基于类间距优化的分心驾驶行为识别模型训练方法*
2022-03-01付俊怡夏金祥
张 斌,付俊怡,夏金祥
(1. 电子科技大学信息与软件工程学院,成都 610051;2. 中国地质大学(武汉)经济管理学院,武汉 430000)
前言
分心驾驶行为,如使用手机、吃东西、与乘客聊天、调整中控等,会引起大量的交通事故。美国高速公路安全管理局的数据显示,仅2019年美国就有3142 人因驾驶员分心驾驶在车祸中丧生,约424000人受伤,因此分心驾驶行为识别研究对保障人民生命财产安全具有重要意义,同时也是高级辅助驾驶系统(advanced driving assistance system,ADAS)的一个研究热点。目前的分心驾驶行为识别方法可以分为以下3类:
(1)基于驾驶员体征的分心驾驶行为识别方法;
(2)基于视频流的分心驾驶行为识别方法;
(3)基于单帧图像的分心驾驶行为识别方法。
基于驾驶员体征的分心驾驶行为识别方法要求驾驶员穿戴各种体征传感器,通过读取驾驶员的体征信号,如EEG 信号等,来识别驾驶员是否有分心驾驶行为。此类方法只能识别疲劳驾驶之类的行为,且会影响驾驶员的驾驶体验。
基于视频流的分心驾驶行为识别方法要求在车内部署摄像头,一次性提取多帧的图像信息来进行行为识别。文献[5]中使用3D 卷积识别动作,3D 卷积相对于2D 卷积多出1 个通道,可以一次性对多帧进行处理;文献[6]中使用Kinect设备来提取视频帧中驾驶员的骨架图,然后将多帧的骨架图序列送入图神经网络完成分心驾驶行为分类;文献[7]中采用基于空间信息的卷积神经网络模型和基于时间光流信息的卷积神经网络模型共同识别分心驾驶行为。这些方法虽然取得了很好的效果,但是要求模型一次性处理多帧的图像,对终端设备的计算能力有极高的要求。
基于单帧图像的分心驾驶行为识别方法将分心驾驶行为识别任务转化为驾驶图像分类任务,通过采集单张图像判别驾驶员的动作。由于模型一次仅处理一帧图像,对终端设备的算力要求不高,本文所提改进方法属于该类。
当前图像分类方法不断进行改进。文献[8]中首先使用一个区域提取网络(region proposal network,RPN)来提取图像中与驾驶行为有关的ROI(region of interests),然后再使用卷积神经网络对ROI 进行分类,排除了无关区域的干扰。文献[9]中提出双注意力卷积神经网络(double attention convolutional neural network,DACNN),通过在卷积神经网络中添加注意力模块,使模型更好地关注重要区域的特征。文献[10]中提出了一种模型融合方法(hybrid CNN framework,HCF),将3 个高性能的卷积神经网络模型融合,使用融合后的模型来对驾驶图像分类。本文在2.1 节中将所提类间距优化方法与DACNN、HCF这两种典型方法进行对比。
与图像分类的通常方法相比,这些改进方法在提高识别准确率的同时,在模型中添加了其他模块,增加了模型的推理时延,在一定程度上降低了实时性。
与上述文献[8]~文献[10]不同,本文提出的基于类间距优化的分心驾驶行为识别模型训练方法,不是对模型结构进行优化,而是对模型的训练过程进行优化。虽然该方法对模型进行了略微修改,需要模型同时输出预测值与特征向量,但是并未添加任何模块,因此不增加模型的推理时延,保证了实时性。
在细粒度图像分类方法中,文献[11]中提出了Part-RCNN 方法,该方法首先提取出图像中一些重要的区域,然后使用RCNN 算法对这些区域进行进一步处理,综合所有区域的信息最后得出该图像的类别,然而该方法要求额外的监督信息(需要对图像中重要区域的位置进行标注)。文献[12]中提出了双线性卷积神经网络,该网络中含有两个卷积神经网络,其中一个网络用来提取位置信息,一个网络用于提取内容信息,这两个信息都用向量表示,最后对这两个向量的外积使用softmax 函数完成分类。虽然该网络取得了很好的效果且不需要额外的监督信息,但是该网络在训练与推理时的计算开销极大。文献[13]中的方法与本文类似,应用在细粒度车辆图像分类领域,该方法在训练过程中引入了类间特征向量的距离损失,然而该损失函数使用的是triplet loss,一次反向传播要求输入3 个样本(2 个同类样本,1 个异类样本),由于triplet loss 需要二分类的标签,当分类任务的类别大于2 时,需要构造标签结构树,也就引入额外的监督信息。相较于文献[11]~文献[13],本文提出的方法既不引入额外的监督信息,又不增加模型推理时的计算开销。
分心驾驶行为识别也可以看作为一个细粒度图像分类任务,即图像中一小部分区域决定了该图像的类别。如图1 所示,一张图像是正常驾驶还是与副驾驶聊天完全由驾驶员的脸部朝向来决定。对于类似的这种图像差异很小的类别,按照图像分类通常训练方法得到的模型无法实现高准确率的分类。针对这一问题,本文借鉴了FaceNet与原型网络的思想,提出了基于类间距优化的训练方法。

图1 正常驾驶和与副驾聊天
FaceNet 将每一张人脸图像转化为一个特征向量(通常由卷积神经网络最后一个卷积层的输出经过全局平均池化得到),并在训练时要求不同人脸的特征向量之间的距离大于一定阈值,来强迫模型学习到不同人脸间细微的区别。因此,增大不同类的特征向量之间的距离,可以提高模型对那些图像差异很小的类别的分类准确率。由于FaceNet 使用的triplet loss 仅适用于二分类任务,因此在训练时,对于特征向量的优化,采用原型网络的损失函数。模型训练完毕后本文还使用CAM 图(class activation mapping)对模型进行解释。
本文的主要创新点如下。
(1)通过绘制混淆矩阵与特征向量经过PCA(主成分分析)降维的散点图,得出以下结论:对于容易混淆的两类分心驾驶行为,模型对这两类图像提取的特征向量之间的距离过小是导致容易混淆的原因。基于上述结论,本文中将类间距优化的思想应用于分心驾驶行为识别场景。
(2)提出了基于类间距优化的分心驾驶行为识别模型训练方法,该方法在一次反向传播过程中,同时对模型预测值与特征向量进行优化,实现了端到端的训练。该方法通过提高模型对那些图像差异很小的类别(易混淆类)的分类准确率,进而提高总体的准确率,既不增加模型的推理时延,又不引入额外监督信息。
1 基于类间距优化的模型训练方法
1.1 模型混淆图像差异很小的类别的原因
为了探究模型无法高精度地区分图像差异很小的类别的原因,本文中使用公开的分心驾驶行为识别State Farm 数据集(部分样本见图2)进行实验,State Farm 数据集为2015年State Farm 公司在kaggle平台上举办的驾驶行为图片分类比赛所使用的数据集,包含10 类分心驾驶动作:正常驾驶、左手打电话、右手打电话、左手玩手机、右手玩手机、调整中控、化妆、侧身取物、喝水、与副驾聊天。为了方便试验,本文对数据集进行了裁剪,在State Farm 数据集中选取每类1000 张组合成10 类共10000 张样本的测试集,另选取每类200张组合成为10类共2000张样本的训练集。

图2 State Farm数据集部分样本
本文使用通常的图像分类训练方法和基于类间距优化的训练方法分别训练CNN 模型(见2.1 节),训练好的模型分别标记为模型X 和模型Y。CNN 模型选用MobileNetV2,其原因是车载设备算力有限,只能选择轻量级的卷积神经网络模型,而MobileNetV2正是目前使用最广泛的轻量级模型。
模型在测试集上的混淆矩阵如图3所示,0~9标签分别表示正常驾驶、左手打电话、右手打电话、左手玩手机、右手玩手机、调整中控、化妆、侧身取物、喝水、与副驾聊天,图3(a)为模型X在测试集上的混淆矩阵,图3(b)为模型Y在测试集上的混淆矩阵。
通过图3(a)可知,有195 张正常驾驶的测试样本被误判为与副驾聊天,这类误判也是模型X 最容易混淆的一类(图3(a)中195 是除对角线以外最大的数),本文中使用模型X提取所有正常驾驶和与副驾聊天这两类测试样本的特征向量(特征向量为CNN 全局平均池化层的输出,详见图5),并使用PCA 将特征向量降到2 维,如图4(a)所示,圆点代表正常驾驶样本的特征向量,三角点代表与副驾聊天样本的特征向量。

图3 模型在测试集上的混淆矩阵
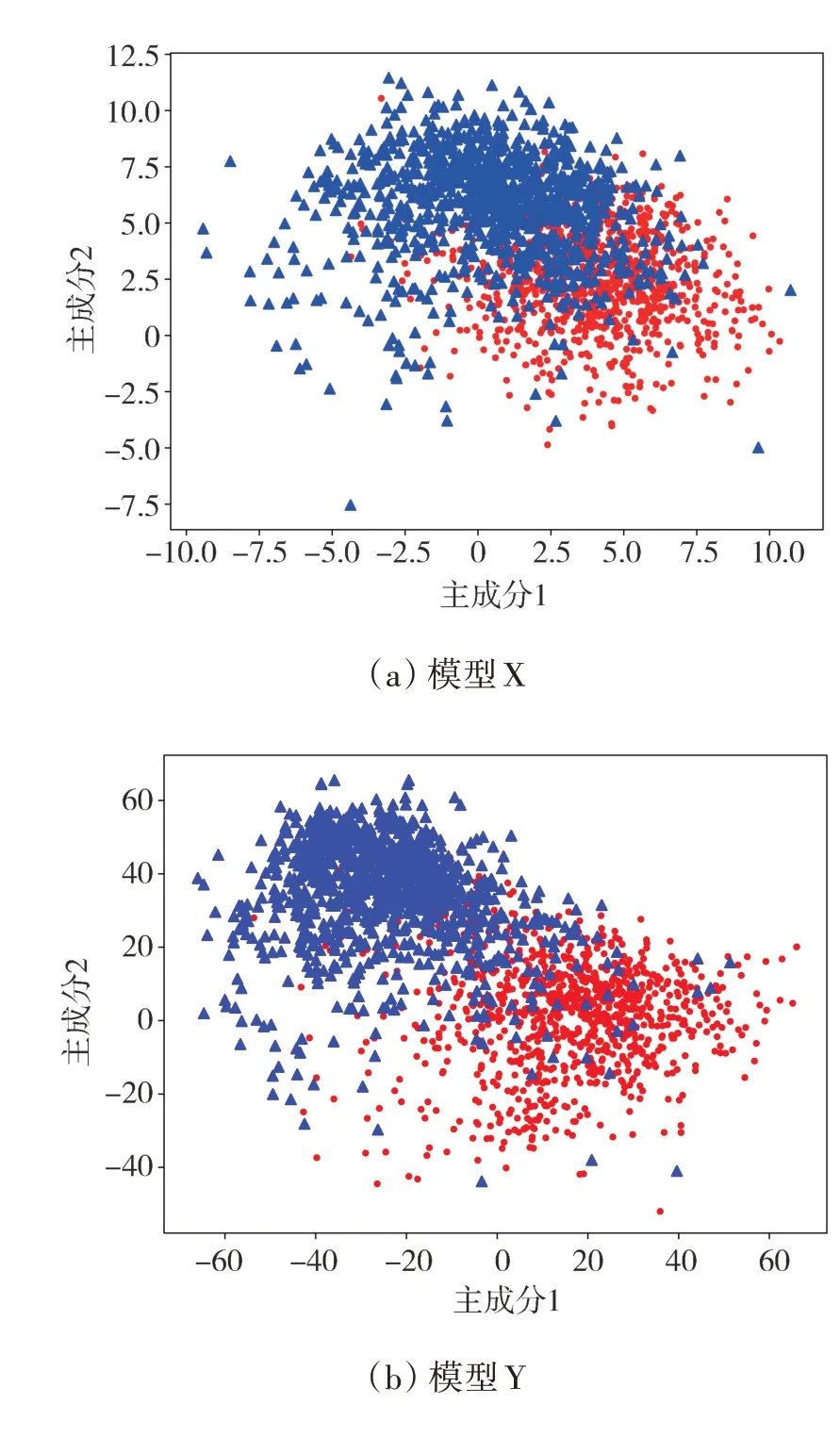
图4 模型对正常驾驶和与副驾聊天两类样本提取特征向量的PCA降维散点图
从图4(a)中可见,圆点与三角点之间并没有清晰的边界,尤其是正中间的一些点混在一起,模型X对正常驾驶和与副驾聊天两类样本提取的特征向量都容易混淆,更不可能使用这些特征向量完成高精度的分类。相对而言,本文提出的基于类间距优化的训练方法在训练时就要求增强不同类别样本的特征向量之间的距离,如图4(b)所示,使用模型Y提取的两类特征向量虽然还是有一些混淆,但是大体上已经呈现左右两个分布,因此在图3(b)模型Y 的混淆矩阵中,与图3(a)相比,模型混淆正常驾驶和与副驾聊天这两类的样本数量已经大幅下降(195+22 下降到89+60)。
1.2 所提方法的具体训练步骤
本文提出的基于类间距优化的训练方法如图6所示,在一次反向传播的过程中,本文的训练方法要求输入一个-way、-shot的支持集:

图6 基于类间距优化的训练方法示意图
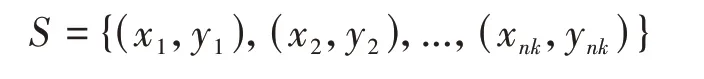
一个个样本的查询集:
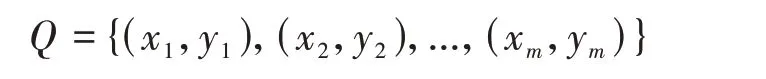
查询集的样本与支持集的样本没有重叠,这与原型网络的输入一致。与原型网络不同的是,原型网络仅对模型输出的特征向量进行优化,而本文所提方法还需要对预测值进行优化(使预测值贴近标签)。因此本文对CNN 模型进行了修改,使得该CNN模型不仅输出特征向量,还输出预测值,这样给定一张图片,模型就可以输出其预测值与特征向量,修改后的CNN 模型如图5 所示(CNN 模型具体为MobileNetV2,包含上百层,中间层没有绘制)。

图5 输出特征向量与预测值的CNN模型示意图
本文所提的训练方法包括3 个损失函数:、、,总的损失函数记为(,,),其计算公式如下:
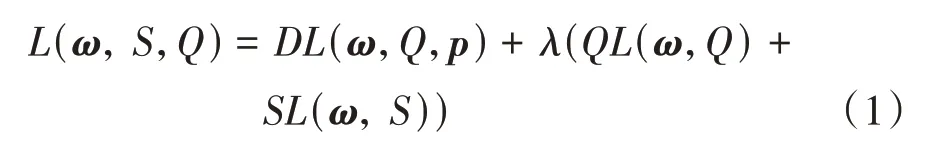
式中:表示CNN 模型的参数;为超参数;表示计算的函数,用于优化特征向量;表 示 计 算的 函 数;表 示 计算的函数,这两个损失用于优化预测值,使预测值贴近标签。如果去掉,那么本文的改进方法可视为输入batch size 为的图像分类的通常方法。下面分别介绍这3 个损失函数。
1.2.1
为优化特征向量所用的损失函数,计算步骤如下。
(1)首先提取支持集所有样本的特征向量,由于支持集是-way、-shot 的,对每一类样本的特征向量进行平均,可以得到个原型。其公式如下:
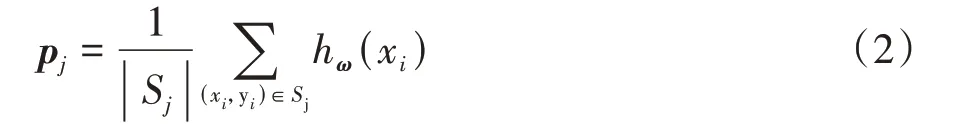
式中:S为支持集中标签为的所有样本的集合;p为该类特征向量的原型;h(x)表示对一样本x提取特征向量;为CNN模型的参数。
(2)对于查询集的任意一个样本x,仅使用其特征向量与每个原型之间的欧式距离进行预测,预测的函数记为θ(x,),具体公式如下:

(3)平均查询集所有样本的预测值与标签的交叉熵即为,其公式如下:

式中为交叉熵函数。
1.2.2&
、为图像分类的通常训练方法所用的损失函数,其公式如下:

式中f(x)表示模型对样本x进行预测的函数。
2 实验
为验证基于类间距优化的训练方法的有效性,本文在State Farm 数据集上构造了3 个不同大小的训练集来进行模型训练。3个训练集如表1所示,测试集与1.1节中所使用的保持一致。

表1 使用数据集情况
2.1 多种分心驾驶行为识别方法对比分析
本文定义图像分类的通常训练方法为式(8),其中训练集为={(,),(,),...,(x,y)};表示交叉熵;f(x)表示模型对样本x的预测值,表示模型的参数。

在上述3个训练集上进行3次对照试验,在每一次对照试验中分别使用4 种方法训练一个MoibleNetV2 模型,训练完毕后,测试模型在测试集上的准确率。4 种方法分别为:图像分类通常训练方法(记作baseline)、DACNN、HCF和基于类间距优化的训练方法。具体设置如下。
baseline:batch size=100,优化器Adam,epoch=40。前30 个epoch 设 置 学 习 率=3×10;后10 个epoch设置学习率=3×10,不使用数据增强。
DACNN:batch size=100,优化器Adam,epoch=40。前30 个epoch 设 置 学 习 率=3×10;后10 个epoch设置学习率=3×10,不使用数据增强。
HCF: 选 用 MobileNetV2、 ResNet50与Xception进行 模 型融 合,dropout rate=0.5,batch size=100,优化器Adam,epoch=40。前30 个epoch 设置学习率=3×10;后10个epoch设置学习率=3×10,不使用数据增强。
基于类间距优化的方法:支持集与查询集均为10-way,5-shot,优化器Adam,epoch=40。前30 个epoch设置学习率=3×10,=0.1;后10个epoch设置学习率=3×10,=10,不使用数据增强。
3次对照实验结果如表2所示。
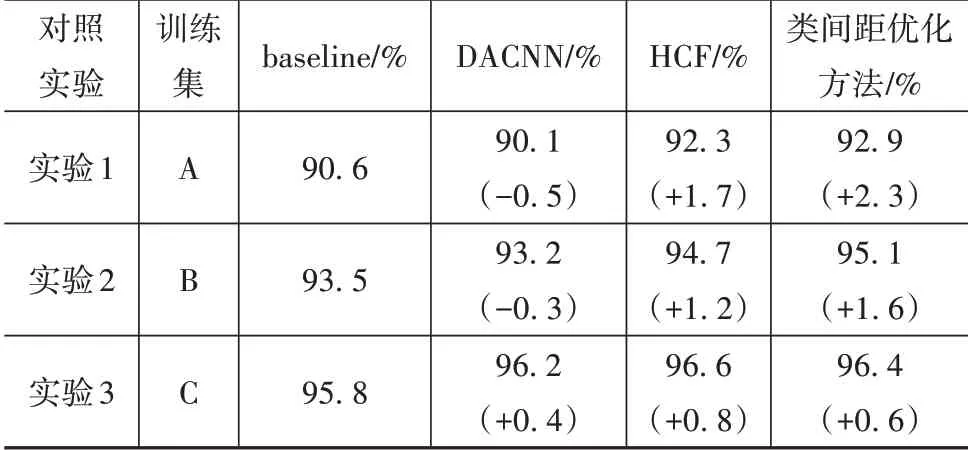
表2 3次对照实验结果
由表2 可知,在对照实验3 中,所有方法的准确率提升都不明显,这是因为测试集中有些驾驶员并未在训练集中出现,96%左右的准确率已经是模型的上限。
在任意一次对照实验中,本文中所提方法的准确率提升均超过了DACNN,且DACNN 添加的注意力模块会增加模型推理的计算开销,而本文所提方法在模型推理时不增加任何计算开销。在对照实验1 与对照实验2 中,DACNN 的表现甚至不如baseline,这可能是因为训练数据不够,导致其注意力过拟合所致。
在对照实验1与对照实验2中,本文所提方法的准确率提升也超过了HCF,虽然在对照实验3 中,HCF 的准确率提升略微超过了本文所提方法,但是HCF 是将3 个模型融合在一起,其模型推理的计算开销成倍增加,难以真正的部署。相比之下,本文所提方法在模型推理时不增加任何计算开销,具有更高的应用价值。
综上,本文所提方法在3 次对照实验中准确率均优于DACNN,与HCF相比,亦具有相当大的优势。
2.2 验证各类样本特征向量的类间距是否优化
本文将对照实验1 中使用图像分类通常训练方法和基于类间距优化的训练方法分别训练好的模型分别标记为模型X和模型Y(与1.1节一致),将对照实验2 中使用图像分类通常训练方法和基于类间距优化的训练方法分别训练好的模型分别标记为模型E和模型F。
使用模型X、模型Y、模型E、模型F 分别提取测试集所有样本的特征向量,使用PCA 将这些特征向量压缩至2 维,不同类的特征向量使用不同颜色区分,如图7所示。
观察图7 可知,图7(b)中每类特征向量之间的距离相较于图7(a)中要大了很多,图7(d)中每类特征向量之间的距离部分相较于图7(c)中要大了很多,这样在全连接层进行分类时,输入全连接层的每类特征向量的相似度变小,全连接层可更好地分类,模型的准确率也会更高。
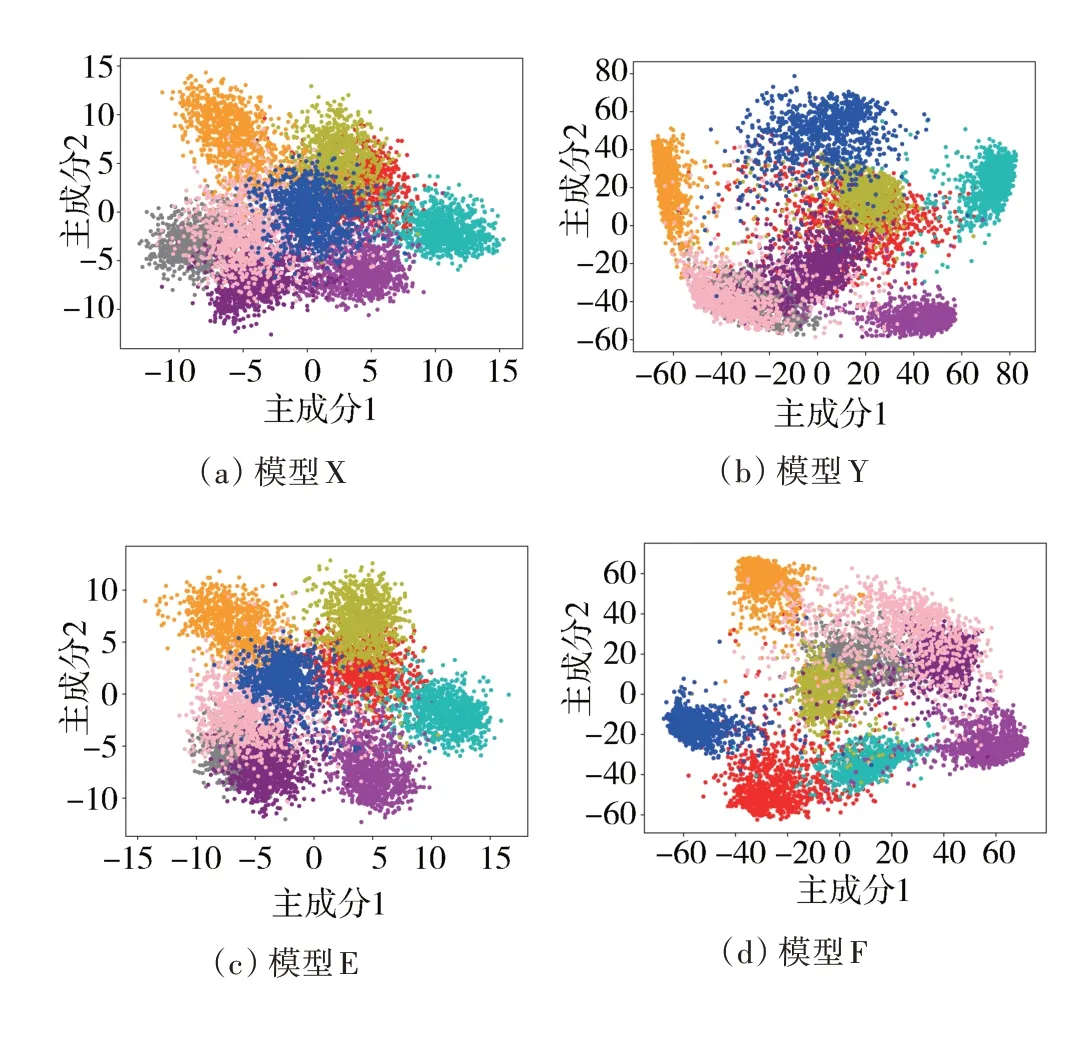
图7 模型所提取特征向量的PCA散点图
2.3 使用CAM图验证模型关注点是否正确
为了更好说明本文所提出的基于类间距优化的训练方法的有效性,将模型Y 与模型X 通过绘制一些样本(取模型X 错误分类但是模型Y 正确分类的样本)的热力图来进行对比,对比结果如图8(a)所示。
人类识别驾驶员是否正常驾驶主要关注图中驾驶员手臂是否伸直,驾驶员双手是否握住转向盘等信息,而模型X对于某些正常驾驶样本,其关注点在背部、头部,这显然是关注区域错误,相比之下模型Y就可以关注到同样的样本中正确的位置。
人类识别驾驶员是否在与副驾驶聊天主要关注驾驶员的头部朝向,而模型X 对于某些与副驾驶聊天的样本,其关注点在手部,这显然是因为模型没有学到头部的细微特征,从而无法区分正常驾驶和与副驾聊天这两类样本,相比之下模型Y 就可以关注到驾驶员的头部位置,这得益于基于类间距优化的训练方法在训练模型Y 时要求这两类样本特征向量之间保持一定距离。
模型E与模型F对一些样本的CAM图如图8(b)所示,不难发现模型F比模型E的关注点更加准确。

图8 模型对一些样本的CAM图
2.4 额外计算开销分析
2.4.1 训练时额外计算开销分析
本文所提方法与图像分类的通常方法相比需要额外计算,本文通过测试添加了后较未添加前模型一次反向传播所需时间的变化来定量评价本文所提方法的额外计算开销,测试结果如表3所示。

表3 反向传播时间对比
该测试在NVIDIA Tesla K8024GB RAM 显卡上进行。图像分类的通常方法设置batch size 为100,本文所提方法设置支持集10-way,5-shot,查询集50张样本,保持两种方法batch size一致。
由表3可知,添加了后,仅增加了7 ms的反向传播时间,不足原反向传播时间的1%,可见本文所提方法的额外计算开销很小。
2.4.2 推理时额外计算开销分析
在推理时,给定一张样本作为输入,模型会输出该样本的预测值与特征向量,仅取预测值即可(特征向量仅在训练时计算使用)。由于本文所提方法未在模型中添加任何模块,所以不增加任何额外计算开销。
3 结论
本文将分心驾驶行为识别转换为一个细粒度图像分类任务。图像分类通常训练方法所训练的模型,对于一些图像差异较小的类别无法实现高精度的分类,其原因是模型对这两类图像提取的特征向量之间的距离过小。为了解决上述问题,提高模型的分类准确率,本文中提出了基于类间距优化的训练方法。该方法通过增大模型从异类图像中提取特征向量之间的欧式距离,使得模型学到可以区分那些图像差异很小的类别的细微特征,进而提高模型对这些类别的分类准确率。但是该方法对训练集与测试集的同分布程度要求较高,若两者分布差异过大则无法取得好的效果,后期希望对模型进行一些改进。
