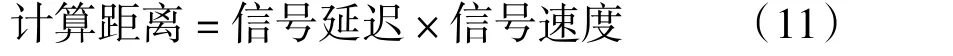
在一些应用中,可能会有障碍阻止传感器节点和目标之间的直接视线。因此,TOA 的读数可能受到影响。然而,在IAH 中所采用的定位算法与簇头自适应聚类算法相同,主要依赖于图1 所示的圆交原理。定位算法利用式(11)的结果,结合检测传感器节点的位置,得到一组圆方程:
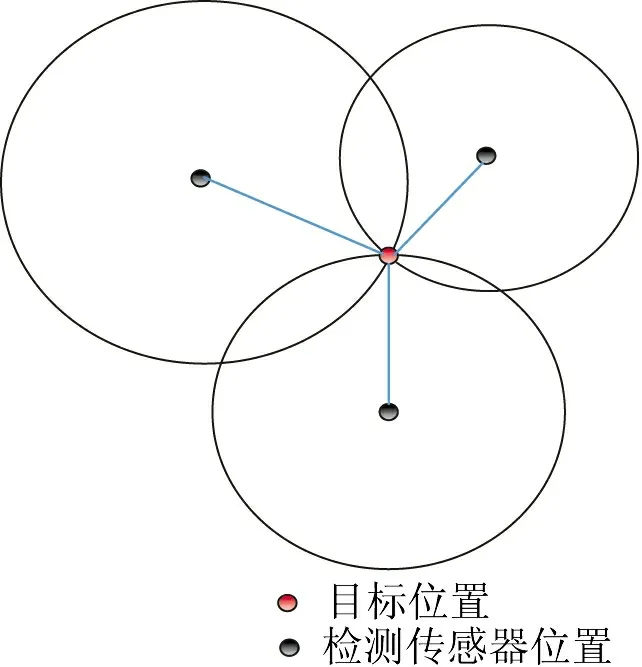
图1 利用圆交求目标估计位置

在(a,b)的位置检测传感器节点,每个传感器节点在网络部署时知道它的位置,r是检测传感器节点和移动目标之间的距离,n 代表所需的检测传感器节点且数量必须至少有3 个。则求解这组方程,得到目标(x,y)的估计位置。
在本文所提算法中,传感器节点一般按照图2 所示的状态转换模型工作。根据簇头自适应头算法的定义,每个传感器节点应该处于以下4 种状态之一:主、从、监听或休眠。然而,在本文提出的算法中,除了接收和发送消息的能力之外,接收者或从者状态还可以检测到其范围内的目标。该传感器处于侦听状态,可以检测到其范围内的目标,而不是其从邻近传感器接收消息的能力。当处于睡眠状态时,传感器无法检测目标或接收任何消息。因此,这种状态更省电。
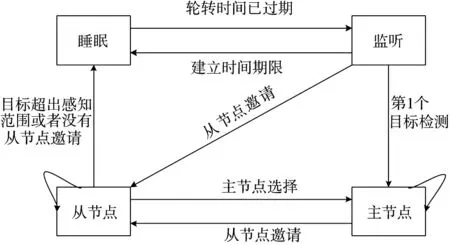
图2 算法中传感器节点的状态转移模型
2.2 基于预测机制的的簇头自适应算法
目标的运动是不确定的但通常遵循一定的物理规律。基于预测的方法能有助于优化能量效率和跟踪精度。因此,本文将基于预测的方法与2.1 节提出的自适应算法相结合,以提高算法的性能。基于预测的方法用于预测运动目标的下一个位置。利用了这一点,提出了一种节能的方法,在一定的误差阈值的基础上,可以有效地将形成的簇中激活的传感器节点数量减少一半。除此之外,所提算法为簇头的选择公式增加了一个新的维度,包括节点与预测位置的距离。本文采用线性预测方法,这种机制使用目标的当前和以前的位置来预测它的下一个位置。整个预测过程分为5 个步骤,这5 个步骤都是由主节点完成的。假设当前目标位置为时刻(t),则
步骤1:根据当前位置(x,y)和以前的位置(x,y)获得当前速度v 和方向θ,通过MigraMaster 消息发送,计算如下:


D表示预测位置和检测节点之间的距离。

3 实验与结果分析
3.1 参数设置
在Windows7 环境下的Intel core 2 Duo 2.20GHz和4 GB 内存上进行仿真实验。在本实验中,(24×24)传感器节点均匀分布在230 m×230 m 的二维正方形网格上。接收器位于位置(x=115,y=115),无线电电子能量设置为50 nj/bit,其中,无线电发射机能量设置为当距离小于d时,值为10 pj/bit/m2,如果距离大于d时,值为0.001 3 pj/bit/m2。相邻节点之间的定长距离设置为10 m。每个节点的感知范围为10×√2 m。每个节点初始为0.5 j 的能量。在本文提出的第1 个算法(改进的簇头自适应算法)的仿真模型中,簇由8 个从节点和1 个位于集群中心的主节点组成。在第2 种改进的算法中(基于预测机制的的簇头自适应算法),簇由1 个主节点,位于簇的中心,通过一定误差门限选择4 个或者8 个从节点。在两种算法中簇的形状均为正方形,用于处理簇压盖或者主节点与从节点之间的通信距离。
实验证明数据传输比数据处理和局部感知会消耗更多的能量。因此,在设计目标跟踪算法时必须充分考虑。在本文提出的算法中,传感器通过5个控制消息相互通信:InviteSlave、JointRequest、SlaveData、SinkData 和Migratemaster 消息。这些消息的格式基本上由以下5 个部分组成:头部用于区分控制消息和可能的上层使用,距离读数描述为被检测目标到检测节点的距离,目标位置历史记录读取显示主节点上先前接收到的目标位置的历史记录,预测读数表示目标的预测位置,剩余能量部分表示从节点的剩余能量。最后,主ID、从ID 和接收ID 分别表示主、从和接收标识符。利用仿真实验来评估本文算法的性能,主要使用3 个性能指标,包括能源消耗、网络寿命和跟踪误差。它们的定义如下:
1)能量消耗:表示仿真开始后传感器节点之间通信所消耗的总能量。
2)网络生存期:它表示从最初部署到网络中第1 个节点死亡的时间,以轮为单位计算。
3)跟踪误差:得到的估计位置与实际位置之间的欧氏距离的平均值,用于测量跟踪误差。
3.2 仿真结果及分析
本文使用多种场景来验证所提算法的性能。首先,研究了增加传感器密度对能量消耗的影响,增加传感器密度意味着减少所使用的固定长度的距离。其次,研究了改变传感器密度对跟踪误差的影响。第三,对比了不同的目标速度对跟踪误差的影响。第四,研究了扩大网络规模对能耗的影响。最后,研究了当初始能量变化时网络的生命周期。将本文所提算法与文献[12]所提簇头自适应算法进行比较,下文中Algorithm1 表示文献[12]所提算法,Algorithm2 表示本文所提第1 种算法,Algorithm3 表示本文所提第2 种算法。
3.2.1 能量消耗与传感器密度关系分析
图3 给出了文献[12]所提算法、本文所提算法1 和本文所提算法2 的能量消耗与传感器密度的对比。在这个图中,网络中的传感器密度从361 个节点到2 025 个节点不等。正如预期的那样,所有算法的能量消耗都随着环境密度的增加而增加,因为环境之间的距离越来越近,而形成环境变化趋势的可能性也在增加。因此,检测目标的传感器数量增加,从而消耗更多的能量。相对于文献[12]所提算法,本文所提第1 种算法的能耗降低了15%。实际上,这是由于在选择主节点时采用了一种新的准则,主要有助于缩短主节点和汇聚节点之间的通信距离。为了满足这个条件,每个从台只向主节点发送1 条控制消息,这足以估计目标位置并选择新的主台。因此,交换的控制消息的数量保持在较低水平。如图3 所示,在考虑所有密度值时,本文所提第2 种算法在能量消耗方面优于其他所有算法。相对于本文所提第1 种算法和文献[12]所提算法,本文所提第2 种算法的能耗分别降低了28%和43%。

图3 算法的能量消耗与传感器密度的对比
3.2.2 跟踪误差与传感器密度关系
在此情况下,通过仿真研究了传感器密度对跟踪误差的影响。图4 给出了文献[12]所提算法、本文所提算法1 和本文所提算法2 的跟踪误差与传感器密度的变化关系图。由跟踪误差的结果可以清楚地看到,文献[12]所提算法在目标低速运动(0 ~10 m/s)的约束下,跟踪误差取得了有趣的结果。事实上,主选过程只取决于目标的检测。随着目标移动的越来越快,形成的簇经常会错过目标,这反过来会导致罕见的簇形成,从而触发跟踪误差的急剧增加。另一方面,本文所提算法1 和本文所提算法2的跟踪误差(与门限45°)算法是稳定的。换句话说,目标速度的任何提高都不会对跟踪误差产生太大的影响,因为选择新节点采用了一种新的程序,如前所述,其中组合了多个参数,并相应地考虑了这些参数的最高权重。因此,降低了目标丢失的概率,从而提高了跟踪精度。本文提出的算法对目标速度在[10 m/s~16 m/s]范围内的跟踪误差提高了近52%。随着传感器密度的增加,传感器之间的距离越来越近,所以所有算法的跟踪误差都比较小,并且表现出相似的行为。这使得对目标的定位更加准确,从而使得动态形成的簇偏离目标的概率越来越低。
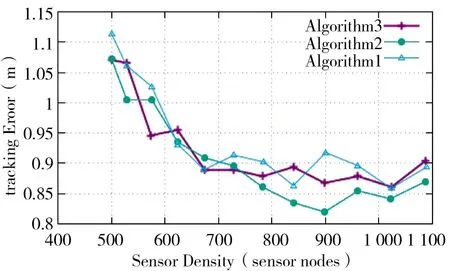
图4 算法的跟踪误差与传感器密度的对比
3.2.3 跟踪错误与目标速度的对比
图5 描述了所有可比较算法提高目标速度对比。
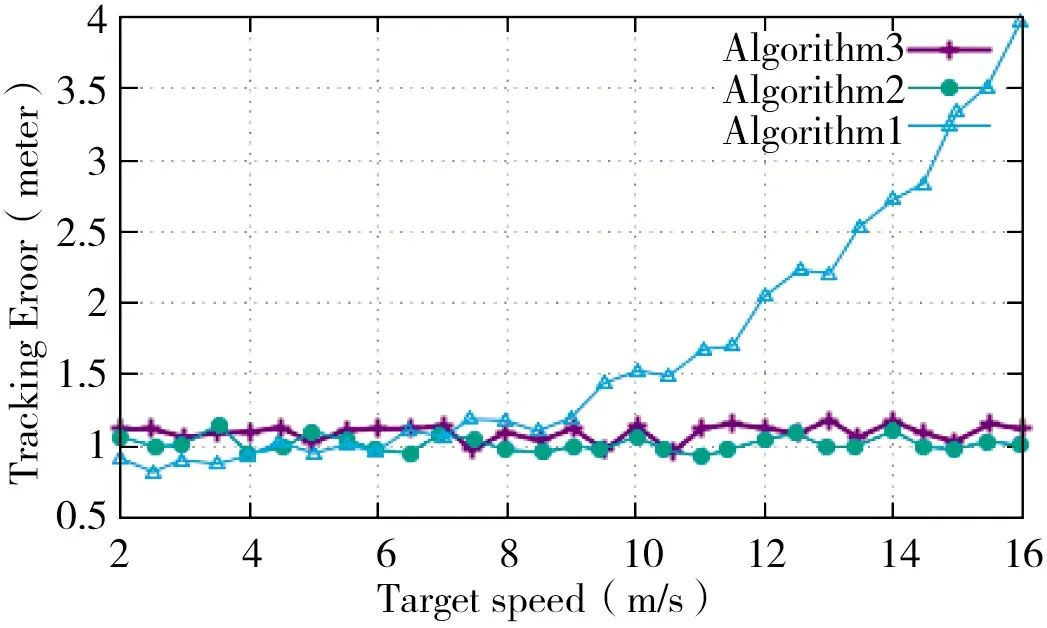
图5 算法的跟踪误差与目标速度对比
3.2.4 能源消耗与网络大小的对比
图6 描述了在考虑上述所有算法的情况下,增加网络规模对能耗的影响。网络中传感器节点密度保持不变(0.011 5 sensor/m2),而网络大小从(100 m×100 m)到(350 m×350 m)不等。首先,所有算法都具有递增行为,随着网络规模的增大,传感器节点之间的距离越来越远,数据传输的距离也越来越远,从而导致了大量能量的消耗。其次,本文所提两种算法的性能优于自适应头算法。因为主节点的选择过程得到了改进,这充分有助于在与基站通信时保持使用自由空间模型而不是多径衰落信道。最后,可以进一步观察到,本文所提第2 种算法在阀值为45°时,在能源消耗方面优于所有其他算法,分别减少了27%和40%。

图6 算法的能耗与网络维数对比
3.2.5 网络生命周期与初始能量
图7 描述了在网络生命周期中使用不同初始能量的结果。正如预期的那样,随着初始能量的增加,所有算法都趋向于拥有更长的生命周期。事实上,增加传感器节点的初始能量可以使其工作时间更长,从而使网络寿命更长。结果表明,本文所提算法的网络生存期比文献[12]所提算法的网络生存期要高。这是由于选择方法缩短了主节点和接收节点之间的通信距离。这样,在主传输期间消耗的能量就减少了,从而使网络的生命周期更长。这种新的选择方法不仅缩短了通信距离,而且通过将传感器节点的剩余能量作为参数插入到选择准则中来平衡传感器节点的能量消耗。因此,主节点在网络中的大多数传感器节点之间进行旋转。换句话说,不会频繁地选择同一个主节点。事实上,这可以降低传感器节点早死的可能性,从而增加网络的生命周期。同时随着初始能量的增加,本文提出的算法比文献[12]所提算法的轮数急剧增加,直到第1 个节点死亡为止。这是合理的,因为它提供了更高的能源效率。从图7 中可以明显看出,本文提出的算法的网络寿命比文献[12]所提算法至少提高了70%。
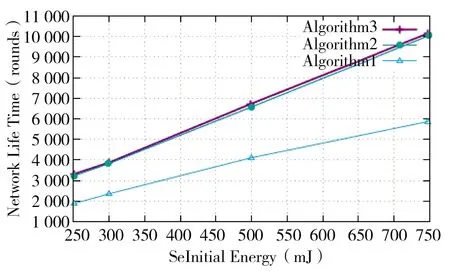
图7 网络生命周期与节点初始能量的关系
综上,本文所提出的算法通过优化主节点的选择和减少参与跟踪过程的传感器节点的数量,达到了更好的能效和跟踪质量。具体来说,第1 种算法增强了主节点的选择机制,考虑了节点剩余能量、传感器节点到汇聚的距离和传感器节点到运动目标的距离3 个参数。在第2 种算法中,采用了一种基本影响主选举过程和激活传感器数量的预测方法。换句话说,主节点的选择受1 个附加参数的影响超过了前面3 个描述节点与预测位置的距离的参数。根据所采用的误差阈值,参与簇形成的传感器数量可能会下降到4 个菱形(而不是8 个)。在能量效率和跟踪质量方面表明,在考虑不同网络密度、目标速度和网络维数的情况下,本文提出的算法取得了令人满意的性能,大大优于文献[12]所提算法。此外,目标速度的增加对两种算法的跟踪误差影响不大,而在自适应头聚类算法中,当目标速度增加超过10 m/s 时,跟踪误差急剧增加。本文提出的算法保证了网络的可扩展性,因为即使网络规模越来越大,它们也能很好地执行。
4 结论
本文针对无线传感器网络目标跟踪中跟踪精度与传感器节能问题进行研究,提出了基于预测的自适应头聚类算法,该算法首先采用动态聚类算法,通过考虑节点剩余能量、传感器节点到汇聚的距离和传感器节点到运动目标的距离3 个参数,最大限度地减少簇头与簇sink 之间的远程通信,从而节约网络能量,延长网络寿命,降低目标漏失概率。在此基础上,加入预测机制,采用线性预测的方法预测运动目标的下一个位置,继而根据得到的预测误差,改变集群的大小和形状,从而减少参与跟踪过程的传感器节点数量,节约网络能量,保持合理的跟踪精度。仿真实验对网络能源消耗、跟踪误差和网络寿命进行分析,实验结果表明,与现有算法相比,该算法在考虑随机运动速度的情况下仍能准确地跟踪目标,且能耗更低,大大延长了网络的生命周期,从而表明本文所提算法的有效性和可行性。
