基于小波分解-长短期记忆网络预测模型的酱卤肉制品安全预测分析
2022-03-03郭鹏程
尹 佳,陈 翔,董 曼,陈 锂,郭鹏程,张 涛,文 红,*
(1.湖北省食品质量安全监督检验研究院,湖北省食品质量安全检测工程技术研究中心,湖北 武汉 430075;2.武汉理工大学计算机与人工智能学院,湖北 武汉 430070)
酱卤肉制品是我国传统的肉类食品之一,风味独特,具有较高的营养价值,其安全问题直接影响到广大人民群众的健康。随着社会经济的快速发展,国家对食品抽检力度也不断提升,大量的食品抽检数据为了解食品安全现状、制定针对性的抽检计划和监管提供了重要的数据支撑[1]。但国内食品安全事件如豆芽中检出6-苄氨基腺嘌呤[2]、胶囊中检出铬[3]、速冻米面食品存在单核细胞增生李斯特菌污染[4]等时有发生,使得对食品进行潜在风险的事前预防控制变得尤为重要。食品安全涉及食品供应链的整个过程,各个环节都存在威胁食品安全的潜在因素,食品安全风险评估与监管需要综合考虑各个环节的风险因素。因此,非常有必要对这些因素进行挖掘分析,充分利用这些复杂数据,提炼出潜在的有价值的信息,识别出潜在的安全风险,实现综合性、动态性的预测,对问题食品或可能存在的风险及时发出预警,为食品安全风险监管部门进行风险控制提供技术支持。
我国的食品监管部门和检验机构对于海量的抽检数据,通常通过对某类食品安全历史抽检数据集进行简单地统计分析,得到该类食品的不合格率,然后利用该指标对该类食品安全状况进行评价,此方法为对食品安全状况的事后分析。通过分析历年食品安全检测数据发现往往存在大量空值,即某项目没有检测或者是检测后没有结果,数理统计方法不能在空值上进行风险评估并发现数据项之间的联系,显然,在食品安全风险评估中数理统计显现出不足。通过这些传统的数理统计、典型病例通报等手段对食品进行风险警示,缺少深度的分析与应用[5-6]。另外,国内监管机构对监督抽检数据合格数据利用相对不足,而合格数据中也有风险因素,如果仅利用不合格率评估食品安全状况,忽略食品中检测项目实际检测数据以及检测数据与相关食品安全标准值间的关系,不能准确反映食品安全状况。部分发达国家和地区在风险预警方面起步较早,目前已建立了相对成熟的食品安全风险预警系统,例如欧盟食品与饲料快速预警系统、全球环境监测系统/食品污染物监测与评估规划、国际食品安全当局网络、美国食源性疾病主动监测网络及联合国的畜牧业预警系统[7-9]等。在食品安全风险预测方法方面,国内外学者也进行了许多探索。Allain等提出新兴风险识别支持系统的设计,适用于家禽屠宰场肉类检验的风险预警系统[10]。Wang Jing等采用关联规则挖掘和物联网技术,对整个食品供应链的所有检测数据进行及时监控,判断是否应发布预警[11]。Geng Zhiqiang提出了两种基于层次分析法的食品安全预警模型[12-13]。另外,为充分利用合格数据,李小凤提出了基于指数的不合格度与不合格率两方面去综合评价食品风险等级,将食品安全风险等级程度分为了5 级[14]。郭海霞等也构建了食品安全指数评估模型,用于评估山东省猪肉中兽药残留风险程度[15]。陈夏威等[16]指出目前大部分食品安全风险预警相关文献仍在使用支持向量机模型[17]、BP神经网络模型[18]、决策树模型[19]等,仍然不能取得最佳的效果。例如目前广泛应用在食品安全风险预测的研究方法——BP人工神经网络和支持向量机,在预测过程中会遇到一些问题[20-23],如BP神经网络在食品安全预测方面存在训练时间长、网络训练效率不稳定、泛化能力不强、精度不太高等缺点,这是由于BP神经网络的本质是梯度下降法,由于优化的目标函数较为复杂,导致算法效率较低,同时它又是一种局部搜索的优化方法,在训练过程中可能会陷入局部极值,从而导致训练失败。而支持向量机算法则适用于少量线性可分数据的训练。
食品安全检测数据具有非线性的特点,时序性和波动性较强。目前在食品安全预测方面,基于时序性的预测模型较少,一类是基于传统的统计分析和随机过程,通常要求序列具有平稳性,并且本质上只能描述线性关系[24-25];除了统计学方法外,传统的模型还有灰色时间预测模型[26],其对数据的要求较低,适合短期预测,但对于波动较大的数据却效果不佳。另一类模型基于神经网络,例如循环神经网络(recurrent neural network,RNN),其能够更加充分地利用数据的时间特性。长短期记忆网络(long short-term memory,LSTM)属于循环神经网络的一种,是针对普通循环神经网络的长期依赖问题所提出的一种改进方案。与普通的RNN不同,LSTM的隐藏层不是简单的重复结构,而是采用了三重门的设计,即遗忘门、输入门和输出门[27]。三重门的设计使得“记忆”信息更有选择性,能够筛选出真正有效的信息,从而避免无效信息对整个循环网络产生较大的干扰。LSTM在考虑时间规律的同时,可以捕捉到数据复杂的非线性特性。由于食品安全抽检数据是非平稳的离散时间序列,振幅较大,目前对于非线性非平稳信号的分析主要方法有短时傅里叶变换[28-29]、小波分解[30-31]、经验模态分解[32-33]等分析方法,其中小波分解继承和发展了短时傅立叶变换局部化的思想,同时又克服了窗口大小不随频率变化等缺点,能够提供一个随频率改变的“时间-频率”窗口,是进行信号时频分析和处理的理想工具。相较于傅里叶变换,小波分解由于其小波基的特征,能获取其时域特征,更适合处理非平稳信号,小波分解能同时分解趋势信息和波动细节信息,常用来解决波动性问题。
本研究以2014—2019年我国酱卤肉制品历史抽检信息为数据源,依据国家标准对检测结果进行风险等级划分,并采用数据分箱对风险等级数据进行预处理,利用小波分解对数据进行分解,对分解后不同细节的分量分别采用LSTM模型进行预测,最后将预测后的分量结果进行相加重组,得到预测的风险等级,构建了基于时间序列的小波分解-LSTM预测模型,并对模型的有效性进行验证,以期为我国酱卤肉制品食品安全问题分析与风险预警提供理论支持,为食品安全大数据的进一步深入挖掘提供参考。
1 数据与方法
1.1 数据的来源
本研究使用的数据来源于国家市场监督管理总局2014—2019年公开公布的以及本机构抽检所获得的30 757 批次酱卤肉制品信息,数据涵盖抽检合格与不合格产品的名称、生产日期、生产企业省份、检验项目、检验结果、标准值等原始信息,所得到的部分数据如表1所示。

表1 部分食品安全抽检原始数据汇总Table 1 Summary of selected food safety survey data
分析数据发现不同年份各省酱卤肉制品抽检项目有所不同,为尽量全面反映酱卤肉制品的食品安全状况,最终将所有抽检的项目均纳入指标体系。以湖北省2014—2019年数据为例,包括28 个检验项目(酸性橙II、克伦特罗、氯霉素、沙丁胺醇、莱克多巴胺、商业无菌、大肠菌群、菌落总数、单核细胞增生李斯特菌、苯并[a]芘、N-二甲基亚硝胺、亚硝酸盐残留量(以亚硝酸钠计)、山梨酸及其钾盐(以山梨酸计)、糖精钠(以糖精计)、脱氢乙酸及其钠盐(以脱氢乙酸计)、苯甲酸及其钠盐(以苯甲酸计)、胭脂红、苋菜红、新红、日落黄、柠檬黄、诱惑红、赤藓红、防腐剂混合使用时各自用量占其最大使用量的比例之和、总砷(以As计)、铅(以Pb计)、铬(以Cr计)、镉(以Cd计)),该检验项目包含8 类:非食用物质、禁用兽药、其他微生物、致病性微生物、有机污染物、其他污染物、食品添加剂、重金属等元素污染物(表2)。

表2 酱卤肉制品安全风险预警指标体系Table 2 Early warning index system for marinated meat product safety risks
1.2 数据预处理
由于食品检测结果具有多源性、异构性、非线性等特点,不同样品之间的检测结果存在差异性,波动性较强[34],如果直接将检测结果的数值直接带入模型训练,学习曲线会十分复杂,预测结果会存在较大偏差。本研究以湖北省2014—2019年酱卤肉制品28 个检验项目的检测结果为例,根据国家标准(GB 2760—2014《食品安全国家标准 食品添加剂使用标准》等)采用公式(1)将食品的各项目检测值进行去量纲化处理。根据各项目去量纲化的结果,结合专家打分法,将项目风险等级分为5 级,其中1~4级符合国家标准要求,1级为无需预警,2级为轻微预警,3级为轻度预警,4级为中度预警,5级为不符合国家标准要求,为重度预警[35],等级详见表3。

表3 项目风险等级分级表Table 3 Risk rating scales for test items

式中:Yi表示预处理后的风险等级评价值;Xstandard为国家标准中规定的标准值;Xi为检验项目的实测值。
通过上述预处理,得到1级风险数据16 733 条,2级风险数据1 026 条,3级风险数据945 条,4级风险数据19 条,5级风险数据38 条。由于食品风险等级低的检测项目占大多数,而风险等级高的检测项目占少数,但风险等级高的数据对最终的食品安全风险等级却有决定性的影响。因此,如果采用传统的加权平均法,会导致最终的食品风险等级都很低,不能反映出食品的真实风险等级,而借鉴softmax函数采用指数的方式来计算食品A的综合风险等级(公式(2)),则可以很好地反映食品数据的特征,使得计算出的风险等级更加符合实际情况。

式中:level(A)为食品A的综合风险等级;i为食品A中的等级数值;w(i)为风险等级i在食品A中的占比。
1.3 小波分解-LSTM模型的建立
1.3.1 小波分解
小波分解能够将原始信息分解为不同精细度的信息,其中粗略信息能够代表原始信息的趋势,而细节信息反映的是原始信息的波动情况。本研究中食品安全抽检数据是离散时间序列,采用离散小波分解中的快速二进正交小波分解[36](Mallat算法)进行分解,分解示意图如图1所示。

图1 小波分解示意图Fig.1 Schematic diagram of wavelet transform
1.3.2 LSTM模型
LSTM是建立在RNN上的一种新型深度机器学习神经网络,在输入、反馈与防止梯度爆发之间建立了一个长时间的时滞。这个架构使得其在特殊记忆单元中的内部状态保持一个持续误差流,梯度既不会爆发也不会消失,误差函数随梯度下降得更快,更容易收敛到最优解,使得梯度无论传播多远,都不会出现完全消失的现象。LSTM循环结构示意图如图2所示。

图2 LSTM循环层结构示意图Fig.2 Schematic diagram of LSTM cyclic layer structure
其中核心的部分是神经元Ct-1到Ct的状态转移,如式(3)所示。

式中:Ct-1为t-1时刻的神经元状态;Ct为t时刻的神经元状态;ΔCt为t时刻神经元信息增量;ft、it分别为遗忘门和输入门。
遗忘门ft的表达式如式(4)所示。
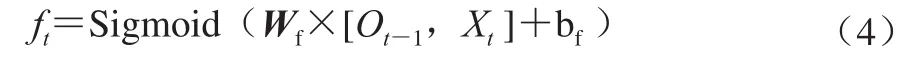
式中:Sigmoid为Sigmoid激活层,使得输出结果为一个0~1的值,代表着对该信息的保留程度;Wf为遗忘门的权值矩阵;Ot-1为t-1时刻的输出;Xt为t时刻的输入;bf为遗忘门的偏置量。
输入门it的表达式如式(5)所示。

式中:Wi为输入门的权值矩阵;bi为遗忘门的偏置量;其余参数含义与遗忘门相同。
神经元信息增量的表达式如式(6)所示。

式中:tanh为tanh激活层;Wc为神经元状态的权值矩阵;bc为神经元状态的偏置量;其余参数含义与遗忘门相同。
而最终的输出则是由神经元的状态Ct和输出门ot同时决定的,如式(7)所示。

式中:Ot为t时刻的输出;ot为输出门;Ct为t时刻的神经元状态。
在本研究中,将前n个酱卤肉制品的综合风险等级值组成一个序列,输入LSTM模型中进行训练,模型会计算前n个酱卤肉制品的综合风险等级值对后面的酱卤肉制品的综合风险等级值的影响,同时在训练时也会考虑后面的风险等级对前面的影响。依据该影响来决定记忆或遗忘,并实时更新神经元状态。
1.3.3 其他相关参数设置
根据本研究的实际情况,对相关的参数进行了设置,本研究使用的神经网络总共4 层,将当前待预测风险等级的前20 个等级作为输入特征,对应的输入层神经元个数为20;将当前待预测风险等级作为输出,对应的输出层神经元个数为1。中间的隐藏层分别为一个LSTM层和一个结点数为16的全连接层,训练集的其他相关参数如表4所示。

表4 训练集相关参数Table 4 Training set-related parameters
1.3.4 小波分解-LSTM模型
本研究采用小波分解-LSTM模型进行预测,其基本思路是先采用小波分解对数据序列进行分解,得到各个分量,再采用LSTM模型对各个分量进行预测,得到各个分量的预测模型,最后对分量的预测结果进行重构,输出最终的预测结果,具体流程如图3所示。

图3 小波分解-LSTM模型流程图Fig.3 Flow chart of WT-LSTM model
1.4 对照模型(经验模态分解-LSTM模型)
经验模态分解(empirical mode decomposition,EMD)广泛运用于信号处理和数据分析中[37],适合非平稳信号的处理,它是将一个频率不规则的信号波分解为不同单一频率的信号波和一个残差的形式,其中不同单一频率的信号波也叫本征模函数(intrinsic mode functions,IMF)。EMD依据数据自身的时间尺度特征来进行信号分解,即局部平稳化,而无需预先设定任何基函数。经过EMD方法分解可将原始信号Xt分解成一系列IMF以及剩余部分的线性叠加。
将经过EMD分解得到的各IMF分量输入LSTM模型,使用LSTM对各IMF分量进行预测,最后重组得到预测结果。
2 结果与分析
2.1 数据分箱时间间隔
由于食品抽检采样存在随机性,并不是每天均有采样,若按天进行建模,存在较多缺省值,故需要对数据进行分箱处理。数据分箱时间间隔会影响LSTM输入点的个数和精度,若时间间隔太长(如以月为单位进行分箱处理),LSTM输入点数太少,导致模型精度降低;若时间间隔太短,数据会存在较多缺省值,且学习曲线复杂,导致最终预测结果缺乏可信性。本研究对数据分箱时间间隔进行优化,分别以时间间隔1、4、7、15、30 d进行实验(表5)。

表5 数据分箱时间间隔优化Table 5 Optimization of data separation time interval
由表5可知,随着采样间隔的增大,预测的平均准确率在逐渐减小,同时数据集也在减小,对于原本数据量较少的城市则会造成数据集过小而无法满足神经网络训练的基本条件。另一方面,由于原始的食品安全数据在时间维度上存在许多缺省值,若采用间隔太小,则会采集到许多缺失值,使得采样数据失去代表性,对预测产生干扰;因此,在考虑到数据的有效性的同时,为尽量减小采样间隔,最终将时间间隔定为4 d一个分箱。
本研究最终将时间间隔4 d的食品数据划分为一个数据集,并使用公式(2)计算每个数据集的风险等级。
2.2 网络模型训练
小波分解能通过变换充分突出问题的某些方面特征,能对时间(空间)频率进行局部化分析,通过伸缩平移运算对信号(函数)逐步进行多尺度细化,最终达到高频处时间细分,低频处频率细分,能自动适应时频信号分析的要求,从而可聚焦到信号的任意细节。基于小波分解,可实现对非平稳离散时间序列的食品安全抽检数据的平稳化处理。在信号空间中,可以采用不同的小波基,其中常用的小波基有Haar、Daubechies、Biorthogonal、Coiflets等。
由于原始数据具有连续性,且波动性较大,本研究在小波分解的过程中选择了光滑性较好的8阶Daubechies小波基,并根据数据的复杂程度将其分解为不同频率的子序列,每个子序列的长度与原始数据相同,反映的是原始序列中所包含的不同频率的信息。例如分解后的3、4、5级分解信息能够不同程度地反映原始数据部分的趋势特征。而其他的分解信息反映了不同的噪声干扰因素。最后采用smooth模式进行重构。本研究中模型构建使用数据分箱后得到的风险等级值作为输入,使用小波分解将数据分解成各个分量,再使用LSTM对各分量进行预测,最后重组得到最终的预测结果。图4为小波分解后各级分量示意图。本研究以湖北省2014—2019年酱卤肉制品数据的前2/3作为训练集,后1/3作为测试集以验证模型的预测准确性。


图4 湖北省酱卤肉制品数据小波分解-LSTM模型各分量预测示意图Fig.4 WT-LSTM model component prediction diagrams of marinated meat products from Hubei province
2.3 网络模型结果分析
2.3.1 有效性分析
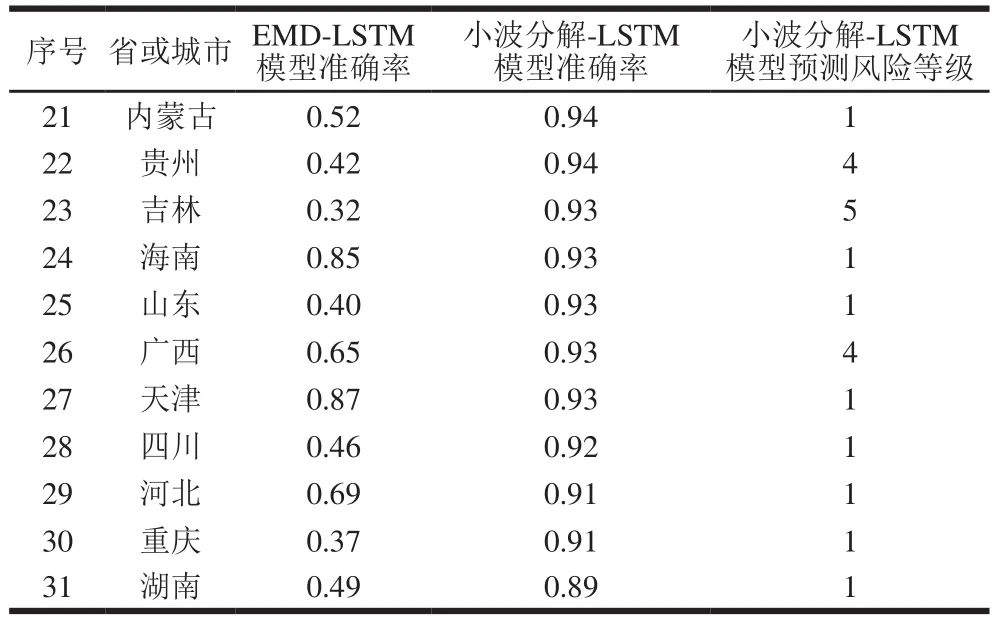
如图5所示,预测的酱卤肉制品综合风险等级与原始数据吻合度较高,计算预测准确率为0.99。使用类似的方法,将全国其他30 个省份的酱卤肉制品数据带入LSTM模型训练并进行预测,均得到较好的效果,具体见表6,准确率最低的为湖南省,准确率为0.89。平均准确率为0.95,标准偏差为0.029,说明整体准确率较高,并且准确率波动较小,表明建立的小波分解-LSTM模型可以适用于酱卤肉制品综合风险等级的时序预测。通过所建立的小波分解-LSTM模型对各省酱卤肉制品综合风险等级进行预测,发现广东和吉林2 个城市下一个时间点酱卤肉制品风险等级最高,需要引起相关部门的重视。

图5 湖北省酱卤肉制品数据小波分解-LSTM模型重构后预测示意图Fig.5 WT-LSTM model reconstruction prediction diagrams of marinated meat products from Hubei province

表6 不同模型间预测准确率比较及风险等级预测结果Table 6 Comparison of prediction accuracy between different models and results of risk grade prediction
续表6
2.3.2 模型比较与分析
本研究将2014—2019年31 个省酱卤肉制品检测数据进行相同数据预处理后,经过EMD分解后,将分解得到的各个本征模函数作为LSTM的输入数据,结果如表6所示,准确率最低的为吉林省,准确率为0.32,平均准确率为0.625,标准偏差为0.190。分析发现,EMD-LSTM模型中,经过EMD分解后的部分分量变化趋势仍然较复杂,从而导致重构后的结果误差较大,而小波分解-LSTM则较好地克服了这一问题,原因可能是小波分解-LSTM选择了光滑度较好的高阶消失矩的多贝西(Daubechies wavelets,db)小波基,而非常用的haar小波基,使得分解后得到的各个分量都具有较好的光滑性,从而使LSTM对各个分量都有较高的准确度。相对EMD-LSTM模型而言,所建立的小波分解-LSTM模型准确率更高,并且预测的准确率更加稳定。
3 结 论
根据2014—2019年酱卤肉制品历史抽检信息,使用专家打分法结合国家食品安全标准,对酱卤肉制品检测结果的数值进行去量纲化后,通过改进softmax函数公式来计算酱卤肉食品的综合风险等级,结合小波分解-LSTM模型,构建了适合酱卤肉制品安全预测的模型,并成功对全国31 个省份的酱卤肉制品风险等级进行验证和预测,结果显示模型精度较好,准确率最低为0.89,全国平均准确率为0.95,标准偏差为0.029,说明建立的模型可以有效实现酱卤肉制品中综合风险等级的预测,为我国酱卤肉食品安全的防御和日常监测工作提供技术支持。
