分布式天牛群优化算法在分类中的应用
2022-02-28陈宏伟杨威威杨智慧
黄 嵩,陈宏伟,边 帆,杨威威,杨智慧
(湖北工业大学计算机学院,湖北 武汉 430068)
逻辑回归分类器作为一种文本情感分类器在自然语言处理中得到了广泛的应用,它的一些参数通常由人为经验设定,容易欠拟合,无法达到最佳分类效果。为了解决上述类似的问题,一些研究人员选择使用群智能算法来优化分类模型的超参数[1-3],使得优化后的模型在处理分类问题时性能有所提高。因此,通过优化模型的关键参数,可以进一步提高逻辑回归分类器模型在文本情感分类的准确率。本文提出了天牛群优化算法(BSO)来优化Logistic回归分类器模型的参数,该模型可以通过BSO算法自适应调整参数并获得最佳分类结果。BSO算法是2017年由Jiang[4]等提出的一种新的生物启发式智能算法Beetle Antennae Search Algorithm(BAS)演化而来。受粒子群算法(PSO)的启发,结合BAS和PSO算法的优点[5-7],将研究对象从天牛个体扩展到天牛群体,既保留了天牛个体的特征,又包含了群算法的优点,在一定程度上解决算法的单一性,提高算法的局部和全局寻优能力。
针对大规模计算中文本数据量大、时间复杂度高的问题, 本文提出一种基于Spark计算框架的分布式BSO算法。实验采用推特评论数据集,通过提出的算法模型对评论文本进行情感倾向分类。实验结果表明,分布式BSO算法在保证模型分类精度的基础上,能够更快、更有效地找到最优参数组合。
1 IM-BSO算法的原理与改进策略
1.1 学习因子与惯性权重的自适应调整策略
在一般情况下,BSO算法的学习因子与惯性权重被设置为常数,这样做无法使算法达到最优,且影响算法的效率。一些学者提出自适应的动态调整学习因子[8-9]与权重[10-11]的策略。本文采取如下策略:
(1)
(2)
其中C1和C2是学习因子,ω为惯性权重,Gbest为全局最优值,fitness为适应度值,t和T_max分别是当前迭代次数和最大迭代次数。
由式(2)知,天牛个体的适应度值比较小的时候,它的权重值就会比较大,因为当前天牛个体所在的位置比较差,需要加大搜索的步长,以便能搜索到更好的位置。而当天牛个体的适应度值比较大的时候,它的权重值就会比较小,因为当前天牛个体所在的位置已经很好了,只需缓慢地搜索到全局最优的位置,避免出现过拟合现象。
1.2 精英反向学习策略
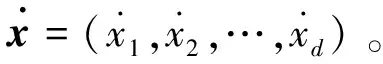
(3)
其中,xmin和xmax是天牛个体位置的取值区间的最小值和最大值。精英学习的具体步骤如:

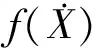
1.3 K均值聚类
K-means是机器学习中最常用的聚类方法,它的原理是求解数据点间的欧氏距离,然后根据距离的大小来划分类别,两个数据点的欧氏距离越近,相似度就越大,就会被划分到一类。
在本节中,K-means聚类的目标是把天牛群中n个天牛个体划分到k个聚类中,形成k个天牛子簇,子群中的每个天牛个体都具有相似的特性。在算法每次迭代后都会进行一次聚类操作,以便得到最好的聚类效果。
K-means算法的步骤如下所示:
Step1:选取初始化天牛群中K个天牛个体作为初始的聚类中心点(a1,a2,…,ak);
Step2:针对天牛群中每个天牛个体xi,计算天牛个体到k个聚类中心的距离,并将距离最小的天牛个体划分到其所对应的类中;
Step3:在每次迭代中,针对每个类别aj,根据公式(4)重新计算其聚类中心;
Step4:重复Step2和Step3这两个步骤,直到达到最大迭代次数。
(4)
式中,dis(xj,ak)表示天牛个体到聚类中心点的欧氏距离,其中j=(1,2,…,N),K=(1,2,…,K)。
经过K-means划分种群后,天牛群速度更新公式可以如下:
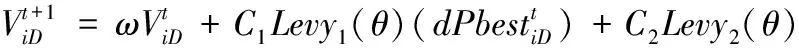
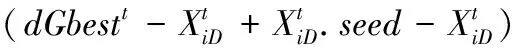
(5)
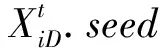
(6)
其中,dmax为干扰因子最大值,dmin为干扰因子最小值。
1.4 拓扑机制
有生物学家发现了欧椋鸟群的飞行机制中,个体之间存在拓扑相互作用,且与距离的大小无关[12]。这一机制同样也能运用到天牛群算法中,天牛群中每个簇可以看作是一个整体,每个簇间的个体的飞行方向和速度都与所属簇中的个体保持一致。Montes[13]等人在上述理论上,模拟出欧椋鸟群的拓扑机制并运用到粒子群算法中。本节将这一拓扑机制融入到天牛群算法中,融入拓扑机制的天牛群速度更新公式如下:
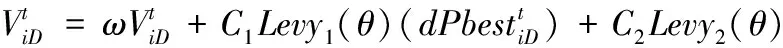
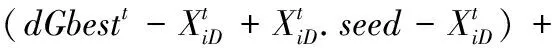

(7)
(8)
1.5 IM-BSO算法
假设在D维空间上有n个天牛,则模拟天牛群位置变化的公式如:
(9)
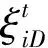
(10)
(11)
式中,d0为天牛左右两触角之间的距离。
2 DIBSO-LR分类模型
2.1 DIBSO算法原理
首先对 Spark 群集中的并行天牛群进行编码,设有n个天牛种群,最终会生成一个由k个分区组成的POPRDD,分别存储当前天牛群的位置(x)、速度(v)、天牛左右两触角的适应度值(fl、fr)和历史最佳位置(pbest)。图1是POP的编码结构。
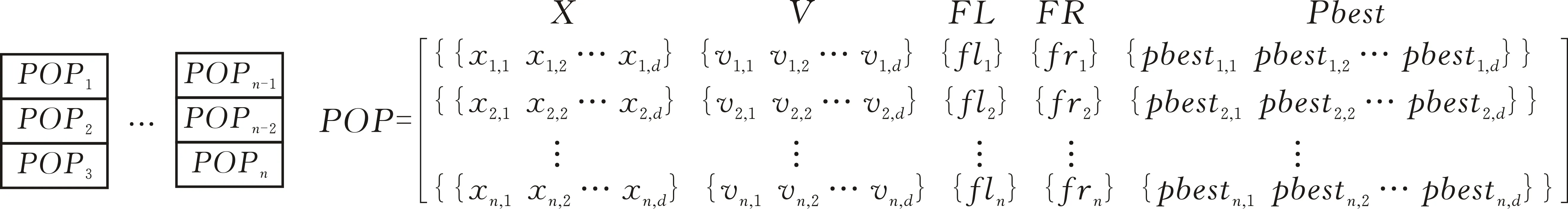
图 1 POP编码结构示意图
其中N=(1,2,…,n)表示天牛种群的个数,D=(1,2,…,d)表示天牛个体的维度。然后将POP转换为POPRDD,在后续算法迭代过程中,直接更新POPRDD中的子组信息即可。
分布式计算的过程主要分为两个部分,一部分是天牛群自身的计算,一部分是与数据结合计算天牛群的适应度值。当天牛群只做自身计算时,POPRDD只进行map操作,然后计算后的值覆盖POPRDD中所对应的值。当与数据结合来计算天牛群的适应度值时,首先取得天牛群的位置信息并广播,此时的天牛群位置信息为广播变量,进行分布式计算的数据是来自Hadoop中分布式文件系统HDFS中的数据,然后进行map操作得到每个分区的天牛群适应度值,最后进行reduce操作求得天牛群的适应度平均值。DIBSO算法的分布式过程与算法流程分别见图2和图3。
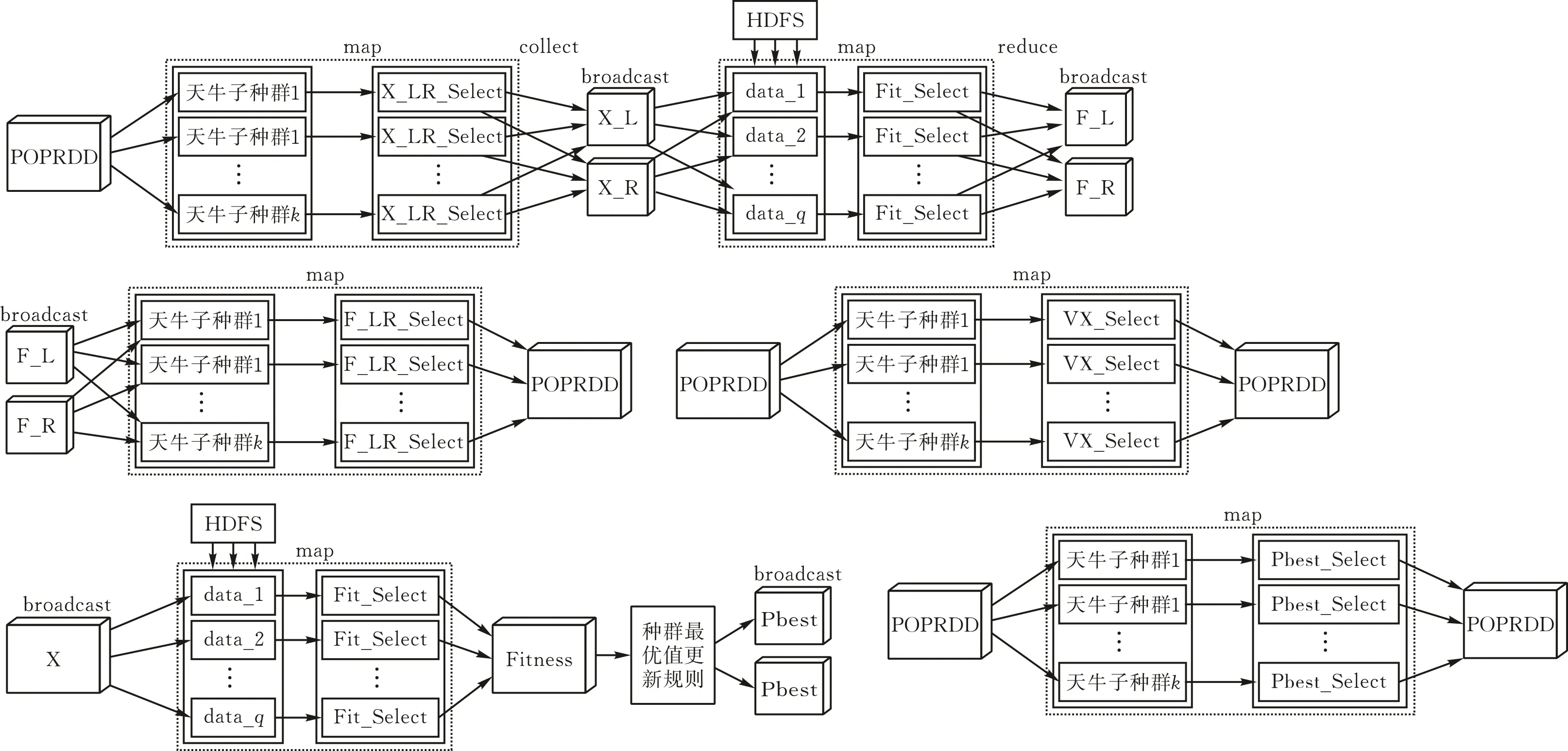
图 2 DIBSO算法分布式过程
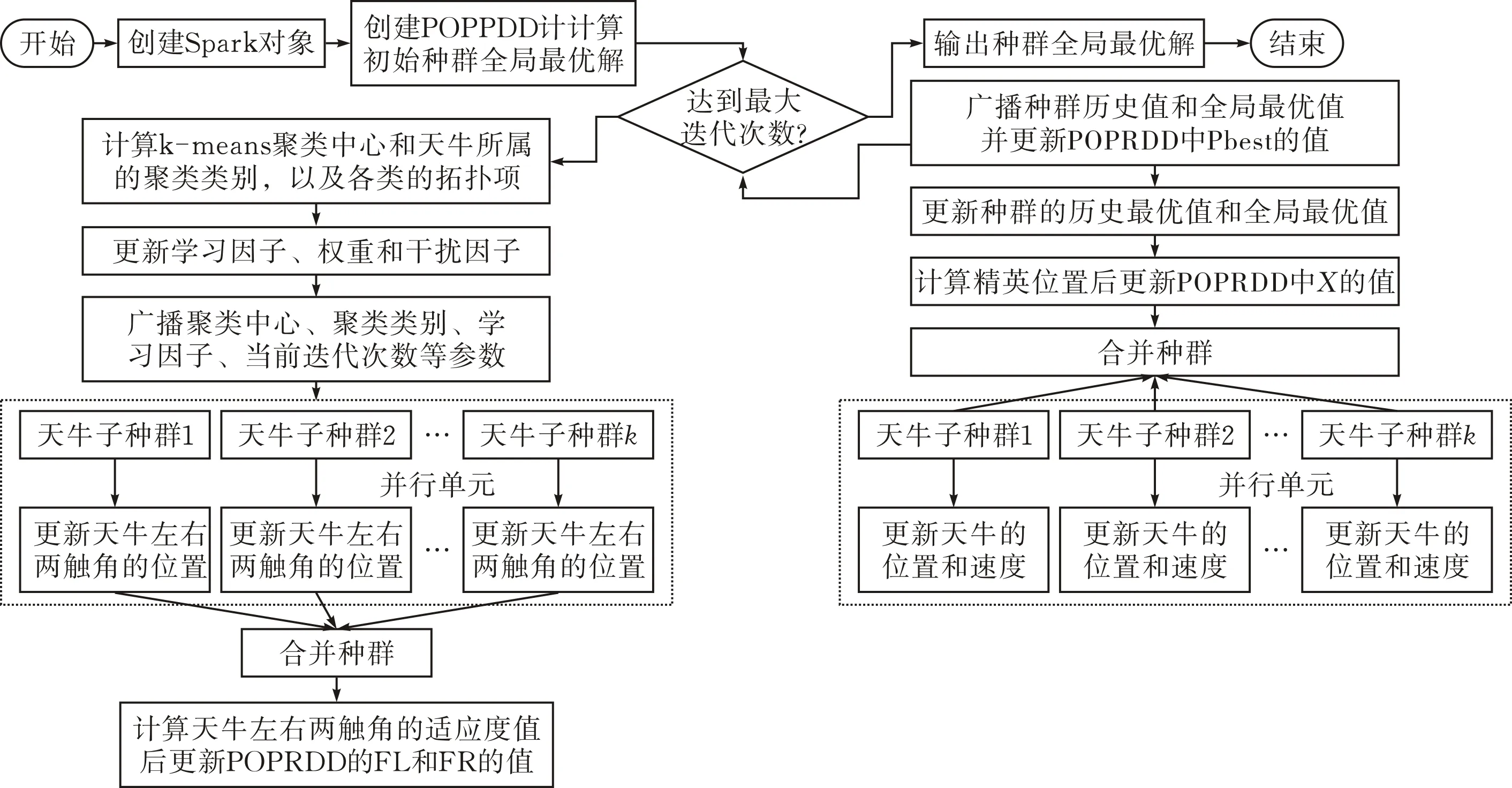
图 3 DIBSO算法流程图
2.2 基于DIBSO-LR的情感分类
本文采用DIBSO算法自适应控制逻辑回归的正则化系数,增强模型的自适应拟合能力。模型的分类准确率作为算法的评价指标。情感分类的框架图见图4。

图 4 情感分类框架图
3 实验与结果分析
在分布式实验中,推特数据集的数据大小分别为20 万、50 万和100 万。基于分布式改进BSO算法(DIBSO),在不同规模的数据集上独立运行10次,先计算不同数据集的分类精度,然后用1、2、3、4、5个计算节点计算,并比较它们的平均运行速度和加速比。加速比是反映分布式算法性能和优化效率的重要指标。通过比较不同数据集中算法的加速比,可以体现分布式算法的加速效果(图5、图6)。
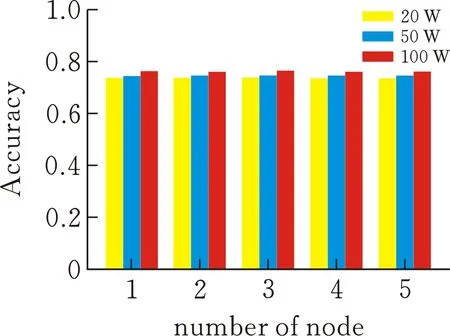
图 5 情感分类准确率
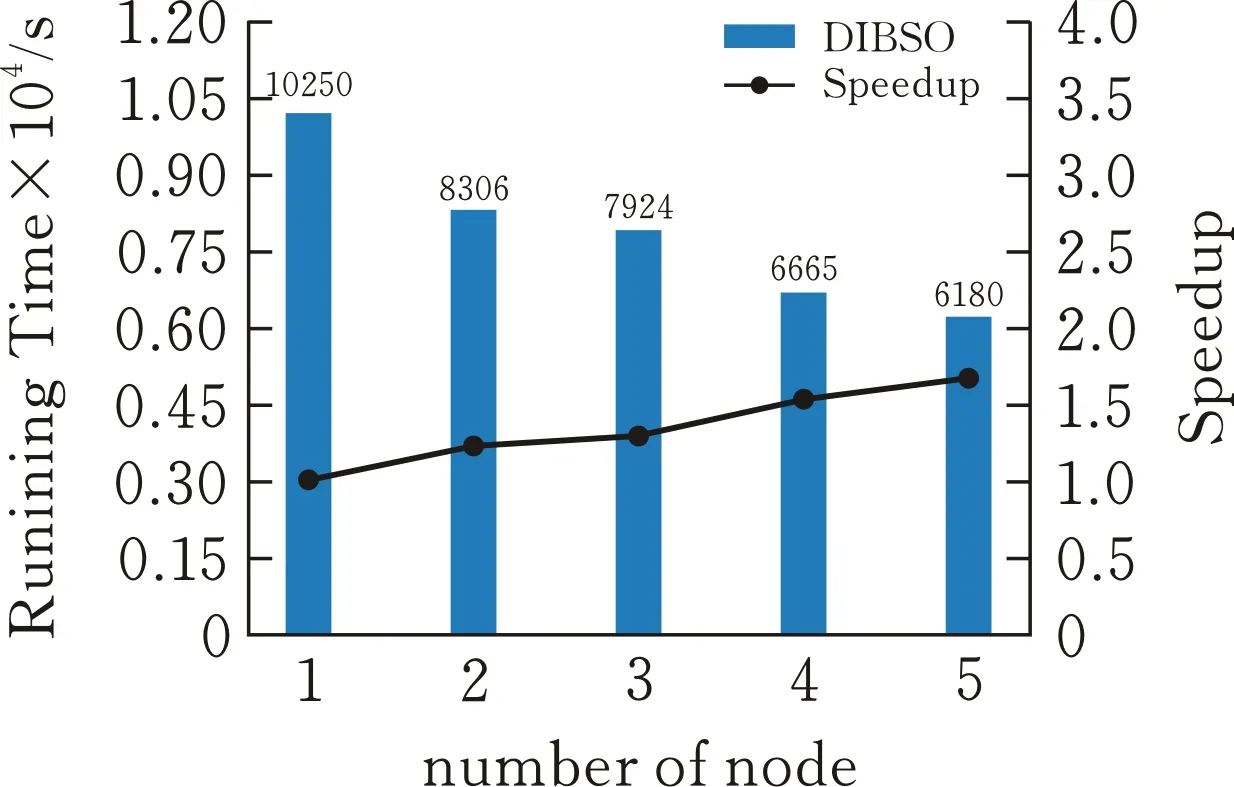
(a)20 万
由图6可看出,随着节点数的增加,由DIBSO-LR分类模型计算出的分类准确率基本保持不变,且计算时间逐渐减小。对于20 万样本,当节点数从1增加到2和3增加到4时,加速效果明显。对于50 万样本,当节点数从1增加到3时,加速效果显著。对于100 万样本,加速效果最为突出,节点数从1增加到5时,加速比接近线性增长。由此可以看出,随着节点数的增加,DIBSO-LR分类模型在确保分类准确率不发生重大变化的同时,加速了模型的计算速度,且随着数据量的增大,加速效果更明显。
4 结论
本文基于Hadoop和Spark,将大数据技术应用于情感分类,提出了DIBSO-LR分类模型,从实验结果来看,DIBSO-LR模型在情感分类问题上取得了不错的效果,尤其在计算效率方面,体现了大数据技术的高效。相信随着对相关领域进一步深入研究和大数据技术的不断发展,把大数据技术与智能算法相结合,在一定程度上,能够提高智能算法在优化问题上的计算效率。
