基于类不平衡的软件缺陷倾向性预测研究
2022-03-07程雪平陈海华
程雪平,陈海华
(广州华商学院数据科学学院,广州 511300)
0 引言
软件缺陷是指软件系统中不被期望、不可接受的偏差[1]。软件缺陷的产生主要源于对软件需求做出了错误的理解,或者在设计、编码过程中,研发人员由于经验或技术原因引入的人为错误。软件缺陷的存在可能会导致巨大的经济损失,甚至会威胁到人的生命安全。
软件缺陷具有累积放大效应,即在整个软件生命周期中,能够越早地发现缺陷,其修复的代价就越小;反之,其修复的代价就越大。现代软件工程中,随着软件规模日益庞大,软件复杂度越来越高,软件开发的响应速度、用户对软件质量的要求均越来越高。如何合理分配有限的资源,及时发现、修复缺陷,是保证软件质量的关键。
软件缺陷预测是保障软件质量的重要手段,也是近年来软件工程领域的研究热点问题之一[2]。软件缺陷预测技术主要包括三个方向:一是通过软件度量元数据对软件模块的缺陷倾向性进行预测;二是预测模块的缺陷数;三是对缺陷严重程度等进行预测[3]。
软件缺陷倾向性预测技术是软件缺陷预测的重要研究方向,是对系统中的模块是否存在缺陷做出预判,有助于提前对软件测试的资源分配做好合理的安排,为软件质量提供坚实的保障。软件缺陷倾向性预测是一个不平衡的二分类问题[4],目前所使用的研究算法包括复杂网络、多目标优化、深度学习等,更多的是基于机器学习算法进行研究,如逻辑回归、朴素贝叶斯、决策树、支持向量机等算法[5]。
本文选取软件缺陷预测中广泛使用的数据仓库NASA MDP 中的部分数据集,对原始数据中的异常值和重复值进行预处理,然后使用三种不同的过采样方法处理不平衡类,最后根据特征数据采用随机森林算法构建预测模型。
1 缺陷倾向性预测总体方案
软件缺陷倾向性预测过程由四部分组成:获取软件缺陷数据资源库、数据预处理、处理类不平衡问题、构建预测模型及评价指标,总体解决方案如图1所示。
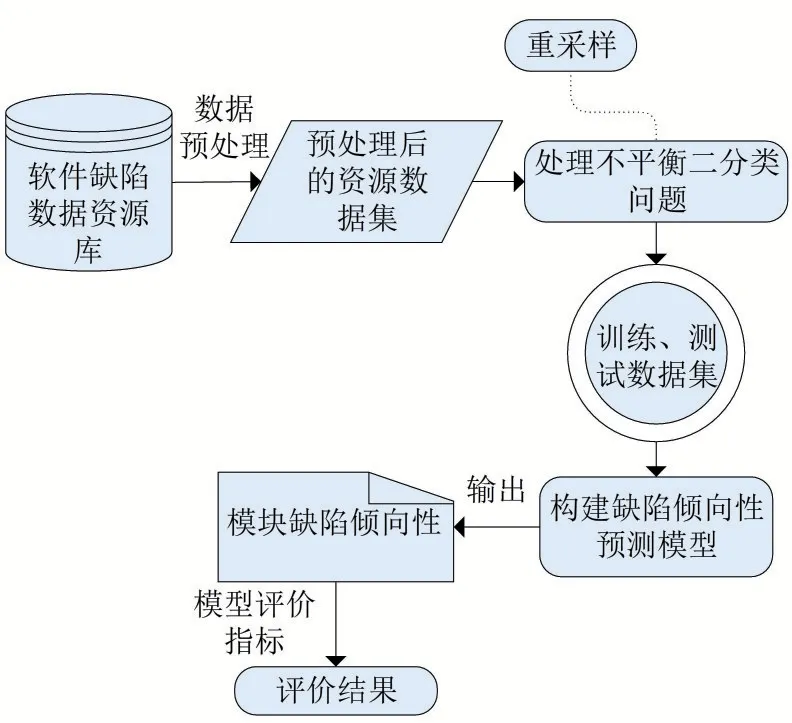
图1 软件缺陷倾向性预测方案模型
1.1 软件缺陷数据资源库
当前,用于软件缺陷预测的数据主要有两大类,包括商业性的数据仓库和公共仓库。商业性数据仓库难以获取,以这类数据源进行研究,其实验结果难以比较和重现,因此,研究人员通常利用公共数据仓库进行研究。较为常见的公共库包括NASA、PROMISE、AEEEM以及ReLink等,这些公共库中的度量元与缺陷信息都是可用的,有利于实验结果的重现与分析比较。
NASA库中总共包含13个缺陷数据集,其中,每个模块对应一条样本数据,无缺陷的模块数据以N为标记结束,有缺陷的模块以Y为标记结束,以CM1数据集为例,其数据结构如图2所示。
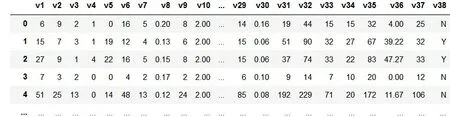
图2 CM1数据结构
本文选取NASA 库中前四个数据集作为软件缺陷倾向性预测实验数据进行分析比较:CM1、JM1、KC1、KC3。
观察软件缺陷实验数据集,无缺陷模块数与有缺陷的模块数相比,前者要多的多,这一现象与工程实践中的软件缺陷分布情况类似,即系统中的软件缺陷分布基本满足二八原则:20%的模块集中了80%的缺陷数。
图3 给出了CM1、JM1、KC1、KC3 四个数据集的有缺陷模块与无缺陷模块的计数饼图。

图3 实验数据集中有缺陷样本与无缺陷样本对比图
无论是工程实践,还是提供研究的公共数据仓库中,软件缺陷预测数据集存在着严重的类不平衡问题。在软件缺陷数据集中,由于有缺陷样本与无缺陷样本遵循二八定律,做缺陷倾向性预测时,若把所有模块预测为无缺陷,其模型准确度依旧会很高,但会严重影响软件缺陷倾向性的真实分类。
预测模型若将不同类的样本数据进行错误的分类,付出的代价有所不同。在软件缺陷倾向性预测中,如果将无缺陷的样本分类成有缺陷样本,会导致测试人员在进行软件测试工作时,将宝贵的时间资源浪费在无缺陷模块上;另一方面,若将有缺陷样本预测成无缺陷样本,则会出现缺陷漏报,缺陷漏报后把有缺陷的产品交付给客户,这将会产生无法估量的后果,甚至使得项目产生灭顶之灾。因此,在构建预测模型之前,需要处理软件缺陷数据集的不平衡问题。
1.2 数据预处理
软件缺陷倾向性预测数据预处理主要包括两个方面:一是对异常数据的处理,二是对数据集中的类不平衡问题进行处理。
基于机器学习的原始异常数据总体分为重复数据、缺失数据以及噪声数据[6]。重复数据指同一条数据在数据集中出现多次,这类异常数据的存在会使预测结果具有更强的倾向性。对重复数据的处理可以根据重复数据所占的比例进行降重,使其概率分布合理化。缺失数据指样本中某些属性对应的值缺失,这类异常数据存在的主要原因是信息的丢失。对缺失数据的处理,可以利用均值、极大似然值或者同类均值进行填充。噪声数据指与其它数据有严重偏离的数据,对噪声数据可以使用线性回归的方式进行替换。
本文首先利用散点图对异常值进行检测,而后通过上述常规方法对数据集中的异常数据进行处理获得异常数据处理后的数据集。对于类不平衡问题,可以从三个方面进行处理:数据处理层面、数据特征层面以及模型算法层面[7]。
数据处理层面解决类不平衡问题的主要思想是同对源数据集中的类进行重采样,从而使得小类样本与大类样本的数量之间趋于平衡。当前,重采样是解决类不平衡问题最直接的方法[5]。数据特征层面解决类不平衡问题的主要思想是自动化地选择不平衡类中具有良好区分能力的特征子集,从而提高小类以及整体分类的准确率。模型算法层面处理类不平衡问题主要有代价敏感算法、单类学习、集成学习等[8]。
本文实验主要用重采样方法处理类不平衡问题,并对不同的采样方法所产生的效果进行分析比较。重采样方法可以分为下采样和上采样两种。下采样方法也称为欠采样,指的是通过一定的算法,将大类样本中的部分数据剔除,从而使得大类样本数据与小类样本数据趋于平衡。欠采样采样方法处理类不平衡问题,可能会导致大量有用的数据丢失,从而导致模型存在欠拟合问题。本文主要使用上采样方法处理类不平衡问题,对下采样方法不做过多赘述。上采样也称为过采样,是指通过增加小类样本数量的方法与大类的样本数量趋于平衡。最为常见的过采样方法是随机过采样,即随机复制小类中的样本,这种方法的优点是简单便捷,但这样一来会造成对小类样本识别不足的过拟合现象。由此,SMOTE 过采样算法[9]被提了出来。
图4 描述了SMOTE 过采样算法生成新样本的过程。

图4 SMOTE过采样算法合成新样本过程
如图4 所示,SMOTE 过采样算法生成新样本的主要过程分为如下四个步骤:
(1)在小类样本中随机选择一个样本作为中心样本点;
(2)搜索与中心样本点距离最近的k个邻近同类样本;
(3)在(2)中选出的k个近邻样本中随机选择一个样本与中心样本点进行连线;
(4)在中心样本点与随机选择的样本连线之间随机生成一个新的小类样本数据。
由上述算法可知,虽然SMOTE 过采样算法相较于随机过采样有较大改进,但是在生成新样本时必须是成倍增加,如此便难以避免样本的重叠生成。基于此,有学者对基础SMOTE 算法加以改进,其中以borderline-SMOTE 算法[10]应用较为广泛。
borderline-SMOTE 算法将小类样本数据分为三类:Safe 样本点、Noise 样本点以及Danger样本点,Danger 样本指靠近分类边界的样本点。该算法对SMOTE 算法的改进之处在于其仅选用边界上的小类样本,即Danger 样本点合成新样本,避免成倍新样本的重叠生成,从而改善样本类别的分布。
针对软件缺陷倾向性预测的类不平衡问题,本文将对比使用随机过采样、SMOTE 过采样以及borderline-SMOTE采样方法的预测效果。
1.3 性能评价指标
当前,针对分类预测能力的评价标准较多,如准确率(Accuracy)、查准率(Precision)、召回率(Recall)、G-mean、AUC等,通常来说,它们的值越大越好,本文选择查准率、召回率和AUC[11]作为模型性能评价指标。
软件缺陷倾向性预测的结果是判断数据集中的每一个模块是否有缺陷,其取值要么为Y,要么为N,因此,这是一个二分类问题。对于二分类问题的结果,可以用混淆矩阵[12]评测。
混淆矩阵如表1所示。

表1 混淆矩阵
召回率反映分类器预测正样本全度的能力,即正样本被预测为正样本在总的正样本的比例,其计算公式如(2)所示:
在软件缺陷数据集中,标记为有缺陷的样本定义为正例,无缺陷样本为负例。因此,查准率P表示预测为有缺陷的样本中,真实为有缺陷样本的占比数。召回率R表示真实的有缺陷样本被预测为有缺陷样本的占比数。
AUC 值通常被用来评价一个二值分类器性能的好坏,ROC 曲线[13]以下部分的面积就是AUC,AUC 的值越大,表示模型预测效果越好。为了比较不同的采样方法处理软件缺陷数据集中不平衡类的效果,本文引入AUC 作为评价指标之一。
1.4 随机森林模型
目前,用于软件缺陷预测的模型算法众多,较为常见的有逻辑回归、决策树、朴素贝叶斯、随机森林等。经过前人大量实践证明,随机森林分类算法在多数数据集上具有良好的性能表现[14]。
随机森林算法[15]是一种集成学习算法,它以决策树为基础学习器去构建Bagging 集成。随机森林预测模型具有准确率高、简单、易于实现、计算开销小、性能强等优点。本文选择随机森林算法作为软件缺陷倾向性预测模型,可以比较不同的过采样方法处理不平衡类的性能表现。
2 实验分析
2.1 实验环境
本文实验环境主要包括SPSS modeler 18.0和anaconda3 下的jupyter,前者用来对异常值的检测与处理,前文提到的三种过采样算法以及随机森林预测模型算法的实现则是在jupyter 环境中利用Python语言编程实现。
2.2 重采样方案的选择
本文主要比较不同的上采样方法处理类不平衡问题的性能表现,因此在重采样方案中选择了三种不同的过采样方法观察预测效果:随机过采样、普通SMOTE过采样算法、borderline-SMOTE过采样算法。
图5 以数据集CM1 为例,给出了三种不同过采样方法的处理结果。
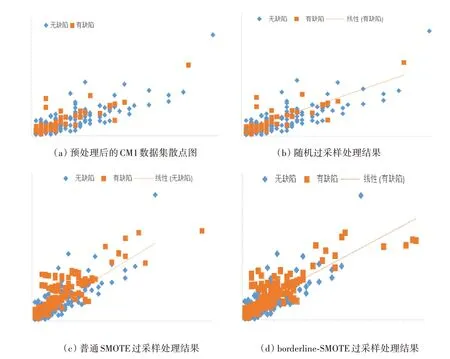
图5 不同过采样方法处理数据集CM1不平衡类的结果散点图
图5(a)是根据异常值处理后的数据集CM1绘制出的散点图,反映了CM1 数据集中有缺陷样本与无缺陷样本的分布情况,其中正方形散点代表有缺陷样本,菱形散点代表无缺陷样本。图5(b)是使用随机过采样方法生成新的有缺陷样本,使得有缺陷样本与无缺陷样本数量相当之后所绘制的散点图,虚线为有缺陷样本分布的趋势线,后同。
通过对比图5(a)与图5(b),其数据分布几乎没有任何变化,这是因为随机过采样所生成的新样本是简单的随机复制原来的小类样本数据,其所有新生成的数据点都与原来的样本数据重复,因此,两图的可视化效果一致。
图5(c)和图5(d)分别为采用普通SMOTE 过采样与改进的borderline-SMOTE 过采样处理CM1数据集之后的有缺陷样本与无缺陷样本的分布情况。实验中,SMOTE 过采样与borderline-SMOTE 过采样的k近邻参数均设置为5,后者的danger 样本类近邻数设为10,从图中结果可知,SMOTE过采样合成的新样本有大量的重叠现象,相比较而言,borderline-SMOTE 过采样所合成的新样本分布情况更合理。
2.3 实验过程数据
针对类不平衡处理后的数据集中的每个样本,使用随机森林模型进行缺陷倾向性预测。为了降低数据的过拟合问题,在模型预测之前,对于每一个数据集,选择70%的数据作为训练数据集、30%的数据作为测试数据集进行训练。
在类不平衡问题中,往往对小类样本的预测结果更为重要。同样,在软件缺陷的倾向性预测中,对有缺陷样本的检测相对来说具有更为重要的现实意义。表2中的实验数据为随机森林模型预测不同数据集中有缺陷样本的性能指标。
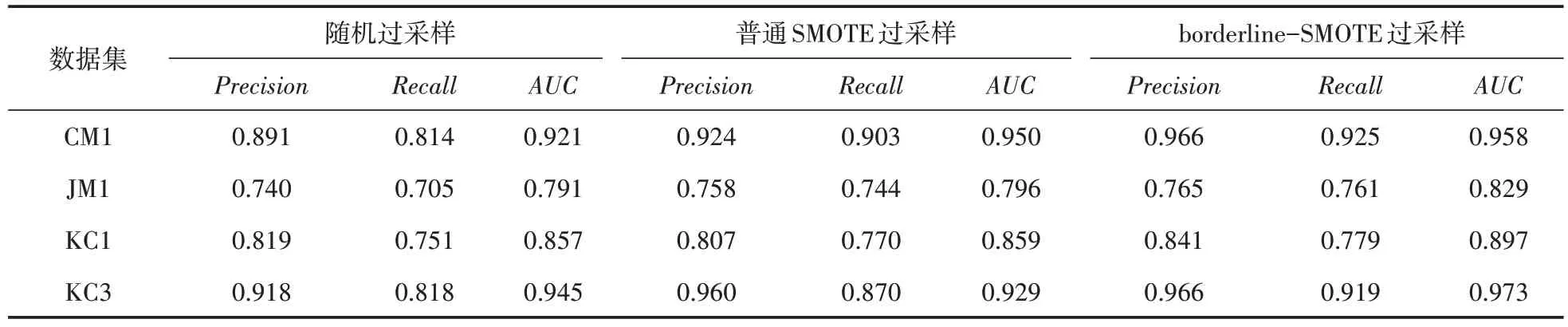
表2 三种过采样算法评价指标数据对比
为了避免一次实验结果带来的偶然性,本文在每个数据集的预测模型上均进行了10 次实验,最终的评价指标数据取10 次实验结果的平均数。
2.4 实验结果分析
根据上述实验结果绘制折线图,能够更加直观地对比出三种过采样算法处理类不平衡问题后预测软件缺陷倾向性的效果。
图6是三种过采样算法处理类不平衡问题后采用随机森林模型预测后的查准率(Precision)值的对比,其中最下面的点状折线代表随机过采样算法对应的值,中间的纯实线折线代表普通SMOTE 过采样算法对应的值,最上面的虚线折线代表borderline-SMOTE过采样算法对应的值。
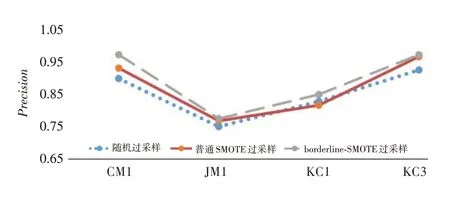
图6 Precision值对比图
图7代表的是三种过采样算法处理的召回率(Recall)对比折线图,不同形状折线代表的含义与图6相同。
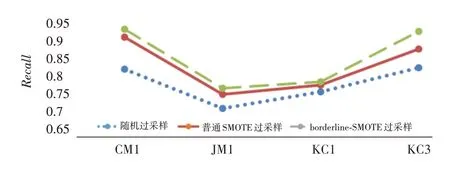
图7 Recall值对比图
图8表示的是AUC值的对比图。

图8 AUC值对比图
从实验结果来看,针对软件缺陷数据集中的类不平衡问题,采用不同的过采样算法进行处理,对软件缺陷倾向性的预测效果会有所不同。在少数评价指标上,随机过采样算法偶尔会稍优于普通SMOTE过采样算法,但整体而言,SMOTE过采样算法的性能表现优于随机过采样算法,borderline-SMOTE 过采样算法明显优于普通SMOTE过采样算法以及随机过采样算法。
3 结语
近年来,软件缺陷预测是一个较为热门的研究领域,软件缺陷倾向性预测是其中之一。软件缺陷数据集中的类不平衡问题较为显著,要对软件缺陷倾向性进行预测,必须解决类不平衡问题。本文采用不同的过采样方法处理缺陷数据集中的类不平衡问题,然后选择随机森林模型预测各数据集中样本的缺陷倾向性,并通过最终的预测结果,利用查准率、召回率等性能评价指标对比了不同的过采样算法处理缺陷数据集中类不平衡问题的最终效果。
后续的工作中,将针对软件缺陷数据集中的类不平衡问题进行更深入细致的研究,并将研究如何更好地利用机器学习算法对软件缺陷做出更精准的预测。
