基于机器学习和单站地面气象要素的雷电临近预警方法
2022-03-05赵生昊覃彬全杜乐
赵生昊 覃彬全* 杜乐
(1 重庆市气象安全技术中心,重庆 401120; 2 重庆市地质矿产勘查开发局,重庆 401121)
引言
雷电防护可以有效减少雷电灾害造成的人身伤亡和经济损失。在雷电防护中,除运用防雷装置对目标进行直接防护,对雷电活动进行预警预报并采取主动措施减小损失也是当前普遍采用的防护手段。雷电临近预警指提前时间为0~2 h的雷电预警[1],近年来国内外学者在该方面开展了深入研究。吕伟涛等[1]结合雷达、闪电定位系统、电场仪等多种观测资料,利用区域识别 、跟踪和外推算法与决策树算法,建立了雷电临近预报系统。张烨方等[2]根据预警对象与闪电定位数据的距离判定关系,并引入雷达阈值控制优化,建立了一种基于闪电定位数据的雷电临近预警模型。琚泽立等[3]、徐伟等[4]基于大气电场仪数据,通过对电场信号的模态分解或重构,分别实现了雷电临近预警方法。Mecikalski等[5]通过结合雷达、GEOS卫星系统和数值模式,实现了一个集成的0~1 h初闪预警框架,能够在暴雨发生前30~45 min发出预警。
以上研究普遍使用了气象卫星、雷达、大气电场仪等专业气象探测设备取得的资料,一些更是需要建立中心化网络,推广应用门槛较高,相比之下小型自动气象站技术成熟、成本低廉,在能源、交通、农业等行业已有规模化布设。本研究旨在充分利用单站气象要素和闪电定位资料,结合知识发现和机器学习方法,建立多参数机器学习模型,探讨一种灵活的、基于单站气象要素的雷电临近预警方法及其可行性。
1 数据与方法
1.1 数据来源
本文所使用的单站气象要素资料由重庆市气象探测数据平台提供的接口获取,对应资料名称为重庆自动站地面5分钟资料, 该资料包含重庆35个自动站器测地面气象要素。综合考虑数据连续性和站点地理分布、海拔高度情况,从中选取了8个站点作为研究站点,站点分布如图1所示,资料选取时间跨度为2017年6月至2019年12月,形成的数据集称为地面要素数据集。
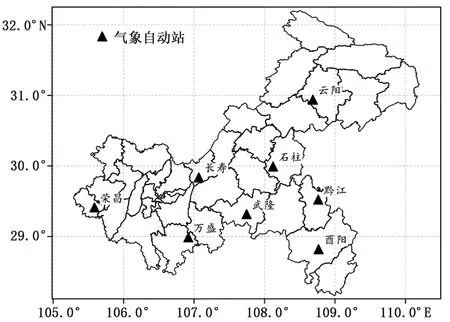
图1 重庆市8个站点地理位置分布
闪电定位数据来源自重庆市闪电定位系统,该系统于2007年基于ADTD闪电定位网络搭建,包含重庆市内5个测站及周边省份的8个测站,能够实时记录地闪回击的发生时间、地理位置、强度等信息,网内理论定位精度优于300 m。取全市范围内2017年6月至2019年12月之间的闪电定位资料形成数据集,称为闪电定位数据集。
1.2 特征向量选取
气压、温度、湿度和风是严格意义上的4种气象要素[6],当雷暴过境时,各气象要素均会发生变化[7-8]。本文选取地面自动站测量的站位气压、气温、相对湿度、风速作为特征向量,虽然所选特征只能反映雷暴涉及的地面气象要素,不能代表与雷暴关系更紧密的高空气象要素,但与高空气象要素相比,地面气象要素的测量更为可靠、连续,数据的获取也更容易、及时,目前各类自动气象站都能够观测。
1.3 数据清洗
对于地面气象要素数据集,因其已经过质量控制,仅通过箱线图分析删除了站位气压异常(小于873.2 hPa)的记录,通过经验删除了温度异常(小于-10 ℃)的记录。
根据ADTD定位系统探测原理,其二站定位采用磁定向交汇法,受地形所限定位精度较低[9],另由于云闪干扰,ADTD对于10 kA以下回击探测能力较差[10],因此将闪电定位数据集中定位方式低于3站和电流强度绝对值小于10 kA的记录删除。
1.4 标签向量设置
以20 km为半径对8个站点进行缓冲区处理(Lambert Conformal投影,中央经线105 °E, 标准纬线25 °N、47 °N),将气象要素数据集逐行对应缓冲区与ADTD数据集进行地理相交运算,在相交运算结果中筛选出观测时间t0之后0~10 min、10~20 min、20~30 min 3个时间段内发生的地闪活动,如果筛出的地闪活动大于等于1次,则将对应标签设置为1,反之则设置为0。如此便得到了3组标签向量,即Ati(i=10,20,30),例如数据集中某条记录对应的观测站点为万盛,观测时间为2018年7月15日11:10:00,At20=1,则表示在当日 11:20—11:30这10 min内,万盛站周边20 km范围内有地闪活动发生。
1.5. 性能评估指标
根据《GB/T 38121—2019 雷电防护 雷暴预警系统》[11],相应观测事件与预警列联关系如表1。衡量雷暴预警系统主要性能的参数有2个,其中虚报率(FAR)由虚报数和总警报数之比确定,FAR越小越好;预警失败率(FTWR)由漏报次数和应报警总数之比确定,FTWR越小越好。

表1 雷电观测事件与预警列联表
在雷电预警中,显然我们最为关注有效警报,但虚报率过高会引起不必要的操作,影响预警效率,因此本文还引入了机器学习中的F1作为性能衡量指标,其定义为准确率和召回率的调和平均,即
(1)
F1值越大,分类器性能越好,其最小值为0,可以看出,仅当FAR和FTWR同时接近于0时,F1接近最大值1。
1.6 研究方法
以At10为标签,分别统计了8个站点的标签向量类别分布,将标签为0的类别称为地闪不活跃类别,标签为1的类别称为地闪活跃类别,统计结果如表2所示。从表中可以看出,地闪不活跃类别与活跃类别(不平衡)比最大为307,最小为115,根据前文中标签的设置,本文对雷电的临近预警可以看作是不平衡场景下的二分类问题。
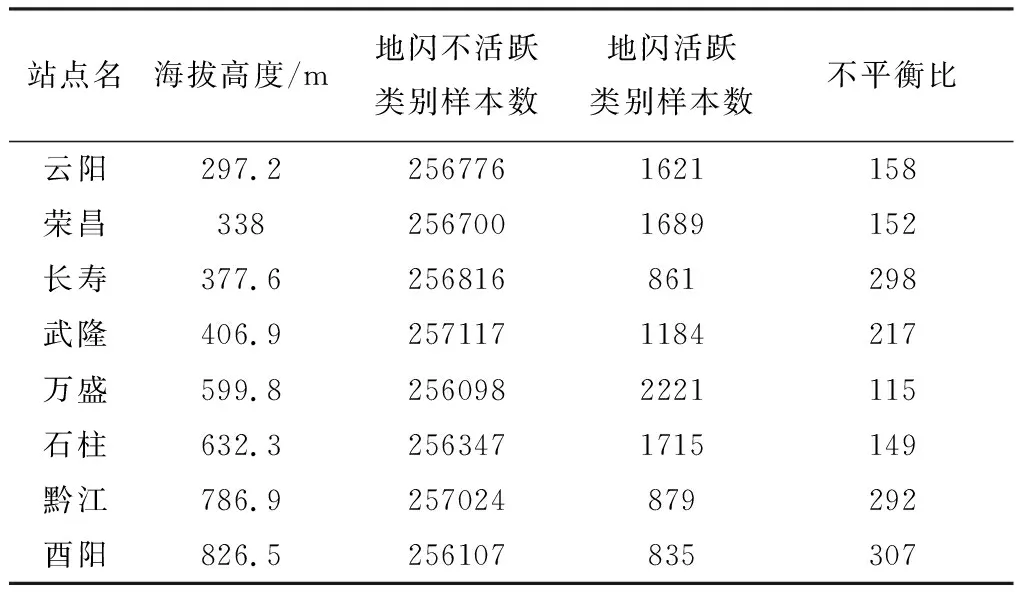
表2 重庆市8个站点海拔高度及2017年6月至2019年12月At10标签地闪样本类别分布
不平衡学习是机器学习中的重要领域,常见的解决方法有设置无偏评价指标、重采样、代价敏感学习等[12],如前文设置的F1就是一种无偏的评价指标,其评价结果不会受不同类别中样本数量所影响。重采样技术则使用通过一些采样机制来改变原始数
据集的分布,使得处理后的数据集分布平衡,从而解决不平衡学习的问题。重采样技术可分为3类:欠采样、过采样与组合采样,在实际应用中,重采样技术的效果因数据形态及分类器的不同存在较大差异,在一些情况下甚至不如直接使用分类器训练。
通过表2中分析,本文拟使用海拔及不平衡比率均差别较大的荣昌、黔江两个站点,以At10为标签,形成2个数据子集,并将每个子集按比例分为训练集和测试集。首先使用多个基线分类器(默认参数)对2个测试子集进行训练并用5折交叉验证评估其准确性,其次在不同的重采样方法下重复上一步骤,在此基础上挑选出性能(F1Score)最好的重采样方法和分类器组合,并使用参数搜索方法调整重采样及分类器参数以得到最佳模型,最后在测试集上验证模型并对于研究区内所有站点做出整体分析。
本文所涉及的分类器有K最近邻(K-Nearest Neighbors,KNN)、决策树(Decision Tree,DT)、随机森林(Random Forest,RF)、极限树(Extra Trees,ET)、XGBoost(eXtreme Gradient Boosting),其中KNN、DT属非线性算法,RF、ET、XGBoost属集成算法;涉及的重采样方法有随机下采样(Random Under Sampling,RUS)、Edited Nearest Neighbors(ENN)、SMOTE、ADASYN、SMOTE and Edited Nearest Neighbors(SMOTEENN),其中RUS、ENN属欠采样方法,SMOTE、ADASYN属过采样方法,SMOTEENN属组合采样方法。本文在前期工作排除了一些明显不合适的分类器及采样技术。
2 结果分析
2.1 观测时间特征处理
使用核平滑函数对荣昌、黔江两个数据子集进行了各特征向量概率密度估计,得到图2。首先,对于两个子集,气压、气温两种特征分离度较好,相对湿度及风速分离度较差;其次,两子集各特征概率密度分布总体较为近似,但在气压概率密度分布上差异较大,如荣昌站点地闪活跃样本集中发生于960 hPa 附近,黔江站点则集中在920 hPa左右,明显与两站海拔高度差异有关。
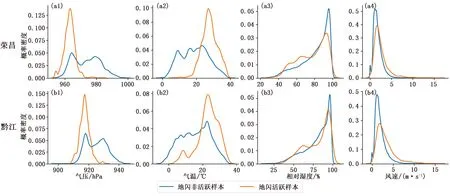
图2 2017年6月至2019年12月荣昌、黔江自动站地闪样本对气压(a1,b1)、气温(a2,b2)、相对湿度(a3,b3)和风速(a4,b4)概率密度估计
由于可分离特征较少,有必要补充特征向量,除气象要素外,雷暴活动在时间分布上也具有鲜明的特征,巩崇水等[13]利用1981—2010年雷暴观测资料,对中国年平均雷暴日的时空分布特征进行分析,结果表明中国年平均雷暴日的时间分布表现为夏季多、冬季少;一天之中雷暴出现的时间集中在下午到晚上。因此将地面气象要素观测时间中的月份和时段列入特征向量,并利用三角函数将其分解为正弦和余弦两个分量,即
(2)
(3)
(4)
(5)
式中,m、h分别为观测月份和观测时段,msin、mcos及hsin、hcos分别为m及h的正、余弦分量,处理后的月份及时段特征在12月至次年1月,23:00—00:00之间更为连续,符合月份、时段的周期性特点。
2.2 分类模型选择
按8∶2比例将荣昌、黔江数据子集分为训练集和测试集,分别基于4特征向量(压、温、湿、风)和8特征向量(压、温、湿、风及观测月份、时段正余弦分量),使用KNN、DT、RF、ET、XGBoost 5种基线分类器对训练集进行5折交叉验证,各基线分类器均使用默认参数。性能对比结果如表3所示。
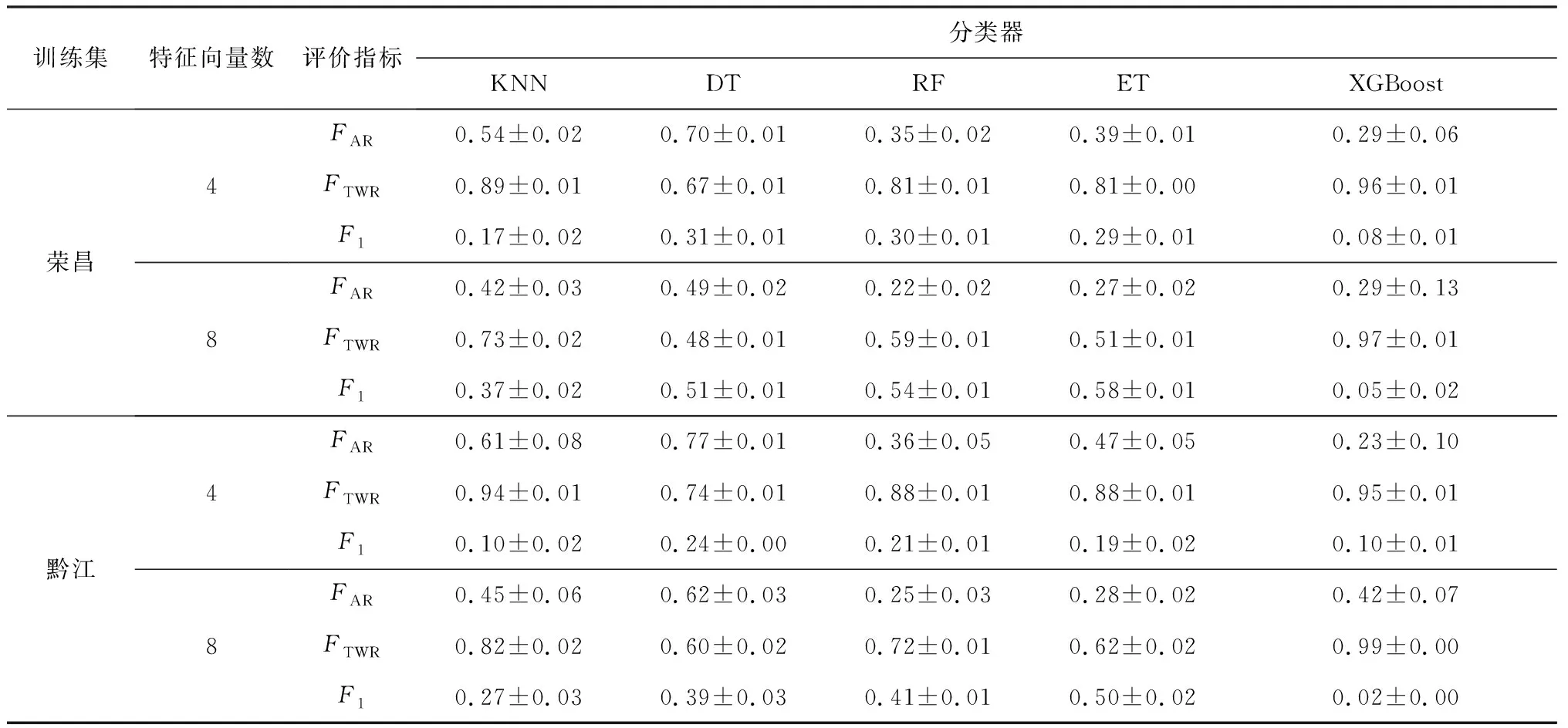
表3 2017年6月至2019年12月荣昌、黔江训练集在4特征向量及8特征向量下基线分类器性能
从表3中可以看出,对于两种训练集,首先,基于树的集成分类器取得了较好的性能,其中极限树分类器性能最好,F1分别达到了0.58及0.50,KNN及XGBoost分类器在本数据集上性能较差;其次,除XGBoost分类器外,8特征向量相对4特性向量分类性能提升巨大,以ET分类器为例,对于荣昌和黔江训练集分别具有100%和163.16%的性能提升。
在分别在使用RUS,ENN,SMOTE,ADASYN,SMOTEENN 5种采样技术对两个训练集(8特征)进行重采样后,再重复前一步骤,性能对比结果如表4所示。从表中可以看出,欠采样方法性能较差,在随机欠采样后,各分类器性能甚至普遍不如未采样(即表3中8特征向量分类性能);组合采样方法性能相对未采样有了一定提升;过采样方法性能最好,尤其在ADASYN重采样下,各分类器性能普遍达到最好;而在各重采样方法下,仍然是ET分类器性能最好。综合来看,虽然荣昌、黔江两站的地理位置,海拔高度不同,数据集不平衡比率相差悬殊,但基于上述方法得到的最佳分类模型同为ADASYN-ET,性能相比未采样的ET分别提升了10.34%、18%。
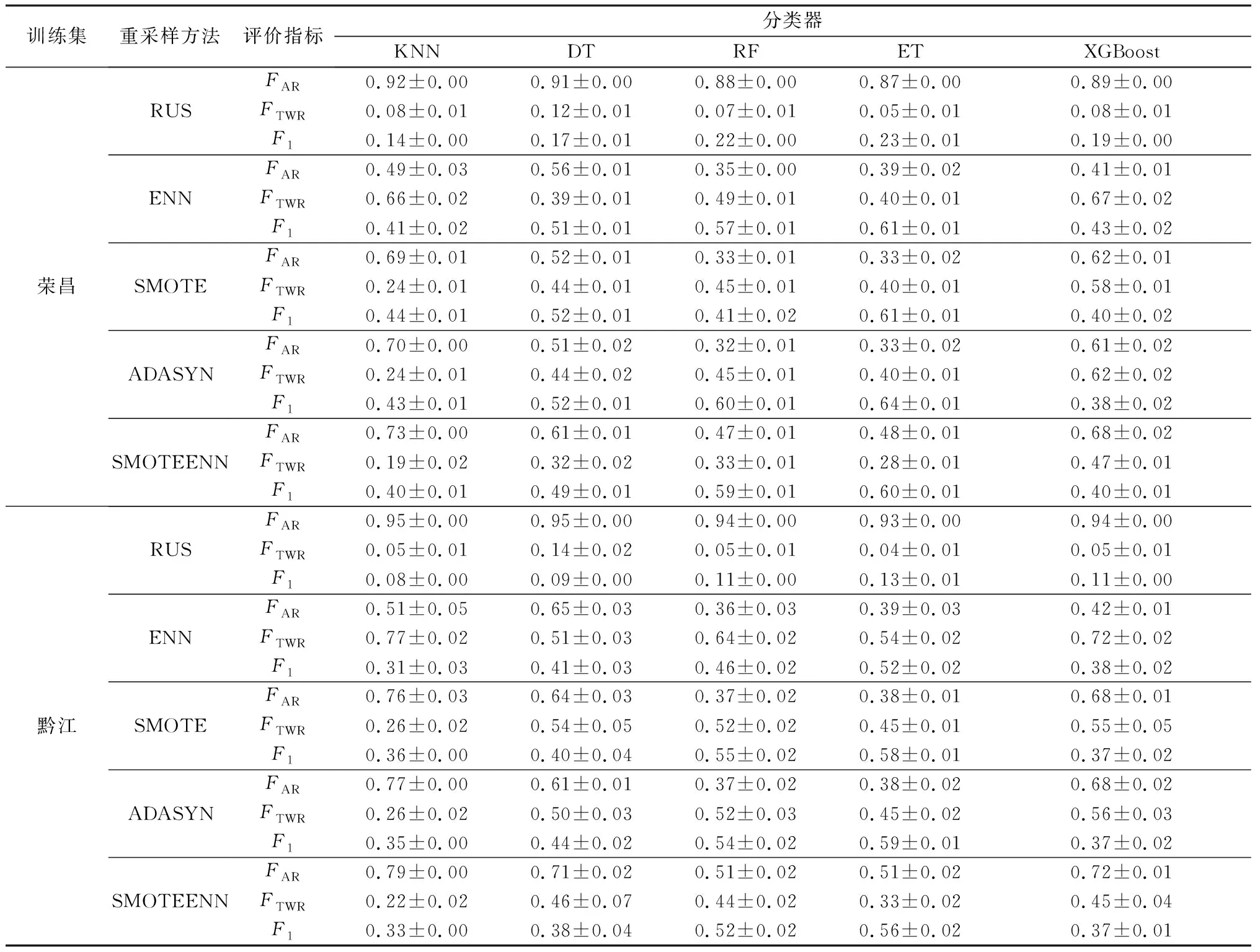
表4 2017年6月至2019年12月荣昌、黔江训练集在各种重采样方法下基线分类器性能
2.3 模型超参数调试及适应性探讨
使用Scikit-Learn中的RandomSearchCV(随机搜索调参)工具,基于荣昌训练集,对ADASYN-ET分类模型进行参数调优,调优过程中交叉验证设置为5折,迭代次数100,模型评价标准设置为F1。最终确定的模型参数ADASYN方法中邻居数为4,ET分类器中最大特征数为lg2,叶节点最小样本数为1,弱学习器个数为180,其他默认,验证曲线如图3所示。对于黔江训练集,使用RandomSearchCV后确定的参数与荣昌训练集基本一致。
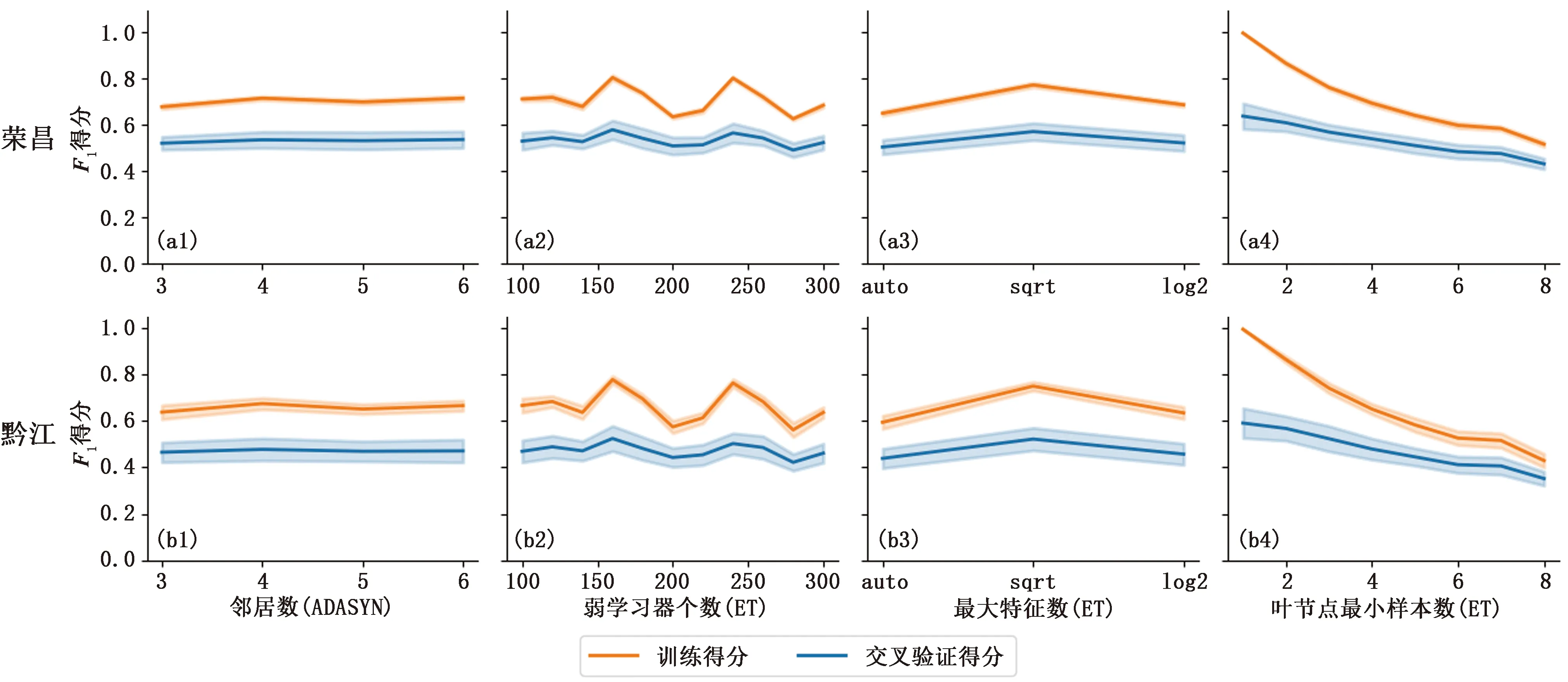
图3 2017年6月至2019年12月荣昌、黔江训练集ADASYN-ET模型RandomSearchCV验证曲线:(a1,b1)邻居数,(a2,b2)弱学习器个数,(a3,b3)最大特征数,(a4,b4)叶节点最小样本数
为更好研究各站差异,使用SVD(奇异值分解)对8个站点地闪活跃样本中各特征的分布模式进行PCA(主成分分析),在每个站点,保留前2个主成分。图4显示了所有8个站点的每个特征变量对两个主成分的载荷,并用KMeans聚类分析标出了聚类中心(红点),综合来看黔江、酉阳两站在大多特征下有着不同的分布模式,表现在距聚类中心较远,根据表2来看,此2个站点恰是海拔最高的两个站点,可以认为海拔高度是影响数据特征分布的主要因素。
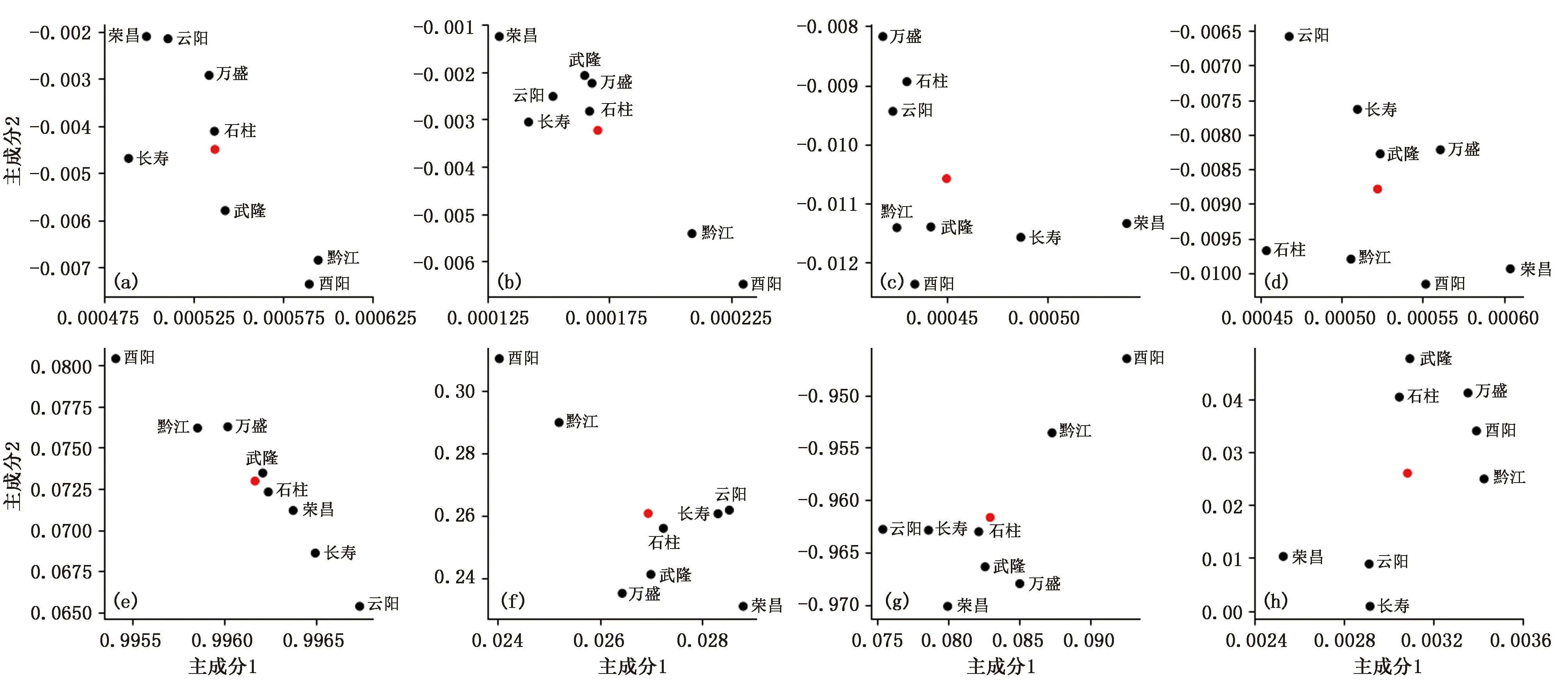
图4 2017年6月至2019年12月重庆市8个站点地闪活跃样本各特征向量对主成分载荷分布:(a)msin,(b)mcos,(c)hsin,(d)hcos,(e)气压,(f)气温,(g)相对湿度,(h)风速(图中黑点为研究站点,红点为KMeans聚类中心)
结合前文,荣昌、黔江2站点虽然在地理条件及类别比率方面差别较大,但2站确定的最优分类模型、模型超参数均一致, 因此可认为ADASYN-ET分类模型适用于本文所有站点;但由于各站海拔高度不同,导致特征分布模式迥异,因此对于目标站点,不能使用其他站点气象要素数据进行训练。
使用ADASYN-ET分类模型,同样以为标签,对8个站点测试集进行分类,各站点分类性能评估指标如表5所示,F1及其不平衡比如图5所示,可以看到,F1总体随不平衡比的降低而升高,其中不平衡比最高(307∶1)的酉阳子集,F1为0.53;不平衡比最低(115∶1)的万盛子集,F1达到了0.66。说明虽然进行了重采样,但是最终性能仍然受到训练数据不平衡比的限制,不平衡比越低,模型性能越好。
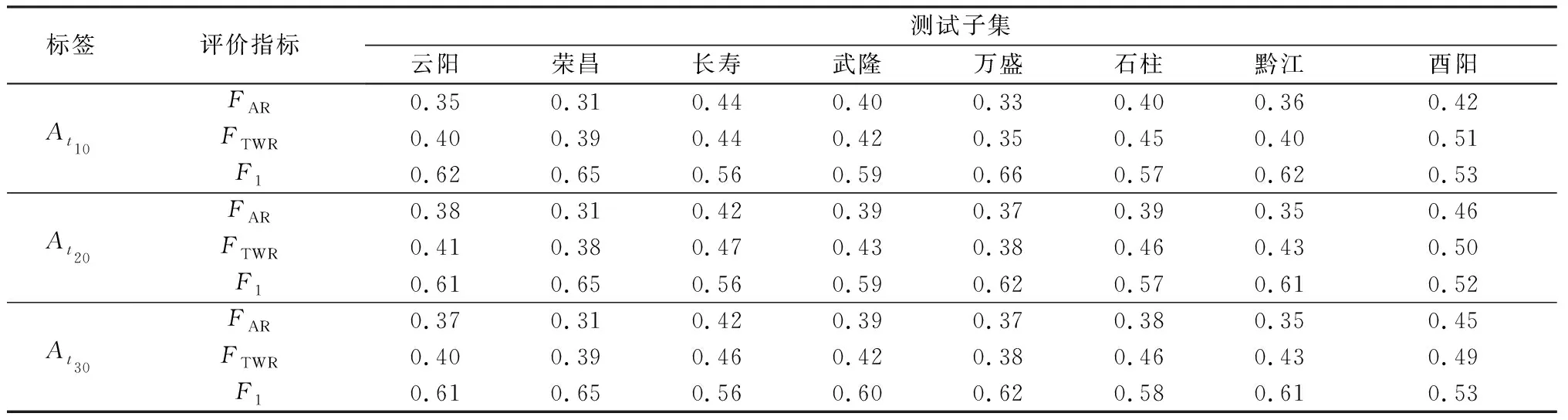
表5 2017年6月至2019年12月重庆市8个研究站点测试集在At10、At20、At30标签下ADASYN-ET模型分类性能
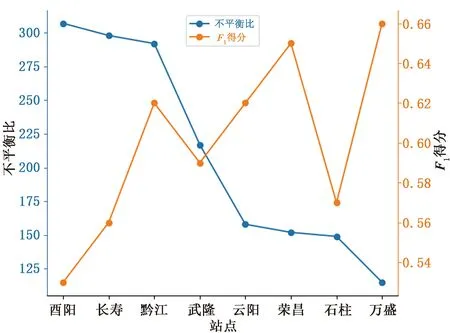
图5 2017年6月至2019年12月重庆市8个站点测试集ADASYN-ET模型分类性能及不平衡比分布
分别以At10、At20、At30为标签,对8个站点测试集进行分类,各站点分类性能评估F1如图6所示,其中At10标签下8站点F1平均值为0.60,At20下为0.59,At30下为0.60,说明在0~30 min的预警提前期内,该分类模型性能基本一致,无衰减情况出现。
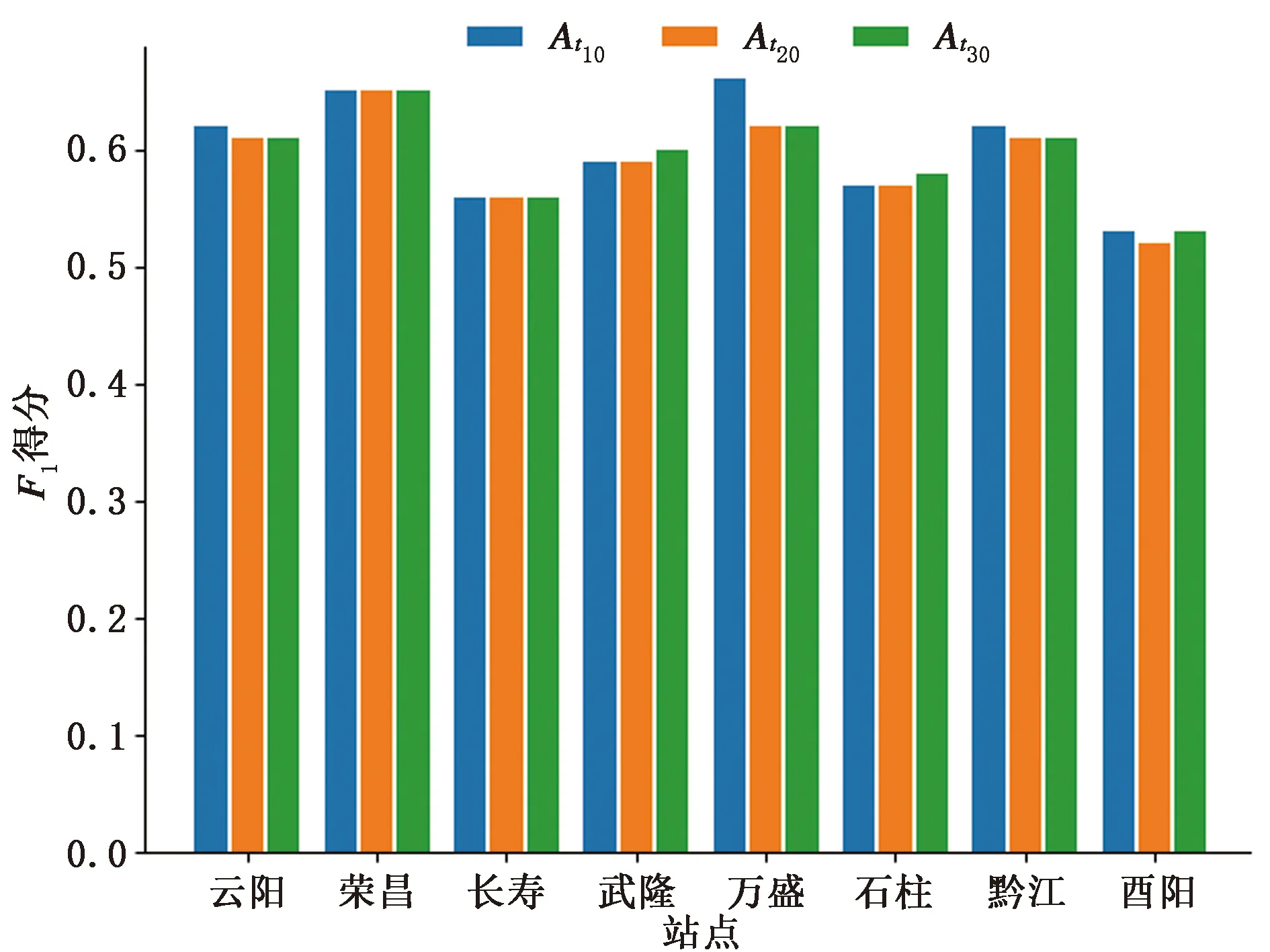
图6 2017年6月至2019年12月重庆市8个站点测试集0~30 min预警提前期ADASYN-ET模型F1得分(图中蓝色为0~10 min提前期,橙色为10~20 min提前期,绿色为20~30 min提前期)
2.4 与其他雷电临近预警方法对比
在GB/T 38121—2019发布前已有雷暴预警系统中,所使用的评估指标不尽相同,可用于直接对比的系统较少。本文找到几种近期临近预警系统或方法,为便于对比,统一将性能评估指标转换为F1得分。
张长秀等[14]在2019年对海南地区8个雷电预警站点的预警效率进行了统计分析,得到海南地区新型雷电预警系统在提前期13.9 min的MPOD(平均有效预警率)约为85.5%,FAR为0.732,文中未提供单站覆盖区域,换算得出,其8个站点在提前期13.9 min的平均F1得分为0.408。
徐伟等[4]基于集成经验模态分解和极端梯度提升的雷电预警方法,选取了单站400个大气电场仪数据样本,其中有雷电发生样本数为90,无雷电发生样本数为310,覆盖区域25 km,其多分类器融合提前20 min的最佳性能为POD=76.2%,FAR=33.3%,换算得出F1得分等于0.711。值得注意的是,其数据集不平衡比为3.4∶1。
雷电临近预警系统由于设计目的不同,对评估指标的偏重也不同,不能简单以一项指标判断优劣。但综合来看,本文提出的雷电临近预警方法通过对模型进行2年跨度的气象要素资料训练即可得到不错的分类性能,在0~30 min预警提前期性能无衰减,具备实际应用价值。
3 结论与讨论
本文提出的雷电临近预警研究,基于容易获得的基本气象要素,通过特征工程、重采样、集成分类等机器学习方法的组合运用,创建并挑选了较为合理的预警模型,该模型本质上是一个不平衡条件下的二分类器,具有以下特征:①在气象要素特征的基础上,加入周期处理的观测时段、月份特征能对模型分类性能提升明显;②对训练数据进行过采样可以进一步改善模型的分类性能;③该模型适用于所有8个研究站点,但由于不同站点间特征分布差异较大,因此对于特定站点,不能使用他站数据集训练模型;④模型性能与数据集地闪非活跃/活跃类别不平衡比呈反比关系。
同时,该预警模型也存在一些不足之处:①预警覆盖区域不够精细,本文提出的预警研究基于气象站周边20 km区域,如缩小预警区域,将造成地闪样本减少,分类性能下降,与一些专业雷电临近预警系统(如具有1 km地闪分辨率的CAMS_LNWS临近预警系统)尚不具有可比性;②在本文选择的研究站点,该模型至少需2年跨度的单站气象资料训练方能达到可用水平,对应用场景有所限制。
综合来看,基于模型的预警方法利用已有气象站资源,应用方式灵活,实现成本较低,对缺乏雷达、卫星、电场仪等其他气象探测资料的地区的防雷减灾工作具有一定的参考意义。
