一种知识图谱的电力设备缺陷检索方案设计与实现
2022-02-21杨迪梁懿王秋琳陈新梅陈恩光王燕蓉
杨迪, 梁懿, 王秋琳, 陈新梅, 陈恩光, 王燕蓉
(1.国家电网有限公司,北京 100000;2.福建亿榕信息技术有限公司,福建,福州 350003)
0 引言
在电力行业中,电力系统的日常管理和运维离不开电力相关信息系统的支撑,电力信息系统具有规模庞大且复杂度较高的特点,信息系统局部出现问题极易使电网的安全稳定运行状态受到影响。这就对电力从发电、输电到用电的全过程,尤其是电力设备缺陷的监控能力提出了更高的要求,及时发现运行状态下电网中电力设备的缺陷、故障以及对设备状态的回查是保证电网安全稳定运行的重要环节,监控电力设备需基于信息化系统实现。
1 系统分析
由于电力设备缺陷记录较为复杂,增加了准确检索缺陷记录的难度,部分电力相关规范以表格形式总结了缺陷及其对应现象,但难以对复杂多样的缺陷情况进行全面归纳,且易受到巡检人员经验的局限,以自然语言形式描述的缺陷记录则增加了计算机对其理解的难度。文本的检索效果取决于语义分析和表示的有效性,传统电力设备缺陷文本的语义框架主要基于人工经验确定并采用二维表形式,文本表示则基于框架的填充实现,过于依赖人工经验,缺乏灵活性及对复杂电力设备缺陷情况的适应性,缺少对缺陷记录的多样化表达,目前运用机器学习算法已成为避免人工经验局限的有效手段,对缺陷记录中的词级别规律通过计算机的使用完成自动挖掘过程,再以具有一定规律性的词的统计特征为依据对文本进行表示,但此种特征选取方法受到是否出现关键词或词的出现频率的限制,解释性不足,且对关键词内在逻辑的考虑不足,易局限于字面特征。缺陷文本在记录设备缺陷时根据实际情况完成,文本间的逻辑关系较为明确[1]。本文在现有研究成果的基础上,为有效弥补语义框架二维表结构的不足,将文本信息及其关系使用知识图谱进行表示,基于缺陷文本信息内在逻辑,结合运用语言处理及机器学习等技术,实现对构建知识图谱所需信息(存储于缺陷语料中)的自动提取,再基于自动构建的知识图谱完成了一种缺陷记录检索方法的设计。
2 电力设备缺陷知识图谱的构建
2.1 知识图谱技术
2.1.1 知识图谱概述
作为一个知识库,知识图谱以知识网络的形式通过关系联结和组织实体与属性,实体—关系—实体(或属性)三元组是构成知识图谱的基本单元,实体和属性的存在形式在采用图的形式表示知识图谱为节点,关系对应连接两节点的有向边,三元组结合时则基于共有的实体或属性实现,在此基础上构成网状结构的知识图谱。知识图谱分为开放域(不限定知识领域,主要用于搜索引擎)和封闭域(只能应用于特定行业)两类,专业性不强的开放域知识图谱的应用深度受到局限,知识专业性较强的封闭域知识图谱的实体、属性和关系能够进行限定和穷举,针对性较强、应用比较深入[2]。
2.1.2 知识图谱的构建
该过程通常分为知识抽取、知识融合、知识加工3部分,知识抽取以非或半结构化数据作为主要抽取对象(包括数据的实体、属性和关系)构成知识图谱的基本元素,知识融合负责实体消歧(用于区分存在多种含义的实体名称)和共指消解(用于合并相同含义和指代的名/代词)处理数据的实体,接下来在现有结构化数据中加入经整合后的实体、属性和关系,形成知识图谱,在知识图谱持续应用过程中需对其数据质量和应用效果进行动态评估,根据不断发展丰富的知识完善和修正知识图谱[2]。
2.2 设备缺陷知识图谱的构建
在日常巡检和试验电力设备过程中,已积累了大量设备缺陷记录,在经分级、消缺等缺陷处理后,相应的缺陷及处理记录的利用率不高,并且设备缺陷情况具有复杂多变的特点,导致缺陷处理工作对工作人员知识与经验的依赖程度较高。根据某条缺陷记录对相同情况的历史记录进行检索,可参考之前的经验及处理方法对该缺陷进行相应处理,进而提高实际缺陷管理工作质量和效率。电力设备缺陷记录的部件、现象、程度等通常使用基于自然语言的单个句子形式进行记录,其知识图谱属于封闭域知识图谱,根据电力设备缺陷记录的特点基于上述知识图谱构建过程进行修改:(1)考虑到作为缺陷部件属性的缺陷现象同时具有缺陷程度等属性,对实体间关系、属性间关系及实体与属性关系进行抽取;(2)有明确术语规范的电力行业基本没有实体歧义问题,因此取消了实体消歧步骤,但需进行共指消解(因为属性会出现同义词现象),由于封闭域数据量较小,应先共指消解再抽取关系,以确保获取更多的关系训练样本;(3)国家电网公司的输变电设备缺陷用语规范可作为进行关系抽取时的训练样本,该规范对部分三元组采用表格形式进行了归纳,提高了结构化数据的利用率,关系抽取后为避免出现冗余,需筛选处理关系,提高知识图谱的后续应用质量;(4)通过整理与合并各三元组形成图结构的缺陷知识图谱。具体构建过程[3]如图1所示。

图1 设备缺陷知识图谱的构建
2.3 实体/属性抽取
该部分主要负责完成对缺陷记录中表示实体/属性的词的抽取与词性标注,可采用电力专业词典对能够穷举的实体和属性进行直接的匹配与抽取,具体步骤为:(1)先基于词典和隐马尔可夫模型对设备缺陷记录进行分词,并结合运用电力专业词典保证准确率;(2)接下来在电力专业词典中逐一检索语料中的词,有匹配项则抽取该词表示的实体/属性;(3)对语料中所有词进行词性标注,并将全部词分为描述设备及部件的名词(表示实体)、描述缺陷现象的动词(表示属性)、描述缺陷程度的副词(表示属性)、描述缺陷程度的量词(表示属性)、未在词抽取中被抽取出的词(非实体非属性)5类,对应词性分别为En、Pv、Pad、Pq和按原词典标注[3]。
2.4 共指消解
共指消解主要负责完成全部表示实体/属性的同义词的查找(无需考虑代词),具体步骤为:(1)先按词性进行分类,由于同义词的词性相同,可按照4种词性将全部的词划分为4个集合后,再对集合进行同义词识别;(2)向量化处理,对缺陷记录使用word2vec方法进行训练,得到记录中全部词对应的词向量,在此基础上通过计算余弦相似度完成对词间的相似程度的判断;(3)筛选词对,向量化处理时,对于句中位置邻近的词或上下文相似的词会表现出较高的余弦相似度,所寻找的同义词为同位词对,而其对应的两个词出现在同一条缺陷记录中的概率较小,为完成同位词对的有效筛选,可删除出现于同一条记录中的词对;(4)形成同义词表,由含有相同词的同位词构成,在所形成的若干个同义词集中各选一个词作为集合的标准化名称[4]。
2.5 关系抽取与关系筛选处理
各实体/属性间的关系及关系类型通过关系抽取完成识别过程,可对关系结合实体/属性的词性进行限定,具体如表1所示,关系抽取转化为分类问题,训练集由国家电网公司的输变电设备缺陷用语规范提供,为提高监督训练较少训练样本方法的分类效果,采用半监督协同训练方法,先形成待分类的词对再对关系进行分类,即按照表1的4种词性组合的词对在所有词的两两组合中筛选后进行关系分类。
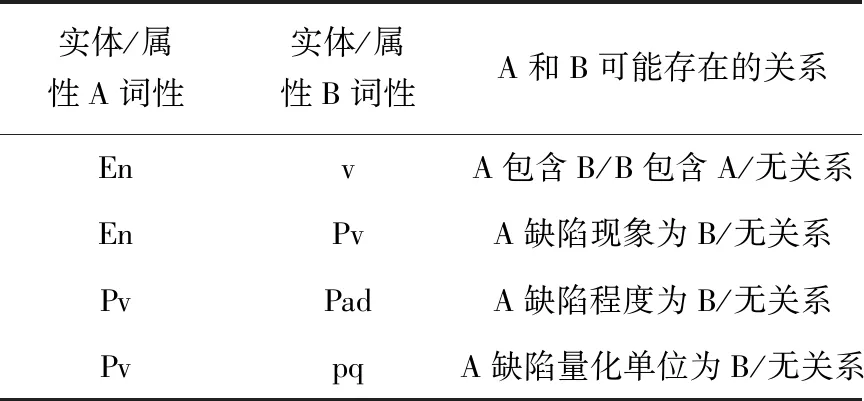
表1 实体/属性间的关系类型
关系筛选主要负责删除冗余的包含关系,考虑到实际工作过程中存在未严格按照规范逐级记录的问题,对于一些非直接包含的关系在关系抽取时,易被识别有包含关系,出现的结构如图2所示。可采用知识推理识别“主变”与“风扇”间的包含关系,在对全部间接包含关系进行表示时,会使知识图谱的复杂性显著提高,需对间接包含关系进行统一删除,具体对各具有包含关系的实体检测两实体间的连通路径,存在另一条路径则删去两者间的包含关系[5]。
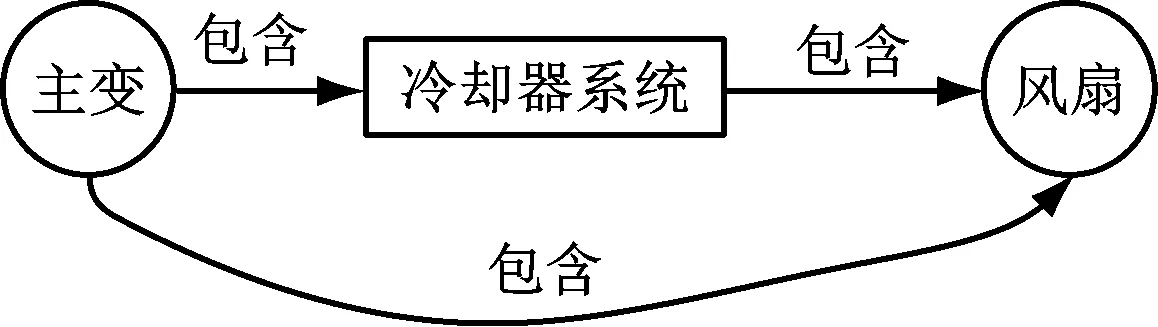
图2 包含关系的实例
3 电力设备缺陷记录检索
3.1 检索的实现
对于一种缺陷情况,缺陷检索主要负责在缺陷记录集中找出与其一致的全部记录,可逐条匹配给定的缺陷与记录集的记录,并输出成功匹配的结果,两条缺陷情况的描述一致,意味着在知识图谱中该记录所对应的实体和属性连成的完整树一致,只需找出并对比各缺陷记录对应的完整树即可,在记录缺陷部位不完整时,寻找对应的完整树以构成完整的实体路径时,需通过已有信息对缺少的实体进行推理,缺少关键缺陷部位信息难以对缺陷主体进行明确定位,如缺陷记录没有唯一对应的完整树,给出代表关键信息缺失的错误提示1;多记缺陷信息时,给出表示关键信息矛盾的错误提示2[6]。
3.2 缺陷记录检索过程
知识图谱结构如图3所示。图3中,节点a至i、j和k分别对应En和Pv词性的实体和属性,节点m和l分别对应pq和Pad词性的属性,先通过分词和词性标注某条缺陷记录,再寻找其完整树,然后规范化处理记录中全部词得到标准名称(对照同义词表完成)。规范化后记录的实体/属性由节点b,c,d,i,j,m和l表示,在知识图谱中以黄色节点标记,确定缺陷记录完整实体路径的流程如图4所示。先输入与被标记的j匹配的i,记为节点N;令有序集合S为空集,对N向上的未搜索过的路径采用深度优先搜索方法完成搜索过程,从N出发依次经过i,f,e,g节点对边1→2→3进行搜索,得到由{i,f,e,g}构成的有序集合R,但有被标记的实体节点不在R中;继续搜索新路径,退回节点e搜索边4→5获取由{i,f,e,b,a}构成的新路径R,同样有被标记的实体节点不在R中;继续搜索新路径,退回节点f搜索边6→7→8→5获取由{i,f,d,c,b,a}构成的新路径R,此时S为空集,R涵盖全部被标记的实体节点,令S=R;继续搜索不存在新路径,S非空,故输出节点有序集合S,在c和d未被标记的情况下,表明无法判断f对应的实体是源于d或e对应的实体,此时S为非空集,输出错误提示1;e被标记会混淆f对应实体的来源,S仍为空集,输出错误提示2;连接完整实体路径S中全部节点和被标记属性节点得到缺陷记录完整树由{a,b,c,d,f,i,j,l,m}构成[7]。
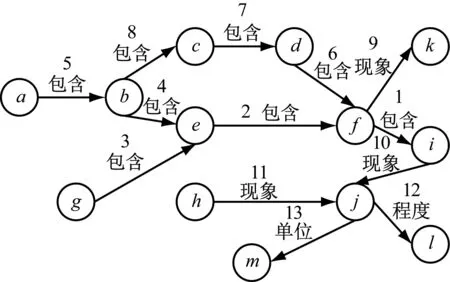
图3 知识图谱结构示例
图4给出实体路径确定的计算框图。
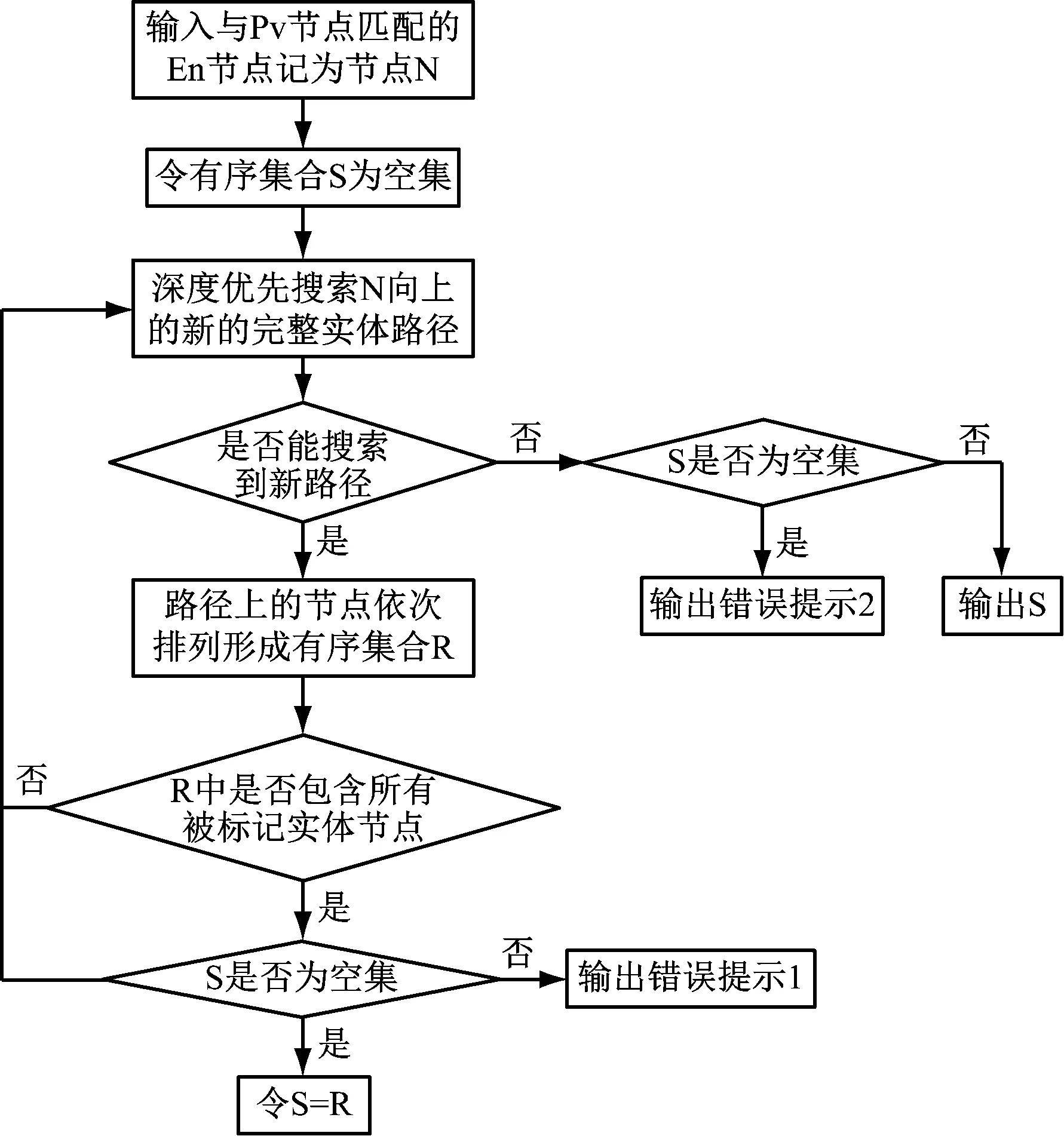
图4 完整实体路径确定流程
4 算例分析
为测试本文检索方法的效果,以某电网公司变压器缺陷记录提供3 000条作为实验对象,随机平均分为3份,分别作为训练集(包含所有正确记录)、待检索的语料库、测试集,以训练集作为非结构化数据来源构建知识图谱时,构建KG1(不加入结构化数据信息)和KG22(加入输变电设备缺陷用语规范包含的结构化数据信息)个知识图谱模型,然后逐条输入测试集的记录,检索通其匹配的全部记录。进行缺陷记录检索时,对比LSI和LDA模型的效果,通过准确率、召回率、F1(两者的综合效果)值评价检索效果[7]。
(1)自动构建知识图谱的结果与分析
采用训练集完成知识图谱的自动构建,并加入输变电设备缺陷用语规范包含的结构化数据信息,得到的变压器缺陷知识图谱由614条边和490个节点构成,出现在缺陷语料中的表示实体/属性的词均能被抽取出来,基于1 000条训练记录训练,判别两两构成的词对是否为同义词,共指消解准确率的统计结果为94.8%,对于出现频率较低的词难以准确识别出同义词,或将相似的近义词误判断为同义词。关系抽取准确率的统计结果为92.2%,因为在记录语料中某些词对对应的实例较少,并且机器学习模型存在一定的不确定性。不断增加的训练记录数量能够改善词频过低、实例过少等问题,提高构建知识图谱的准确性。构建完知识图谱后,在检索时只进行图搜索即可。
(2)缺陷记录检索结果
针对测试集1 000条缺陷记录,分别采用本文模型、LSI和LDA对其在语料库中的匹配记录进行检索,并取测试记录的混淆矩阵的平均值,得到的结果如表2所示。相比于其他2个模型,本文模型的准确率、召回率和F1值较高,通过结构化数据的加入实现了检索效果的有效提升,知识图谱充分结合了电力领域的知识,可准确识别关键信息,具有较强的同义词匹配及知识推理能力。以表3中记录的匹配为例,采用上述3K模型判断各组2条缺陷记录的匹配情况,结果如表4所示。A1和A2只相差一个词,但描述的却是不同的缺陷,2条记录不匹配但在字面上很相似,知识图谱模型实现了在不同完整树中定位两条记录,进而实现了对其不匹配结果的准确判断;B1和B2没有相同的词,但描述了同一缺陷现象,LSI和LDA模型同一难以识别字面相差较大的2条记录文本,知识图谱模型通过节点连接实现了准确的推理过程。
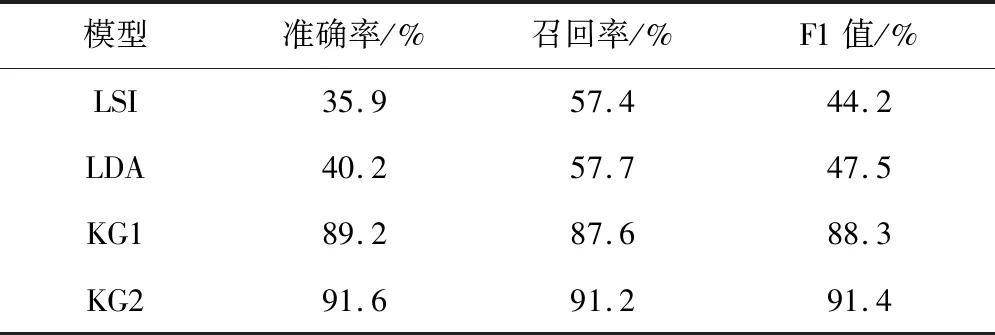
表2 不同模型的检索结果

表3 2组缺陷记录实例

表4 2组记录匹配关系的判断结果
5 总结
本文通过使用知识图谱技术完成了一种电力设备缺陷记录检索方案的设计,构建了一种缺陷记录检索方法,详细介绍了构建知识图谱与检索缺陷记录的过程,采用知识图谱的图搜索方法实现对设备缺陷的检索过程,本文基于知识图谱的检索方法取得了较佳的效果,使缺陷检索质量及效率得到有效提升,为现有缺陷的处理提供支撑。
