多尺度通道注意力机制的小样本图像分类算法
2022-02-28靳华中李文萱李晴晴
王 奇,靳华中,李文萱,李晴晴
(湖北工业大学计算机学院,湖北 武汉 430068)
随着大数据时代的到来,基于数据驱动的深度学习模型在图像分类任务中取得了巨大成功[1]。一般来说,深度学习的成功可归因于三个关键因素:充足的计算资源、复杂的神经网络和大规模数据集。然而,许多现实的应用场景中,例如在医学、军事和金融领域,由于涉及隐私安全问题和较高的人力成本等因素,无法得到足够多的训练样本。训练模型时没有足够多的有监督样本,容易产生过拟合现象,即模型在训练样本上表现良好,在测试集上的泛化效果不佳[2]。小样本学习[3]使用远小于深度学习所需要的数据样本量,达到接近甚至超越大数据深度学习的效果。为了让小样本学习进一步提高模型泛化性能,国内外学者对其进行大量的研究。阿里巴巴智能服务事业部团队[4]根据内部实现机制将小样本学习方法分为基于模型、基于度量和基于优化三类。李新叶等人[5]和赵凯琳等人[6]从跨任务学习知识的角度将基于元学习和基于迁移学习的方法也归为小样本学习。祝钧桃等人[7]根据小样本分类中所采用的技术将小样本学习的解决方案分为数据增强、度量学习、外部记忆、参数优化四个策略。由于真实世界中样本采集困难或成本昂贵,小样本学习已成为当前机器学习的研究热点。
从宏观角度来看,研究小样本学习的理论和实践意义主要来自三个方面[8]。1)小样本学习方法不依赖大规模的训练样本,从而避免了某些特定场景中数据准备的高昂成本;2)小样本学习可以缩小人工智能和人类智能之间的差距,是开发通用人工智能的必要研究;3)小样本学习可以为一个新出现的任务实现低成本和快速的模型部署,为新任务阐明早期的规律。
在图像分类中,依据不同的建模方式,小样本图像分类算法分为卷积神经网络模型和图神经网络模型两大类[9]。其中基于卷积神经网络模型的算法包括四种学习范式:迁移学习[10]、元学习[11]、对偶学习[12]和贝叶斯学习[13]。元学习包括基于度量的元学习[14]、基于模型的元学习、基于优化的元学习。基于度量的元学习方法依据不同的度量方式对成对的样本进行相似度度量,根据不同的度量方式,可被分为暹罗网络[15]、匹配网络[16]、原型网络[17]以及关系网络[18]。在基于度量的元学习方法中,暹罗网络、匹配网络和原型网络的分类器采用手动设计的方法,使用欧氏距离或者余弦距离,关系网络改进了距离的度量方式,使用神经网络作为分类器来学习特征之间度量方式。
基于度量的元学习首先专注学习一个可嵌入的模块,并预先定义固定的度量方式,在此基础上关系网络用来学习一个可转移的深度度量模块以提高图像的分类精度。2018年,sung等人[18]首次提出关系网络。从深度学习出发,关系网络延续基于度量的元学习的基本原理,通过设计模型学习“如何度量”样本间的距离。相比于固定距离的度量方式,关系网络通过学习一种非线性的度量方式取得了更好的分类效果。但是关系网络中的特征提取模块忽略了很多重要的样本信息,对样本的关键信息提取不充分,导致仍然存在识别准确率低的问题。通过将图像裁剪与关系网络相结合,庞振全等人[19]构造的网络取得了较好的图像分类精度,但裁剪操作会造成样本有效信息的损失。金璐等人[20]在关系网络中引入inception模块,融合多尺度特征后对红外空中目标分类取得了良好效果。王年等人[21]通过引入自注意力机制与感受野模块提升了网络的特征表达能力和度量能力。
注意力机制[22]能够使网络模型更加关注重要信息而减少与目标任务无关的信息。2018年,胡杰等人提出SE-Net[23],将它引入CNN中取得良好的图像分类效果。此后,研究者提出ECA-Net[24]、SK-Net[25]、ResNeSt[26]、CBAM[27]等注意力机制,分别从通道域与空间域两个方面增强了注意力机制的性能。注意力机制大幅度提升模型训练的速度与任务效果,同时其即插即用的特性极大方便了模型的设计。小样本学习的训练样本较少,能提取到的信息相对有限,而使用注意力机制可以在有限的训练样本下提取到更多的有效信息。
基于上述分析,在关系网络的基础中本文引入多尺度空间与通道的注意力机制,使关系网络的嵌入模块能够学习更丰富的多尺度特征,同时自适应地对多维度的通道注意力权重进行特征重标定,提升了模型对小样本的分类能力。在MiniImageNet[15]与Omniglot[28]数据集上进行实验,实验表明本文方法的分类精度比原方法明显提高。
1 相关技术原理
1.1 小样本问题描述
受人类智能的启发,研究小样本学习的目的是希望模型(算法)能够像人脑一样,在学习大量的基类后,仅需要少量样本就能快速得到新类,获取新的知识,做到举一反三。
小样本图像分类流程(图1)包括数据集处理,特征提取网络和分类器三个部分。

图 1 小样本图像分类流程
小样本学习的基本模型定义为r=g(f(x|θ)|ω),它由特征提取网络f(·|θ)和分类器g(·|ω)组成,θ和ω分别表示f和g的参数,x表示待识别的图像,f(x|θ)表示对图像x提取的特征,r表示对图像x识别的结果。
为了提取图像的有效特征,分类时需要建立特征提取模型。对于模型,提取的图像特征应该尽可能有效地描述图像,使分类器能够更好地利用它们。可见,提高图像特征描述和提取能力,将能够获得更好的分类结果。注意力机制、记忆力机制等是常见的图像特征有效提取的技术手段。
分类器通过对特征进行相似度度量,来获取对象的不同类别。小样本图像分类中所使用的分类器大多数是在卷积神经网络的最后一层构建带有Softmax的全连接层,或者对提取的图像特征应用K近邻算法等。本文分类器采用的是前者。
1.2 关系网络
关系网络是一个灵活、通用、端到端的小样本学习框架,通过计算支持集和查询集样本图像的关系得分,对新类别的样本图像进行分类。关系网络结构见图2,它主要由嵌入模块fφ和关系模块gφ组成。

图 2 关系网络结构
嵌入模块用于提取图像样本的抽象特征,生成支持集和查询集图像的特征表示,如图3中fφ所示,由4个卷积块和2个最大池化层组成,每个卷积块包含一个卷积核大小为3×3,通道数为64的卷积层,一个BatchNorm层,一个ReLU层。嵌入模块能提取出样本的抽象特征,为模型提供可以用于对比的特征信息。支持集与查询集图片分别输入嵌入模块,首先提取图像特征,接着将特征图级联后送入关系模块。

图 3 嵌入模块与关系模块
如图3中gφ所示,关系模块由2个卷积块,2个最大池化层,2个全连接层组成。该模块最终产生0-1范围内的标量,该标量表示支持集样本和测试集样本之间的相似性,为关系得分。计算该得分的公式如下:
ri,j=gφ(C(fφ(xi),fφ(xj))),i=1,2,…,S
(1)
其中,ri,j为相似度得分即关系得分,C(·)为特征级联。
训练中的损失函数使用均方误差MSE,如:
(2)
2 基于多尺度通道注意力机制的小样本图像分类模型
2.1 金字塔切分注意力模块
金字塔切分注意力模块(PSA)是一种多尺度空间与通道注意力机制[29]。金字塔切分注意力机制框架的结构见图4。
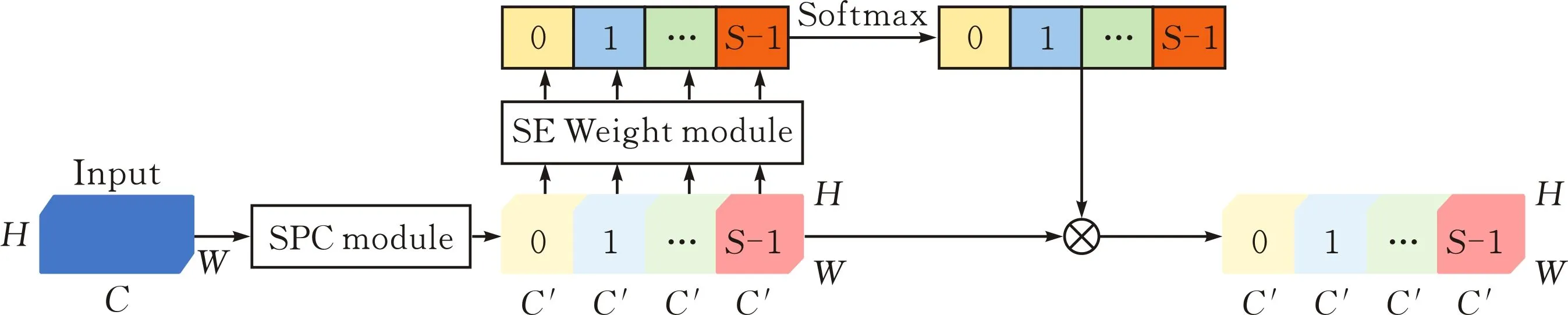
图 4 金字塔切分注意力机制框架
PSA模块包括以下四个部分:
1)使用分割和连接模块(SPC module)将输入转换为通道方向上的多尺度特征图。其中,分割和连接模块的实现步骤如下,将输入的特征图X分割成S个部分,每个部分用[X0,X1,…,XS-1]和通道维度C′表示,C′=C/S。引入群卷积的方法对这些部分分别用多尺度并行处理。
SPC设计了新的准则来处理多尺度内核与组大小的关系:
(3)
其中,G是组大小,K是内核大小。此外,当内核大小K=3时,G=1。经过SPC模块的多尺度特征图的生成函数如下:
Fi=conv(ki×ki,Gi)(Xi),i=1,2,…,S-1
(4)
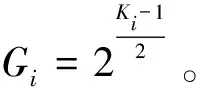
F=cat([F0,F1,…,FS-1])
(5)
2)使用SE权重模块提取不同比例的特征图的注意力权重,获得通道方向的注意力向量。
Zi=SEWeight(Fi),i=1,2,…,S-1
(6)
Z=Z0⊕Z1⊕…⊕ZS-1
(7)
其中,⊕是级联运算符,Zi是Fi的注意力权重,Z是多尺度注意力权重向量。
SE模块是通道注意力机制中的经典模型,包括Squeeze操作与Excitation操作。SE模块结构见图5。
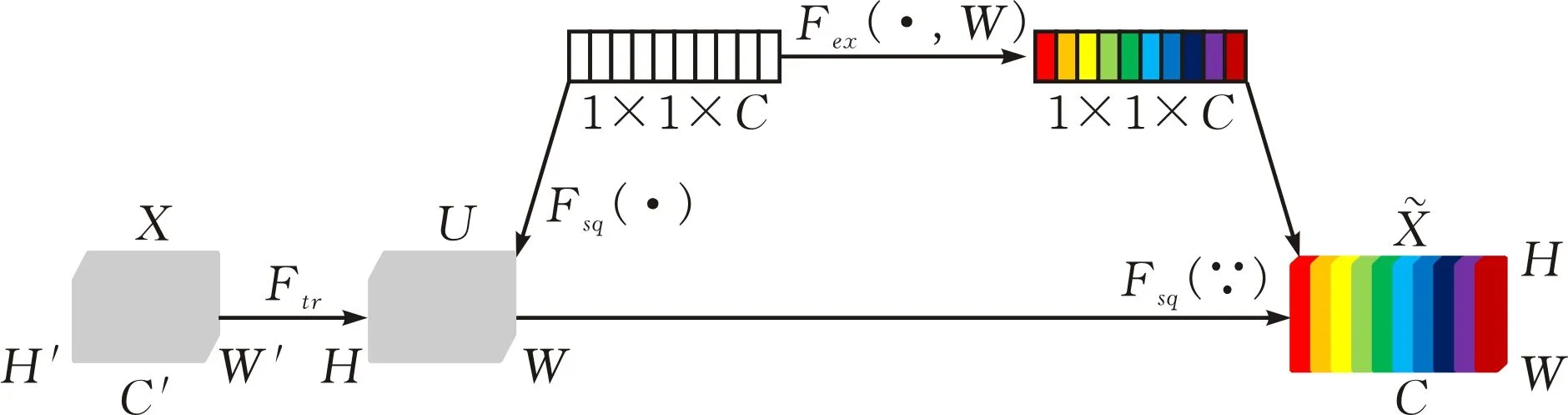
图 5 SE模块结构
对于任何给定的变换,将输入X映射到特征映射U,其中U∈RH×W×C。特征U首先通过Squeeze操作在空间维度上被压缩为1×1×C向量,即全局平均池化。Squeeze操作的公式如下:
(8)
Squeeze操作之后是Excitation操作,该操作通过两个全连接层组成一个Bottleneck结构去建模通道间的相关性,为每个通道生成一个权重值,得到各个通道权重的集合。Excitation操作的公式如下:
s=Fex(z,W)=σ(g(z,W))=σ(W2δ(W1z))
(9)
式中,δ为ReLU激活函数,W1、W2分别为两个全连接层的参数。
最后通过Scale操作将得到的归一化权重加权到每个通道的特征上,以生成SE模块的输出。Scale操作的公式如下:
(10)
3)使用Softmax重新校准通道方向的注意力向量,得到多尺度通道重新校准的注意力权重。
(11)
其中,Softmax用于获得多尺度通道的重新校准的权重,其包含空间上的所有位置信息和通道中的注意力权重。
att=att0⊕att1⊕…⊕attS-1
(12)
其中,att表示注意力级联后的多尺度通道权重。
4)将得到的多尺度通道的权重加权到对应的特征图Fi中:
Yi=Fi⊙atti,i=1,2,…,S-1
(13)
其中,⊙表示通道乘法。
最后得到一个多尺度特征信息更丰富的细化特征图作为输出。
out=cat([Y0,Y1,…,Ys-1])
(14)
2.2 基于多尺度通道注意力机制的小样本图像分类算法
本文提出的基于多尺度通道注意力机制的小样本图像分类网络模型见图6。
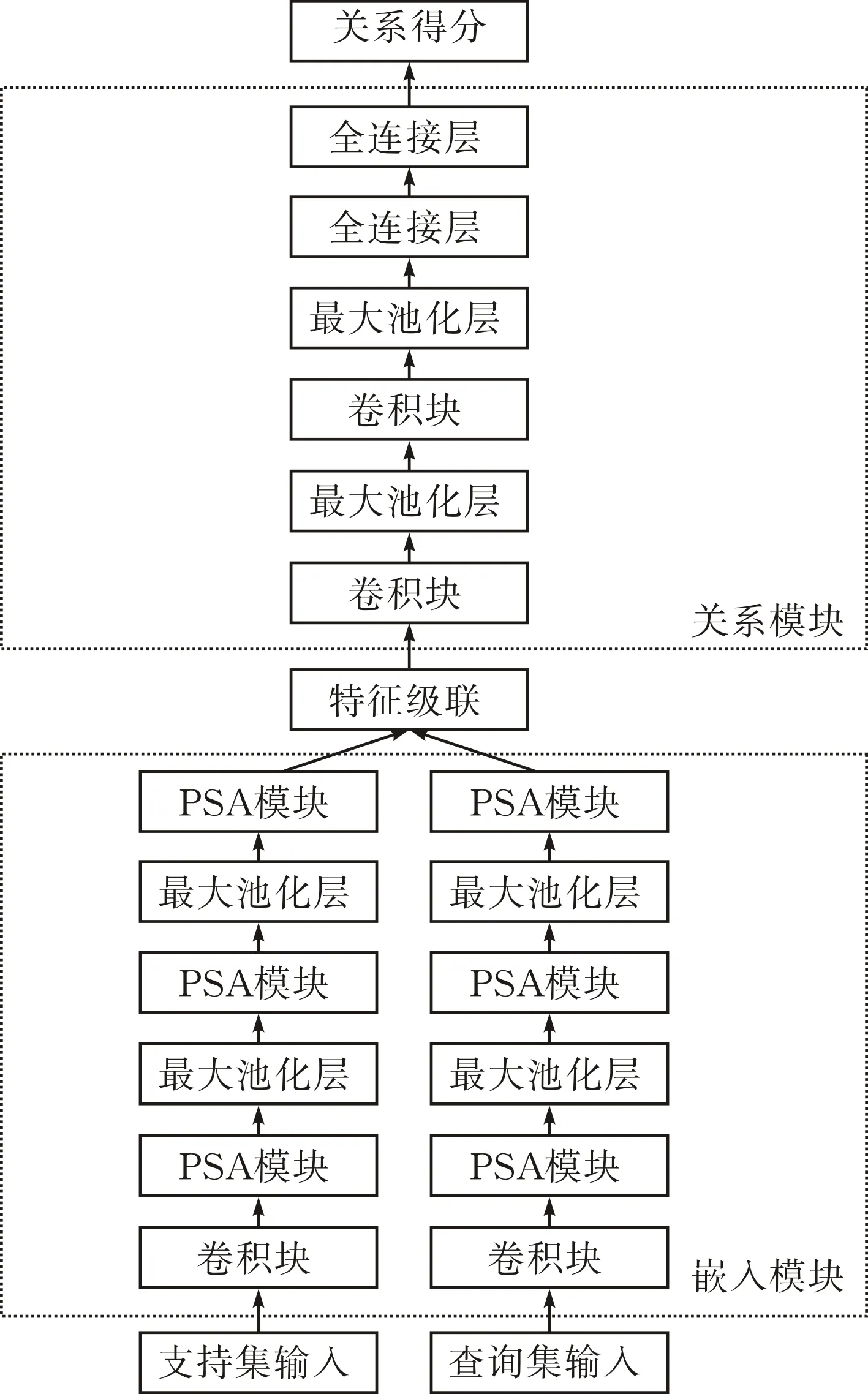
图 6 小样本图像分类网络模型
嵌入模块由一层卷积块、三层PSA模块以及两层最大池化层组成;关系模块由两层卷积块、两层最大池化层,两层全连接层组成。将得到的支持集图像特征与查询集图像特征级联并输入关系模型。
PSA模块网络结构是一个金字塔切分注意力模块[29],其网络结构如图7所示。它将输入的特征图分为四个尺度,用大小不同的卷积核并行处理,其中,K0=3,K1=5,K2=7,K3=9。图中,SE权重模块得到通道注意力先计算不同通道特征图的权重,再通过Softmax层对权重校准,最后得到通道权值不同的特征图。
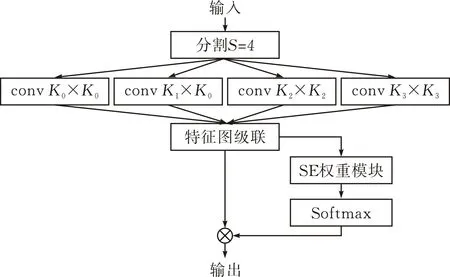
图 7 PSA模块网络结构
本文使用PSA模块替换嵌入模块中后三层卷积块,从而得到改进后的嵌入模块(图7)。
3 实验
3.1 数据集
MiniImageNet数据集是元学习和小样本领域的基准数据集,由google DeepMind团队Oriol Vinyals等人在ImageNet的基础上提取并提出,数据集复杂,包含100类共60 000张彩色图片,其中每类有600个样本,每张图片的规格为84×84,适合进行原型设计和实验研究(图8)。

图 8 MiniImageNet数据集图像示例
Omniglot数据集包含来自50个不同字母的1623个不同手写字符。每个字符由20个不同的人通过亚马逊的Mechanical Turk在线绘制的。对现有数据旋转90°,180°和270°来扩充数据集,1200个原始类加上来进行训练,剩余的423个类来进行测试。输入图像都调整到28×28(图9)。

图 9 Omniglot数据集图像示例
3.2 实验设置
遵循大多数现有的小样本学习工作采用的标准设置,对于MiniImagenet数据集,使用5-way 1-shot和5-way 5-shot两种模式进行训练,在训练阶段随机采样并构建500 000个episode,在每个训练的episode中,5-way 1-shot每类包含15个查询图像,5-way 5-shot每类包含10个查询图像。即,在一个episode中5-way 1-shot有15×5+1×5=80个图像,5-way 5-shot有10×5+5×5=75个图像,实验设置见表1。对于Omniglot数据集,20-way 1-shot和20-way 5-shot两种模式进行训练,在训练阶段随机采样并构建1 000 000个episode,在每个训练的episode中,20-way 1-shot每类包含10个查询图像,20-way 5-shot每类包含5个查询图像。即,在一个episode中20-way 1-shot有10×20+1×20=220个图像,20-way 5-shot有5×20+5×20=200个图像,实验设置见表2。
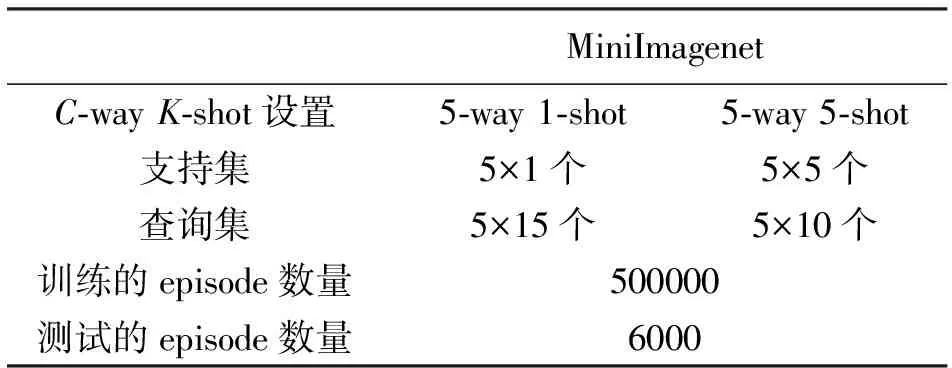
表1 MiniImagenet实验设置

表2 Omniglot实验设置
3.3 实验结果
在MiniImagenet和Omniglot数据集上的实验结果见表3和表4。
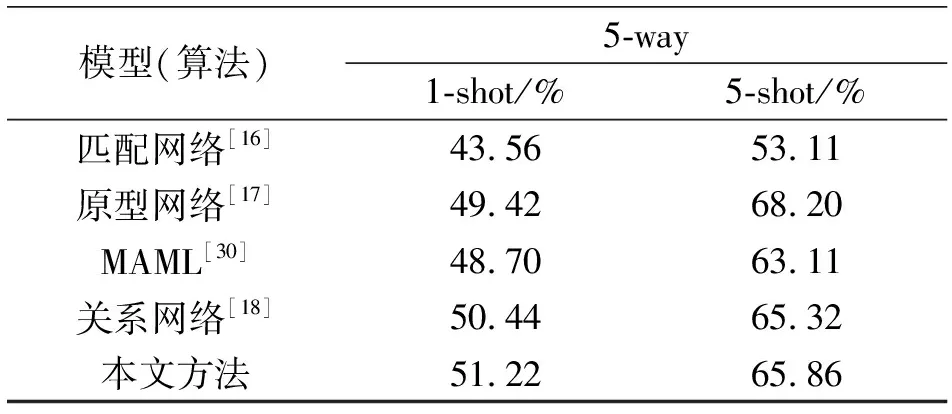
表3 MiniImagenet数据集上识别率
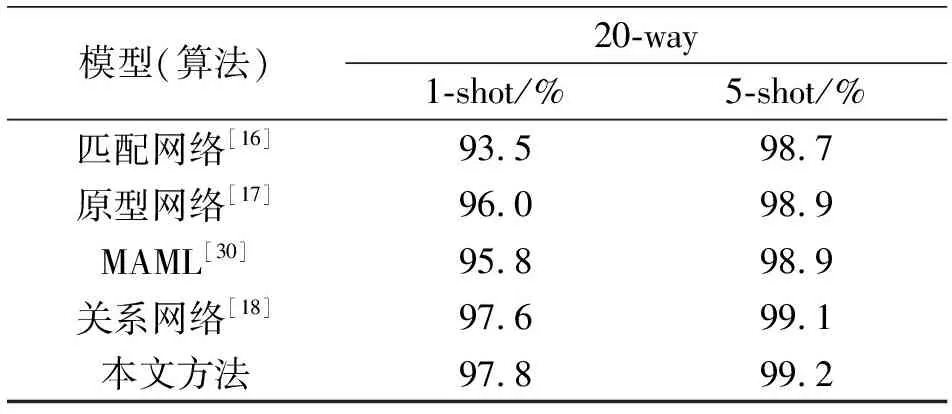
表4 Omniglot数据集上识别率
从实验数据可以看出,本文改进后的网络在MiniImageNet数据集上5-way 1-shot与5-way 5-shot的分类精度分别提升到了51.22%与65.86%,比原网络分别提高了0.78%和0.54%;在Omniglot数据集上20-way 1-shot与20-way 5-shot的分类精度,比原网络提高了0.2%和0.1%。
4 结论
本文在关系网络的嵌入模块中引入多尺度空间与通道注意力机制PSA模块,提出了一种基于多尺度通道注意力机制的小样本图像分类方法,用不同尺度的卷积核对图像进行特征提取,丰富了特征空间。实验表明,在标准的MiniImageNet与Omniglot数据集中,本文提出的方法提升了关系网络中嵌入模块的特征提取效率,提高了小样本图像的分类精度。
