基于RRCM 框架的联邦学习激励机制*
2022-03-02王文鑫赵奕涵张健毅
王文鑫 赵奕涵 张健毅
北京电子科技学院,北京市 100070
1 背景
近年来,深度学习受到社会各界的广泛关注,然而此种技术通过用户端数据直接传输,可能存在信息泄漏和被篡改的风险。 随着欧盟《通用数据保护条例》[1]和我国《个人信息保护法》[2]的相继颁布,越来越多企业对于个人敏感信息提起高度重视。 为解决数据安全问题和实现信息孤岛的共享,谷歌2016 年提出联邦学习(FL)的概念,其主要是将用户数据存储阶段和模型训练阶段转移至本地用户,客户端仅与中心服务器交互更新模型,从而有效保障用户隐私安全。
随着共享理念近些年的不断兴起,联邦学习技术在越来越多领域中得到应用,比如反洗钱、保险规划和累犯风险预测(COMPAS)等。 2019年微众银行正式开源全球首个工业级联邦学习框架FATE,并尝试将联邦学习应用于金融业务。 尽管联邦技术现阶段在通信路由与后门防御研究日趋深入和成熟,然而激励机制却可能成为一个制约其未来发展的短板。 如在联邦学习商业化场景中,中心同盟对参与方上传的本地模型多次迭代后形成全局模型,联邦系统通过全局模型和外界交易获取收益,此部分收益可作为激励分配给各个参与方。 由于联邦系统中数据所有者是具有独立性的利益共同体,所以各数据所有方具有利己性。 当参与方得到报酬与其付出贡献不匹配(激励机制不公平),相互独立的联邦成员可能会选择背叛整体利益,追求自身短期利益最大化,最终导致联邦系统存在合作的风险。
现阶段,联邦学习激励机制的奖励方式主要分为收益奖励和梯度奖励两种类别。 前者包括偏见信息和经济报酬,例如文献[3]通过带有偏见的信息作为奖励给予各个参与方,不过此种方式引入带有偏见的信息,可能使得联邦系统存在歧视,从而影响整体系统的公平性。 文献[4]从经济学和博弈论角度入手,通过经济报酬解决激励机制的分配问题,不过此方法引入其他变量,会加重系统的通信负担,同时通信损耗也会随之增大。 后者研究主要依赖当前轮次数据所有者贡献程度获得不同全局模型的思想,从而使得次轮迭代的局部模型得到更好优化。 然而依靠此种激励的部分文献没有探讨联邦学习Non-IID问题[5],即给联邦系统分配不同的全局模型,各个同盟的数据项和特征属性可能均不相同,所以中心服务器在整体迭代时不能简单采取FedAvg聚合模式。 此外,大多数文献没有考虑梯度奖励的弊端,比如贡献度较低参与方分配得到较小相似度的权重使得次轮训练的全局模型结果变差[6]。
此外由于没有任何保障机制,联邦系统在多方合作时,传统FL 框架存在被敌手攻击的风险。 机会主义者可采用上传无关梯度或者贡献度较低梯度来影响中心同盟的全局模型。 所以联邦系统需要引入惩罚措施,通过对联邦系统中实用主义者的奖励机制和机会主义者的惩罚机制,对系统中的各参与方形成警示作用,从而保证联邦系统有效帮助企业中个体实现资源共享、降低系统经营风险[7]。
目前在激励机制公平性文献中,传统的激励机制[8]没有考虑企业加入联邦系统时需要提供成本。 当联邦系统分配各个参与方奖励时,没有引入联邦系统的成本问题,这样会导致激励机制过程不够完善。 如果成本和成本利息比系统收益更大,参与方可能不会加入到系统中,而会选择加入其它联邦系统或单独训练,此时参与者的实际收益应为利润-收益组成。
总之,本文的贡献包括:
1. 本文提出一个声誉奖惩成本利息机制(Reputation, Reward-punishment system, and Cost-interest Mechanism,RRCM)框架来实现联邦学习激励机制的公平性,使得联邦系统中参与者分配的激励与其贡献度程度呈正相关趋势。
2. 通过引入声誉系统和奖惩措施,实现降低敌手攻击的风险和减少低贡献者存在的可能,提高联邦系统的保护机制。
3. 在基准数据集上的实验表明,本文提出的RRCM 框架能够实现较高的公平性,并且系统引入利润-收益机制,使联邦学习激励机制更加完善。
本文其余章节内容如下:“相关工作”回顾现有文献中的公平性标准和激励机制方式,为本文的研究提供实行基础;“RRCM 框架”介绍本文方法各模块的设计,以及模块间的关联;“实验”包括数据集的设置和实验的比较,从而证明本文提出的RRCM 框架更加合理。 最后,本文在“总结和未来发展”展开总结,并讨论联邦学习激励机制未来的研究发展。
2 相关工作
本节回顾有关联邦学习激励机制的文献,以便将以前的研究与现有研究相联系。
国内外联邦学习的同盟激励普遍分为Stackelberg 博弈、拍卖、契约理论、Shapley 价值和声誉信任五种类别[9]。 Stackelberg 博弈[10]主要用于制定不同参与者在销售或采购共同产品的互动。 文献[11]中Sarikaya 使用Stackelberg游戏模型来激励多个工人的CPU 供应,以减少FL 中心同盟的预算和SGD 本地培训时间;拍卖[12]是一种用于定价、任务分配和节点选择的数学工具。 文献[13]在移动边缘计算场景中提出了一种基于采购拍卖的FL 轻量化多维激励方案[14];契约理论[15]是在利益冲突和信息水平不对等情况下,参与者如何构建和发展最优协议。 在公共采购合同时,服务器向参与者提供一个合同菜单,在编写合同时不告知参与者的私人成本,每个参与者主动选择系统类型设计的选项;源于合作博弈论的Shapley 值[16]被联邦学习的贡献评估和利润分配广泛采用,基于Shapley值进行联盟成员的利益分配体现各盟员对联盟总目标的贡献程度,避免分配上的平均主义。 在文献[17]采用一种Shapley 组值的变体版本来衡量一个特征子集的效用,文中将一些私有特性合并为联合特性,并计算联合特性的Shapley 组值;声誉系统[18]是联邦学习激励的常用方式,杨强团队主要通过此种方式进行激励公平性的研究,文献[19]中引入声誉动态模型和声誉遗憾模型形成更具公平性的激励方式。
合理的联邦学习激励机制需对各个参与方公平[20]。 早期公平性机制主要代表是平均主义[21],不同同盟方在系统中训练迭代得到相同激励。 现在公平性标准主要将公平性分为贡献公平性、遗憾分布公平和期望公平[22]。 贡献公平性指数据所有者的收益须与其贡献呈正相关,遗憾分布公平指尽量减少数据所有者间遗憾和暂时遗憾的差异,期望公平指最小化数据所有者遗憾值和时间遗憾值的波动。
综上,联邦学习激励机制可以将声誉系统机制和贡献公平性相结合,通过声誉信任判断同盟方贡献度的高低,从而分配不同的奖励收益。 此外,还可以引入歧视率、奖励率和惩罚阈值等因素来深度讨论联邦学习的激励分配问题。
3 RRCM 框架
本节介绍在联邦学习系统中引入声誉系统、奖惩措施和成本-收益三种机制,从而形成基于声誉奖惩(RRCM)框架的联邦学习激励优化。本方案遵循的核心原理是:各参与方获取中心同盟激励与其贡献程度呈正关系。
本文采用联邦学习多个客户端通过本地数据集训练全局模型的标准优化模型:min{F(w)≅ψiFi(w)}。 其中F(w) 表示全局模型的梯度,Fi(w) 表示本地模型的训练模型,N表示联邦系统中参与方数量,ψi表示第i个参与方的权重,并且ψi≥0 和= 1。 在第t轮更新 时,: = ▽Fi(w(t-1)) 和Δw(t)=。
3.1 成本-利息机制
在传统联邦学习系统中,不同参与方参与联合训练需要提前向中心同盟上缴入盟费用,这些费用主要用于联邦系统的持续再生产过程。 例如,数据所有者构建本地模型上传给中心同盟,联合训练后的全局模型又可以与外部企业链交易得到收益。 然而模型聚合和商业化形成需要时间,从而导致中心同盟需积累足够的预算偿还同盟方的加盟成本。 现有联邦学习激励机制,如文献[23]中提出联邦学习激励器报酬共享方案,用以解决合伙费用偿还与激励暂时不匹配问题,不过此方法忽视成本的利息效用。 企业从初次加入同盟上缴入盟费用到联邦系统商业化形成分配激励,整个过程中心同盟不能仅仅偿还各参与方成本,还应考虑补偿成本产生的利息。
在联邦学习商业化过程中,中心同盟需事先要求参与方支付加入联邦系统的成本。 在激励补偿时,同盟系统先偿还参与方的成本-利息,然后在支付真正的奖励。 假设Ci为第i个参与方向联邦系统贡献的成本,第i个参与方偿还过程如下:
3.2 声誉系统
声誉系统是一种重定向自反馈机制,其可通过相关方协作认可来反映自身信用的状态,旨在表明声誉对于联邦决策的影响。 本文采取的声誉系统是根据各个参与方每轮的贡献程度,从而决定给予各同盟方激励的程度。 根据余弦相似度表示梯度质量的研究: cos(u,v) = 〈u,v〉/(‖u‖× ‖v‖),本文各参与方贡献度由局部权值和中心权值余弦相似度表示为=cos(,Δw(t))。 联邦系统初始阶段,各参与方初始声誉设置相同初始值(声誉阈值A)。 假设本轮暂时声誉和贡献度α存在一定正向关系≃α, 则(t)i可表示为cov(,Δw(t)), 本轮实际声誉可由历史声誉和本轮暂时声誉求得,公式如下:
其中β是可设置的权重系数,表示前一轮的声誉数值,表示本轮的暂时声誉。 由此,本框架通过声誉和贡献度之间的联系,从而分配不同数据所有者不同的激励。
3.3 奖惩措施
本文激励机制主要包括根据参与方每轮的贡献程度决定给予收益的大小。 除这种定性关系外,本文还考虑通过Pearson 相关系数描述数据所有者的贡献和奖励之间的关系,定量表示联邦学习激励机制的合作公平性。
定义1 合作公平性
假设参与方的实际贡献度为一组α,而其获得的奖励分配为一组σ, 则其合作公平性可表示为ρp(α,σ)。ρp(·,·) 表示Pearson 系数,且ρp(·,·) 越大,表示所提出的RRCM 框架更具有合作公平性。
本文框架除以上奖励措施外,还通过设置声誉阈值A方式制定相应惩罚措施,每一轮低于声誉阈值的数据所有者,将剔除出联邦系统,从而防止贡献度较低的参与方(如搭便车或充满敌意的参与方)破坏系统联合训练的结果。
3.4 整体框架
如图1 所示,参与方先将本地数据训练成模型上传时需通过信誉系统的阈值检测,如果声誉数值小于声誉阈值,则RRCM 系统消除具有异常声誉的参与方,如果声誉良好则通过检测。 良好的本地模型到达中心服务器经多次训练迭代后形成全局模型。 联邦系统可通过商业活动将全局模型与外部交互产生商业化利润。 其中一部分利润用于补偿给信誉良好的数据所有者,另一部分利润在中心服务器临时存储。 当联邦系统训练结束时,中心服务器会将暂时存储的收益返还给信誉良好的参与方,而声誉异常的参与方将不获得利润偿还。
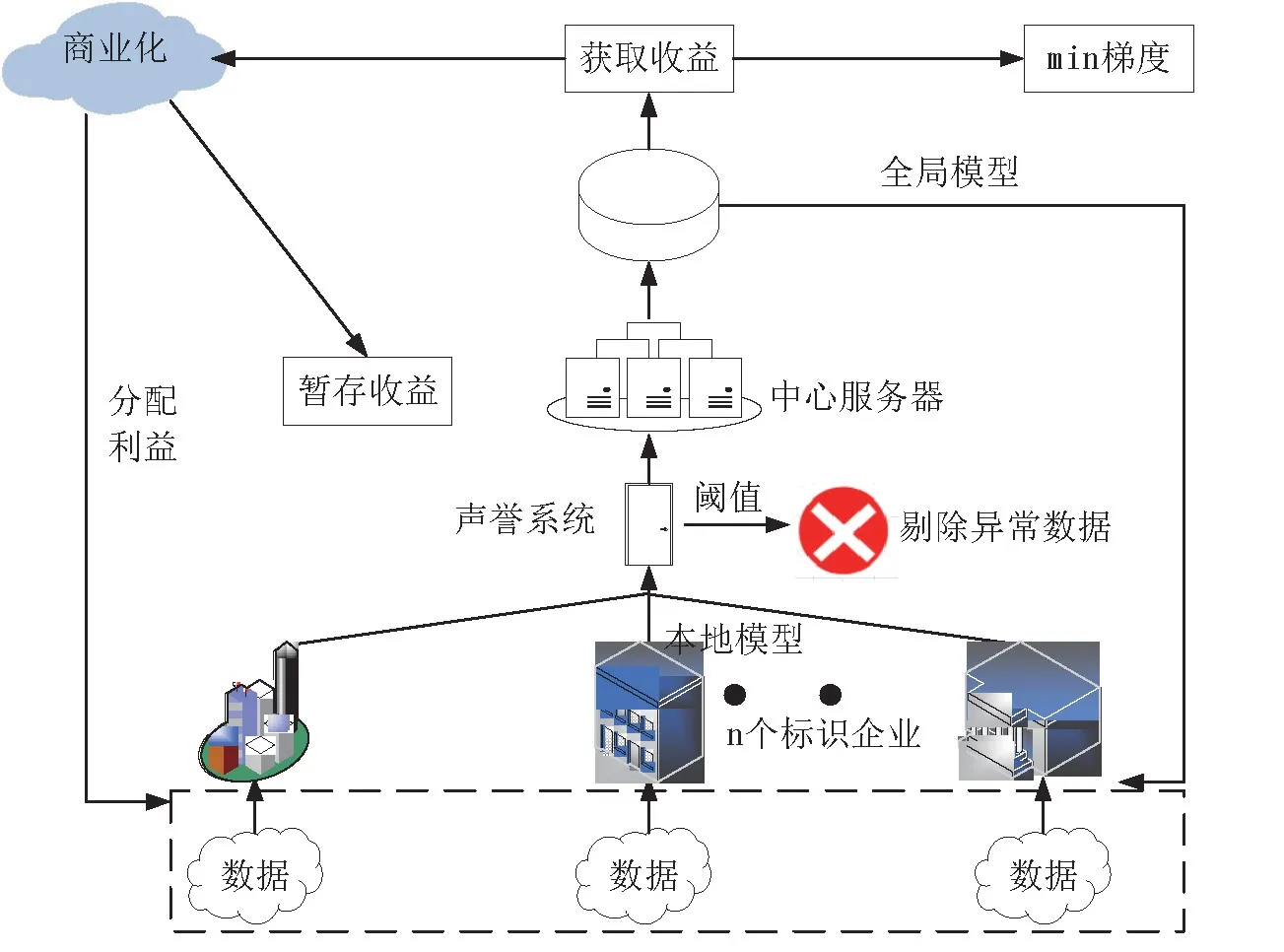
图1 联邦学习激励机制RRCM 框架
整体联邦学习激励机制RRCM 框架包括声誉系统、奖惩措施和成本-利息机制三部分,它们相互独立却又相互关联。 比如,成本-利息机制通过奖惩措施帮助联邦系统商业化收益更合理的补偿数据所有方的成本和利息,分配激励时又可通过声誉系统完成相应的奖惩措施,从而既使联邦学习整体系统更加公平合理,又能吸引更优质的参与者加入到系统中。 本文涉及的惩罚措施不仅为剔除出联邦系统,还包括中心同盟和参与方事先建立契约,数据所有者一定比例的成本保留在中心服务器不给予分配,当数据所有者的声誉低于一定比例时,中心服务器不再偿还贡献程度较低的参与方成本,且将其直接剔除系统。 由于各参与方寻求加入联邦系统获取更多的利益,所以它们会选择提供较高相似度的贡献,由于贡献程度低而剔除联邦系统的方法不将影响各参与方合作的积极性。
RFFL 的具体实现在算法1 如下:

算法1 RRCM输入:每个参与方加入同盟投资成本Ci,联邦系统回报的激励和利息率分别为ut i、γ,声誉阈值A。符号:r(t)i 、αti、σt i 和Tt 表示第i 个参与方第t 轮的声誉、贡献度、分配收益和中心同盟总收益,R = {i rti ≥A } 是一个良好的声誉集合,Δw(t)i 和Δw(t) 分别表示第t 轮i 的局部模型和全局模型,且中心同盟最初收益应为各个参与方的加盟成本Tt = ∑i=Ni=1 Si。参与方i:下载梯度▽w(t-1)i 、分配激励σti ( σt i ∈Tt )if ∑tt=1σti < ∑t t=1uti(1 + γ)此阶段是偿还成本if ∑tt=1σti > ∑t t=1uti(1 + γ)此阶段是实际收益本地训练得到本地模型Δw(t)i 并上传服务器:聚合:Δw(t) = ∑N i=1ψiΔw(t)i αt = cov(Δw(t)i ,Δw(t))for i ∈R do r~ti = ρρ(αti,σti)r(t)i = βr(t-1)i + (1 - β) r~ ti if r(t)i A then R = R{i} 剔除声誉过低的参与方Tt+1 = Tt -∑i=N i=1∑t t=1σt i + Si end if end for下载:分配梯度▽w(t+1)i 、分配激励σt i
算法1 中RRCM 框架惩罚措施有两种,其一是将声誉低于声誉阈值的参与方剔除出联邦系统,从而保障联邦系统训练梯度聚合的准确性。 其二是成本-利息中的补偿机制,联邦系统会将部分成本临时储存于中心服务器。 若参与方声誉从始至终大于声誉阈值,当训练结束时,中心服务器会归还临时存储的成本。 若参与方的声誉小于声誉阈值,则中心服务器不将此参与方临时存储的剩余成本退换给数据所有方。 此部分资金一方面可以用于更多商业化的投入,另一方面可以更多补偿给其他高贡献度参与方。表示中心同盟总收益过程。
4 实验
4.1 评估标准
本文通过三个指标作为本实验的评估标准:公平性、准确度和补偿趋势。 公平性通过定义1中的合作公平性定量表示,贡献度和激励间的皮尔逊系数(ρp(α,σ)) 越大,表示联邦学习的框架更具有公平性。 除了FedAvg[24]框架,本实验提出的RRCM 还和q-FFL[25]、CFFL[26]两种公平性标准框架相比较。 而准确度通过联邦系统输出结果和测试集相比较得出,本文提出的RRCM框架使用FedAvg 算法和声誉系统、奖惩措施、成本-收益三种机制结合,所以就准确性而言本实验框架只和FedAvg 相比较。 补偿趋势主要比较激励机制没有成本、考虑成本和成本-利息三种方案下激励机制的奖励趋势,从而确定本文提出的框架具有优越性。
4.2 数据切割
本文选取MNIST[27]和CIFAR-10[28]两种数据集完成本次实验的对照。 就标准IID 方面,本文选择数据集的统一切割,将其记做UNI;就Non-IID 方面,考虑数据的异质性,本研究根据幂率分布将样本在参与者中随机切分, 将其记做POW[29]。
4.3 超参数设置
参照联邦学习声誉激励相关文献,本文将信誉阈值设置为A= 1/(3N), 即每个联邦系统应贡献超过1/3 参与方的贡献比。 又根据工资分配原则,本文将中心同盟存储成本设置为S=1/(10T),联邦系统将此成本临时存储以防止数据所有方贡献较低相似度的模型。
4.4 实验结果
公平性比较:表1 列出不同数量参与方在MNIST 和CIFAR-10 两种数据集下不同合作公平性的数值,合作公平性数值可以通过皮尔逊系数计算。 根据表中内容,RRCM 性能明显优于FedAvg[24]、q-FFL[25]和CFFL[26]三种框架,所以本文提出的方案能使贡献度更高的数据所有方得到更好的准确度:表2 列出不同参与方通过RRCM、FedAvg 两种方式在UNI 和POW 情况下的准确度。 根据实验数据大体一致表明。 其中RRCM和FedAvg 的准确度相似,这是因为RRCM 框架中参与方的分配方式是借助FedAvg 算法。 不过在准确度一致的情况下,此方法比FedAvg 更具有公平性,所以RRCM 框架更具有优越性。

表1 常用框架的公平性比较

表2 FedAvg 和RRCM 的准确性比较
补偿趋势:如图2 所示,是联邦学习激励机制在三种情况下的补偿趋势仿真图。 左边表示不同补偿,右边表示不同激励。 根据图示,“没有成本”方案的参与者不需要中心服务器补偿成本,而是直接从联邦系统中获得激励。 在“成本”方案中,联邦系统应先补偿参与者的入盟成本,然后再分配参与方相应的激励报酬。 在“成本利息”方案中,联邦系统在分配激励前需先补偿参与方成本和成本附带的利息。 因此,在训练开始时“成本利息”方案并不直接奖励每个参与者,而是首先补偿每个参与者的部分成本和利息之和。 此外,“成本利益”方案通过暂时存储参与方的部分激励来保护整体系统的安全运行,所以此方案并不会在系统训练中提供与“成本”方案一致的激励。 但在系统整体迭代训练结束后,中心服务器会补偿声誉良好的参与者剩余的激励。

图2 补偿趋势仿真图
总之,根据准确性和公平性,RRCM 在公平性相似的情况下能提高框架的准确性。 根据补偿趋势,本方案引入成本-利息机制可以使得联邦系统更符合实际生活。 相比于传统框架,本文提出的RRCM 激励机制更具有优越性和合理性。
5 总结和未来发展
本文提出声誉系统、奖惩措施和成本-利息三种机制相结合(RRCM)的联邦学习激励优化,它对联合学习协作公平性优化改进。 在使得考虑参与方加入联邦系统产生成本-利息时,还能使参与方获得与其贡献度程度成正相关的激励。根据实验得出,本文提出的方案不仅能保证准确度无损,还能使公平性得到提升,由此本文提出的激励优化更具有优越性。 就奖惩措施方面,本文只是简单提出可将惩罚的参与方成本作为系统激励的措施,后续实验可以进一步改进奖惩方式,如引入阈值判定的容错机制或设置声誉异常次数的超参数等,希望此框架后续能够优化完善。
