基于边缘计算的在线学习资源压缩存储方法研究
2022-02-22李媛
李 媛
(桐城师范高等专科学校 商贸与电子信息系,安徽 桐城 231400)
网络现代化生活为人们提供了极大的便利,但同时也带来了不小的挑战.由于突如其来的新冠疫情冲击,对各国人民生活和学习都产生了极大挑战.疫情下,在线授课和学习成为主流应对方法,但云端大量数据的存储和计算已不能被传统存储方法满足,数据量大、传输速度慢和存储效率低等现状相继引发资源被消耗和存储空间被占用等问题[1].刘亚琼[2]曾提出基于快速傅里叶变换的数据压缩方法,但部分信号不存在傅里叶变换,对一些数据不够灵敏,该方法存在局限性.孙建伟[3]提出使用RICE算法完成数据压缩,该方法无法一次完成索引,导致压缩效率低.屈永斌[4]提出云计算的数据压缩方法,云计算规模大,扩展性高,但响应时间慢.充分借鉴现有研究成果,引入边缘计算配合云计算工作,可实现“云边协同”,提高资源的压缩存储效率,减少占用云端存储空间[5-7].为此本文提出基于边缘计算的在线学习资源压缩存储方法,满足现阶段大量数据的压缩存储需求.
1 基于边缘计算的在线学习资源压缩存储方法
1.1 基于分布式压缩感知的边缘算法
压缩感知的目的是重构原始信号,主要通过构建联合稀疏模型、信号稀疏表示、字典学习、选取测量矩阵、联合重构等步骤完成在线学习资源的压缩感知[8-9].压缩感知具体过程见下文.
(1)
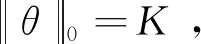
将M×N的测量矩阵Φ投影在x上得出公式(2).
y=Φx=Φψθ=Θθ,
(2)
其中,y表示投影系数组成的N×1列向量,称为观测矢量,Θ为观测矩阵.
在压缩感知理论中,可以用M个非自适应的线性投影值重构出x,前提是测量矩阵Φ和正交基矩阵ψ不相关或者Θ具备路由信息协议特性.如果测量矩阵选择随机矩阵,那么Θ会在很大程度上满足路由信息协议条件.
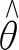
(3)
公式(3)中,1-范数问题可以利用正交匹配追踪的线性规划方法求解.使用正交匹配追踪方法重构N维K稀疏向量需要的测量值个数需满足公式(4).
M≥cK,c≈2ln(N).
(4)
1.1.1 联合稀疏模型
构建第一联合稀疏模型JSM-1对在线学习资源进行压缩采集.
在JSM-1模型中,信号群中的所有信号均可拆分,表达式见公式(5).
xj=zc+zjj∈{1,2,…,J},
(5)
其中,zc为共同分量,zj为特征分量,zj=ψαj,αj为第j个信号的独立稀疏系数;xj表示第j个信号,J为信号群中的信号个数;zc=ψθc,θc为所有信号的公共稀疏向量.
1.1.2 信号稀疏表示及字典学习(K-SVD)算法
假设字典为D,在线学习资源为Y,系数矩阵为X,那么K-SVD的目标函数为
(6)
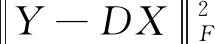
(7)
(ii)字典更新.在字典学习算法下重置每个字典原子,每次只重置一个[10],惩罚项见公式(8).
(8)

(9)
1.1.3 选取测量矩阵
选用贝努利随机矩阵,当贝努利测量值M的关系满足M≥4.72Klog(N/K)时即可重构原始信号,其中N为原始信号长度,K为稀疏度.
1.1.4 联合重构
采用同步正交匹配追踪算法(SOMP)与K-SVD算法组成CS-SOMP联合重构算法.为得到满足目标阈值的信噪比,首先根据SOMP算法重构收集的在线学习资源,再通过K-SVD对稀疏字典持续重置降低误差以达到要求.此算法不需要大量的字典原子和测量值,大幅度提高了效率,具体过程如下.
(i)初始化参数.令初始残差rj=yj,j[1,s],其中s为节点个数,字典原子个数τ,索引值ξ为零,索引集Λ0为空集.
(ii)设数据长度n,测量值数量m,将原始信号矩阵Xn×s和Φm×n、初始字典Ψn×n以及最低重构信噪比SNRdef输入算法.
(iii)计算传感矩阵Am×n=Ψm×nΦn×n.
(iv)令各行残差与Am×n各列二范数相加,将最大值对应到Am×n列索引,合并到上次索引集.数学表达式见公式(10)和公式(11).
(10)
Λτ=[Λτ-1ξj].
(11)
(v)残差更新见公式(12)和公式(13).
(12)
(13)
(vi)重构中间信号及其相对方均根误差(R)与重构信噪比(SNR)计算见式(16).
(14)
(15)
(16)
(vii)当SNR符合要求时,输出结果;当SNR比SNRdef小时,重复步骤(4)直到符合要求.
1.2 基于云边协同的在线学习资源压缩存储方法
当有大量数据需要分析时可以使用云计算技术,该技术具有免维护计算硬件、关联软件和不需要储存数据在本地等优点,但缺点是响应时间慢,这是由于其他终端与云平台间的距离比较远导致.此时引入一种创新方式——边缘计算[11-12].该算法离其他终端距离更近,可以解决云计算因距离导致的响应时间慢问题,同时数据和存储中间需要的宽带也随之减少.因此引入边缘计算配合云计算工作,可以降低网络延迟,改善系统性能.
基于如图1所示的云边协同框架,采集在线学习资源,在云端服务器上传经边缘计算CS-SOMP联合重构算法重构产生的稀疏字典原子和测量值,然后进行以下操作.
(i)在线学习资源数据的压缩存储;
(ii)建立完备稀疏字典.边缘服务器对云端服务器发送的结果进行资源调整,采集资源后再传到云端服务器[13-14].
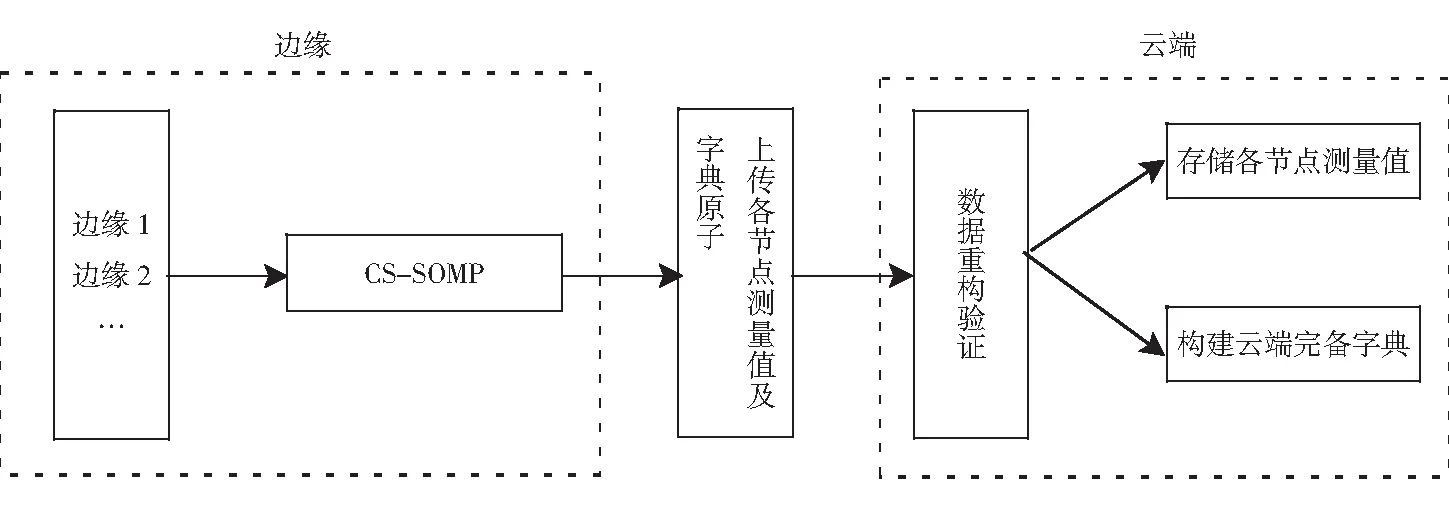
图1 云边协同框架
在云边协同架构下,当采用CS-SOMP联合重构算法一起压缩采集s个节点的数据时,每个数据使用同一个字典原子,各节点数据长度设为n,τ为上传的字典原子个数,则
(17)
其中,Ym×s为各节点测量值,Dτ×n为字典原子,Xn×s为各节点原始信号.上传云端的测量值与字典原子的存储量随着矩阵长度m和传入云端字典原子个数τ的降低而降低.完备字典Dk×n的建立需要云端整合各边缘上传的字典原子,来保证迅速精准地调用云端数据,其中k表示总原子数.稀疏表示系数θn×s描述见公式(18).
θn×s=SOMP(Ym×s,Dk×n,Ψm×n).
(18)
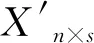
(19)
数据的压缩存储通过建立云端完备字典来完成,此时只需各边缘上传测量值,极大降低了云端的存储空间.具体构建完备字典的过程如下.
(i)di为字典原子,Dk为云端初始稀疏字典Dk×n中第k个原子,它们间的相关度用ri,k表示,关系式见公式(20).
(20)
假设上传到云端的字典原子di与云端稀疏字典Dk×n的整体相关性较弱,则产生的各个ri,k均比某一阈值低,此时将该字典原子扩充进云端稀疏字典.
(ii)过完备稀疏字典由上传的字典原子组合而成,各字典原子间的相关性通过正则化降低.具体过程见公式(21)和公式(22).
Dk×n={d1,d2,…,dk},
(21)
(22)
(iii)通过归一化过完备字典更新字典原子,见式(23).
(23)
(iv)在上传的测量值中通过分布式压缩感知算法,再与过完备稀疏字典相结合恢复原始数据,由此确认恢复存储数据的可能性.在每个节点获取对应稀疏系数θj,j∈[1,s],通过把每个节点数据的测量值作为存储数据完成数据的压缩存储[15].
综上所述,基于边缘计算的在线学习资源压缩存储方法的具体流程如图2所示.
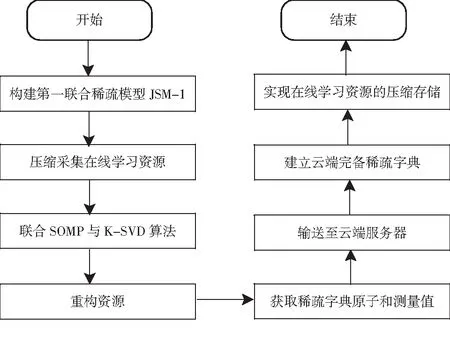
图2 基于边缘计算的资源压缩存储方法的具体流程图
2 实验分析
以某在线学习网站的资源为研究对象,验证本文方法的在线学习资源压缩存储性能.
利用本文方法压缩存储在线学习资源时,需要通过在云端上传边缘计算采集到的数据及其相应的稀疏字典原子和测量值,再进行恢复等操作实现.在保证其他参数相同的情况下,对收集到的数据采用本文方法训练学习.字大小典分别是128、256、512、1024,不同大小字典在稀疏度和压缩比逐渐增大时的信噪比变化结果见图3.
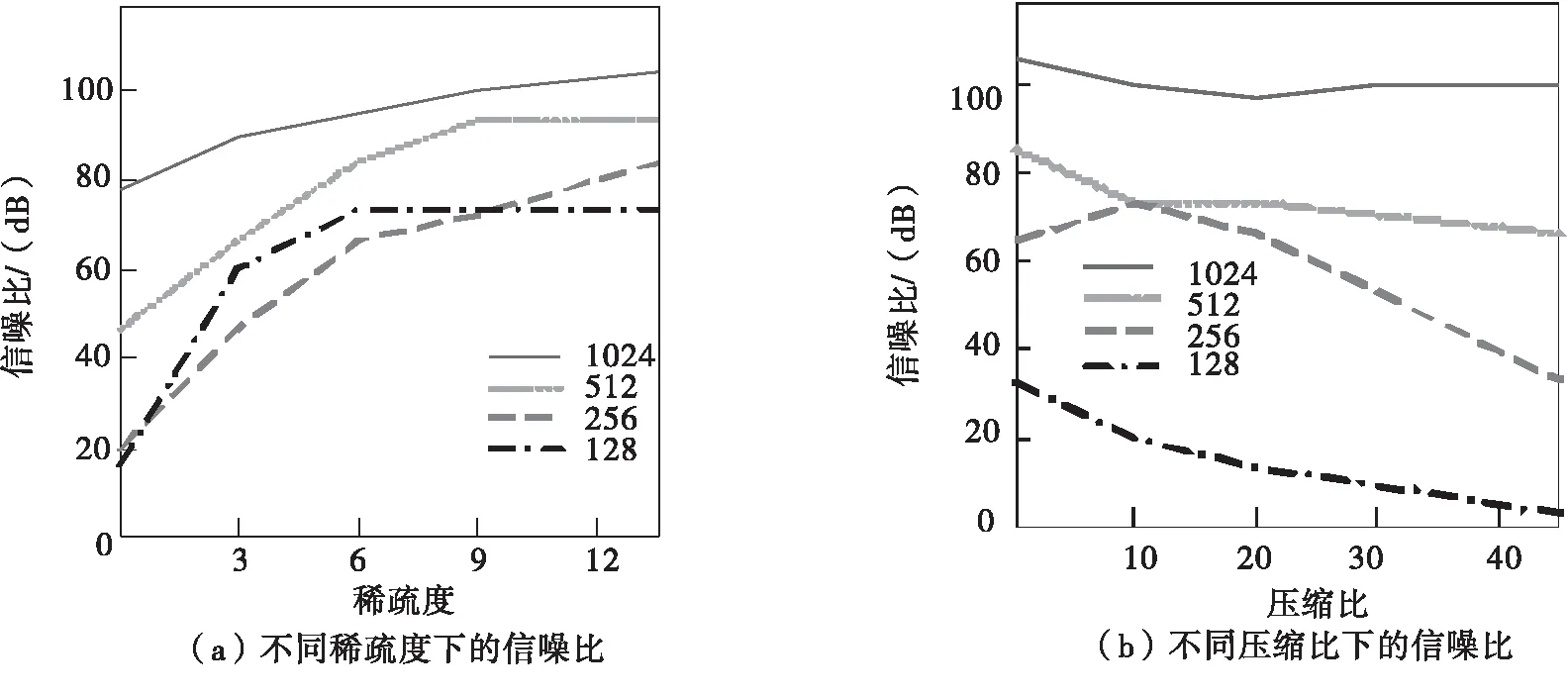
图3 不同大小字典信噪比对比
由图3可知,不同大小字典的信噪比均随着稀疏度的增加呈升高趋势,且随着字典增大,信噪比增大幅度变小;随着压缩比逐渐增大,不同大小字典的信噪比均有不同程度下降,128字典和256字典的信噪比在压缩比达到20%之后出现大幅下降,但1024大小的字典信噪比始终保持平稳,且一直高于其他字典的信噪比,说明字典越大,应用本文方法进行数据压缩存储时的数据处理性能越好.
另外采用本文方法压缩存储在线学习资源过程中,样本数量也是影响字典学习的重要因素.在字典固定1024大小的情况下,分别对比25、50、75和100个样本数量训练学习的字典信噪比,对比结果见图4.
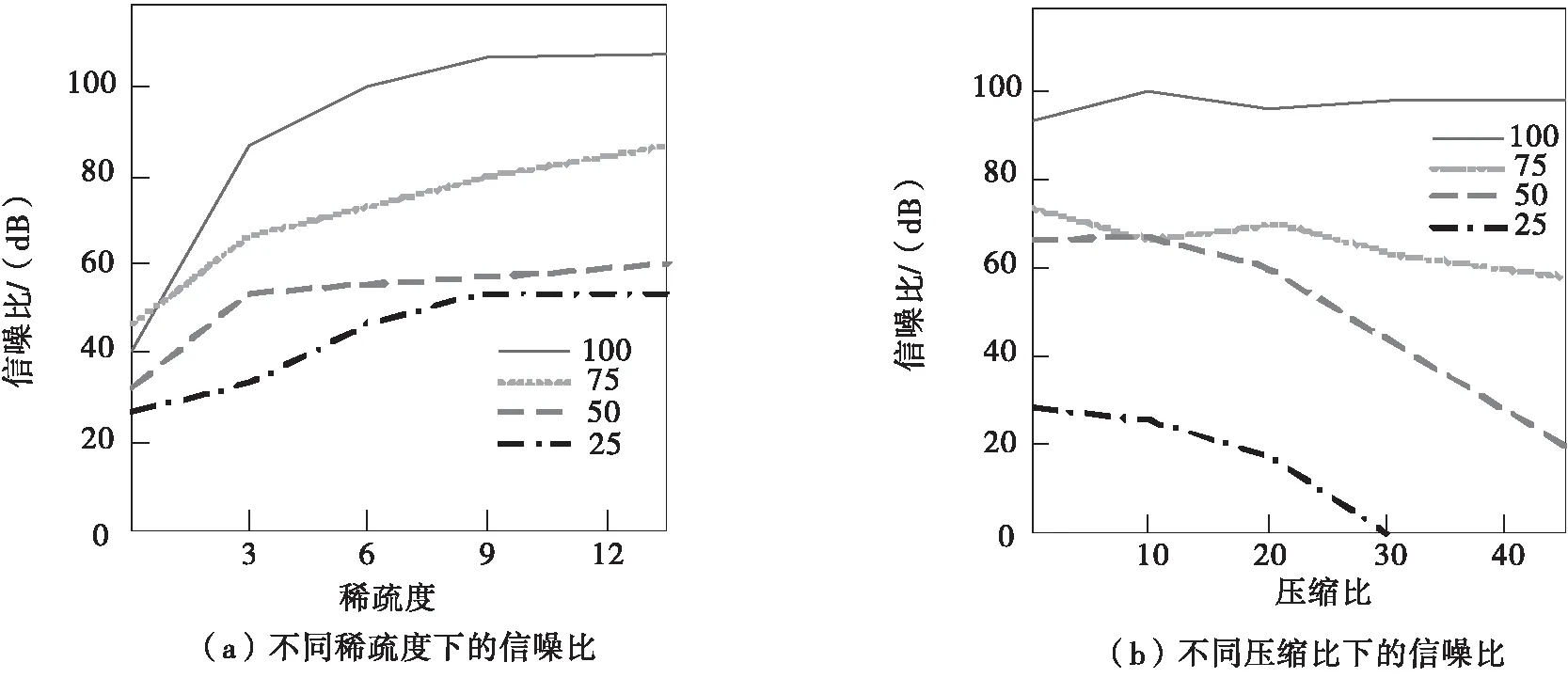
图4 不同样本数量训练学习字典性能结果图
图4(a)表明,随着稀疏度增大,各字典的信噪比均呈上升趋势,后期增幅变小,逐渐达到稳定.但样本数量越大,信噪比越高,前期上升速度越快,证明字典学习效果更好;图4(b)描述训练样本数量越少应对压缩比变化能力越差,仅有25个样本数量的字典在压缩比为30%的时候出现严重失真,而100个样本数量的字典信噪比随压缩比增大仍保持稳定.实验结果表明,采用本文方法压缩存储在线学习资源时,样本数量越大,训练学习字典效果越好,对应的压缩存储优势越显著.
为了验证本文方法的有效性,采用本文方法、文献[2]方法和文献[3]方法,对在线学习资源进行压缩存储,对比三种方法压缩后图片的清晰度,对比结果如表1所示.

表1 清晰度对比结果(%)
根据表1可知,本文方法对在线学习资源进行压缩存储后,图片的清晰度最高可达100%,压缩后图片清晰度较高,无信息缺失.
为了进一步验证本文方法的有效性,对本文方法、文献[2]方法和文献[3]方法的在线学习资源压缩时间进行对比分析,对比结果如表2所示.

表2 在线学习资源压缩时间对比(s)
根据表2可知,本文方法的在线学习资源压缩时间在2s内,比文献[2]方法和文献[3]方法的在线学习资源压缩时间短.
3 结论
本文以分布式压缩感知算法为边缘算法,通过对在线学习资源的稀疏采样识别,利用云边协同框架高效压缩存储数据的同时实现数据完整恢复,保证了在线学习资源质量.通过实验,验证本文方法训练学习1024大小字典的数据处理性能最好,且压缩存储性能随样本数量增多而变好,本文验证四种数量样本中,数量为100的样本数据训练学习效果最好.
