基于中心核对齐的多核单类支持向量机
2022-03-01祁祥洲邢红杰
祁祥洲,邢红杰
(河北省机器学习与计算智能重点实验室(河北大学数学与信息科学学院),河北保定 071002)
0 引言
单类分类(One-Class Classification,OCC)是机器学习领域一个重要的研究内容,被广泛地应用于解决如疾病诊断[1]、文本分类[2]、入侵检测[3]等实际问题。在OCC 中最为常用的两种方法是单类支持向量机(One-Class Support Vector Machine,OCSVM)[4]和支持向量数据描述(Support Vector Data Description,SVDD)[5]。OCSVM 是Schölkopf 等[4]以传统的支持向量机(Support Vector Machine,SVM)[6]为基础提出的一种解决异常检测问题的核方法,其思想是将正常数据在高维特征空间中的像与原点以最大间隔分开,因为在训练集中没有任何异常数据的信息,因此将原点看作是异常数据的代表。SVDD 则是在特征空间中使用最小超球将正常数据的像包围起来。在特定的条件下,能证明OCSVM 与SVDD 等价[5,7]。
近年来,多核学习(Multiple Kernel Learning,MKL)方法获得了越来越多的关注[8]。与使用单个核函数的核方法相比,使用多个核函数的MKL 方法可以有效地处理数据异构、样本规模巨大和样本分布不平坦等问题。在MKL 中,最为关键的问题是确定核函数的组合权重。针对该问题,相关学者提出了许多相关的方法及模型。为了解决核函数及其参数的选取问题,同时减小核矩阵的计算量,Bennett 等[9]提出了多重加性回归核(Multiple Additive Regression Kernel,MARK)算法,在梯度提升及列生成算法的基础之上,MARK构造了异质核矩阵的列向量,并将它们加入到核集成中。Lanckriet 等[10]利用半定规划从数据中学习核矩阵,针对迁移学习情形,使用有类别标签的数据学习一个嵌入空间,然后应用于无类别标签的数据,测试样本之间的相似性由训练样本及其类别标签推理得到。实验结果表明,将多核组合起来产生的分类器取得了和最优的单个分类器接近的性能,此外,优于任何一个单核。Bach 等[11]将二次约束二次规划(Quadratically-Constrained Quadratic Programming,QCQP)的对偶形式考虑为一个二阶锥规划问题,并利用Moreau-Yosida正则化保持SVM 结构的稀疏性,从而使得生成的公式能够使用序列最小最优化(Sequential Minimal Optimization,SMO)技术进行求解。Sonnenburg 等[12]将QCQP[11]的对偶形式改写成一种基于列生成的半无限线性规划形式,并通过常规的线性规划求解方法进行求解。实验结果表明该方法有较强的适应性,可用于解决大规模的核函数组合优化问题,但需要大量的迭代才能收敛到一个较为合适的解。为了解决该问题,Rakotomamonjy 等[13]提出一种称为简单多核(simpleMKL)的基于混合范数正则化的MKL 方法,通过加权ℓ2范数正则化的方法来解决MKL 问题,并对核函数的权重增加基于ℓ1范数的约束来提高其稀疏性。实验结果表明,与文献[12]的方法相比,simpleMKL 具有更快的收敛速度。
最近,为避免对所有的核函数都分配相同的组合权重,Gönen 等[14]提出了局部多核学习(Localized MKL,LMKL),通过引入门模型(gating model)作为核函数的权重,然后将核函数与门模型相乘所得的组合核函数代入传统SVM 的优化问题中,并使用梯度下降法进行求解;然而,该方法的训练过程非常耗时且存在参数冗余问题。为了解决该问题,丁跃[15]在LMKL 的目标函数中增加了正则化项,并在门模型中使用ℓp范数,成功地解决了LMKL 的参数冗余问题,并进一步提高了其泛化性能。为了提高模糊支持向量机(Fuzzy SVM,FSVM)的抗噪能力,何强等[16]将MKL 引入到FSVM 中,提出模糊多核支持向量机,利用模糊粗糙集和核目标对齐(Kernel Target Alignment,KTA)[17]分别计算每个样本的隶属度和每个核函数的组合权重,进而将组合核函数引入到模糊支持向量机中,实验结果表明该方法有效地提高了FSVM 的分类性能和抗噪能力。针对聚类分析问题,Lu 等[18]提出基于中心核对齐的多核聚类(Multiple Kernel Clustering based on Centered Kernel Alignment,CKAMKC),使用中心核对齐(Centered Kernel Alignment,CKA)的方法将MKL 和聚类统一成一个优化问题,他们将缩放聚类隶属指标矩阵(scaled cluster membership indicator matrix)作为CKA 的理想核矩阵(idea kernel matrix)并将CKA 用作目标函数,通过两步迭代优化方法求取核函数的权重和缩放聚类隶属指标矩阵,进而求出组合核函数。Xue 等[19]将MKL 应用到特征选择中,在不确定核支持向量机(Indefinite Kernel SVM,IKSVM)的基本框架上,提出一种新的多不确定核特征选择(Multiple Indefinite Kernel Feature Selection,MIK-FS)方法,该方法对每个特征使用一个不确定基核,然后对核组合系数施加ℓ1范数约束去自动选择特征,通过一种两阶段交替优化IKSVM 和核组合系数的算法,将原IKSVM 的非凸优化问题转化为凸差函数规划,并利用仿射最小逼近将非凸优化问题转化为凸优化问题,进一步利用分数抽样方法选择样本点来解决大规模问题。此外,还将MIK-FS 扩展到多类特征选择的情况中。Wang 等[20]提出多Universum 经验核学习(Multiple Universum Empirical Kernel Learning,MUEKL)框架,利用不平衡数据来生成更有效的Universum 样本,MUEKL 通过引入正则化的Universum 数据,提出了基本的MKL 框架。引入正则化的目的是调整分类器边界,使其更接近于Universum 数据,来降低不平衡数据的影响。Oikonomou 等[21]将稀疏贝叶斯学习(Sparse Bayesian Learning,SBL)和MKL 相结合用于稳态视觉诱发电位(Steady State Visual Evoked Potential,SSVEP)的分类,首先在SBL 框架下使用多个线性回归模型判别SSVEP的类,然后利用变分贝叶斯(Variational Bayesian,VB)方法和MKL 方法学习每个模型的回归系数,从而将不同的核空间进行组合,并通过实验验证了该方法在处理不同核空间的有效性。后来,Wang 等[22]又将MKL 和最近比较热门的深度学习(Deep Learning,DL)相结合,其中一种方法是将DL 的思想应用到MKL 或者优化过程中。例如Rebai 等[23]提出自适应反向传播多层MKL 方法,该方法是将前一层中的多个基核组合起来,作为下一层的输入,然后使用梯度上升优化方法来计算每个核函数的权重,这种方法计算较为简单,可以成功地优化多层网络结构。但是上述方法仅限于监督学习情形。
虽然MKL 被广泛地应用于聚类、二分类和多类分类,然而它被应用于OCC 的研究却非常少。为了提高传统OCSVM的分类效果并避免核函数的选取问题,Gautam 等[24]将LMKL应用于OCSVM,与文献[14]相同,也是利用门模型确定核函数的组合权重,并利用梯度下降法求解相应的优化问题。实验结果表明,该方法能够生成较少的支持向量,且具有较好的稀疏性;然而训练过程非常耗时且存在参数冗余问题。为了避免参数冗余问题,He 等[25]利用多个具有不同参数值的同一种核函数构造组合核函数,采用KTA 方法求取最优组合权重,并利用组合核函数替代传统OCSVM 中的单个核函数。该方法不仅避免了核函数参数的选取问题,而且训练过程耗时较短;然而,该方法仅能求取向量维度上的相似性,不能表现出数据之间的相关性,由于没有将样本在特征空间中的像进行中心化,因此可能会产生病态矩阵[26]的问题。
为了避免核函数选取问题,同时提高OCSVM 的抗噪声能力,提出了一种基于中心核对齐的多核单类支持向量机(CKA based Multiple Kernel OCSVM,CKA-MKOCSVM)。
本文的主要工作如下:
1)使用CKA 方法求得核函数的权重。与KTA 相比,CKA 需要对样本在特征空间中的像进行中心化,使得这些像与原点的距离更近,从而避免产生病态矩阵,使得所提方法在分布较为分散的数据集上也能取得较优的分类性能。
2)用组合核函数替代OCSVM 中的单个核函数,可以解决核函数的选择问题,同时能够取得更优的抗噪能力。
1 相关知识
1.1 OCSVM
给定训练样本集D=,其中,xi∈Rd,i=1,2,…,N。OCSVM[4]首先通过非线性映射函数φ将样本点从输入空间映射到高维特征空间,然后在高维特征空间中最大化样本点的像与原点之间的间隔,最终求取最优分离超平面wTx-ρ=0,其中:w表示超平面的法向量;ρ表示截距即在高维特征空间中原点和超平面的距离。为了求取最优分离超平面,OCSVM 需要求解下面的优化问题:
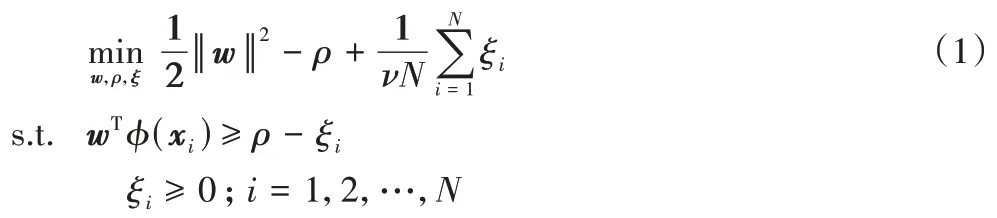
其中:ξ=(ξ1,ξ2,…,ξN)T且ξi是松弛变量;v为折中参数,是边界支持向量所占比例的上界,也是全部支持向量所占比例的下界。
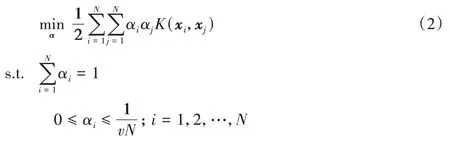
其中:αi是样本点xi对应的拉格朗日乘子且α=(α1,α2,…,αN)T;K(·,·)为核函数。
对偶优化问题(2)求解之后,对应于αi>0 的样本xi为支持向量。此外法向量可以表为:

截距ρ可以通过某个支持向量在特征空间中的像φ(xSV)及法线向量w的内积求取,即:
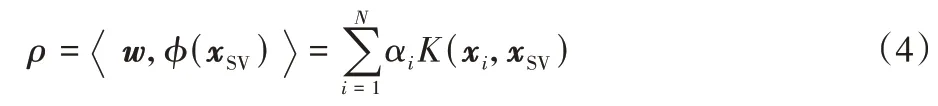
最后,OCSVM 的决策函数可以表示为:
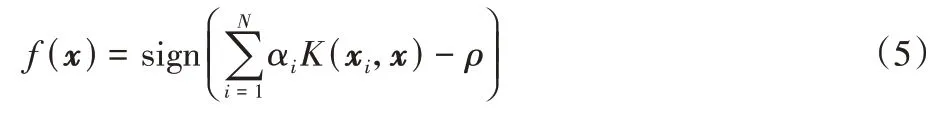
其中:sign(·)为符号函数。当决策函数值为+1 时,待测样本x被判别为正常数据;当决策函数值为时0,待测样本x则被判别为异常数据。
1.2 核对齐和中心核对齐
本文采用CKA 的MKL 方法来计算核权重,CKA 由经典的核度量方法——核对齐改进得到。所谓核对齐,就是在两个核函数(核矩阵)之间或者是核函数(核矩阵)与目标函数(矩阵)之间的相似性度量,是一种经典的核度量方法,它们之间的相似性越高,则它们的一致性也就越高,从而训练所得的分类器会具有较低的泛化误差。
定义1核对齐。[17]假设k1和k2是数据集上的两个核函数,则k1和k2在上核对齐的值为:

若训练集中仅包含样本信息,而无法获取目标函数知识时,经常会采用经验核对齐代替核对齐进行度量,其定义如下:
定义2经验核对齐。[17]假设k1和k2是数据集D={x1,x2,…,xN}上的两个核函数,对应的核矩阵分别为K1和K2(k∈RN,K∈RN×N),则K1和K2在数据集D上的经验核对齐定义为:
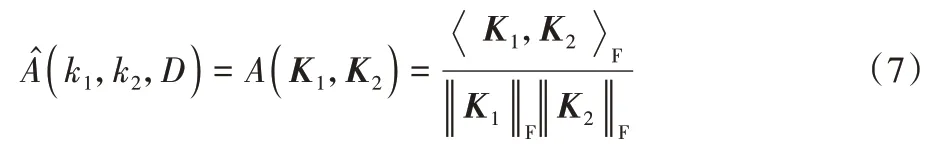
其中:K1和K2均为半正定的核矩阵。是Frobenius内积且‖·‖F表示Frobenius 范数(F 范数),它们分别定义为:

在一定条件下,式(7)所计算出的值是接近式(6)计算出的值[17],即可利用经验核对齐代替核对齐。此外,式(7)与余弦度量的公式相同,因此,若越接近于1,K1和K2就越相似。然而,式(7)仅考虑了向量维度上的相似性,而没有体现数据间的线性相关性。
在特征空间中,若原点远离样本的凸包,则核矩阵中元素可能会具有几乎相同的值,使得核矩阵存在病态问题[26]。为了解决该问题,引入CKA,它与经验核对齐原理相同,不同之处在于CKA 需要首先在特征空间中进行中心化,然后对中心化后的核矩阵再进行经验核对齐。
定义3中心核对齐。假设在数据集D={x1,x2,…,xN}上k和k′均为核函数,所对应的核矩阵分别K为和K′,则K和K′在数据集D上的中心核对齐定义为:

2 基于中心核对齐的单类支持向量机
2.1 数学模型
在MKL 中,存在多种不同学习方法来确定核的组合函数,其中常用的方法有以下五种:启发式[17,27]、固定规则[28]、最优化方法[29]、贝叶斯方法[30]和Boosting 方法[9],本文采用启发式学习方法。
所谓启发式学习方法,这里是指通过最大化CKA 来确定核的权重系数,也就是通过计算核矩阵之间的相关性来确定每个核函数的权重。所提方法包含两个阶段:第一阶段确定核组合权重μ;第二阶段利用组合权重μ学习多核单类支持向量机。
为了求取最优的核组合权重,需要最大化目标核和理想核之间的相关性,即:
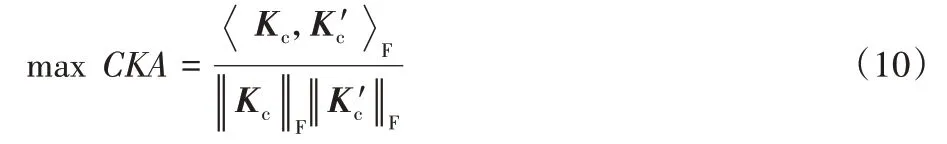
又因为:

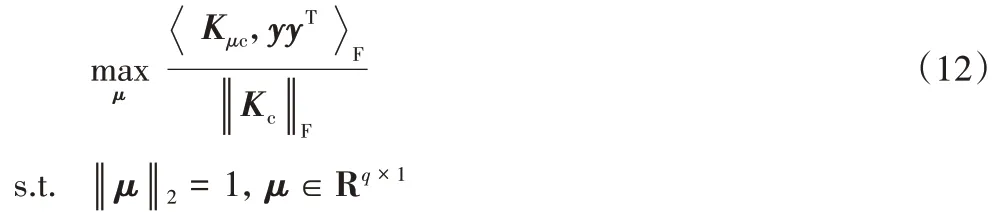
对于优化问题(12),在这里将采用解析式的方法进行求解,首先要将式(12)进行变换,改写成所需要的形式,即令
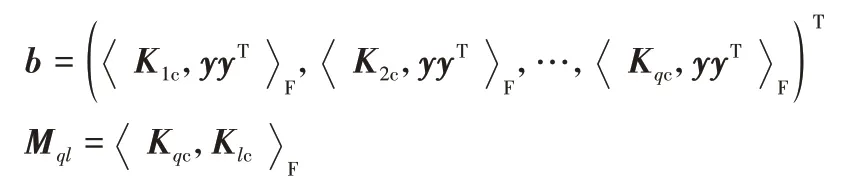
其中:q,l∈[1,p]。所以优化问题(12)可转化为:

假设μTb>0,在稍后给出证明,对优化问题(13)的目标函数式平方,可得:

因为μ为非零向量,M是非负对称的半正定矩阵。显然,优化问题(14)中的目标函数与广义瑞利商(generalized Rayleigh quotient)相同。可令μ=M-1/2η,代入式(14)可得:

根据瑞利商的性质,式(15)的最优解对应于M-1/2bbTM-1/2的最大特征值,最后可求得解,又因为M和M-1都是半正定矩阵,所以≥0。
将求得的μ引入到OCSVM 中,则优化问题(2)就转换成如下形式:
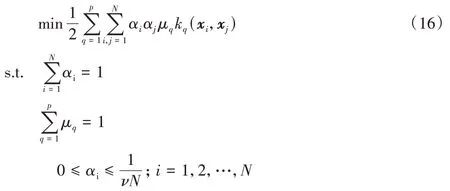
决策函数为:
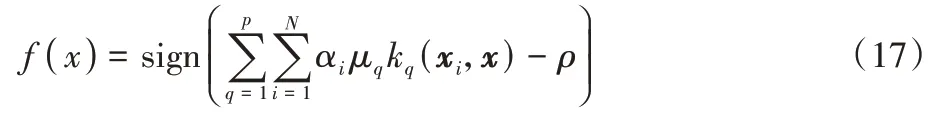
2.2 学习算法
CKA-MKOCSVM 算法的整个训练过程如下所示:

在算法过程中的第2)~4)步是计算核矩阵,计算复杂度近似为O(pN2),其中p是核矩阵的数量,N是训练样本的数量。第5)步的复杂度近似为O(pN2+pN3)。第7)步的复杂度近似为O(pN2+pN4),而第8)~9)步是OCSVM 的求解过程,也就是一个二次规划问题的求解,所以复杂度近似为O(N3)。综上,整个算法的计算复杂度近似为O(3PN2+(P+1)N3+PN4)。
3 实验与结果分析
为了验证本文所提CKA-MKOCSVM 方法的有效性,在20 个UCI 基准数据集上将它与其他五种相关方法进行了比较,UCI 基准数据集是均取自于UCI 机器学习数据库[31]。其他五种相关方法分别为:基于核目标对齐的多核单类支持向量机(Kernel-Target Alignment based Multiple Kernel OCSVM,KTA-MKOCSVM)[25]、局部多核单类支持向量机(Localized Multiple Kernel OCSVM,LMKOCSVM)[24]、基于径向基核函数的单类支持向量机(OCSVM with radial basis function kernel function,OCSVM(r))[4]、基于线性核函数的单类支持向量机(OCSVM with linear kernel function,OCSVM(l))[4]以及基于多项式核函数的单类支持向量机(OCSVM with polynomial kernel function,OCSVM(p))[4]。
所使用的UCI 基准数据集均被设计用于二类分类或多类分类问题,为了使它们适用于单类分类,将其中某一类样本用作正常数据,另一类样本用作异常数据。从正常数据中随机选取80%的样本用作训练集,剩余的20%正常数据和所有的异常数据用作测试集。所使用的20 个基准数据集的信息概括在表1 中,其中:Nta表示正常样本个数;Nnon-ta表示异常样本个数;Nfea表示特征个数;Ntr表示训练样本个数;Nts表示测试样本个数。
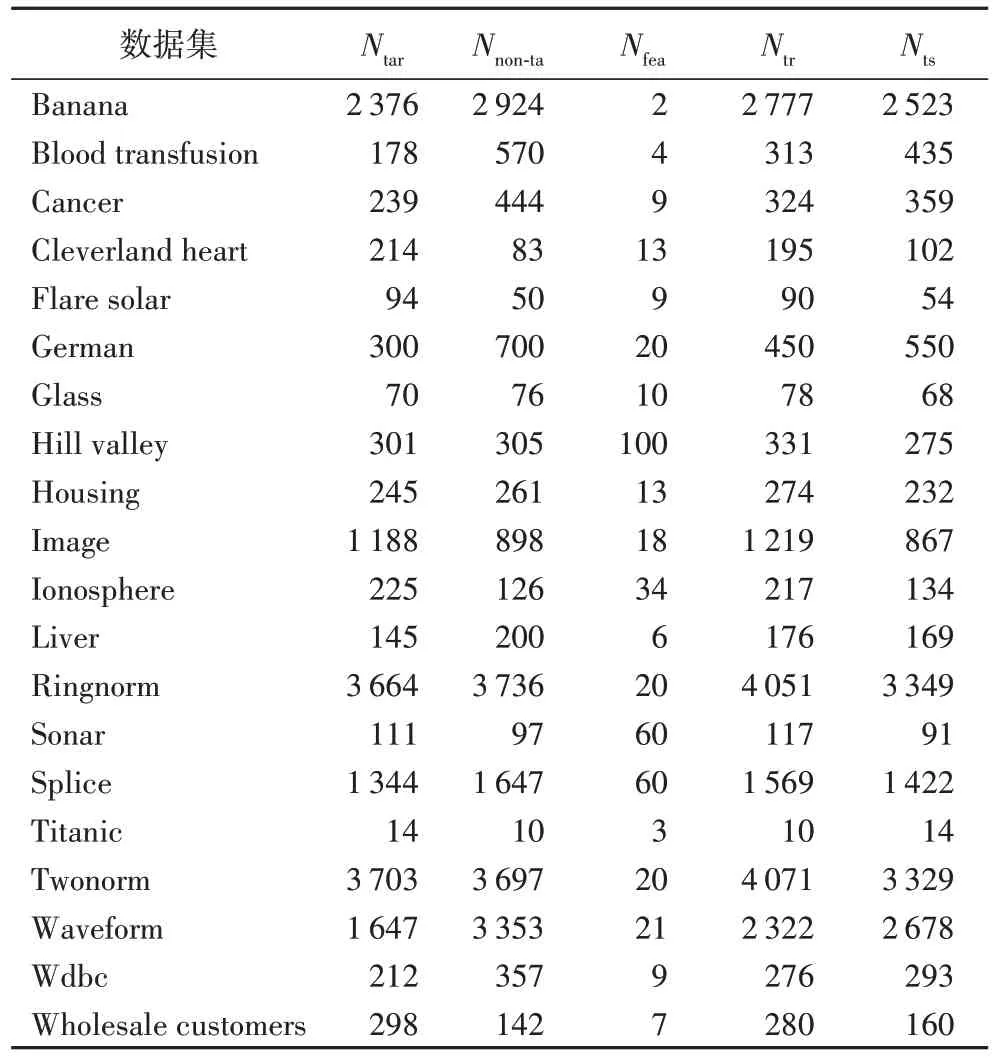
表1 实验中的数据集Tab.1 Datasets used in experiments
为了构造组合核函数,将选用三种不同类型的常见核函数,即线性核函数、多项式核函数以及径向基核函数。多项式核函数K(a,b)=(+c)n的参数设置为:γ=1,c=0 和n=4;径向基核函数K(a,b)=exp(-σ‖a-b‖2)的宽度参数σ在范围{10-5,10-4,…,103}中将使用穷举法进行参数选取;OCSVM 折中参数ν在{0.001,0.01,0.02,…,1}中选取。实验中的参数σ和ν在20 个数据集上的设置如表2所示。

表2 宽度参数σ和折中参数ν在数据集上的设置情况Tab.2 Width parameter σ and compromise parameter ν setting on UCI datasets
此外,在该实验中由于测试集的样本类别是非常不平衡的,所以无法使用传统的准确率来度量,为了降低样本类别不平衡对于实验结果的影响,将使用几何均值(geometric mean,g-mean)来度量单类分类器的分类性能。g-mean[32]可表示为:

其中:Recall表示召回率,即在正常数据样本上取得的准确率;Specificity表示特异度,即在异常数据样本上所取得的准确率。
最后,为了减轻训练集随机选取的影响,所有方法在每个数据集上均重复20 次实验,并将测试集上所取得的20 个g-mean 值的平均值用作最终的测试结果。六种方法在20 个基准数据集上的测试结果概括在表3 中。对于每个数据集,测试集上20 个g-mean 值的标准差也概括在表3 中来展示g-mean 值的稳定程度。此外,为了检验本文所提CKAMKOCSVM 与其他五种方法在统计上是否存在显著性差异,对CKA-MKOCSVM 与其他方法分别进行了成对T 检验,所得P值也概 括 在表3 中。
从表3 中的测试结果可以看出,CKA-MKOCSVM 在13 个数据集上取得了优于其他五种方法的泛化性能。尤其是在Cancer、Ionosphere、Hill valley、Ringnorm 和Twonorm 五个数据集上,CKA-MKOCSVM 的g-mean 值远远高于其他五种方法。由P值可以看出,除Liver 数据集外,所提方法与其他五种方法均存在着显著性差异。此外,从表3 中的测试结果还可以发现:
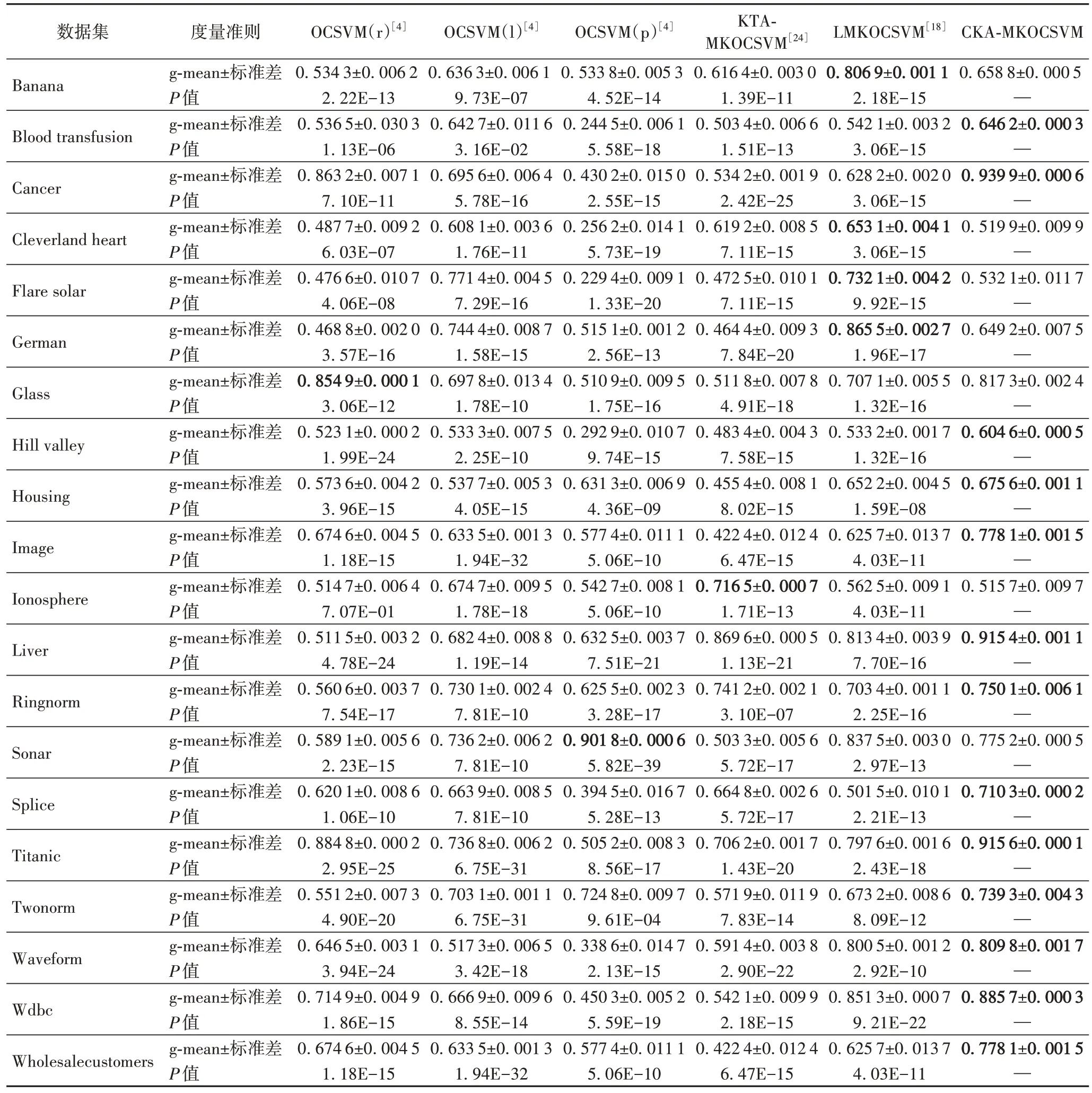
表3 六种不同方法在20个UCI基准数据集上取得的测试结果Tab.3 Test results obtained by six different methods on 20 UCI datasets
1)与单核OCSVM 相比,本文所提CKA-MKOCSVM 将不同类型的核函数组合在一起,并为不同的核函数分配不同的权重值,在处理不同复杂程度的数据时,就能充分发挥不同核函数的优点,从而取得优于单核OCSVM 的性能。
2)与未进行中心化的KTA-MKOCSVM 相比,本文所提CKA-MKOCSVM 将样本在特征空间中的像进行中心化,使得这些像与原点的距离更近,从而避免产生病态矩阵。此外,CKA-MKOCSVM 对于分布较为分散的数据集具有较优的分类效果。
3)与LMKOCSVM 相比,CKA-MKOCSVM 的优化问题更易求解。LMKOCSVM 利用梯度下降算法进行求解,需要消耗较长的迭代时间,且其门函数还存在参数冗余问题[15]。相比之下,CKA-MKOCSVM 的最优解可以解析求得,无需迭代,LMKOCSVM 需要在目标函数中添加正则化项和使用门函数的范数形式来解决门函数的参数冗余问题;而CKAMKOCSVM 中不存在参数冗余问题。
所以,本文提出的CKA-MKOCSVM 方法在处理一些较为复杂的数据(如高维数据)和在特征空间中分布比较分散的数据都有较为理想的结果。
然而,CKA-MKOCSVM 在Banana、Cleverland heart、Flare solar、German、Glass、Image、Liver 和Splice 上的处理效果并没有其他原有的五种方法好,其原因主要是对样本在特征空间中的像经过归一化和中心化处理后,分布较为密集,使得正常数据和异常数据难以准确区分,从而产生较差的效果。
最后,为了检验本文所提CKA-MKOCSVM 的抗噪声能力,在训练集加入了5%~30%不同比例的异常数据作为噪声。图1 展示了6 种不同方法的测试性能随噪声比不同的变化情况。所选用的6 个数据集分别为Cancer、Wdbc、Ionosphere、Wholesale customers、Twonorm、Ringnorm。由图1中的测试结果可以发现,随着噪声比的增加,6 种方法的g-mean 值均呈不同程度的下降趋势。本文CKA-MKOCSVM方法在6 个数据集上均展示了较优的测试性能,尤其在Cancer、Wdbc、Twonorm 上,其g-mean 值明显高于其他5 种方法。在Ionosphere 上添加噪声后,CKA-MKOCSVM 所对应的性能曲线几乎与OCSVM(r)完全重合,虽然在噪声比为25%时,OCSVM(r)的g-mean 值较高,但是两种方法整体上相差很小;同时,CKA-MKOCSVM 在该数据集上优于其他4 种方法。在Ringnorm 上,CKA-MKOCSVM 和KTA-MKOCSVM 的性能曲线几乎重合,即这两种方法的测试性能几乎相同。因此,本文CKA-MKOCSVM 能够综合利用三种不同类型核函数的优点,既不用考虑如何选取核函数,又取得较优的抗噪声能力。
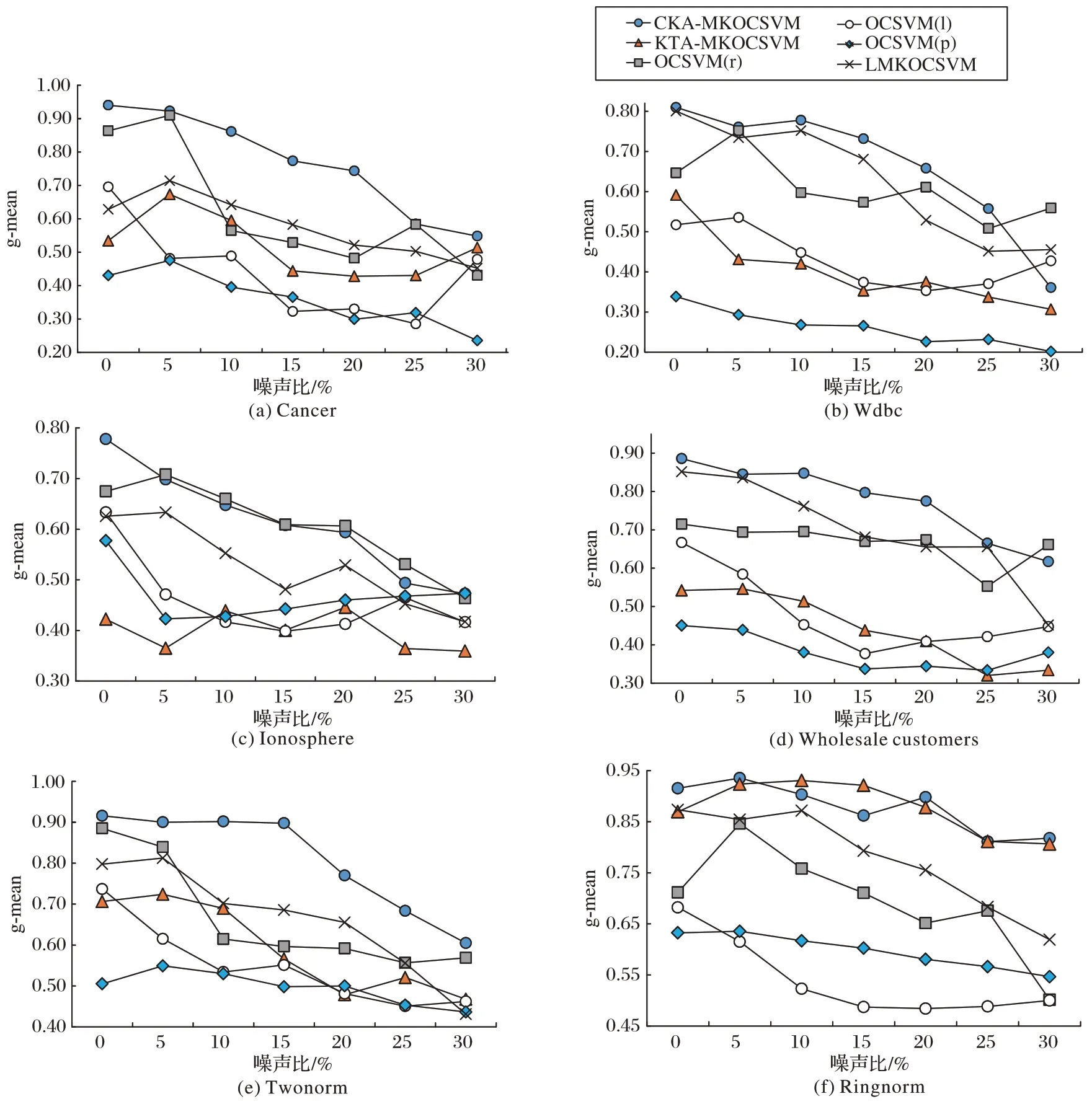
图1 6种不同方法在6个数据集上的测试性能随噪声比不同的变化情况Fig.1 Performance of 6 different methods varying with noise ratio on 6 datasets
4 结语
传统OCSVM 常常面临核函数选取的难题。为克服该难题,提出了CKA-MKOCSVM。本文方法的构造过程由两个阶段组成:第一阶段,利用CKA 求取核函数的组合权重;第二阶段,利用组合核函数替代OCSVM 优化问题中的单个核函数。实验结果表明,与其他5 种对比方法相比,本文方法具有更优的泛化能力和抗噪声能力。
虽然该方法能克服OCSVM 的核函数选取问题,但由其算法的计算复杂度分析可发现,该方法的训练复杂度较高,需要耗费大量时间。在未来工作中需要对组合核的求解方法进行改进,如采用SMO 优化算法[33]等方法;并且本文核函数只选择了最为常用的3 个,还应该进一步探索其他的核函数并进行组合。
