基于中文发音视觉特点的唇语识别方法研究
2022-03-02袁家斌陆要要
何 珊,袁家斌,陆要要
1.南京航空航天大学 计算机科学与技术学院,南京211106
2.南京航空航天大学 信息化处,南京211106
人类语音互动本质上是多模式的,与他人交流时可以通过“听”和“看”来获取信息。在干净的声学条件下,听觉方式会携带大多数有用的信息,并且最新的技术水平已经能够自动准确地记录语音内容,准确率高达98%。而当音频通道被噪声破坏甚至没有声音时,视觉模态变得最有效,因为从中可以获得一定的语言特征。
唇语识别是融合了计算机视觉、语音识别和自然语言识别等多种技术的一个课题,目的是解码说话者嘴唇运动生成的文本。唇语识别具有广阔的应用空间,例如嘈杂环境中的语音识别、公共场所的静默听写、无声影视资料处理等。由于计算机视觉任务的进步,这种自动化应用是极具前景的。近年来,至少在数据集定义的词汇量有限的情况下,利用深度学习架构训练得到的唇读模型在很大程度上已经超过了专业读唇者。
几十年来,仅根据视觉特征来识别说话者所说的内容一直是一项挑战,难点之一就是如何提取嘴唇的视觉特征,以使模型具有更好的性能。
早在1984年,Petajan等人就提出了唇语识别模型[1]。1988年,在原工作的基础上,他们引入了矢量量化和动态时间规整等算法[2],并提出了新的相似度测量算法,极大地提高了唇语识别准确率。之后随着机器学习的崛起,隐马尔科夫模型(hidden Markov model,HMM)在语音识别领域取得了巨大成功,根据唇语识别和语音识别的相似性,出现了大量将HMM应用在唇语识别领域的研究[3-6],都取得了较好的结果。
近年来,由于深度学习的发展,使用卷积神经网络(convolutional neural networks,CNN)或长短期记忆网络(long short-term memory,LSTM)提取嘴唇特征已成为一种趋势,并且能显著提高唇读准确率[7-10]。在模型的构建上,通常采用以下两种方案:一个是连接时序分类法(connectionist temporal classification,CTC),另一个是带有注意机制的序列到序列结构(Seq2Seq),二者均可解决输入输出长度不一致的情况。从单词分类任务[9,11-13]到在字符级别转录大量单词[14],再到从静态图像预测音素[7]或视素[15],已经涌现出许多出色的工作。LipNet 使用CNN、LSTM 和CTC 损失构建句子级的端到端唇语识别网络[16]。Chung 等提出的WLAS(watch,listen,attend and spell)模型具有双重注意机制[14],可以仅输入视频、仅输入音频或二者均输入,实现在字符级别将开放域视频转录成大量英文词汇。刘大运等提出了一种双向LSTM 和注意力机制相结合的深度学习模型[17],解决了唇语识别中唇部特征提取和时序关系识别存在的问题。
马金林等人总结了较有影响力的唇语识别方法及语料库[18],可以看出,相比英文,中文数据集较少,识别工作较少且性能较弱。Yang等提出了一种用于开放域中文唇语识别的大规模数据集,名为LRW-1000,并相应提出了一个模型DenseNet-3D[19],但是他们仅对中文进行了单词分类,而不能在完整的句子级别上执行。针对句子级别的唇读,张晓冰等构建的CHLipNet 是一个两步式的端到端体系结构[20],其中使用了两个神经网络模型分别进行图像到拼音的识别以及拼音到汉字的识别。Zhao等则搭建了一个三级结构的网络[21],分别用于图像到拼音的识别、拼音到声调的识别以及拼音加声调到汉字的识别,且发布了第一个也是唯一公开的句子级中文视听数据集CMLR。
英文和中文有很多差异,最大的不同点在于:英文的最小单元为单词,而中文的最小单元是汉字,一个英文单词是具有语义的,汉字则要组合起来才具有语义;另外,中文发音在视觉上极具混淆性,体现在不同的词语因为有着相同的拼音序列,所以共享完全相同的唇形(例如“联系”和“练习”),甚至有着两个不同拼音序列的词语,因为发音相近,亦难在唇形上进行区分(例如“联系”和“电击”)。因此,在建立模型时要充分考虑到中文自身的特点,为了最大程度上减少视觉混淆对模型性能的影响,本文先研究说话者讲话时的唇型变化与实际发音的对应关系,对其进行归类,将最终得到的结果称为“视觉拼音”。基于此,提出一个中文句子级唇语识别模型CHSLR-VP,该模型是一个端到端的二级结构,整个识别过程分为视频帧到视觉拼音序列的识别和视觉拼音序列到汉字语句的识别。鉴于视觉拼音是基于中文拼音得出的,将更换CHSLR-VP前半段的建模单元为拼音,比较二者在中文唇语识别任务上的效果。基于CMLR数据集上的实验表明,该模型在视觉拼音上表现更好,且与其他唇语识别方法相比,基于视觉拼音的模型性能更优。
综上所述,本文的贡献如下:(1)根据中文发音的视觉特点得出“视觉拼音”,并首次将其应用于中文唇语识别领域;(2)构建了基于视觉拼音的中文句子级唇语识别模型CHSLR-VP,通过实验证明了视觉拼音可有效提升汉字识别准确率。
1 视觉拼音
汉字的发音可用拼音标记,而拼音由音节和声调组成,声调代表整个音节的音高,由于本文是对无声视频进行识别,故不考虑声调。通过对中文的研究可知,汉字发音可以用1 300 多个音节进行表示,一个音节又由声母和韵母组成。其中,声母是整个音节的开头,其余部分是韵母,声母有23个,可分为双唇音、唇齿音、齿龈音、龈颚音、卷舌音和软腭音,其具体发音分类如表1所示;韵母有39个,可分为单元音韵母、复韵母和鼻韵母,如表2所示。全部声母加上一个“ng”组成辅音,单元音韵母组成元音,二者统称为音素,音素是最小的语音单位,依据音节里的发音动作分析,一个动作构成一个音素。举例来说,“中国”一词由两个音节组成,可以分解为“zh,o,ng,g,u,o”6 个音素。中文音素共32 个,详见表3。

表1 声母发音分类表Table 1 Initials’pronunciation classification table

表2 韵母发音分类表Table 2 Finals’pronunciation classification table

表3 中文音素表Table 3 Chinese phoneme table
不同的发音部位和发音方法决定了声音的不同,但在没有声音仅依据视觉判定发音时,某些音素是很难进行区分的。为了减少这种歧义,提出一个新的概念——视觉拼音,它是将视觉上相似度较高的音素进行分组归类得到的,采取了如下技术手段:先将2.1节提到的视觉拼音预测模型修改成一个拼音预测模型,就是将拼音作为建模单元,把输入的视频帧序列预测成拼音序列;然后按照Neti等人的方法计算音素的混淆矩阵[22]。图1显示了6个混淆度最高的音素矩阵,横坐标代表预测得到的音素,纵坐标代表实际音素,颜色越浅代表混淆度越高。

图1 音素混淆矩阵Fig.1 Phoneme confusion matrix
仅根据混淆矩阵不足以最终确定视觉拼音,仍有以下三种情况需要考虑:(1)通过图1可知,最不易区分的是辅音,也即是声母部分。综合表1,“f”作为唇齿音和“b,p,m”具有一定的视觉相似性,为了进一步确定“f”的分类,观察了以“f”或“b,p,m”作为声母,韵母相同的汉字对应的嘴唇视频帧序列,截取了部分例子,如图2 所示。经过比较发现,“f”在发音时具有“咬下唇”的特点,而“b,p,m”则是爆破音,故“f”将单独划分为一类。(2)在音节中存在“y”和“w”,它们并不是实际意义上的声母,因为声母是一个音节开头的辅音,以“y”“w”为首的音节,虽然也处于开头的地位,但其实是元音“i”“u”的大写形式。按照中文拼音的拼写规则,当“i”“u”独立成音节时,必须在它们的面前分别加上“y”“w”,所以视觉拼音会纳入二者。(3)考虑到某些整体认读音节的发音与单个音素的视觉效果一样,将这样的音节也进行归类。综上所述,得到了如表4所示的视觉拼音字母表。

图2 “f”与“b,p,m”发音的视觉区别举例Fig.2 Examples of visual difference between pronunciation of“f”and“b,p,m”

表4 视觉拼音字母表Table 4 Visual pinyin alphabet
2 中文句子级唇语识别模型CHSLR-VP
CHSLR-VP模型是一个端到端的二级结构,其中以第1章提出的视觉拼音作为中间结果,最终得到无声视频中嘴唇运动序列对应的汉字文本。如第1章所述,视觉拼音是在嘴唇运动的基础上得到的,可以在一定程度上减轻视觉歧义。下面将详细分析模型的两个预测过程及其最终的整体架构。
2.1 视觉拼音预测模型
视觉拼音预测模型将输入的视频帧序列转为视觉拼音序列,其结构如图3所示。它基于带有注意机制的Seq2Seq体系结构,主要由两部分组成:视频编码器和视觉拼音解码器。
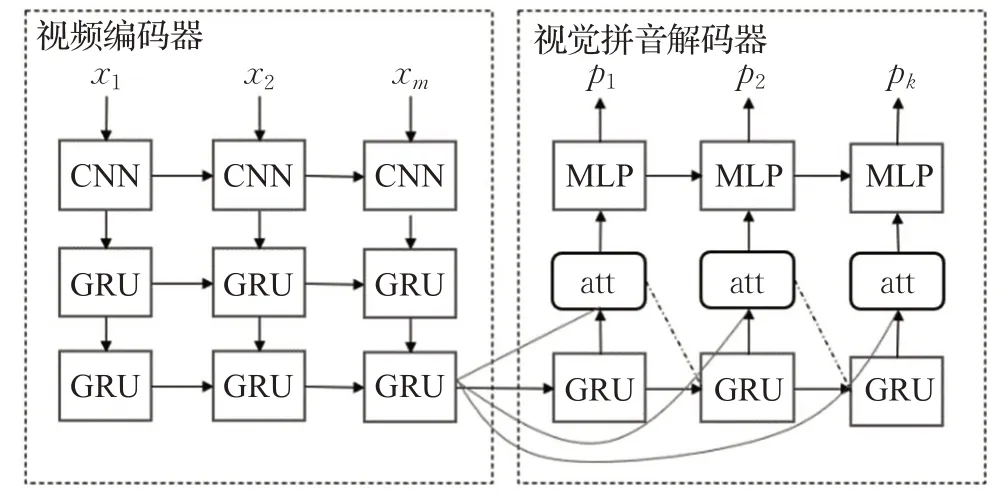
图3 视觉拼音预测模型Fig.3 Visual pinyin prediction model
视频编码器首先将视频序列xv输入到CNN 中以提取视觉特征,然后将特征向量输入到GRU。编码过程可以表示为:

视觉拼音解码器基于GRU 生成解码器状态和输出状态向量。在预测视觉拼音序列p时,在每个时间步长i使用视频编码器的输出来计算上下文向量。输出字符的概率分布是由MLP 在输出上使用softmax生成的。整个解码过程可以通过以下等式表示:
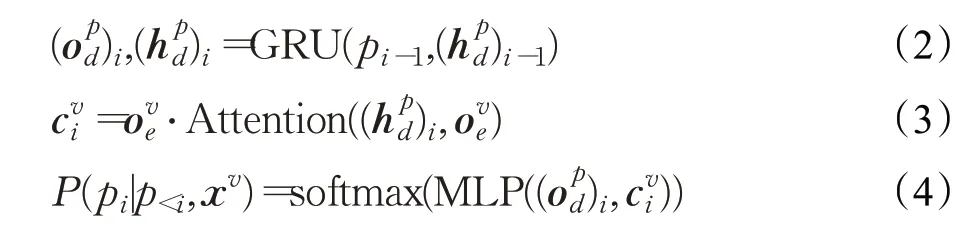
2.2 汉字预测模型
汉字预测模型可以将视觉拼音序列转为汉字序列。该结构如图4 所示,同样是基于具有注意机制的Seq2Seq结构。这里将编码器和解码器分别命名为视觉拼音编码器和汉字解码器。

图4 汉字预测模型Fig.4 Chinese character prediction model
视觉拼音编码器的操作类似于上述视频编码器。当汉字预测模型独立工作时,暂时先忽略编码器中的注意机制。另外,由于音节的总数只有1 300 左右,而中文汉字的数量超过了90 000,甚至常用汉字也超过了3 000。为了使模型更具鲁棒性,在训练过程中再额外引入大量的中文句子,增加的样本取自CCTV官网的新闻稿。
2.3 CHSLR-VP模型整体结构
从图4 可以看出,视觉拼音编码器使用了注意机制,但在汉字预测模型中并未起到作用,因为它需要视觉拼音预测模型中视频编码器的输出向量,目的是引入唇部特征来矫正视觉拼音序列,提升模型整体性能。因此,在CHSLR-VP 的训练过程中,将视觉拼音预测模型中视觉拼音解码器的输出和视频编码器的输出均输入到汉字预测模型中。至此,整个CHSLR-VP模型构建完成,当然,将对CHSLR-VP 进行重新训练以实现端到端模型。所提出的CHSLR-VP的体系结构如图5所示。

图5 CHSLR-VP的结构Fig.5 Structure of CHSLR-VP
3 实验
3.1 数据集
所有的实验均是在CMLR数据集上进行的,该数据集由浙江大学视觉智能与模式分析小组收集,是第一个开放式中文句子级视听数据集。数据内容来自中国电视网站,囊括了2009 年6 月至2018 年6 月录制的《新闻联播》,其中包含102 072个句子,25 633个短语和3 517个汉字。每个句子最多不超过29 个汉字,并且不含有英文字母、阿拉伯数字或标点符号。整个数据集按照7∶1∶2的比例随机分为训练集,验证集和测试集。
3.2 数据预处理
视觉输入由一系列视频帧组成,这些视频帧是嘴唇区域的一组三通道BMP图像,大小为64×80像素。10层的CNN网络用于从图像中提取嘴唇特征,所获得的512维空间特征向量构成视频编码器的输入。所有卷积内核均为1×3×3,所有最大池化stride 均为1×2×2,最大池化仅沿图像的宽度和长度方向执行。
对于视觉拼音,在预处理时需要改动三个地方:“you”对应的视觉拼音由“Iou”改为“Iu”;“wei”对应的视觉拼音由“UeI”改为“UI”;“wen”对应的视觉拼音由“Uen”改为“Un”。韵母中的“iou”“uei”“uen”分别对应“you”“wei”“wen”,预处理的目的是将嘴型一致的“iu”与“iou”、“uei”与“ui”、“un”与“uen”统一到一个标准,减少歧义。
对于文字,将对每个句子进行分词处理,如果该分词出现20 次以上,则将它作为一个固定整体。这样做的目的是将单个的字连接成一个有意义的整体,这在语言学上有一个专门的定义——语素,即指语言中最小的音义结合体。对于每个语素,都有其对应的视觉拼音组合和拼音组合,例如“中文”对应的视觉拼音组合为“RoNUn”,拼音组合为“zhongwen”。如此,便可减少低维度视觉拼音(16 个)及拼音(26 个)与高维度汉字(3 517 个)之间的混淆度,视觉拼音组合及拼音组合映射成汉字词的匹配度也就更高。最终,视觉拼音词汇的数量为3 287,拼音词汇的数量为3 537,汉字词的数量为3 584。它们都包括
3.3 训练与评估
为了验证CHSLR-VP的效果,选取了4种不同的模型与之进行比较,分别是CHSLR-PY、WAS、CHLipNet、CSSMCM,它们均为端到端唇语识别方法。CHSLR-PY是将CHSLR-VP的视觉拼音预测阶段改成拼音预测,以证明视觉拼音是否更适用于唇语的解读;WAS[14]是句子级唇语识别领域经典的方法,它将用于直接识别汉字;CHLipNet[20]和CSSMCM[21]均为和本文所提模型结构类似的中文句子级唇语识别模型,前者是二级结构(拼音预测和汉字预测),后者是三级结构(拼音预测、声调预测和汉字预测)。以上模型均在CMLR数据集上进行性能比较。
在训练时,将会通过Adam优化器优化真实字符转录与预测字符序列之间的交叉熵损失,课程学习和时间表采样策略用来提高性能,初始学习率设置为0.000 1,如果训练结果在4个epochs内仍未改善,则将初始学习率降低50%。
在评估中,测量了真实字符转录与预测字符序列之间的编辑距离,并通过真实长度进行归一化。对于所有实验,视觉拼音准确率/拼音准确率(PAR)和汉字准确率(CAR)被用作评估指标。PAR由1-(S+D+I)/N计算,其中S是从预测视觉拼音/拼音序列到目标视觉拼音/拼音序列所需的替代数,D是删除数,I是插入数,N是目标序列中的视觉拼音/拼音字符数量。CAR的计算方法同PAR,只是预测序列和目标序列均为汉字语句。
3.4 结果分析
表5确认了视觉拼音相比于拼音更适合解析唇语,且以视觉拼音作为媒介的CHSLR-VP 模型的预测结果(67.38%)明显好于以拼音作为媒介的CHSLR-PY 模型(61.77%)。出现这种现象的原因是:将拼音映射成视觉拼音降低了预测维度,将视觉上易混淆的元素合并到一起,使得唇形序列与预测单元匹配度更高。因此从表6中可以看见,单独训练的视觉拼音预测模型V2VP准确率(76.48%)明显高于单独训练的拼音预测模型V2PY(70.81%)。虽然在汉字预测阶段前者VP2H(89.13%)略逊色于后者PY2H(90.96%),但当两个子模型合并成一个整体时,CHSLR-VP在视觉拼音预测阶段取得的优势足以弥补甚至使得最终结果超过了以拼音作为媒介的CHSLR-PY模型。

表5 不同唇语识别模型在数据集CMLR上的性能比较Table 5 Performance comparison of different lip reading models on CMLR dataset

表6 CHSLR-PY和CHSLR-VP的性能比较Table 6 Performance comparison between CHSLR-PY and CHSLR-VP
表5 中还显示了CHSLR-VP 模型与其他唇语识别工作的对比结果。在同一数据集下,CHSLR-VP性能要优于其他模型,可以得出视觉拼音相较于拼音和汉字,能更准确地传达视频中蕴含的语言信息,也证明了本文所构建的这个二级结构模型的可行性。
建立的CHSLR-VP 模型目前存在以下两个问题:(1)使用视觉拼音归并了拼音,在大大提高视频解析精度的同时也会不可避免地降低汉字预测准确率。举例来说,表7 显示了一个用CHSLR-VP 预测得到的句子,其中错误地将“理性”预测成了“提醒”,因为它们的拼音“lixing”和“tixing”归纳成视觉拼音均表示为“DIJIN”,而“提醒”出现的频次远远高于“理性”,故得到错误的结果。(2)视频帧解析阶段,长句的预测效果远好于短句,这是由Seq2Seq模型本身的特性造成的,该结构本身就更适合解析长序列。

表7 CHSLR-VP预测的句子举例Table 7 Examples of sentences predicted by CHSLR-VP
4 结束语
本文基于中文发音的视觉特点对音素进行相似性归类得到视觉拼音;然后据此提出了一个中文句子级唇语识别模型CHSLR-VP。通过实验得出结论,提出的视觉拼音运用到唇语识别模型中能达到较好的效果,并证实了使用视觉拼音作为过渡过程的二级结构的有效性。在未来,希望对这项工作进行一些扩展:(1)收集更多的视听数据语料,通过更多的数据提高模型鲁棒性;(2)优化模型结构,探索更适合唇部特征提取或语句解析的方法以解决模型现存的问题;(3)参考语音识别或输入法,使其具有自动联想功能,提高预测语句的逻辑性,进而提高模型整体的识别率。
