基于BERT与记忆网络的长文本方面级情感分析*
2022-02-28吴亚东褚琦凯付朝帅张贵宇
李 攀, 吴亚东, 褚琦凯, 付朝帅, 张贵宇
(1.四川轻化工大学 自动化与信息工程学院,四川 宜宾 644000;2.四川轻化工大学 计算机科学与工程学院,四川 宜宾 644000;3.四川轻化工大学 人工智能四川省重点实验室, 四川 宜宾 644000;4.四川省大数据可视分析工程技术实验室,四川 宜宾 644000)
0 引 言
方面级情感分析(aspect-based sentiment analysis,ABSA)区别与篇章级和句子级情感分析方法,目的是确定出语句中不同方面的情感极性,是一项细粒度情感分析方法[1]。例如:“这家店铺的地理位置很好,但是口味很差”。当方面词给定为“位置”时,句子对应的情感极性为积极,而当方面词给定为“口味”时,句子情感极性为消极。由于ABSA能实现多维度的情感挖掘,已被广泛地运用在产品推荐和产品质量反馈等方面。
方面级情感分析解决方法最开始是通过人工构建特征,结合机器学习或者浅层神经网络去做分类任务,这些方法不仅特征工程复杂,且需要大量的人工,缺乏泛化能力[2]。近年来,随着注意力机制的出现,ABSA方法大多开始结合单层或多层注意力机制来实现显示方面词与上下文的交互。在单层注意力方面,Ma D等人[3]提出了交互注意力网络(interactive attention networks,IAN)模型,以交互式注意力机制计算上下文与方面词的注意力得分。Wang Y等人[4]提出了基于注意力机制的长短时记忆网络(attention-based LSTM with aspect embedding long short term memory,ATAE-LSTM)模型,用LSTM对目标句和方面词进行合并编码,采用注意力机制来获取给定方面词的目标句特征向量表示。多层注意力与ABSA的结合,使得模型又提升了较高的性能。例如,Tang D等人[5]将记忆网络(memory network,MemNet)应用到ABSA任务中。其主要思想是采用具有外部记忆的注意力机制来捕捉每个与给定目标方面相关的上下文词。Huang B等人[6]将AOA(attention-over-attention)机制应用到ABSA任务中,从行和列分别计算句子级与文档级的注意力得分,增强了文本与方面词的信息交互。杜成玉等人[7]以螺旋交互注意力机制实现上下文与方面词交互,增强了目标句与方面词的语义表示。
随着BERT[8]的出现,大多数ABSA任务选择将其作为句子的编码模型,来获取比Word2vec[9],Glove[10]等浅层词嵌入更好的语义表达。在编码方式上,Sun C等人[11]将ABSA任务转化成句子对分类问题,采用构造辅助句子对的方式将上下文与方面词进行联合编码,以编码后的[CLS]向量作为情感分类特征。Gao Z等人[12]提出了TD-BERT(target dependent sentiment classification with BERT)模型,通过截取方面词的特征编码与[CLS]拼接后,作为最终的文本分类特征。Liu Y等人[13]构造了多[CLS]的Token嵌入,每一个[CLS]向量代表该短句的分类特征,在摘要抽取任务上取得较好的表现。
综上所述,大多数ABSA模型在处理长文本时,以上下文或方面词的平均向量或拼接后的首位[CLS]向量作为分类特征,都会造成信息损失。此外,在面对隐式方面词的场景,基于方面词嵌入与融合位置加权信息的方式便不再适用了。为此,本文研究了一种基于BERT表示的记忆网络(BERT-deep memory network,BDMN)模型。通过构造多[CLS]的Token嵌入方式来降低处理长文本时信息损失,同时采用结合注意力机制的记忆网络结构捕获句子的深层方面语义表示,以提升模型在含隐式方面词及长文本情形下的方面情感分析性能。
1 方面级情感分析模型

1.1 基于BERT的多[CLS]嵌入模型
受Liu Y等人[13]的启发,为了获取到多语句编码,将长句切割为多个短句的形式,分别使用[CLS]和[SEP]字符进行包裹,最后用同样的方式整合方面短语,并与全部编码后的短句进行拼接,便将一个长句编码成由多个句子组成的方式。模型整体结构如图1所示。

图1 基于BERT的多[CLS]结构模型
从图1可以看出,模型主要由输入层,Mark层,BERT以及情感分类层组成。对比于原始的BERT模型,模型在Input,Token,Segment三个嵌入的表示都不相同,只有位置编码与原BERT一致。为了区分不同的短句,本文沿用原BERT的Segment编码方式,将切割后的短句(包含[CLS]和[SEP])用0,1编码区分。针对每一个句子长度以及切割后的短句长度不一致,增加了Mark层输入,该层主要是记录句子中所有短句中的[CLS]与[SEP]字符位置,便于对每个短句中的特征向量进行抽取和屏蔽。
1.2 记忆网络层
基于上述BERT的输出结构上,本文设计了一种基于记忆网络的注意力机制结构,用以捕获目标句与方面词间的重要信息,结构如图2所示。

图2 基于BERT的记忆网络结构
为了得到句子的深层语义表示,本文采用了多个计算层(hops)进行记忆的叠加,每一个计算层都包含一个注意力机制[14]和线性层,整个计算流程如式(1)、式(2)所示
(1)
(2)
式(1)中,hg∈dBERT表示更新注意力记忆后的方面短语表示,g为当前计算层数,FC表示全连接层。式(2)中,colm为长度为m,值为1的列向量,⊗表示将平铺成与相同的维度。
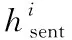
(3)
(4)

(5)
在第一个计算层(hop1)中,将方面短语的Acls作为输入,通过注意力机制选择记忆h中重要的部分,之后,将注意力层的输出和Acls的线性变换相加,作为下一层的输入。在经过多个计算层之后,得到了每个短句更新记忆后的情感特征向量,其更能表示句子中不同部分对特定方面的情感贡献。最后,将所有短句的情感特征向量ei堆叠在一起得到最终的文本情感表示E=[e1,e2,…,en]∈dn×dBERT。
1.3 分类层
由于训练样本中各类别数据存在不均衡的情况。为此,本文选用Focal Loss作为训练时的损失函数,其在多分类场景下的计算公式如式(6)~式(8)所示[15]
yt=SoftMax(E)
(6)
CE(yt)=ytruelog(yt)
(7)
(8)
式中αi用于调节多分类时各类别的权重占比,取值范围在[0,1]。γ为一个可调节的参数,用于降低简单样本的损失值,使得模型更关注于样本数量较少的类。在多分类场景下,αi的计算流程如下
(9)
(10)
式中ci为类别样本,ki为各个类别样本占比。
2 实验设计与结果分析
2.1 实验数据
本文采用AI Challenger 2018细粒度情感分析数据集进行训练测试。为与其他文献一致,选择了“位置”粗粒度下“交通是否便利”、“距离商圈远近”和“是否容易寻找”3个细粒度方面的数据。由于数据中的“未提及”类别样本数目过多,剔除了3个细粒度方面标签均为未提及的样本以及标点符号间文本过长无意义的样本。数据详情分布如表1所示。
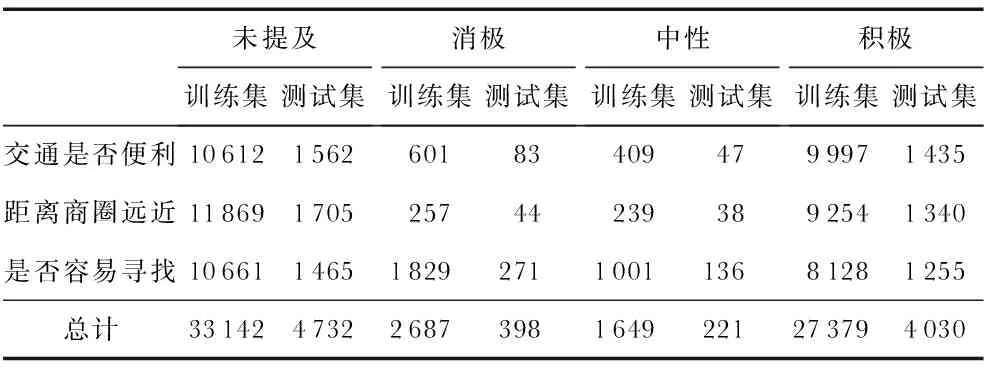
表1 数据集分布详细
2.2 参数设置及评价指标
本文所有模型均使用Tensorflow2.2框架搭建,4张内存为12G TITAN显卡共同训练。操作系统Window10,软件环境为Pycharm。
由于不同类别样本数目差异较大,无法用准确率来衡量模型的好坏,为此选用宏平均F1值(Macro_F1)作为评价指标[16]。模型参数设置如表2所示。

表2 参数设置
2.3 对比模型
所有的对比试验均采用BERT作为词向量模型,迁移至BERT下游,与BERT共同微调训练。由于本文针对的是隐式方面短语,若原文中使用了方面位置加权,则去除这一部分的特征向量。
BERT-Single[11]:BERT编码后的首位[CLS]向量作为情感分类特征。
AOA[6]:按行和列分别计算方面词与上下文的注意力得分,句子的方面短语表示作为情感特征向量进行分类。
IAN[3]:以方面短语的平均向量为方面词嵌入向量,交互计算上下文与方面短语的注意力得分。
MemNet[5]:方面短语的平均向量为方面词嵌入向量,以句子向量作为外部记忆,多次与方面词嵌入计算注意力得分。
ATAE[4]:方面短语的平均向量作为方面词嵌入向量,与BERT编码后的首位[CLS]向量计算注意力得分。
BERT-Pair[11]:首位[CLS]向量作为情感分类特征,直接输入SoftMax进行情感分类。
HAN[7]:方面短语的平均向量作为初始化方面嵌入向量,以螺旋迭代的方式计算上下文与方面词嵌入的注意力得分。
Multi:拼接所有短句的[CLS]向量作为情感分类特征。
2.4 实验结果分析
所有模型都经过4次实验后,取平均值。各个类别的F1值与宏平均F1如表3所示。
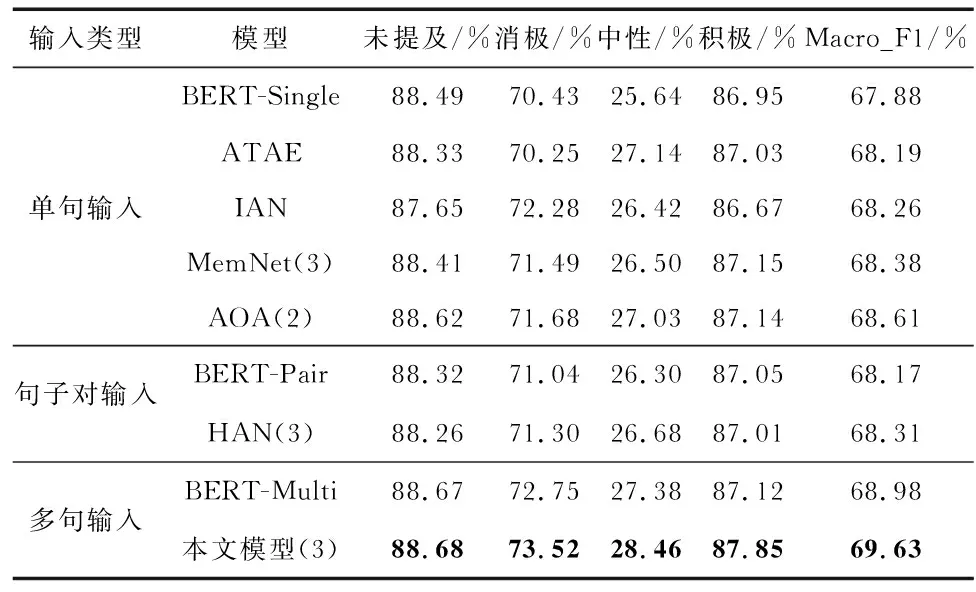
表3 各个类别F1与宏平均F1值对比(括号内为注意力层数)
以上所有基于BERT的下游模型中,本文方法效果最好,Macro_F1值达到了69.63 %。BERT-Single的Macro_F1最低,说明以句子的[CLS]向量作为情感特征不能很好地代表整个句子的语义信息。对比BERT-Single, BERT-Pair,BERT-Multi-3个模型,使用多[CLS]结构作为分类特征比使用单句高1.1 %,比句子对高0.81 %,说明多句输入更能完整保存句子的语义特征。此外,使用注意力机制的模型最少都比BERT-Single高0.31 %,说明注意力机制能有效地提升模型的性能。对比HAN,MemNet,IAN三者,前2者Macro_F1分别比IAN高0.05 %,0.12 %,说明使用多层注意力机制要比单层注意力机制模型效果要好,但不是注意力层数越多,模型性能越好。对比AOA与MemNet,AOA在使用了2层注意力的情况下反而比MemNet(3层)高0.23 %,表明使用字符级的注意力机制比以方面短语的平均向量为方面嵌入更能捕获方面短语的上下文表示信息。另外从整体来看,模型的F1值高低主要由句子是否有明显的情感特征字符决定。中性类的F1值为所有类别最低,主要是由于该类别的数据量较少,且无明显的情感字符,使得分类较为困难。同样数据量较少的消极类,由于存在较为明显的情感倾向字符使得分类性能远高于中性类。以多[CLS]结构为输入的BERT-Multi和本文模型在中性类的F1值都高于其它模型,进一步说明多[CLS]结构更能挖掘出句子的方面情感特征。本文模型与BERT-Multi相比,除未提及类基本持平外,其余的各个类别的F1值均高于Multi,其中消极类高0.77 %,中性类高1.08 %,积极类高0.73 %,这也表明基于记忆网络更新后的特征向量能更深一步地表示句子的方面情感特征。
3 分析与讨论
3.1 记忆网络层数对模型的影响
本文从模型的训练时长以及各类别的F1值2个方面进行对比,实验结果如表4所示。
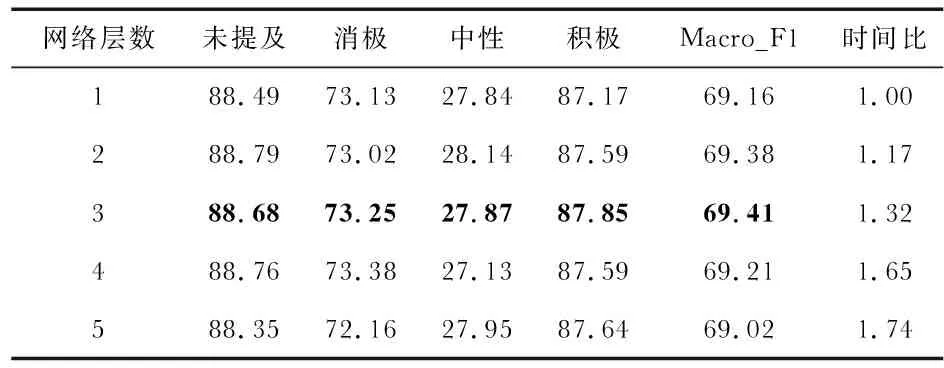
表4 不同注意力层数对本文模型的影响
表4为不同层数对应的类别F1,Macro_F1值以及训练时间比。其中时间比是以1个记忆网络层为基础,不同记忆层的运行时长是通过与单个记忆网络层的时间比值换算得出。分析发现,随着记忆网络层数的增加,模型的Macro_F1值并未一直上升,在层数为3时Macro_F1最高,表明模型已经学习到了足够的方面特征表示。当网络层数为4层时性能反而开始下降,当为5层时结果还低于单个计算层,同时模型的训练时长提高了1.74倍。由于层数2与层数3之间差别不大,为了更好地同其他多层注意力模型进行对比,本文采用的网络层数为3。
3.2 注意力可视化
将不同记忆层与方面计算的注意力权重进行了可视化,以颜色的深浅表示当前字符的方面注意力值,颜色越深,注意力值越大,结果如图3所示。

图3 记忆层注意力权重的可视化
图3中这句话在方面为“交通是否便利”的情感极性是积极的。在第一层注意力时模型已经将与方面相关的“交通”这一关键词进行了加强表示,但并未将表示积极情感的“便利”一词找出。在第二层注意力中,虽然“交通”与“便利”这2个相关词较其他词来说权重较大,但没有得到充分的强调,其周围词的权重也得到了增加,产生较多的噪声。在第三层注意力时,对“交通很便利”这个短句进行了加权,同时“是”一词的权重也得到了加强,并判断为积极。从整体来看,随着注意力层数的增加,与方面相关的关键词“交通”以及情感倾向词“便利”的权重越来越大,这表明本文的方法能够有效地找出句子中情感信息较大的词,从而得到更好的方面特征表示。
4 结 论
本文设计了BDMN模型来解决含隐式方面词与长文本场景下的方面情感分析任务。模型通过重新构造BERT的输入,以多短句输入的方式从BERT中获取上下文的初始化向量,并将其作为初始记忆与方面短语的[CLS]向量进行充分注意力交互,增强注意力记忆。设计了多组对比实验,结果表明:本文模型的性能在众多基于BERT的下游任务中获得了最好的效果,从而证明了模型能够有效降低在处理长文本时上下文与方面词交互的信息损失,提高分类性能。接下来将就如何有效筛选短句、挖掘出更好的句子向量以及提高注意力得分几个方面开展研究,以减少错误的加权信息,进一步提高模型的分类性能。
