基于深度学习的稀疏矩阵向量乘运算性能预测模型
2022-02-24曹中潇冯仰德闵维潇姚铁锤王丽华高付海
曹中潇,冯仰德,王 珏,闵维潇,姚铁锤,高 岳,王丽华,高付海
(1.中国科学院计算机网络信息中心,北京 100190;2.中国科学院大学,北京 100049;3.北京航空航天大学 软件学院,北京 100191;4.中国原子能科学研究院,北京 102413)
0 概述
在科学计算和工程应用领域中,很多实际问题的求解通常可以转换为求解线性代数方程组Ax=b,而大部分实际问题中遇到的矩阵A往往是稀疏的,因此稀疏矩阵向量乘(Sparse Matrix Vector Multiplication,SpMV)是数值计算的主要组成部分,也是计算耗时最多的部分。在使用迭代法求解大规模稀疏线性方程组时,SpMV 被重复调用,SpMV 计算效率直接影响了整体求解效率[1]。由于存储访问不规则等特性,SpMV 运行效率一般低于单个处理器浮点性能峰值的10%[2],在实际应用中往往成为性能瓶颈。文献[3-4]介绍了BCSR和BELLPACK 存储格式的变体。文献[5]提出一种新型存储格式CSX,该格式利用矩阵中的子结构来压缩元数据。文献[6]提出一种CSR5格式,该格式能在CPU、GPU、Xeon Phi等平台上提供高吞吐量SpMV。文献[7]提出一种在向量多处理机上实现稀疏矩阵乘法的算法SEGMV。文献[8]提出一种新型存储格式Cocktail 并基于该格式开发clSpMV 框架,clSpMV 框架能够在运行时分析各种稀疏矩阵,在给定目标平台上为其推荐最优存储格式。文献[9]提出一种新型存储格式CVR,该格式同时处理输入矩阵中的多个行以提高缓存效率,并将它们分成多个SIMD 通道,以便利用现代处理器中的向量处理单元。文献[10]提出一种基于COO 格式的BCCOO 格式。文献[11-13]利用自动调优技术来提高SpMV 性能以及跨平台的可移植性。传统自动调优方法主要关注在硬件上的参数搜索空间中进行搜索,搜索空间大,且对每一次搜索的参数设置都要执行SpMV运算,导致自动调优的耗时大幅增加。因此,研究SpMV的性能模型对提高自动调优性能具有重要意义。
一些学者基于机器学习方法构建SpMV 算法生成库。李佳佳等[14]提出一个SMAT 自动调优器,对于一个给定的稀疏矩阵,SMAT 结合矩阵特征选择并从DIA、ELL、CSR、COO 等4 种格式中返回最优的存储格式。SEDAGHATI 等[15]构建一个决策模型,实现对给定目标平台上的稀疏矩阵自动选择最优存储格式。BENATIA 等[16]采用SVM 方法来解决存储格式选择问题。NISA 等[17]结合决策树和SVM 两种方法,实现一个存储格式预测模型。ZHAO 等[18-19]考虑运行时预测开销以及格式转换开销的影响,设计回归模型以及基于神经网络的时间序列预测模型,有效捕获了开销以及格式预测和转换对整体程序性能的影响。ZHAO 等[20]将深度学习方法引入SpMV的最优稀疏矩阵存储格式选择中,提出Late-merging卷积神经网络(Convolutional Neural Network,CNN)结构,有效地将深度学习方法应用于高性能计算问题,但该模型缺乏对体系结构参数的考虑。上述方法主要用于稀疏矩阵存储格式选择,并不适用于SpMV 性能预测。对于SpMV,由于输入的特征数据来源于稀疏矩阵和体系结构参数,数据含义以及表示形式与图像处理网络中的输入数据不同,因此图像处理领域中的CNN 网络结构不再适用,需要设计新的CNN 网络来满足SpMV 运算时间预测的需求。
本文构建一个SpMV 性能预测模型,将稀疏矩阵的特征以及硬件平台的特征作为输入、SpMV 运算时间作为输出。设计CNN 网络结构,对各部分特征输入分别独立进行特征处理。引入特征融合模块,将特征融合延迟到CNN 网络后期,使CNN 网络更好地适应SpMV 的输入表示形式,并使用稀疏矩阵集合进行实验验证。
1 基于CNN 的SpMV 运算时间预测模型
1.1 模型构建
SpMV 运算时间预测模型为三通道独立CNN 模型,网络添加了特征融合模块,如图1 所示。该模型主要由双通道稀疏矩阵特征融合以及稀疏矩阵特征与体系结构特征融合两部分组成,每个部分的作用如下:
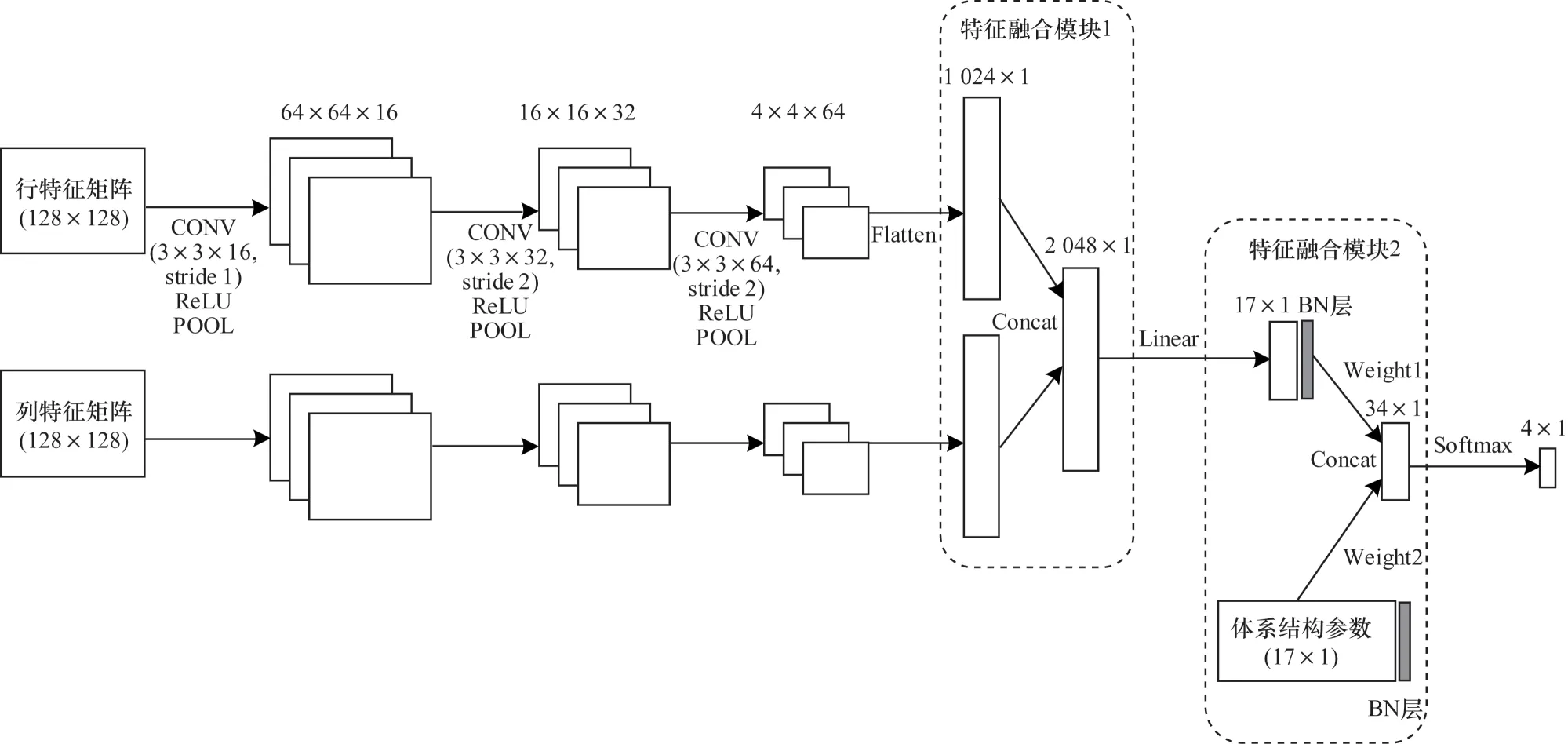
图1 特征融合CNN 模型结构Fig.1 Structure of feature fusion CNN model
1)双通道稀疏矩阵特征融合。考虑到稀疏矩阵的表示以及CNN 具备提取矩阵特征的能力,本文设计双通道稀疏矩阵特征融合模块,获取稀疏矩阵的特征。通过直方采样算法从稀疏矩阵中提取出行特征矩阵以及列特征矩阵,采用特征后融合的方法,将它们分别输入各自的卷积神经网络中,在后期进行线性拼接融合,并输入至全连接层,进而得到稀疏矩阵的融合特征。
2)稀疏矩阵特征与体系结构特征融合。同样采用特征后融合的方法,首先将融合后的稀疏矩阵特征与体系结构参数特征分别使用BN(Batch Normalization)层[21]规范化后进行特征融合,得到稀疏矩阵与体系结构参数的融合特征,然后经过Softmax 函数,最后输出四分类的预测值。
在图像处理领域,对一幅给定RGB 图像,每个通道中的第i个元素都对应原始图像的第i个像素。在本文所研究的问题中,由于稀疏矩阵采用直方采样算法提取特征,行特征矩阵和列特征矩阵在数值上具有不同的统计意义,即一个是对行的直方统计,另一个是对列的直方统计,因此并没有图像处理中点对点的对应关系[20]。基于上述考虑,特征融合模块将对来自稀疏矩阵的特征矩阵以及来自运行平台的体系结构参数特征分别进行处理,在网络后期将两者特征融合,避免了多类别特征过早融合导致特征提取时造成的相互干扰,同时降低了算法复杂度。
1.2 特征数据的选取和构建
SpMV 实际运行的时间与多种因素有关,例如矩阵的规模大小、矩阵的非零元素个数、运行平台的体系结构参数等。在构建模型时,单一特征通常只侧重于某一方面,为了提高模型的可靠性和准确性,采取特征融合的方法来兼顾多种特征的信息。为此,本文选取并构建SpMV 运算时间预测的多类别输入特征,将SpMV 数据特征分为两类,即稀疏矩阵特征和硬件平台特征,如表1 所示。

表1 输入特征信息Table 1 Input feature information
稀疏矩阵特征包括行特征矩阵、列特征矩阵,以及稀疏矩阵的行数、列数、非零元素的个数。其中,对于稀疏矩阵,采用直方采样算法对原稀疏矩阵分别进行行直方采样以及列直方采样,从而得到行特征矩阵以及列特征矩阵。稀疏矩阵的行数和列数表征了稀疏矩阵的规模大小,对于规模很小的稀疏矩阵,执行SpMV 自动调优的耗时较短,对其进行时间预测的意义较小。因此,本文实验剔除了规模较小的矩阵,即行数或列数小于100 的矩阵。
在选定模型的输入特征后,需要进行数据采集以及数据预处理,构建完整的特征数据集。适当的数据预处理能够提高整个预测模型的准确性,图2给出了数据预处理的过程,其中,实线表示数据预处理的流程,虚线表示模型的特征数据和标注数据。由于CNN 网络需要大量数据作为训练样本,进而获得样本间的知识,因此应用数据增强技术来获取足量数据。首先,对原始稀疏矩阵进行转置,对现有的数据进行扩充产生更多训练数据,以便模型学习到更多矩阵特征。其次,对扩充后的数据进行筛选和过滤,包括处理无效数据、过滤不符合要求的数据等。最后,采用直方采样算法提取稀疏矩阵的行特征以及列特征,并借助yaSpMV[10]工具获取体系结构参数以及SpMV 运算时间。
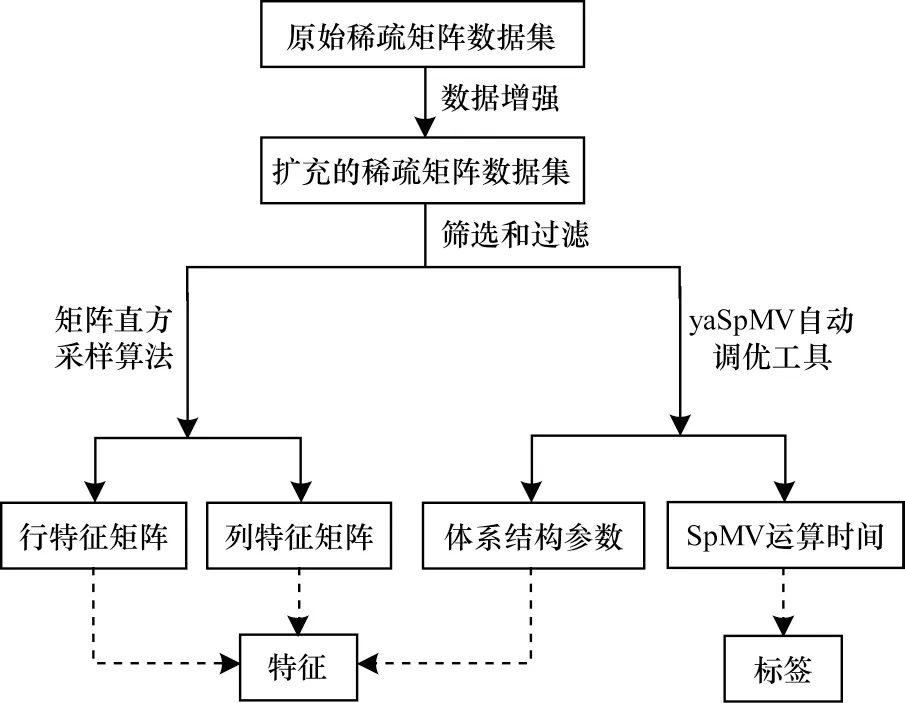
图2 数据预处理过程Fig.2 Process of data preprocessing
1.3 基于箱图的时间标签分类
基于深度学习的模型训练需要海量的标注数据。本文使用箱形图[22]统计时间信息,箱形图能够显示出一组数据的最大值、最小值、中位数以及上下四分位数,可以用来反映数据分布的中心位置和散布范围,并且可以直观地识别批量数据中的异常值。在箱形图中,异常值被定义为小于Q1-1.5IIQR或大于Q3+1.5IIQR的值,其中,Q1为第1 个四分位数,Q3为第3 个四分位数,IIQR为Q3与Q1的差距,即IIQR=Q3-Q1。基于箱形图的时间信息统计结果如表2 所示。
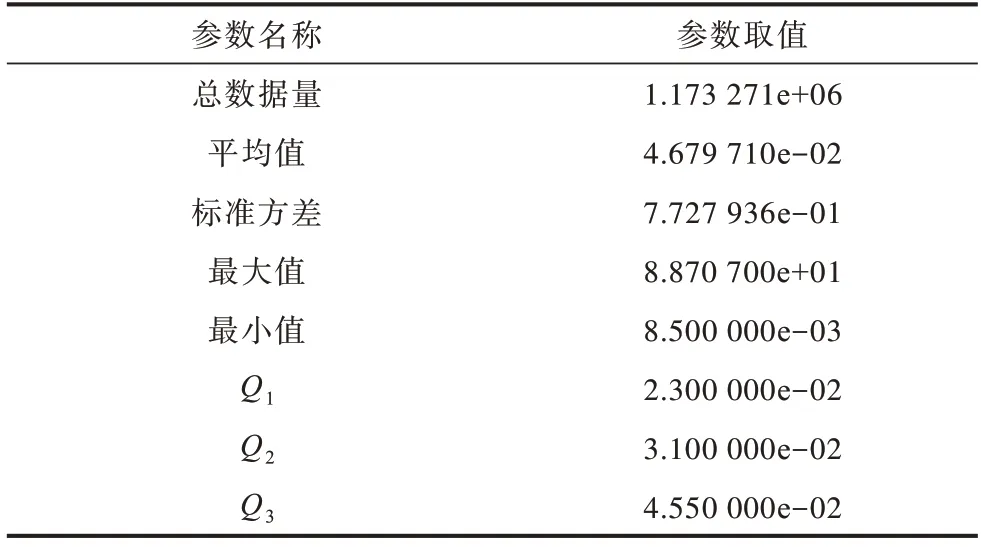
表2 基于箱形图的时间统计信息Table 2 Time statistics based on box plot
为使数据类别划分尽可能均匀,实验采用Q1、Q2、Q3这3 个四分位点作为分界点,将摒弃异常值之后的数据划分为4 个部分,分别对应0、1、2、3 等4 个类别(Class)。不同类别对应的时间(t)情况如式(1)所示:
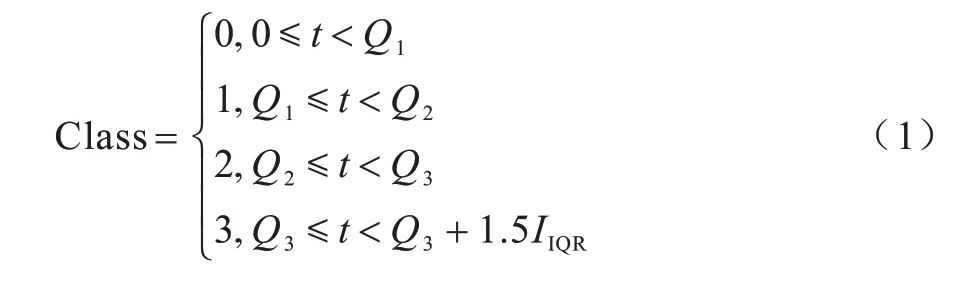
其中:SpMV 运算时间在[0,Q1)、[Q1,Q2)、[Q2,Q3)、[Q3,Q3+1.5IIQR)区间范围内的分类标签分别为0、1、2、3。SpMV 运算时间预测模型的训练和推理过程如下:
1)对原始稀疏矩阵数据进行预处理,提取稀疏矩阵的特征,得到特征矩阵,包括行特征矩阵和列特征矩阵。
2)获取硬件平台的体系结构参数组合,构建多类别特征数据集,同时对每一组参数设置执行SpMV 运算,得到对应的SpMV 运算时间,作为训练标签。
3)设计基于卷积神经网络的模型结构,利用步骤1、步骤2 中得到的特征数据和标签组成数据集,输入模型中进行训练,不断进行参数优化调整,直至得到训练好的模型。
4)使用新的稀疏矩阵,经过数据预处理得到特征数据,输入训练好的模型中得到预测结果。
2 实验与结果分析
为验证本文特征融合CNN 模型的准确性和有效性,实验选择佛罗里达稀疏矩阵数据集[23]进行验证,选用格式为MM 格式[24],获取并扩充得到稀疏矩阵文件1 538 个。实验平台相关信息如表3 所示。

表3 实验平台相关信息Table 3 Experimental platform related informations
本文特征融合CNN 模型采取将稀疏矩阵特征与体系结构参数特征先分别卷积池化再进行融合的模型进行处理,旨在消除输入特征之间的相互干扰。为验证该模型的有效性,建立一个对比模型,记为非特征融合CNN 模型。在该模型中,稀疏矩阵特征与体系结构参数特征在网络后期直接融合,这与图1所展现的特征先消融再融合的结构有着本质区别。
对于两个模型,将预处理得到的数据按10∶1 的比例分为训练集和验证集,数据量信息如表4 所示。模型均在相同的训练集以及验证集上进行实验。由于数据量较大,如果直接将训练数据输入预测模型进行训练,每轮迭代时间较长,参数更新缓慢,因此采用梯度下降法中的mini-batch 训练方法进行小批量训练,结合反向传播算法优化参数,降低内存负载,提高训练速度。模型训练参数设置如下:损失函数为CrossEntropyLoss,优化器为optim.Adam,学习率为1e-2,共训练50 批次,每批次数据量为1 024。

表4 数据集划分Table 4 Dataset division
选取以下评价指标对特征融合CNN 三通道独立CNN 模型进行预测性能分析:
1)Loss 值。使用平均绝对误差(Mean Absolute Error,MAE)值表示Loss 值,MAE 计算公式如下:

其中:n表示数据数目;yi和′ 分别表示 第i条SpMV执行时间的真实值和预测值。
2)ACC 值。使用ACC 值作为准确率的值,ACC计算公式如下:

其中:Ctrue和Call分别表示预测结果正确的数目以及全部预测结果的数目。
图3给出了未添加特征融合模块的非特征融合CNN模型以及添加了特征融合模块的三通道独立CNN 模型的Loss 值随迭代轮次的变化趋势图。从图3 中可以看出,特征融合CNN 模型比非特征融合CNN 模型的收敛速度更快,收敛效果更好。图4 给出了两个模型的ACC 值随迭代轮次的变化趋势图,两个模型在训练集以及验证集上的平均准确率如表5 所示。可见,特征融合CNN 模型在收敛过程中的预测准确率更高,表现出更好的泛化能力,说明本文对不同特征之间关联性的考虑及处理使得特征提取更加全面多样且层次性更强,从而进一步提升了预测准确率。
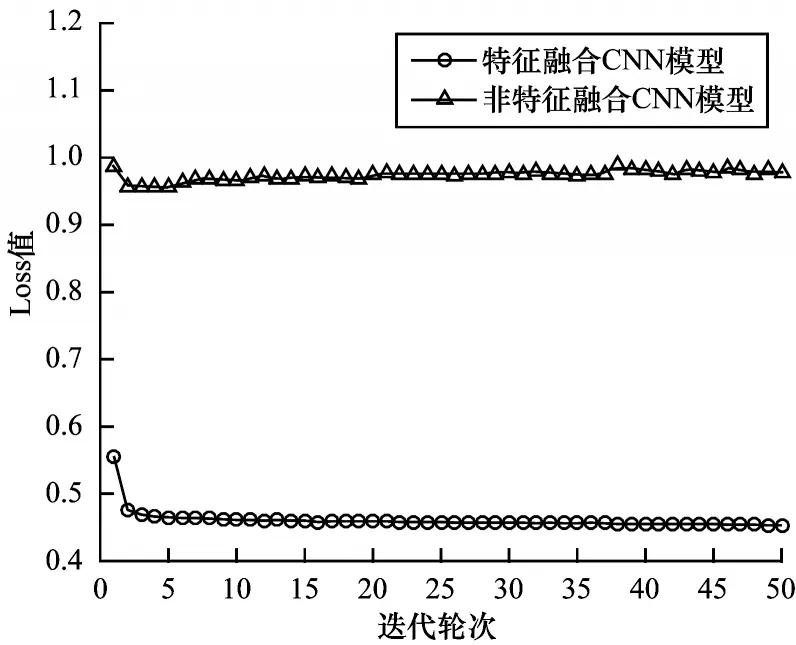
图3 特征融合CNN模型与非特征融合CNN模型的Loss值对比Fig.3 Comparison of Loss values between feature fusion CNN model and non-feature fusion CNN model

图4 特征融合CNN模型与非特征融合CNN模型的ACC值对比Fig.4 Comparison of ACC values between feature fusion CNN model and non-feature fusion CNN model

表5 模型平均预测准确率对比Table 5 Comparison of average prediction accuracy between models %
3 结束语
预测SpMV 的运算时间有利于加快SpMV 自动调优速度。本文建立基于深度学习的SpMV 运算时间预测模型,结合稀疏矩阵的行特征、列特征以及运行平台的体系结构参数等因素,分类别对SpMV 的运算时间进行预测。实验结果表明,基于特征融合CNN 的SpMV 运算时间预测模型的预测准确率较高,运行速度较快,适合处理不同特点的稀疏矩阵。后续将对SpMV 自动调优过程中的每组调优参数均进行运算时间预测,从而寻得耗时最短的调优参数组合,以达到快速自动调优的目的。
