一种基于FPGA 的卷积神经网络加速器实现方案*
2022-03-02陈心宇高文斌
李 莉 陈心宇 高文斌
北京电子科技学院,北京市 100070
引言
近年来,深度学习领域中的神经网络技术因为其算法性能方面的优异表现被研究者们广泛关注, 在神经网络中卷积神经网络CNN 表现格外突出[1]。 CNN 作为一种经典的利用标签进行学习的监督学习算法,一直都是计算机图像处理领域的热点[2]。 由于CNN 中存在大量的卷积运算,即乘法和加法运算,如何提升CNN 的运算性能成了近年来研究者的重要关注点。
针对CNN 中卷积池化的运算计算量大、计算效率低的问题,存在三种解决办法:一是改进神经网络模型,减少神经网络对权值与参数数量的需求[3];二是利用快速算法,文献[4]中采用Winograd 算法,通过减少乘法次数来实现加快卷积运算;三是采用计算效率更高的平台,提高运算的效率。 CNN 是多层感知机的一个变种模型,这种模型刚开始被用来模拟大脑皮层的视觉行为,后在计算机视觉识别任务上表现出色被广泛运用于图像识别领域。 与传统神经网络不同的是,CNN 卷积层中输出特征面的每个神经元与其输入进行的是局部连接而非全连接,通过对应的连接权值与局部输入进行乘积求和再加上权值的偏置值,得到该神经元输出值,该过程等同于卷积过程。 CNN 采用局部感受野、权值共享等思想,显著地减少了网络中自由参数的个数,使得使用更多层的深度神经网络来进行监督深度学习成为可能。 CNN 由输入层、卷积层、池化层、全连接层及输出层构成,通常采用多个卷积层和池化层交替出现的结构,在卷积层、池化层、全连接层中,层内部的运算都是相互独立的,靠后的层内运算不会影响靠前的层内运算,换言之,以并行的方式实现CNN 的网络结构是可行的。 在文献[5]中,作者率先指出CNN 并行特征可以概括为层间并行性、输出间并行性、卷积核间并行性和卷积核内并行性四种类型。 但在实际应用中由于各种客观原因,无法兼顾四种并行性,在文献[6]中作者将探寻CNN 并行性的最大挑战总结于探究多种并行机制的最佳组合。
针对CNN 模型这种并行的层间结构,CPU的串行实现方式难以发挥CNN 的并行结构特点,而FPGA 具有计算资源丰富、逻辑电路设计灵活,并行设计容易实现的特点,广泛应用于硬件加速领域。 文献[7]采用主机+FPGA 的计算架构,通过将卷积层的卷积核参数和特征输入权值一次性全部缓存,再进行卷积的并行运算来减少卷积层的运算时间,但是会占用更多的FPGA片上资源。 文献[8]考虑到FPGA 片上资源的有限性,选择对部分卷积核进行并行运算,使用了循环变换方法构建卷积层计算电路,通过循环分块方法将卷积层划分成多组不同的输入-输出分块,构成多输入多输出的模型结构,通过循环展开方法以并行方式计算输入-输出块内的卷积操作,从而以层间并行、层内并行的方式实现卷积层的计算。 文献[9]提供了一种用来优化卷积运算中乘法和累加运算的稀疏卷积算法,降低了卷积运算中乘法运算复杂度。 文献[10]采用移位操作代替卷积运算中的乘法操作来降低硬件资源消耗。
在前人研究基础上,本文完成了以下工作。
(1) 选取CNN 中典型的LeNet-5 网络,分析各层结构,考虑CNN 的四种并行类型:层间并行性、输出间并行性、卷积核间并行性和卷积核内并行性,采用卷积核间全并行、核内部分并行、输出部分并行的方案实现神经网络卷积池化运算的加速。
(2) 提出一种新的行缓存乘法-加法树结构,一定程度上减少了内存资源消耗,提高了缓存-卷积操作的运算速率。
(3) 提出卷积-池化-卷积-池化-卷积五级流水线结构,设计控制模块高效地控制各层数据的读入输出,降低了CNN 的运算所需时间。
1 CNN 结构及其分析
1.1 LeNet-5 卷积神经网络
CNN 通过前向传播来进行识别和模式分类,通过反向传播来进行训练。 CNN 模型由多个计算层组成,除输入层和输出层外,CNN 使用卷积层、池化层代替了传统神经网络中的隐含层。 CNN 通过反向传播不断更新两层神经元之间连接的权值,使层中的不同神经元能够提取输入的不同特征,实现传统全连接网络达不到的多层深度学习网络的目标。
如图1 所示,手写体字符识别7 层CNN——LeNet-5 由输入层、卷积层C1、池化层S2、卷积层C3、池化层S4、卷积层C5、全连接层F6 和全连接输出层组成。 为了提高加速方案的普适性,本文只研究加速神经网络中具有高度并行性的部分:卷积层、池化层,也就是实现输入层、卷积层C1、池化层S2、卷积层C3、池化层S4、卷积层C5 的硬件加速。 待识别的32*32 单通道二值图像和6 个5*5 大小的卷积核做卷积操作得到6 通道28*28 的二维特征输出,经过2*2 的最大池化得到6 通道14*14 的特征输出,16 个5*5 卷积核与前一层6 通道特征输出中的部分通道做卷积运算,得到16 通道10*10 输出,经过下一层最大池化得到16 通道5*5 特征输出。池化层S4 的特征输出和卷积层C5 的120 个卷积核都是5*5 大小,卷积运算后得到120 维1*1 大小的向量输出。
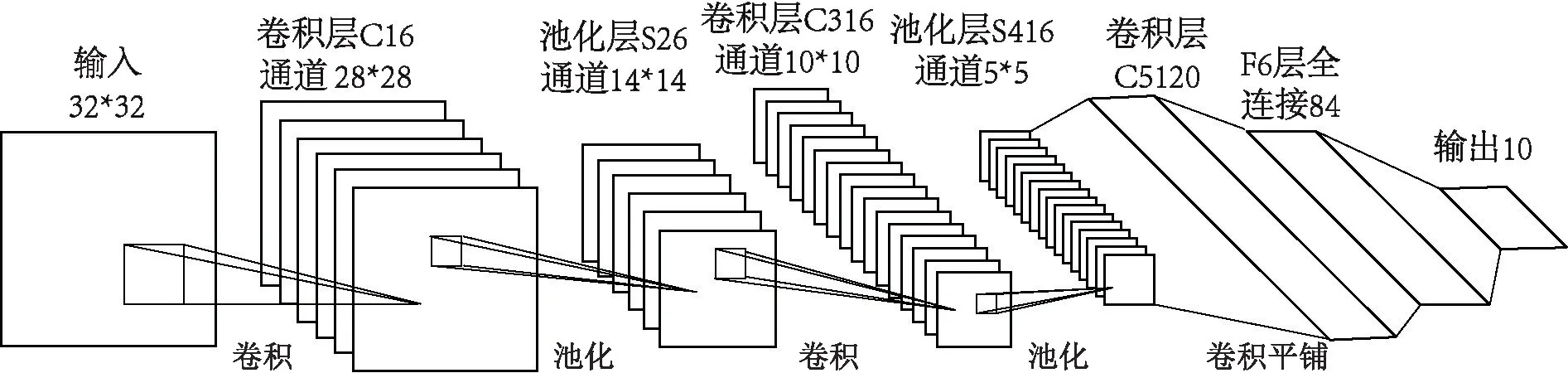
图1 LeNet-5 神经网络结构
1.2 并行性分析与层间结构分析
在上文描述LeNet-5 结构时,可以注意到,前后卷积层与池化层之间相互独立,但是每层的输入和上层的输出有关。 考虑到后一层不需要等待前一层所有数据处理完成再开始处理数据,前一层继续处理数据的同时向后一层输出数据,达到多层同时处理数据的效果,因此层间的数据处理可以用流水线的方式实现。 输出间的并行性可以和卷积核间的并行性一起考虑。 在LeNet-5 卷积层C1 中,28*28 的特征输入需要和6 通道的5*5 卷积核做卷积运算。 对于6 通道的卷积操作,每个通道的卷积之间互不影响,而且每个通道的卷积运算过程完全相同,所以对于卷积核间的并行性是可行的。 在一定程度上,多通道的输出,即输出间的并行性也是可以实现的。 对于核内的并行性,即乘法和累加的并行性,在已有的文献中都有提及,这里不再详细说明。
综上,本方案针对LeNet-5 神经网络的前五层卷积层C1、池化层S2、卷积层C3、池化层S4、卷积层C5 设计五级流水线架构。 采用卷积核间全并行、核内部分并行,输出部分并行的方式实现CNN 加速,层与层之间采用流水线结构实现数据流的高效处理。
2 实现方案
本文基于FPGA 对CNN 中典型的LeNet-5网络进行实现:层与层间采用卷积-池化-卷积-池化-卷积五级流水线设计,来加速CNN 层间的数据流传递与不同层之间的数据处理;层内卷积运算采用卷积核全并行、核内部分并行、输出部分并行的并行方式来加速CNN 的卷积、池化运算。
2.1 总体方案设计
在现行研究下,利用软硬件协同来实现CNN 加速器的架构主要有两种,一种是利用FPGA 片上CPU 和硬件资源协同实现整体方案[11],另一种是通过PC 机和FPGA 硬件资源实现整体方案。 本文采用第二种PC 机协同方案:PC 机负责传输图像输入、权值参数和偏置参数以及控制的功能;FPGA 负责CNN 运算的整个过程,二者通过UART 串口进行数据的传输交换。 CNN 并行加速方案的总体设计结构框图如图2 所示。

图2 方案的总体设计结构框图
本方案硬件设计实现CNN 的前向测试部分,CNN 的反向学习训练部分、输入的待识别图片二值化、权值浮点数定点化均由PC 端实现,系统读取训练完成的权值数据、偏置数据和二值化后的图片数据。 输入层、卷积层、池化层、全连接层、输出层间设计数据缓存模块,将前一层的输出保存在寄存器中,并等待控制模块输出使能信号控制下一层对前一层数据的读取。 卷积层由数据处理模块、卷积模块和激活函数Relu 模块组成;池化层由最大池化模块组成。
2.2 五级流水线设计
针对LeNet-5 神经网络的前五层——卷积层C1、池化层S2、卷积层C3、池化层S4、卷积层C5 设计五级流水线架构,如图3 所示。

图3 五级流水线架构
2.3 分模块设计
2.3.1 浮点数定点化
CNN 训练完成得到模型的参数分别为各卷积层所需要的卷积核权值及其偏置的值,经过软件部分的训练,上述参数值大小介于-10 与10之间。 对于FPGA 而言,不能直接处理浮点数,处理正负数小数需要将其定点化为二进制补码。Holt 等人[12]研究发现16bit 定点数既能维持一定的分类精度,也能有效地降低能耗。 在16bit中,第一位为符号位,0 代表正,1 代表负,随后五位为整数部分,最后10 位为小数部分。
2.3.2 缓存模块和输入控制模块
对于CNN 的硬件实现来说,待识别的图像数据输入、每层的特征输出都是需要下一级处理的数据,选择合适的缓存方案来保存这些数据显得尤为关键。 以待识别的图像输入数据为例,图像数据是32*32bit,考虑到后续卷积操作中卷积核大小为5*5,相较于直接采用5 组寄存器的行缓存结构,采用4 组寄存器串联和一条数据输入流组成5 行行缓存结构不仅更能节省FPGA 片上资源,而且更适合需要快速读入缓存数据的情况。 读取图像像素数据流是串行读入,在每个时钟周期,优先读取的数据从左到右,从上到下依次流入。 该结构如图4 所示。

图4 5 行行缓存结构
在上述行缓存结构中,在每个时钟周期,卷积窗口从左至右,从上到下移动一个像素,实现每个窗口下的卷积运算。 在卷积层与池化层之间的缓存器中,在每个时钟周期,2*2 池化窗口从左往右、从上至下依次平移一个像素,对两行缓存数据进行最大池化操作。
控制模块主要是通过输出使能信号来控制池化层S2、卷积层C3、池化层S4、卷积层C5 的数据输入输出。 卷积层C1 即时处理串行流入的数据,由卷积窗口在像素值上左右上下滑动,横向上,在卷积窗口滑动至第28 个像素值后需要在第二行的第一个像素值继续向右滑动,滑动至第5 行第5 个像素值之后,卷积层C1 输出第一个卷积窗口的卷积结果。 图解如图5 所示。

图5 控制模块C1 图解
池化层S2 在接收到C1 层第一个卷积结果的同时开始工作,因此当池化层S2 的计数器,经过4*32+5=133 个时钟后,S2 的使能信号s2_en 置为高电平1,接收数据。 除此以外,池化层S2 还需对卷积层C1 数据取舍,每32 个数据中的最后4 个数据是无效数据。 因此池化层S2 开始工作后,每隔28 个时钟需要将使能信号由高电平1 置为低电平0,低电平持续4 个时钟周期后再置为高电平1,往复循环,直到得到所有卷积层C1 的特征输出,如图6 所示。
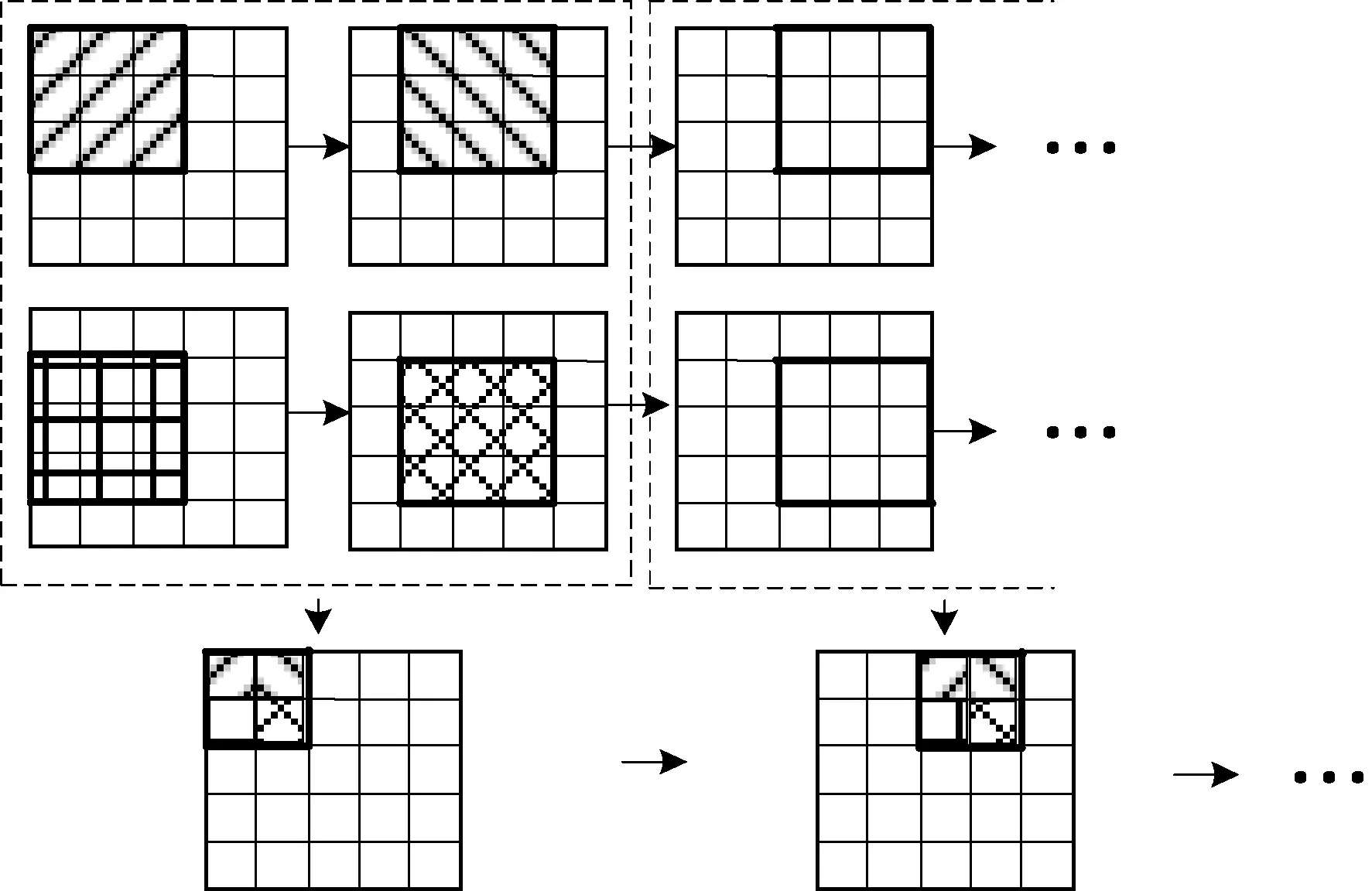
图6 控制模块S2 图解
卷积层C3 必须等到池化层S2 输出第一个最大池化结果后开始工作。 S2 层输出一个最大池化结果需要四个C1 层的卷积输出,卷积窗口在第二行像素上滑动到第二个卷积输出后,会得到第一个S2 层池化结果。 所以,320+20=340个时钟周期后,卷积层C3 开始读入数据。 在横向上,池化操作的池化窗口滑动步长为2,卷积层C3 的使能信号每隔一个时钟周期高低电平交替变换,即高电平每2 个时钟周期出现一次,重复14 次。 纵向上步长也为2,偶数行的池化层S2 特征输出全部舍去,在使能信号上就表现为重复14 次高低电平后,使能信号置低电平持续280 个时钟周期后还需要40 个时钟周期,共计320 个周期得到下一行的池化操作输出,并以此规律取遍所有数据。 池化层S2 输入使能信号S2_en 和卷积层C3 输入使能信号C3_en 的时序逻辑如图7 所示。 池化层S4、卷积层C5 使能信号的获得同上。

图7 使能信号时序逻辑
2.3.3 卷积模块
相对来说我国是一个淡水资源比较缺乏的国家,为世界13个赤水国家之一。在我国的农业的生产中,我国每年的农业灌溉用水量约4 00多亿m3。我国淡水资源比较缺乏,但是农业用水占总用水量比重比较多,在农业灌溉方面浪费情况严重。在我国的现有的水资源基础上,满足我国农业生产所需灌溉用水需求,对于农业提出了一个更高的要求。
CNN 中卷积层是CNN 中最核心的部分。卷积窗口在输入像素上依次滑动,卷积窗口的每一个权值与窗口内像素点做内积。
CNN 模型的通道个数称为深度,二维图像的特征输出由输入深度和卷积核的数量共同决定。 对于LeNet-5 来说,卷积层的卷积运算是建立在多通道的卷积运算基础上,不同通道的卷积运算互不干扰,而且不同通道的卷积运算动作完全一致,因此本文采用核间全并行的方式实现多通道卷积运算,以卷积层C1 六通道为例,其实现结构如图8 所示。
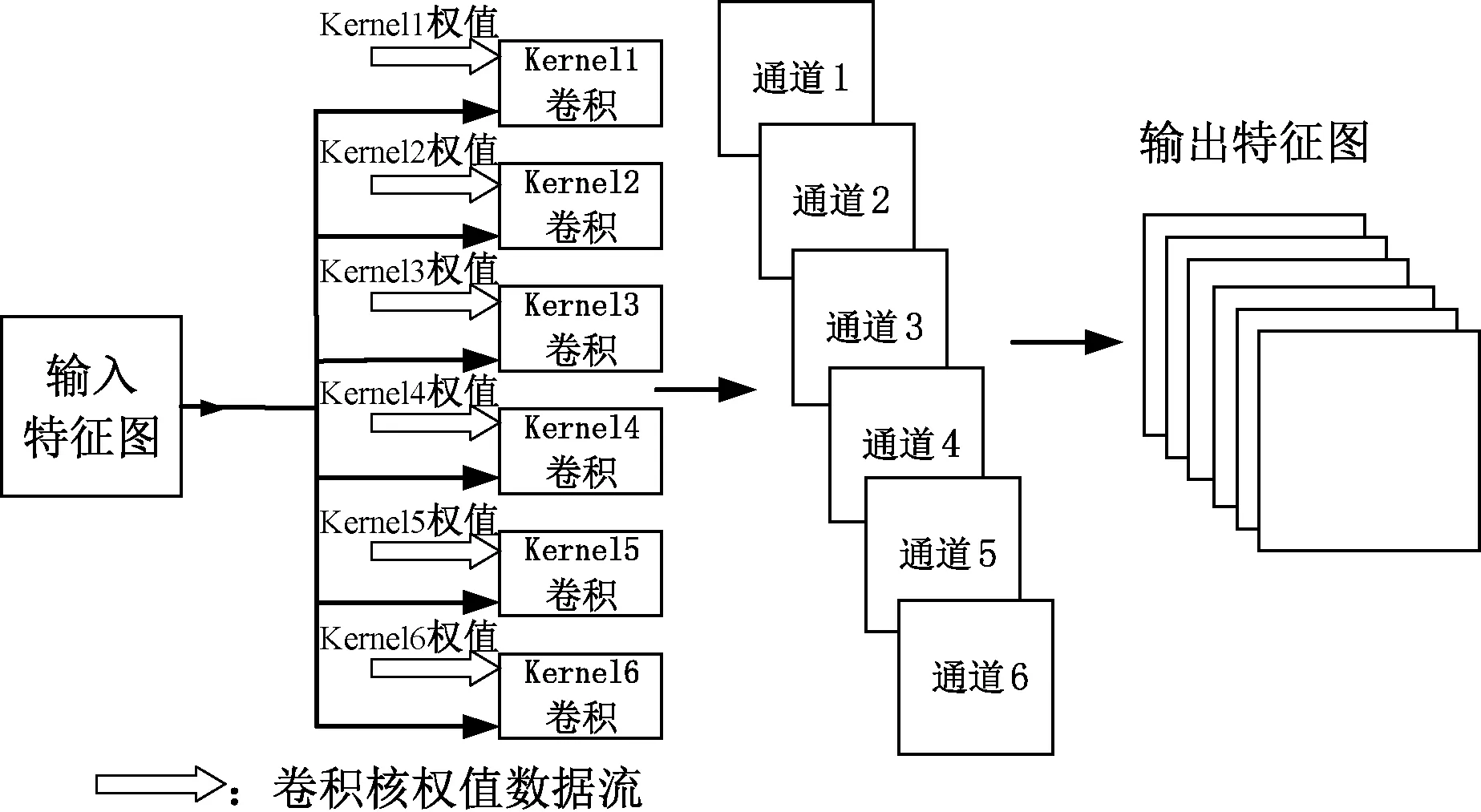
图8 核间全并行实现结构
卷积模块中的卷积操作涉及乘法和加法运算。 以5*5 卷积窗口和5*5 像素卷积操作为例,需要进行25 次乘法操作。 伪代码如下所示。
卷积模块中的加法操作即是对卷积窗口中得到的25 个乘法结果进行累加得到一个卷积窗口的卷积结果。 为了发挥FPGA 并行计算的优势,采用加法树结构实现核内运算的部分并行,如图9 所示。

图9 卷积加法树结构
每个时钟下进行两两加法求和,第一轮一个时钟周期内并行执行12 组加法运算,第二轮一个时钟周期内并行执行6 组加法运算,以此类推,第五轮得到最终卷积结果。 相较于普通串行实现的累加运算,使用加法树结构,可以实现并行高效的累加运算。 卷积操作的结构方案如图10 所示,因篇幅原因,加法树只画一部分。

图10 卷积操作结构方案
综上,考虑到采用核间全并行、核内部分并行的方式实现卷积层的卷积运算操作,卷积层的输出采用输出部分并行的方式实现,不同通道的卷积运算结果并行输出,相同通道的卷积核滑动运算结果串行输出。
卷积模块后,需要对卷积结果进行Relu 函数激活。 Relu 模块采用的激活函数如下所示。
2.3.4 池化模块
池化层主要通过减少网络的参数来减小计算量,并且能够在一定程度上控制过拟合。 本文采用最大池化方案,相较于卷积操作,最大池化操作窗口只需要对2*2=4 个特征输入进行取大操作。 参考卷积模块中的加法树结构,本文中最大池化操作采用如图11 所示的池化树结构:从两行缓存器中输入待比较的数据,两两比较大小,得到一个池化窗口四个特征输入的最大值输出。

图11 池化树结构
3 实验与实验结果分析
本文实验仿真工具采用Mentor 公司的Modelsim 10.5,通过图12 所示的仿真结果可以看到,在经历32*4+4 个时钟周期(1320ns)后得到卷积层C1 的输出;在卷积层C1 输出第一个卷积结果后,经历32 *1+2 个时钟周期(340ns)后得到池化层S2 的输出,后续的C3、S4、C5 等层同理。 在经过10735 个时钟周期后得到卷积层C5 的输出结果。
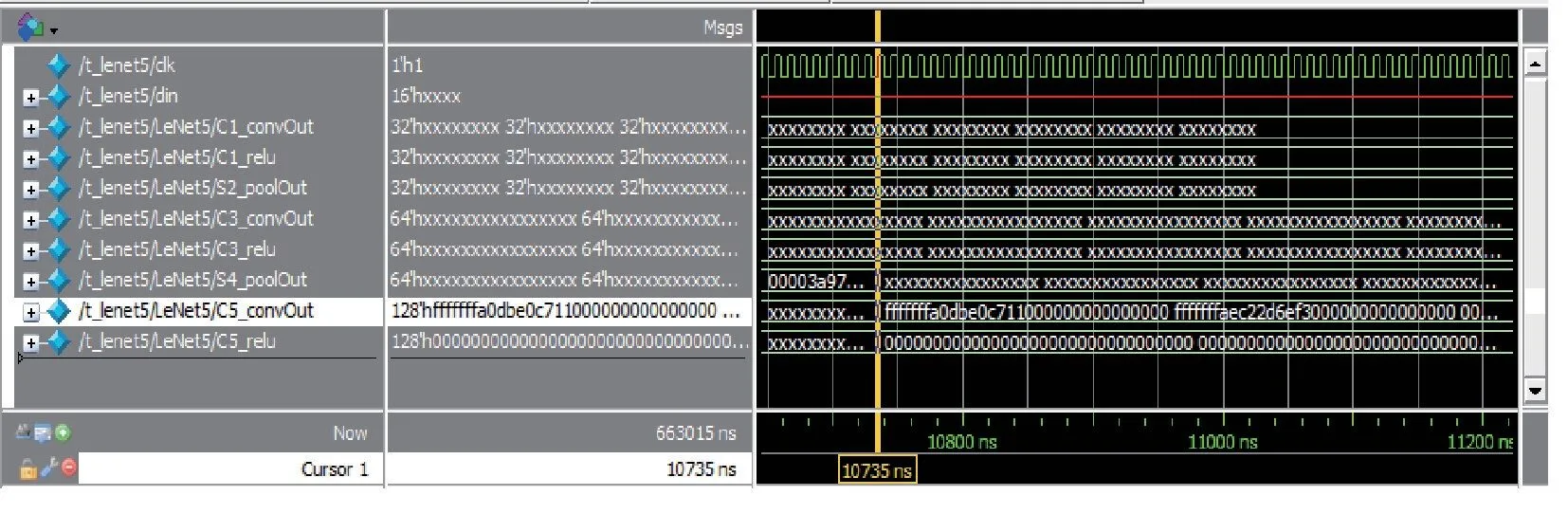
图12 Modelsim 仿真结果图
本文实验选用Xilinx Zynq 架构的开发板xc7z010clg400-2,CPU 采用主频为2.3Ghz 的i5-6300HQ 处理器。 在相同的权值数据和模型下,在Vivado 18.3 下综合,各资源占用情况与其他相关研究对比如表1 所示。

表1 资源占用情况对比
图13 为综合后时序报告,时钟信号的最差负松弛WNS 指标为2.296ns。

图13 综合时序报告
在不同FPGA 平台的纵向对比上,计算性能是一个比较关键的指标,通常用单位GOP /s(每秒十亿次运算数) 来描述,计算公式如式1。
其中P代表计算性能,Clk_num是总执行时钟周期数,即完成运算所需要的时钟周期的个数,Opt是CNN 中涉及乘加运算的总运算数,Frem是最高时钟频率,单位为MHz。 各层的运算数如表2 所示。

表2 各层运算数
经分析统计,本方案前向预测过程的总运算数为16936188 次。 在Vivado 中,Frem最高时钟频率由公式2 得到,其中T 为综合预设时钟周期。 本文预设时钟周期T 为10ns,WNS 为2.296ns,可以计算得到本方案最大时钟频率为129.8MHz。
把上述参数,代入式1,可以得到本方案的计算性能为
本方案设计卷积-池化-卷积-池化-卷积五级流水线结构来提高系统吞吐量。 吞吐量TPS的计算如式3 所示。
BITS为t时间内运算的比特数,Frem是最高时钟频率,N为流水线级数。 在最高时钟频率129.8MHz 下系统需要经历10735 个时钟周期得到运算结果,即t=8270.4ns 后得到结果。 本方案的系统吞吐量为
在129.8MHz 最大时钟频率下,表3 列出了本方案与其他方案在计算性能和功耗方面的对比。 文献[11]和文献[15]采用Zynq 系列开发板,处理精度采用8bit 定点数,能够以较小的功耗实现加速设计,但是相较于16bit 定点数,计算精度和计算性能都存在差距。 相较于其他文献方案,本文方案能效比没有太大优势:相较于文献[14],本文方案有较低的功耗;相较于文献[15]和文献[16],本文方案有较高的计算性能;相较于文献[17],本文方案,在计算性能没有明显优势的情况下,有着较低的功耗。
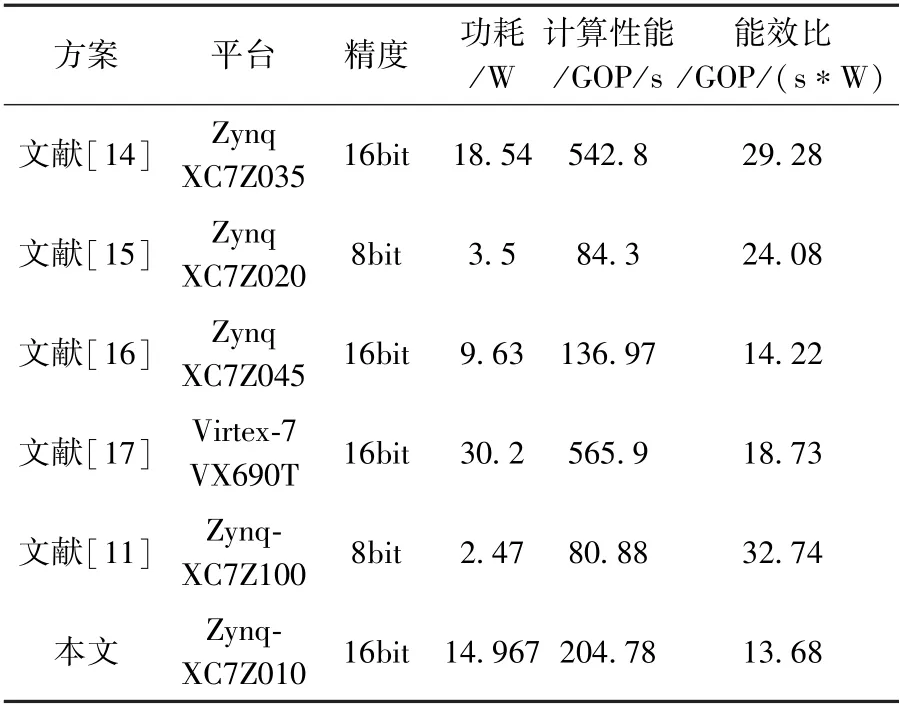
表3 加速器方案性能能耗对比
本硬件加速方案和在采用主频为2.3Ghz 的CPU 下基于python 实现LeNet-5 网络的正向预测的所需时间对比如表4 所示,较CPU 实现速度提升近337 倍,实现了CNN 加速功能。

表4 计算时间对比
4 结语
本文通过对一种典型的CNN 的权值参数和网络结构进行分析,提出了一种CNN 加速器硬件实现方案:采用16 位定点量化方案和一种新的行缓存乘法-加法树结构,设计卷积-池化-卷积-池化-卷积五级流水线结构实现卷积核间全并行、核内部分并行、输出部分并行的卷积池化方案。 在129.8MHz 最高时钟频率和定点化16bit 精度的实验情况下,系统对单张图片的处理速度较CPU 提高近337 倍。 在功耗为14.967W 的情况下, 系统计算性能达204.78GOP/s,能效比为13.68GOP/(s*W),系统吞吐量为1028.56Gbit/s。 后续工作将集中以下两点:1. 对定点数精度选择带来收益损失进行研究;2. 选择更复杂的神经网络模型,在提高运算量的基础上优化加速器软硬协同结构,在降低片上资源消耗的基础上进一步提高加速器的性能。
