基于FPGA的人脸识别系统实验设计
2022-03-02韩力英宁欣波
韩力英 宁欣波


摘 要:随着科技的快速发展,人脸识别技术逐渐进入了人们的生活中,成为了生活中密不可分的一部分。FPGA不仅能够进行数字系统设计,在人工智能领域也崭露头角。电子信息类本科生的实验安排也必须跟上人才培养的需求、时代的步伐,为此,开发了基于FPGA的人脸识别系统实验设计。该设计使用PYNQ实验板,利用Vivado HLS高级综合工具搭建电路系统,用python调用设计的电路建立卷积神经网络模型并训练神经网络,实现人脸识别技术,进一步加强学生学习EDA技术的意识。
关键词:人脸识别;卷积神经网络;PYNQ
中图分类号:G642 文献标识码:B
众所周知,我国集成电路领域人才缺口巨大,EDA技术是集成电路设计的核心。因此,EDA技术的发展才是集成电路卡脖子问题的关键所在。
随着人工智能以及机器学习、深度学习的快速发展,电子信息类本科学生的课程在不断地与时俱进,传统的实验设计已经不适合人才培养的需求,开发新的能够反映现代前沿信息技术的实验设计势在必行。对于公共场所,无接触识别生物特征识别系统开始成为确认用户身份的重要方式,其中人脸识别具有使用方便、识别更准确等优势,广受用户喜欢[1]。
本实验设计就是基于Xlinx公司的PYNQ开发板,采用Vivado HLS高级综合工具利用硬件资源搭建电路系统,用python调用设计的电路建立卷积神经网络模型并训练神经网络,实现人脸识别技术,进一步加强学生学习EDA技术的兴趣,激发学生解决我国集成电路领域卡脖子技术的热情,培养学生的大国工匠精神。
1 系统整体框架
尽管在不同的应用环境下,人脸识别系统的结构也有所不同,但大部分的人脸识别系统结构都包括人脸采集和检测部分、图像预处理部分、特征提取部分和人脸识别部分。人脸图像被输入系统后,将进行人脸检测和人脸对齐,然后用特征提取器提取特征,系统再将提取的特征与图库人脸进行比较,进行人脸匹配。
人脸图像采集和检测是根据人脸图像的模式特征,在采集到的图片中对人脸所在区域进行数据提取。
人脸图像预处理的目的主要是消除各种干扰,为后续人脸识别准确性做准备。人脸图像特征提取是提取包括口、鼻、眼等特征,主要是根据位置构成的几何结构等,以作为人脸图像特征数据。人脸图像识别就是通过提取一个人脸图像的特征数据。当提取到特征数据与某个模板相似度超过了设定的概率时,则认为这个特征匹配成功,否则匹配失败,同时输出一个特征匹配结果。
2 硬件设计
在卷积神经网络中,大量的计算是卷积的计算,FPGA的计算速度要比软件计算速度快,这也是为什么FPGA能够用于人工智能领域的原因,模型中所有的卷积计算和池化部分通过FPGA器件实现,这样可以使计算速度更快。
PL端的设计首先使用Vivado HLS软件实现卷积计算,然后将一些变量分别设置为输入和输出端口,在HLS软件中通过pipeline和unroll等方法进行优化设计,通过软件综合后查看硬件资源的使用量以及时序约束等情况,最后利用此高层次综合工具生成IP核。当使用unrolling方法进行优化时,折叠的for循环被展开,相当于电路被复制成需要的数量,假如使用N个相同电路,则只需要一步计算就完成,这就是为什么FPGA可以作为硬件加速器。如图1中,一个循环次数为6的for循环,当使用unrolling将其分为3个for循环后,原来需要6步完成的计算只需要2步就可以了。
几乎所有的优化方法都是以增大硬件资源开销来达到提高计算效率的目的。没有进行优化前使用的硬件资源(solution1)远低于使用unroll优化(solution2)后使用的硬件资源数量。随着集成电路制造工艺的发展,在单片FPGA上已经能够集成大量的硬件资源,所以在硬件上进行加速设计已经完全可行。可以通过同样的步骤做最大池化IP核,如图2所示。
设计好IP核之后就可以通过Vivado中的Block Design进行整体的电路设计。将设计好的电路通过软件生成bit文件和tcl文件,再将bit文件、tcl文件和hwh文件改为相同的文件名,放到PYNQZ2的文件夾中即可使用。
3 软件设计
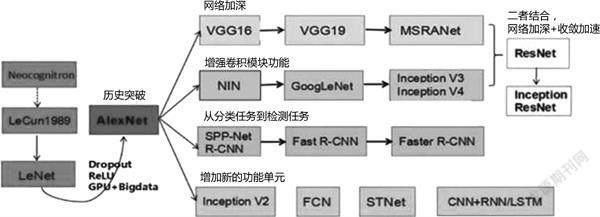
LFW人脸数据库[5]是设计用于人脸识别问题的人脸照片数据库。这个数据库里面的图像是RGB彩色图像。本实验设计可以使用LFW人脸数据库,也可以采集自己、同学等人脸照片进行识别训练。由于数据集不只是包含人脸数据,还包括身体等很多背景,所以需要对数据集中的图像进行筛选,首先提取出人脸部分,再进行随机旋转、翻转等几何变换,以增大训练集。现在流行的卷积神经网络算法如图3所示。
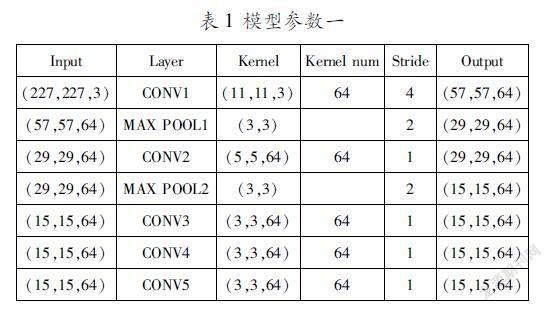
学生可以选择AlexNet网络模型,注意网络参数数量要适应PYNQZ2的内存空间大小。例如表1模型参数虽然可以满足训练要求,但是在移植到PYNQZ2开发板上时,由于参数数量太多,开发板的缓存根本装不下,但是在AlexNet模型上删减使用的卷积核数量,又会使训练效果不理想,准确率低,所以大家要考虑如何选择模型参数。例如可以降低最后一层的输出种类数,即将人脸识别的结果分为正确和错误两种,可以使正确率大大增加。如图4所示,是以LFW数据集作为训练集、训练的结果。
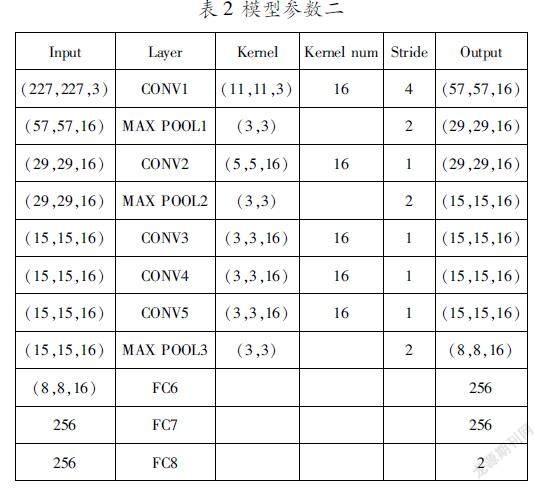
从图4中可以看出,随着训练次数的增加准确率在逐渐增加,采用二值结果,最后训练得到的模型准确率可达97%以上。但由于卷积核的数量越多,计算量就越大,相应的程序运行时间就越长,可以通过降低卷积核的数量来提高运行速度。表2是降低卷积核数量后的模型参数。
按照表2参数训练情况如图5所示,在图中可以看到训练的准确率在训练的第15次就稳定在了98%以上,尽管训练时间有所延长,但程序运行时间仅为按照表1参数的七分之一。
随着参数的降低,程序需要运行的时间虽然大幅度减少,但是训练所需要的时间也成倍增加,训练的准确率有所降低。要求学生综合训练时间、程序运行时间、准确率三方面因素,选择合适的模型参数进行训练和测试。
4 系统测试
可以在程序中设定检测到非人脸图片时,提示不是人脸,跳过人脸识别步骤,直接输出结果,不是人脸,结束识别任务。
可以针对所给出的前三种训练的模型进行人脸识别测试,当然也可以自己重新修改模型参数,找到最优模型。对比在什么情况下,识别效果最好。下面仅给出使用模型参数一对数据库中一幅图片進行识别的结果,要求学生自己进行其他图像或者自拍照片进行人脸识别。
结论
本实验设计采用协同异构的方法,在PYNQ上利用FPGA设计卷积IP核和池化IP核等硬件电路,利用开发板中的ARM部分调用硬件电路逐层搭建卷积神经网络,最终实现人脸识别设计,使学生对FPGA的认识从数字系统设计转变到人工智能领域设计。
参考文献:
[1]李霖潮.浅析人脸识别技术的发展[J].新型工业化,2020,10(03):129133.
[2]HSIAO J HW,COTTRELL G.Two fixations suffice in face recognition[J].Psychological science,2008,19(10):9981006.
[3]CHANDRA S R,PATWARDHAN K,PAI A R.Problems of Face Recognition in Patients with Behavioral Variant Frontotemporal Dementia[J].Indian journal of psychological medicine,2017,39(5):653658.
[4]SUN C C,AHAMAD A,LIU P H.SoC FPGA Accelerated SubOptimized Binary Fully Convolutional Neural Network for Robotic Floor Region Segmentation[J].Sensors,2020,20(21),6133:117.
[5]YANG Y X,WEN C,XIE K,et al.Face Recognition Using the SRCNN Model[J].Sensors,2018,18(12),4237:124.
基金项目:河北省高校教学改革项目“产学合作、协同育人背景下电子信息类创新实践课程的改革研究与实现”(2020GJJG033),河北省新工科教学改革项目“面向新工科建设,改革电子信息类实践教学模式,培养新型工科人才”(2020GJXGK055)
作者简介:韩力英(1977— ),女,博士,副教授,主要从事数字电子技术、EDA技术、DSP技术等相关课程的教学工作以及医学图像处理研究。
