Underwater Target Detection Based on Reinforcement Learning and Ant Colony Optimization
2022-02-24WANGXinhuaZHUYungangLIDayuandZHANGGuang
WANG Xinhua, ZHU Yungang, LI Dayu, and ZHANG Guang
Underwater Target Detection Based on Reinforcement Learning and Ant Colony Optimization
WANG Xinhua1), *, ZHU Yungang2), LI Dayu3), and ZHANG Guang3)
1),,132012,2),,,130012,3),,,,130033,
Underwater optical imaging produces images with high resolution and abundant information and hence has outstanding advantages in short-distance underwater target detection. However, low-light and high-noise scenarios pose great challenges in underwater image and video analyses. To improve the accuracy and anti-noise performance of underwater target image edge detection, an underwater target edge detection method based on ant colony optimization and reinforcement learning is proposed in this paper. First, the reinforcement learning concept is integrated into artificial ants’ movements, and a variable radius sensing strategy is proposed to calculate the transition probability of each pixel. These methods aim to avoid undetection and misdetection of some pixels in image edges. Second, a double-population ant colony strategy is proposed, where the search process takes into account global search and local search abilities. Experimental results show that the algorithm can effectively extract the contour information of underwater targets and keep the image texture well and also has ideal anti-interference performance.
ant colony optimization; reinforcement learning; underwater target; edge detection
1 Introduction
In recent years, underwater optical imaging equipment has rapidly developed, and underwater target detection technology has also been widely used (Lin., 2019). Such technology involves the laying of submarine optical cables (Fatan., 2016), the establishment and maintenance of underwater oil platforms (Bonin-Font., 2015), the salvage of submarine sinking ships (Liu., 2019), and the research of marine ecosystems (Li., 2020). Underwater optical imaging produces images with high re-solution and abundant information and hence has outstanding advantages in the short-distance underwater target detection task. However, due to the influence of water light absorption and scattering, images captured by the underwater optical imaging system often encounter many problems, such as increased noise interference, blurred tex- ture features, low contrast, and color distortion (Wang.,2019). Therefore, the underwater target detection task faces many challenges. How to detect the underwater target accurately, quickly, and stably in a complex underwater scene with poor image visibility has become an urgent problem that needs to be solved. In recent years, domestic and foreign research institutions and scholars have conducted considerable research on the underwater target de- tection method, which can be divided into underwater target detection based on traditional features and underwater target detection based on deep learning networks. The traditional underwater target detection method based on feature descriptors describes underwater targets. The commonly used underwater image features include color, shape, and texture features, which is a simple method and has good real-time performance (Chuang., 2016). How- ever, they are also affected by changes in the target size, rotation, occlusion, shooting angle, and species category. With the development of the graphics processing unit (GPU) and other hardware systems, target detection technology based on deep learning has rapidly developed. In the computer vision task, a deep learning network extracts information layer by layer from pixel-level raw data to abstract semantic concepts, which makes it have outstanding advantages in extracting global features and context information of images. Even in the case of occlusions or small object size, it can perform successful detection (Sun., 2018). However, due to the complex structure of deep neural networks, they need to adjust several parameters when applied to a specific environment, resulting in a decline in the algorithm efficiency.
In the fields of ecological monitoring of the marine biological population, the edge contour of a target image is an important appearance feature used to distinguish marine biology. By detecting the edge of a target image, not only the feature information of the target can be effectivelyextracted, but also the computational complexity and amount of data processing can be greatly reduced. As a metaheuristic algorithm, the ant colony optimization (ACO) algorithm is insensitive to noise. Accordingly, this study attempts to apply the ACO algorithm to underwater target image edge detection to improve the image edge detection accuracy and anti-noise ability. Our contributions are as follows:
1) The reinforcement learning idea is integrated into the artificial ant movement, and a variable sensing radius strategy is proposed to calculate the transition probability of each pixel to avoid undetection or misdetection of some pixels in an image edge that cannot be detected or even mistakenly detected.
2) The double-population strategy is proposed to controlthe movement direction of ants, the first population focuseson the global search, and the second population focuses on the local search. Thus, the search process takes into account global search and local search abilities.
3) The proposed method can achieve high accuracy in practical datasets in the real world.
2 Principle of the Algorithm
2.1 ACO
The ACO algorithm is a heuristic search algorithm that simulates ant foraging. As a probabilistic group intelligent search technology, ACO has been widely used in manyfields, such as data mining (Gao., 2013), cluster ana- lysis (Deng., 2019), and image processing (Tian.,2008). The application of the ACO algorithm in imageedge detection was first proposed by Nezamabadi-pour(2006). The flow of the image edge detection algorithm based on ACO is shown in Fig.1.
In Fig.1, the basic principle of the ACO algorithm is that ants will deposit pheromones along the path they travel during foraging, and other ants can detect pheromones to guide their movement (Luand Chen, 2008). During the initialization of the ACO algorithm, a predetermined number of artificial ants are placed in the search space. The movement of each ant is based on the transition probability, which indicates the probability of the ant moving from one unit to another in the search space. The value of the transition probability depends on the pheromone and heuristic information of the unit. After the ants move, the pheromone is up-dated. When the predefined number of iterations is reached, the search is terminated. Then, most ant travel routes that contain more pheromones are selected as the best solution.
2.2 Reinforcement Learning
The basic idea of reinforcement learning is, if a certain action of the system can bring positive returns, then the future trend of the action will be stronger; otherwise, the trend of the action will be weakened (Montague, 1999). Based on the reinforcement learning model, a reinforcement learning system includes not only the agent andenvironment but also the four basic elements, namely, stra- tegy, value function, return function, and environment mo- del. Because the state transition probability function and reward function in the environmental model are unknown, the agent can only choose a strategy based on the rewards obtained from each trial. Therefore, a function for stra- tegy selection needs to be constructed between the stra- tegy and instantaneous reward (Mnih., 2015).

Fig.1 Flow of the image edge detection algorithm based on ACO.
Reinforcement learning is a heuristic learning strategy based on machine learning theory. The problem to be solved is how to choose the action that can achieve the optimal goal through learning (Silver., 2018). First, you need to build an agent that can sense the surrounding environment and complete the mapping from environment to action. Reinforcement learning regards learning as a process of continuous exploration. The standard reinforcement learn- ing model is shown in Fig.2.
In Fig.2, the agent accepts the input stateof the environment and outputs the corresponding actionthrough the internal learning inference mechanism. Under action, the environment becomes a new State. At the same time, an enhanced signalfor a reward or punishment is gene- rated and fed back to the agent. The agent selects the next operation based on the feedback information and the current state of the environment (Vinyals., 2019).
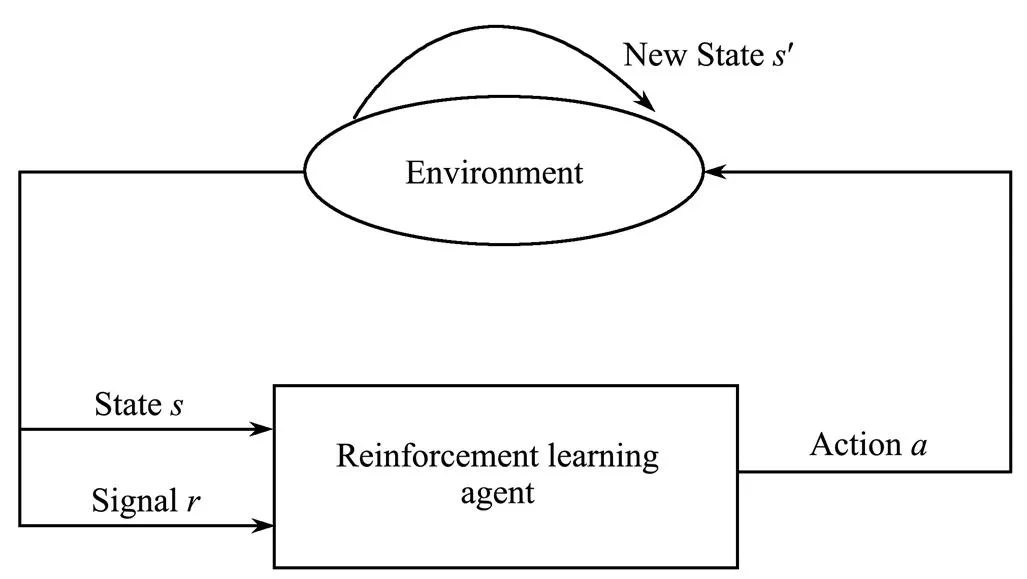
Fig.2 Reinforcement learning model.
3 Related Work
In recent years, many scholars have studied the application of the ACO algorithm in image edge detection. Most of these methods improve the algorithm from two aspects: the improvement based on the algorithm itself and the fu- sion with other algorithms. Singh. (2019) proposed an ACO method based on bioinspired technology to identify the edges of ships in the ocean. To reduce the time comple- xity, a triangular fuzzy membership function is used. The results of the proposed work confirm the clear edges of small and partial objects. Kheirinejad. (2018) applied the max-min ACO method to detect image edges. Moreover, a new heuristic information function (HIF) is proposed, namely, group-based HIF, to determine nodes that ants visit around their place. The proposed HIF exploits the difference between the intensity of two groups of nodes instead of two single ones. The simulation result sections show that the robustness of the proposed edge detection algorithm is more than that of the previous algorithms. Nasution. (2017) proposed improvements to the edge detection method with the approach graph with the ACO algorithm. The repairs may be performed to thicken the edge and connect the cutoff edges. The ACO method can be used as a method for optimizing operator Robinson by improving the image result of the Robinson detection average by 16.77% as compared with that of the classic operator Robinson. Rafsanjani and Varzaneh (2015) proposed an approach based on the distribution of ants on an image. Here ants try to find possible edges using a state transition function. Experimental results show that the proposed method is less sensitive to Gaussian noise compared to standard edge detectors and gives finer details and thinner edges compared to earlier ant-based approa- ches. Liu and Fang (2015) proposed an edge detection me- thod based on the ACO algorithm. This method uses a new heuristic functionand a user-defined threshold during the pheromone update process and provides a suitable set of parameters. Experimental results show that the methodcan also show good effectiveness in the presence of noise. Daw- son and Stewart (2014) presented the first parallel im- plementation of an ACO-based edge detection algorithm on the GPU using NVIDIA CUDA. By exploiting the mas- sively parallel nature of the GPU, we can execute significantly more ants per ACO iteration, allowing us to reduce the total number of iterations required to create an edge map. We hope that reducing the execution time of an ACO- based implementation of edge detection will increase its viability in image processing and computer vision. For the image edge detection problem in complex scenes, most ACO algorithms use a fixed number of neighborhood pixels to calculate the pixel gradient, which we call a fixed sensing radius, and then heuristic information that calculates the transition probability of each artificial ant at each pixel. However, this strategy may result in the undetection and misdetection of some pixels at the edge of the image. In other words, it may lose some important edges or detect worthless edges. In addition, the movement of artificial ants for complex scene images will produce precocity, resul- ting in only local optimal solutions, not global optimal so- lutions.
4 Proposed Method
To solve the abovementioned algorithm problems, this paper proposes an image edge detection algorithm that combines reinforcement learning and ACO. This method is different from the traditional method that uses a fixed and constant number of neighborhood pixels to calculate the gradient. By integrating multiagent reinforcement learn- ing with the movement of artificial ants, the number of neighborhood pixels used to calculate the gradient of each pixel can be adaptively determined. In addition, the dual- population strategy and adaptive parameters are introduced to control the movement direction of the artificial ant so as to prevent local optimization.
4.1 Parameter Initialization of the ACO Distribution

The pheromone matrix is constructed by moving artificial ants on the image grid, and the image edge detection is based on the pheromone matrix. Artificial ants deposit pheromones by constantly moving the pixels in the image grid. The initial value of pheromones is set to a random value. When the threshold of the convergence time or a given number of times is reached, pixels with higher phe- romones will have a greater probability of belonging to the edge of the image.
4.2 Reinforcement Learning Transfer Probability Strategy
Reinforcement learning is a field of machine learning inspired by behavioral psychology. It studies how agents should take actions in the environment to maximize the cumulative rewards (Lewis and vrabie, 2009). When calculating the gradient information of pixels in the proof of artificial ant transfer, the selection of sensing radius will affect the effect of edge detection. As mentioned before, most methods adopt the strategy of having the same sen- sing radius in all pixels throughout the search process. This condition affects the detection effect, which may make the algorithm lose some important edges or detect worthless edges (Kober., 2013). Considering the actual situation around each pixel, using different sensing radii for different pixels is a promising optimization approach.
We propose a new variable radius sensing strategy to calculate the gradient of each pixel. Reinforcement learning is integrated into the artificial ant motion, and then the perception radius of each pixel is obtained. In the reinforcement learning strategy, the state of the ant is its position in the×image grid, that is, State=(,), and (,) represents the pixel coordinates. The action of an ant is a binary Action=(,), which means that an action contains two subactions. The first actionis the movement from the current position to the adjacent position in the image grid, and the second actionis the perception radius. After ants choose an action in a state, they will be rewarded. The(State, Action) function, that is,((,),,), is the maximum reward obtained by executing actionin state (,) and selecting perception radius. Thefunction is initially set to a random positive value. After each artificial ant moves, its updating formula is formulated as follows:
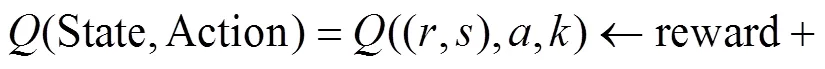
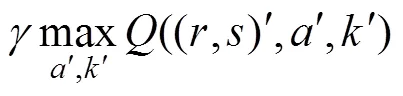
where (,) is the next state of (,) after applying (,) action. All ants share thefunction and maintain thefunction.
During the movement of artificial ants, the sensing radius is determined by(|(,),). This probability can be calculated by Eq. (2):
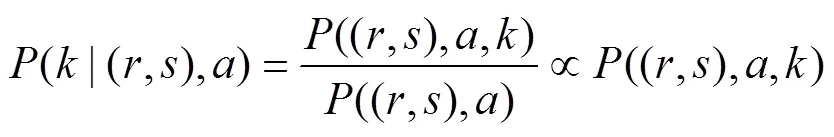
In Eq. (2), the denominator does not include, so Eq. (3) is proportional to the numerator.

In Eq. (3), the selection probability(|(,),) of the perceptual radius can be obtained by thefunction.
In summary, the new transition probability combining ants and reinforcement learning is defined in Eq. (4):
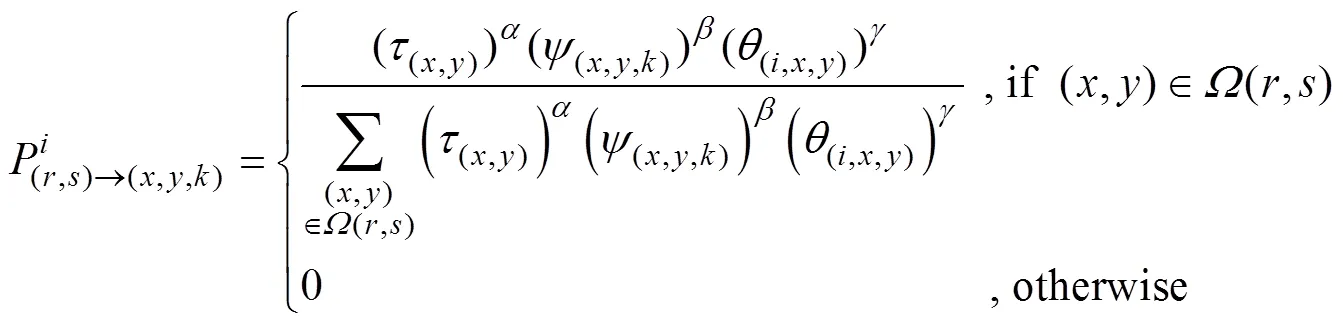
In Eq. (4), (,) represents the pixel coordinates,(x, y)represents the pheromone position (,),(x, y, k)is the heuristic information of the pixel (,),represents the perceived radius of a pixel (,), and(i, x, y)is the direction factor that controls the movement direction of the ant in the population.(,) is a collection of neighborhoods containing pixels (,).is expressed as the(x, y)factor,is expressed as the(x, y, k)factor, andis expressed as(i, x, y).
Heuristic information guides the movement trends of artificial ants. The new heuristic function(x, y, k)is defined as follows:

where grad1and grad2calculation formulas are as follows:



Fig.4 Grad2 calculation strategy.
In addition, we introduce a dual-population strategy,which divides the ACO into two populations. The first po- pulation focuses on the global search, and the second popu- lation focuses on local search. The calculation formula is defined as follows:
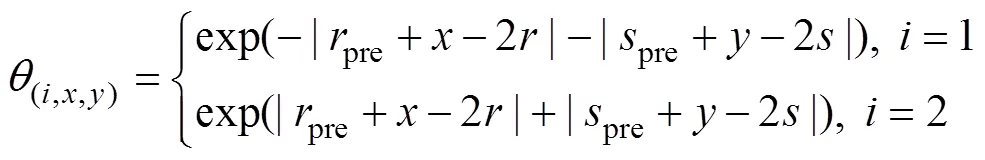
where(i, x, y)is a directional factor controlling the movement direction of the ant of the populationandis an influence factor of the azimuth factor(i, x, y).(=1, 2) re- presents the population number, (,) is the current position of the ant, (pre,pre) is the previous position of the ant, and (,) is the next position of the ant.
The double-population strategy ensures that the ants of the first population will advance in the same direction as the original direction with a high probability and perform a global search to find the optimal solution as soon as possible in the initial stage of the search. The ants of the secondpopulation will advance in the same direction as the original direction with a small probability, move around the cur- rent position with a high probability, and perform a local search to carefully find the optimal solution near the optimal solution.
4.3 Pheromone Update and Edge Extraction
4.3.1 Pheromone update
After the ant moves one step each time, the artificial ant updates the pheromone on the pixel it visits using the fol- lowing Eq. (7).

whereis the evaporation coefficient. The reward after anant moves to a pixel (,) is defined as the difference between the pheromone of the pixel (,) and its neighboring pixel:

We update thefunction using Eq. (1). After the ant moves one step, the pheromone matrix is updated by Eq. (9):
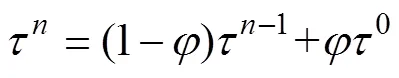
whererepresents the attenuation coefficient of the phe- romone and0is the initial pheromone matrix.is used to avoid the ants in the path from depositing pheromone to avoid local optimization. When the threshold number of iterations is reached, the search is terminated, and the final pheromone matrix can then be used to detect edges in the image.
4.3.2 Edge extraction
The intensity threshold based on the pheromone matrix is calculated as follows:
Step1: Select the average valuein the pheromone matrix and useas the initial value of the threshold.
Step 2: Divide the pheromone matrix into two groups: the first group contains elements larger than, and the other group contains elements smaller than.
Step 3: Calculate the average of the two groups, namely,1and2, and let=(1+2)/2.
Step 4: Repeat the above three steps untilis not changed, and then obtainas the threshold. If the value of the element in the pheromone matrix is greater than, the corresponding pixel belongs to the edge; otherwise, the pixel does not belong to the edge.
5 Experiments
5.1 Experimental Test Environment
During the experiment, the computer hardware environ- ment is as follows: Intel Core i9-9900k processor, GeForce RTX 2080 Ti graphics card, 64GB memory, Windows 10 (64bit) system type, and Matlab R2018b program development tool. The pheromone influence factoris 6, the heuristic information influence factoris 0.1, the orientation influence factoris 1, the initial pheromone0is 0.0001, and the maximum number of iterations is 1000.
5.2 Experimental Test Plan
First, two typical methods are selected to compare the methods proposed in this paper. The first ACO-based me- thod uses the fixed perception radius 1 to calculate the gradient in heuristic information, instead of using the direction factor, herein referred to as ‘perception radius 1’ in short (Nezamabadi-pour., 2006). The second ACO- based method uses the fixed sensing radius 2 to calculate the gradient fixed sensing radius 2 in heuristic information, herein referred to as ‘sensing radius 2’ in short (Tian., 2008). For each test image, the edge detection results of each method are given.
The real image taken by an underwater camera (DEEPSEA Power & Light, San Diego, USA) in the turbid medium is used as the edge detection dataset. Three images are randomly selected: underwater badminton (Fig.5), fish(Figs.6 and 7), and turtle (Figs.8 and 9). Figs.5–9 show the image edge detection results. In each figure, the subgraph (a) is the original image, (b) shows the image edge detection results of the ‘perception radius 1’ strategy, (c) shows the image edge detection results of the ‘perception radius 2’ strategy, and (d) shows the image edge detection results of the proposed method.
Table 1 shows the comparison values of the quantitativeevaluation indexes of each method on the test image. Quan- titative criteria are used to evaluate the methods proposed in this paper. The quantitative criteria include completeness, discriminability, precision, and robustness (Moreno., 2009). The completeness index measures the ability of edge detection to detect all possible edges of a noiseless image. Discriminability measures the ability of edge detection to distinguish an important edge from an unimportant edge. Precision measures the degree to which the edge detected by the edge detection method is close to the actual edge. Robustness measures the ability of edge detection to be immune to noise.
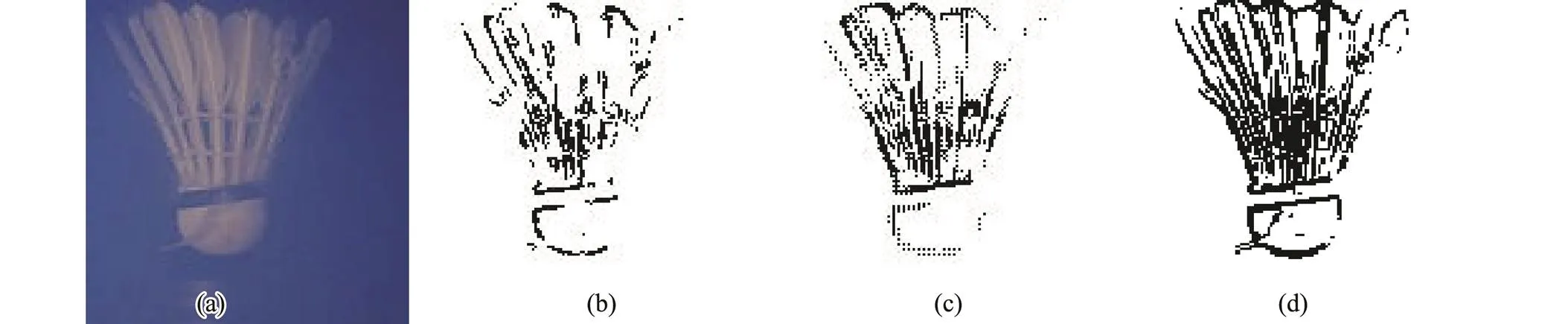
Fig.5 Edge detection results for the badminton image. (a), real image; (b), perception radius 1; (c), perception radius 2; (d), proposed method.

Fig.6 Same as Fig.5 but for the fish image.

Fig.7 Same as Fig.5 but for the fish image.

Fig.8 Same as Fig.5 but for the turtle image.

Fig.9 Same as Fig.5 but for the turtle image.

Table 1 Quantitative comparison results of the methods
As shown in Figs.5 to 9 and Table 1, the method proposed in this paper can detect the unclear edge pixels and can also remove some noise in the image, which is superior to the comparison method in details and as a whole.
Fig.10 shows the pheromones deposited on the pixels of the image after the end of the algorithm. The plane in the two horizontal axes represents the image, and the vertical axis represents the pheromone on each pixel. Fig.10(a) shows the pheromone of Fig.7, and Fig.10(b) shows the pheromone of Fig.8. The experimental results show that the algorithm can extract the image edge effectively and deposit the pheromone on the edge pixels of the image correctly.
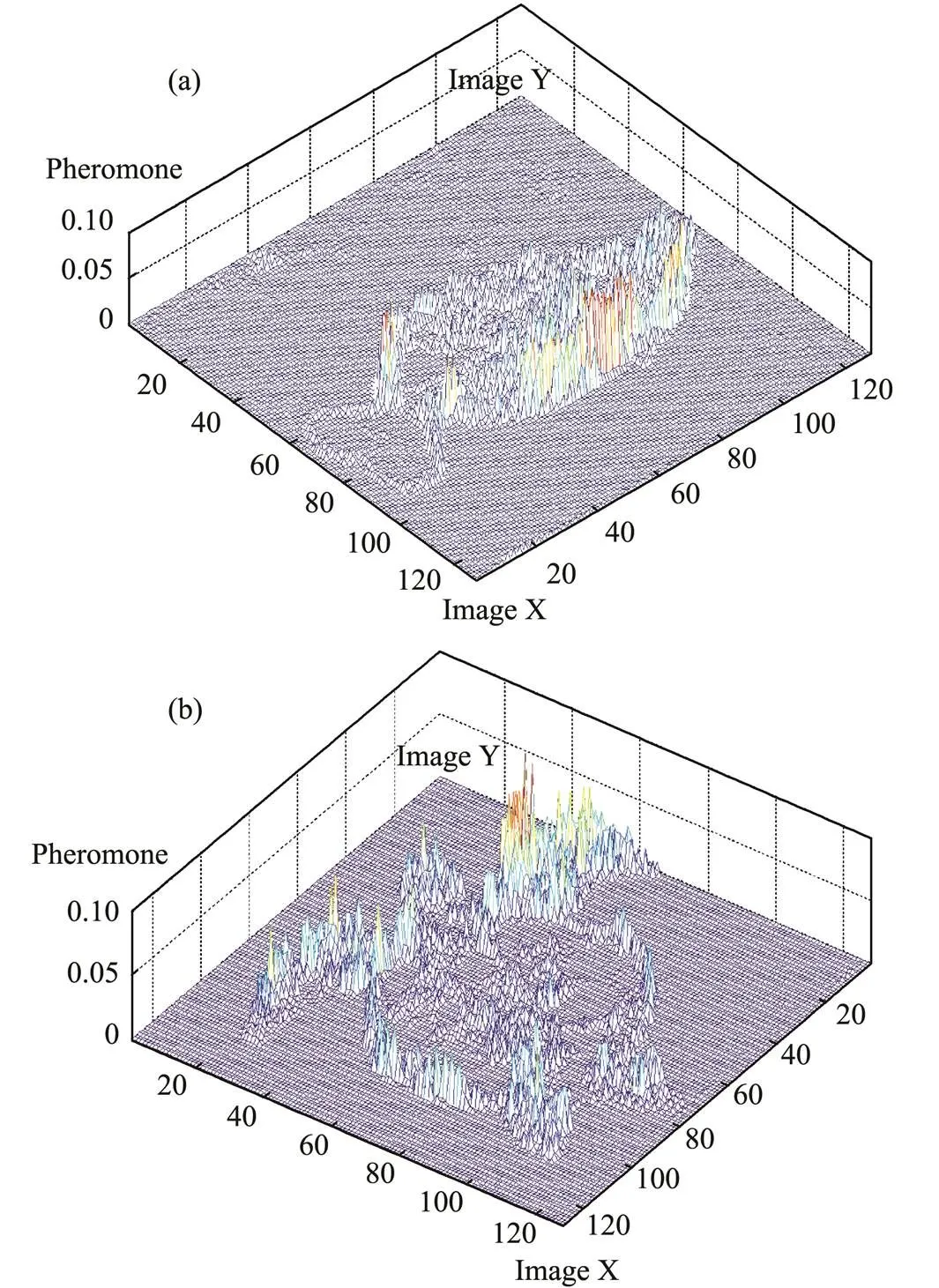
Fig.10 Pheromone of ants deposited on images. (a), the phe- romone is deposited on the image in Fig.7. (b), the phero- mone is deposited on the image in Fig.8.
Finally, to evaluate the performance of the algorithm objectively and accurately, 20 images are randomly selected from the actual underwater image dataset as test samples and then randomly divided into 5 groups with 4 images in each group. The ‘perceptual radius 1’ method, ‘perceptual radius 2’ method, and the algorithm proposed in this paper are used to evaluate the image edge detectionalgorithm quantitatively. The comparison results are shown in Tables 2–5.

Table 2 Completeness of the comparison results of the methods
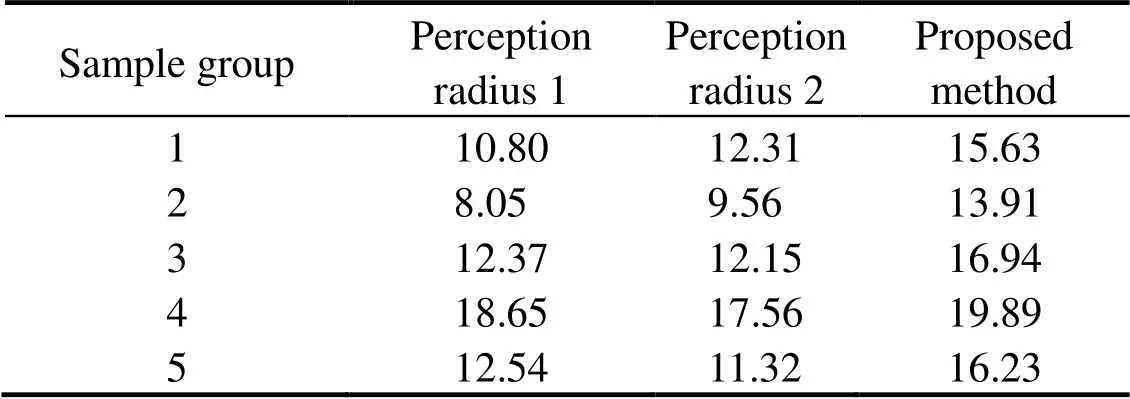
Table 3 Discriminability comparison results of the methods

Table 4 Precision comparison results of the methods

Table 5 Robustness comparison results of the methods
6 Conclusions
In this paper, an ant colony pheromone computing stra- tegy based on reinforcement learning is proposed, which is different from the traditional gradient computing method with a fixed number of neighborhood pixels and can realize adaptive variable neighborhood pixel gradient computing. In addition, a double-population strategy is proposed to control the movement direction of ants: the first population focuses on the global search, whereas the second population focuses on the local search. Thus, the search process takes into account global search and local search abilities. Experimental results show that the algorithm can effectively reduce the impact of noise on edge detection, obtain complete and clear image edges, and achieve good results. In the future, we will study the complexity of the algori- thm to further improve its efficiency and adaptively adjust other parameters in the algorithm.
Acknowledgements
The study is supported by the start-up fund for doctoral research of Northeast Electric Power University (No. BS JXM-2020219) and the Science and Technology Research Program of the Jilin Provincial Department of Education (No. JJKH20210115KJ).
Bonin-Font, F., Oliver, G., Wirth, S., Massot, M., Negre, P., and Beltran, J., 2015. Visual sensing for autonomous underwater exploration and intervention tasks., 93: 25-44.
Chuang, M., Hwang, J., and Williams, K., 2016. A feature learning and object recognition framework for underwater fish images., 25 (4): 1862- 1872.
Dawson, L., and Stewart, I., 2014. Accelerating ant colony optimization-based edge detection on the GPU using CUDA.. Beijing, 1736-1743.
Deng, W., Xu, J. J., and Zhao, H. M., 2019. An improved ant colony optimization algorithm based on hybrid strategies for scheduling problem., 7: 20281-20292.
Fatan, M., Daliri, M., and Shahri, A., 2016. Underwater cable de- tection in the images using edge classification based on texture information., 91: 309-317.
Gao, Y. Q., Guan, H. B., Qi, Z. W., Hou, Y., and Liu, L., 2013. A multi-objective ant colony system algorithm for virtual machine placement in cloud computing., 79 (8): 1230-1242.
Kheirinejad, S., Hasheminejad, S., and Riahi, N., 2018. Max- min ant colony optimization method for edge detection exploi- ting a new heuristic information function.. Mashhad, 12-15.
Kober, J., Bagnell, J., and Peters, J., 2013. Reinforcement learning in robotics: A survey.,32 (11): 1238-1274.
Lewis, F., and Vrabie, D., 2009. Reinforcement learning and adap-tive dynamic programming for feedback control., 9 (3): 32-50.
Li, Q., Sun, X., Dong, J. Y., Song, S. Q., Zhang, T. T., Liu, D.,., 2020. Developing a microscopic image dataset in support of intelligent phytoplankton detection using deep learning., 77 (4): 1427-1439.
Lin, Y. H., Chen, S. Y., and Tsou, C. H., 2019. Development of an image processing module for autonomous underwater vehicles through integration of visual recognition with stereoscopic image reconstruction., 7 (4): 107-149.
Liu, F., Wei, Y., Han, P. L., Yang, K., Lu, B., and Shao, X. P., 2019. Polarization-based exploration for clear underwater vision in natural illumination., 27 (3): 3629-3641.
Liu, X. C., and Fang, S. P., 2015. A convenient and robust edge detection method based on ant colony optimization.,353: 147-157.
Lu, D. S., and Chen, C. C., 2008. Edge detection improvement by ant colony optimization., 29 (4): 416-425.
Mnih, V., Kavukcuoglu, K., Silver, D., Rusu, A. A., Veness, J., Bel- lemare, M. G.,., 2015. Human-level control through deep reinforcement learning., 518 (7540): 529-533.
Montague, P., 1999. Reinforcement learning: An introduction, by Sutton, R. S., and Barto, A. G.,3 (9): 360-360.
Moreno, R., Puig, D., Julia, C., and Garcia, M., 2009. A new me-thodology for evaluation of edge detectors.. Cairo, 2157-2160.
Nasution, T., Zarlis, M., and Nasution, M., 2017. Optimizing robinson operator with ant colony optimization as a digital image edge detection method.. Medan, 930012034.
Nezamabadi-pour, H., Saryazdi, S., and Rashedi, E., 2006. Edge detection using ant algorithms.g, 10 (7): 623- 628.
Rafsanjani, M. K., and Varzaneh, Z. A., 2015. Edge detection in digital images using ant colony optimization., 23 (3): 343-359.
Silver, D., Hubert, T., Schrittwieser, J., Antonoglou, I., Lai, M., Guez, A.,, 2018. A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play., 362 (6419): 1140-1144.
Singh, R., Vashishath, M., and Kumar, S., 2019. Ant colony op- timization technique for edge detection using fuzzy triangular membership function., 10 (1): 91-96.
Sun, X., Shi, J. Y., Liu, L. P., Dong, J. Y., Plant, C., Wang, X. H.,, 2018. Transferring deep knowledge for object recognition in low-quality underwater videos., 275: 897-908.
Tian, J., Yu, W. Y., and Me, S. L., 2008. An ant colony optimization algorithm for image edge detection.. Hong Kong, 751-756.
Vinyals, O., Babuschkin, I., Czarnecki, W. M., Mathieu, M., Du- dzik, A., Chung, J.,., 2019. Grandmaster level in StarCraftII using multi-agent reinforcement learning., 575 (7782): 350-370.
Wang, X. H., Ouyang, J. H., Li, D. Y., and Zhang, G., 2019. Underwater object recognition based on deep encoding-decoding network., 18 (2): 376-382.
January 19, 2021;
June 30, 2021;
September 10, 2021
© Ocean University of China, Science Press and Springer-Verlag GmbH Germany 2022
. E-mail: wangxh@neepu.edu.cn
(Edited by Chen Wenwen)
杂志排行

Journal of Ocean University of China的其它文章
- Study of the Wind Conditions in the South China Sea and Its Adjacent Sea Area
- A Spatiotemporal Interactive Processing Bias Correction Method for Operational Ocean Wave Forecasts
- Characteristics Analysis and Risk Assessment of Extreme Water Levels Based on 60-Year Observation Data in Xiamen, China
- Polar Sea Ice Identification and Classification Based on HY-2A/SCAT Data
- Thermo-Rheological Structure and Passive Continental Margin Rifting in the Qiongdongnan Basin,South China Sea, China
- Effect of Penetration Rates on the Piezocone Penetration Test in the Yellow River Delta Silt