基于Google Earth Engine的黄土高原覆膜农田遥感识别
2022-02-21郑文慧王润红曹银轩何建强
郑文慧 王润红 曹银轩 靳 宁 冯 浩 何建强
(1.西北农林科技大学旱区农业水土工程教育部重点实验室, 陕西杨凌 712100;2.西北农林科技大学中国旱区节水农业研究院, 陕西杨凌 712100;3.山西能源学院资源与环境工程系, 晋中 030600; 4.中国科学院水利部水土保持研究所, 陕西杨凌 712100)
0 引言
黄土高原位于我国西北地区中部,是典型的旱作农业区,在国家粮食安全体系中具有举足轻重的作用[1]。黄土高原蒸发强烈,干旱少雨且年内降雨分布不均匀[2],同时田间管理水平落后,导致水资源严重匮乏,限制了黄土高原农业的发展[3-4]。因此,采取有效的田间管理措施提高水资源利用效率是旱区农业可持续发展的必然趋势。地膜覆盖技术具有节水、保墒和增产的性能[5],因此在黄土高原大田作物生产中被广泛应用[6]。然而,随着地膜用量的逐渐增加和覆盖面积的不断扩大,地膜易破碎、难降解、难回收的短板日益显露,生态环境问题日益严重[7-8]。精准获取覆膜农田的时空分布信息有助于发挥地膜覆盖技术的积极作用、缓解生态环境压力,也有助于相关部门对地膜的使用和分布进行监管和调度,提高对地膜污染的防治能力。
随着科学技术的深入发展,应用遥感技术快速提取覆膜农田信息成为可能。遥感技术具有信息获取快、观测范围大等特点,能够宏观地把握地物空间分布概况[9-11],从而解决了大范围内覆膜农田监测的难题。近年来,覆膜农田的监测和识别逐渐发展为农业遥感领域的研究热点[12-15]。目前,我国大多数相关研究地区主要集中在新疆等地膜连片分布地区,该地区的地膜识别相对容易。此外,已有研究多采用支持向量机和决策树等单一算法进行分类,较少采用多分类器集成算法。
谷歌地球引擎(Google Earth Engine,GEE)是专门用于卫星影像及其它空间数据解译运算的开源智能云平台[16],它将谷歌最先进的云计算能力和存储能力用于处理各类热点问题,为遥感工作者及其他公众用户提供了便利[17-19]。近年来,GEE平台逐渐被广泛应用于农田面积提取等研究[20-21]。GEE平台改变了传统遥感软件处理数据的定式,解决了大尺度应用研究中数据收集难、解译效率低的弊端,从而为黄土高原覆膜农田的识别提供了可能。
本研究以甘肃省定西市安定区团结镇作为黄土高原覆膜农田的典型区域,借助GEE平台,利用分辨率30 m的陆地卫星地表反射率数据(USGS Landsat 8 Surface Reflectance Tier 1),采用特征选择和随机森林算法对该地区的覆膜农田进行提取,构建基于GEE平台的黄土高原覆膜农田识别方法框架,以研究随机森林算法的关键参数对遥感影像地物分类结果的影响。通过分析不同特征组合下的遥感影像分类结果,确定识别黄土高原覆膜农田的最优特征组合方案;通过比较不同的分类算法,验证随机森林算法在黄土高原覆膜农田识别中的有效性。
1 材料和方法
1.1 研究区概况
本研究选择黄土高原和西秦岭山地交汇处的甘肃省定西市安定区团结镇作为研究区域(图1)。该地区地势南高北低,山脉南北走向,属温带大陆性季风气候,总面积约134.43 km2,年平均气温6.3℃,有效积温2 300℃,年平均降雨量430 mm,无霜期140 d。统计数据显示,截至2019年底,团结镇总耕地面积达53.11 km2,约占全镇总面积的2/5[22]。该地区属于典型的黄土高原地膜覆盖种植区,地膜覆盖马铃薯种植面积占总种植面积的90%以上。
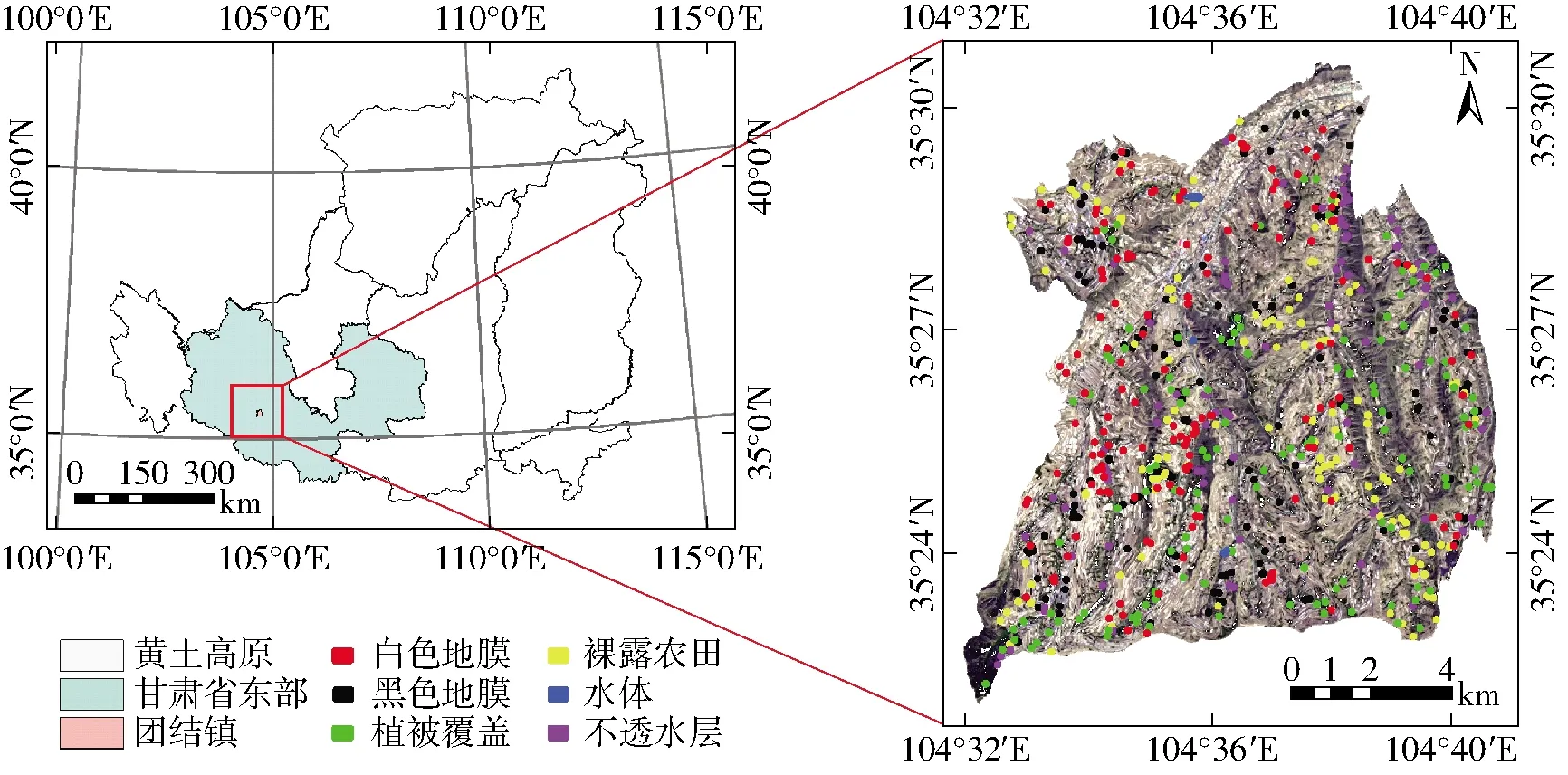
图1 研究区域位置图和地面样本点分布示意图Fig.1 Location schematic of study area and distributions of land surface sample points
1.2 数据来源与处理
1.2.1Landsat-8卫星数据
本研究所需Landsat-8卫星数据来源于GEE平台(https:∥earthengine.google.com)的陆地卫星地表反射率数据(USGS Landsat 8 Surface Reflectance Tier 1),空间分辨率为30 m,时间分辨率为16 d。该数据已进行过大气校正,消除了大气和光照等因素所造成的辐射误差。
黄土高原主要的覆膜作物为春玉米和马铃薯,一般于4月下旬至5月上旬播种[23-24]。在5月上中旬时,冬小麦正处于拔节抽穗期,夏玉米还未种植,春玉米和马铃薯刚刚播种,此时地膜受作物叶片的干扰程度小,容易获取光谱信息。因此,5月上中旬是解译研究区地膜覆盖范围的最佳时相。首先利用时间和空间的过滤函数获取团结镇上空2018年5月11日的Landsat-8影像,轨道号为130/035;然后对该影像进行去云处理,以减少云层遮挡的影响;最后使用团结镇的矢量图进行影像裁剪。
1.2.2地面样本数据
团结镇内的地物类型主要包含白色地膜、黑色地膜、植被覆盖、裸露农田、水体和不透水层(包括建筑、道路、山体、废弃用地等)共6种土地覆盖类型。基于地球大数据科学工程数据共享服务系统(http:∥data.casearth.cn/)提供的全球分辨率30 m精细地表覆盖数据和Google Earth高分辨率影像,采集了团结镇6种不同土地覆盖类型共计648个矩形样本,样本尺寸为2像素×2像素,并在GEE平台中随机分为训练数据和验证数据两类,两类数据的数量基本一致(表1)。
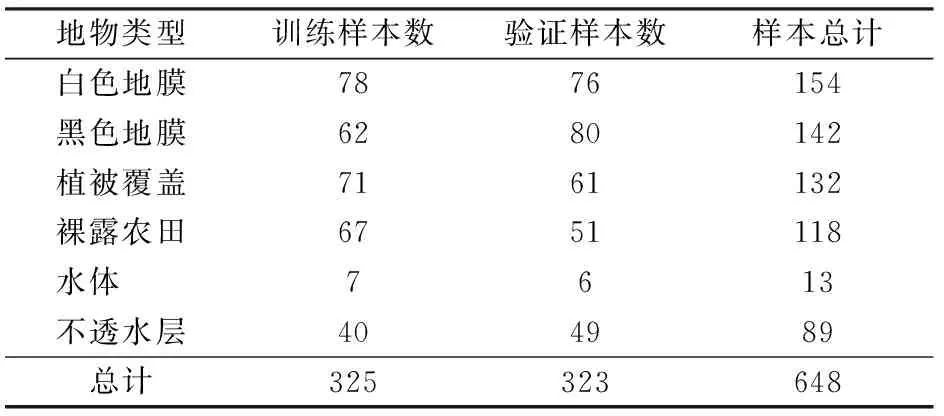
表1 研究区地物分类体系及样本数量Tab.1 Classification scheme and sample number of surface features in study area
1.3 基于GEE平台的覆膜农田识别
1.3.1基于GEE平台的覆膜农田识别框架
基于GEE平台提取团结镇覆膜农田区域的具体步骤(图2)为:①对获取的Landsat-8影像数据进行预处理,并提取影像的光谱特征、指数特征和纹理特征。②使用提取的遥感识别特征和训练数据选取随机森林(Random forest,RF)算法的关键参数。③利用参数优化后的RF算法进行纹理特征重要性分析,获得优选纹理特征。④基于提取的遥感识别特征和优选纹理特征制定6种不同的分类方案,利用参数优化后的RF算法进行不同方案下的地物分类并从中提取出覆膜农田区域,通过混淆矩阵方法和验证数据对分类结果进行精度评价,确定最佳分类方案。⑤使用最佳分类方案和同一地面样本数据分别利用支持向量机(Support vector machines,SVM)、决策树(Decision tree,DT)和最小距离分类(Minimum distance classifier,MDC)算法进行地物分类,并进行精度验证,通过与RF分类精度进行比较和McNemar’s检验,评价RF算法的分类性能。

图2 基于GEE平台提取研究区覆膜农田区域的技术流程图Fig.2 Technical flowchart of extraction of plastic-film-mulched farmland based on Google Earth Engine platform in study area
1.3.2遥感识别特征构建
本研究基于Landsat-8地表反射率数据提取了光谱、指数和纹理3组特征进行地膜识别。其中,光谱特征包括遥感影像可见光、近红外和短波红外7个波段的反射率数据。指数特征包括归一化植被指数[25]、归一化水体指数[26]和归一化建筑指数[27]。纹理特征选用灰度共生矩阵(Gray level co-occurrence matrix,GLCM)来提取。GLCM是由HARACLICK等[28]提出的通过计算影像灰度级之间联合条件概率密度来提取纹理特征的一种统计学方法。GEE平台提供了基于GLCM快速计算纹理特征的函数,可在短时间内同时导出18种不同纹理特征。若将18种纹理测度全部用于机器学习分类必然会产生冗余,因此本研究选取最为常见的和平均、方差、对比度、异质性、逆差矩、熵、角二阶矩和相关性8种纹理指标来区分不同地物类型的空间结构差异。由于光谱特征中考虑了影像的7个波段,因此选用的纹理特征共包含56(8×7)个波段信息。最终共提取了66个光谱特征、指数特征以及纹理特征,其中纹理特征占全部遥感特征的80%以上。
为了进一步提高覆膜农田的识别精度和算法运行效率,研究利用RF算法对56个纹理特征进行重要性分析,然后按照重要性排序,逐一添加纹理特征开展覆膜农田识别工作,最后通过评价分类的生产者精度、用户精度、总体精度和平均精度(白膜和黑膜的生产者精度与用户精度的平均值)来选取最优纹理特征组合,从而实现基于最优特征集下的覆膜农田识别。
1.3.3随机森林关键参数对分类结果的影响
RF算法在一定程度上可以避免过拟合[29-31],对噪声和异常值有较好的容忍性,表现出很多普通机器学习算法未有的独特优势[30,32]。
RF算法可在GEE平台上实现,且在构建RF算法时仅需对两个最为关键的参数进行优化,即决策树数量T和节点分裂特征个数M,其他参数保持默认值。一般地,增加决策树数量T可有效减小算法的泛化误差,但同时降低计算效率;节点分裂特征个数M是单棵决策树分类性能的决定性因素,并对树之间的相关性产生影响[33]。
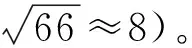
1.3.4团结镇覆膜农田的识别
为了评价不同特征组合在覆膜农田识别中的表现,本研究制定了6组不同的分类方案,具体为:光谱特征(方案S);指数特征(方案I);优选纹理特征(方案T1);光谱+指数特征(方案S+I);光谱+指数+优选纹理特征(方案S+I+T1);光谱+指数+全部纹理特征(方案S+I+T2)。利用参数优化后的RF算法和325个训练数据进行不同特征组合下的地物分类,并从分类结果中提取出覆膜农田区域,对比分析不同分类方案的分类精度,从而选取最佳分类方案。
为了进一步比较不同分类算法在覆膜农田识别中的有效性,本研究基于最佳分类方案,使用同一训练和验证样本,分别采用SVM、DT和MDC算法提取覆膜农田区域,依据分类精度和McNemar’s检验结果与RF算法提取结果作对比分析,从而评价不同算法的分类性能。SVM算法是以统计学为理论基础,以结构风险最小化为原则的机器学习方法[34],核函数是影响其分类性能的决定性因素之一,本研究选用线性核函数进行分类,该核函数已被证明在覆膜农田识别中效果最佳[13]。DT算法是一种依据分割阈值对遥感影像的像元进行归类的非参数监督分类方法[35],包括ID3、C4.5和CART共3种常见类型,本研究选用其中的CART算法执行地物分类。MDC算法是通过计算未知类别向量与训练样本向量中心点的距离,将非样本像元归类到距离最短类别中的分类方法[36],本研究采用欧氏距离计算距离。
1.3.5识别精度验证
采用混淆矩阵法对分类结果进行精度评价,包括生产者精度(Producer accuracy,PA)、用户精度(User accuracy,UA)、总体精度(Overall accuracy,OA)和Kappa系数4个评价指标[37-38]。
此外,利用McNemar’s检验来检测不同算法间分类精度的差异,该检验是基于两个算法的混淆矩阵而计算的非参数检验,以Z值来评判算法间差异的显著性[39]。现有研究表明,若|Z|>1.96,则表明在0.05检验水平下两种算法间的分类精度差异性显著。
2 结果与分析
2.1 随机森林关键参数对分类结果的影响
决策树数量T和节点分裂特征个数M对RF算法的袋外误差均有明显的影响(图3)。随着T的增大,袋外误差开始降低,尤其是当T<100时,此时因还未形成“森林”,袋外误差明显降低;当T≥100时,袋外误差趋于稳定。节点分裂特征个数M的增加也可以有效降低袋外误差,但相比参数T的影响较小,且参数M对算法的作用也与T的取值有关。当T<100时,M的增加能够引起袋外误差大幅度降低,而当T>100时,M的变化对袋外误差的影响不明显。当M<6时,袋外误差降低相对明显;在M≥6时误差变化幅度很小,尤其在T≥100后基本趋于稳定。因此,兼顾RF算法的稳定、精度与效率,本研究选取T=600、M=8(即默认值)作为RF算法的输入参数用于下一步最优特征子集的筛选。

图3 随机森林算法中决策树数量T和节点分裂特征个数M与袋外误差的关系Fig.3 Relationships between number of trees (T) or variables per split (M) and error of out-of-bag dataset in random forest algorithm
2.2 最优纹理特征组合的选取
白膜覆盖农田识别的生产者精度和用户精度波动较小,且随纹理特征数量的增加均呈缓慢上升趋势,在特征数量达到12时,两种精度趋于平稳并保持在90%以上(图4a)。黑膜覆盖农田识别的生产者精度和用户精度的变化幅度较大,当特征数量小于4时,生产者精度直线增长,随后转变为小区间内浮动,精度保持在85%以上;而用户精度则在特征数量增加到2时,由53.13%直接上升到82.35%,随后保持在85%上下波动(图4b)。特征数量小于10时,总体精度呈现整体上升趋势,之后随着特征数量的增加而逐渐趋于平缓,在特征数量为14和15时达到较大值,其值依次为87.93%和87.62%(图4c)。根据平均精度,即白膜和黑膜的生产者精度与用户精度的平均值(图4d),可知该值在特征数量为15、23和36时较高,分别为90.66%、90.79%和90.86%。

图4 不同纹理特征数量与识别精度之间的关系曲线Fig.4 Relationships between number of textural features and recognition accuracy
总体而言,本研究的RF算法运行过程中,使用的特征数量越多,则运算时间越长,工作效率越低,而通过重要性分析和精度评价筛选特征,将贡献度和重要性较小的变量予以剔除,进而以较少的特征变量来确保较高的分类精度,降低变量维度。因此,本研究确定前15个纹理特征作为最优纹理特征组合。
2.3 不同特征组合下随机森林覆膜农田识别结果
根据不同特征组合下随机森林地物分类结果的空间分布(图5),可以看出方案I(图5b)与方案S+I(图5d)的分类结果中不透水层的分布范围大于其他方法,并且已经超出了Google Earth高分辨率影像中目视解译的不透水层范围,存在一定程度的不合理性。方案T1(图5c)获取的分类结果中农田区域约占研究区的1/2,这与统计数据(约2/5)不相符,因此仅依靠优选纹理特征的识别结果也不可靠。而方案S(图5a)、方案S+I+T1(图5e)以及方案S+I+T2(图5f)得到的分类结果中各类地物的空间分布较为合理,也与Google Earth高分辨率影像大致相符。

图5 基于随机森林算法和不同特征组合下的研究区地物分类结果Fig.5 Classification results of land covers in study area based on random forest algorithm and different feature combinations
根据不同分类方案下随机森林覆膜农田识别结果的空间分布(图6),可以看出覆膜农田集中分布在研究区的北部和西南部,在中部、东部较为分散。在对Google Earth高分辨率影像进行目视解译的过程中发现,研究区存在大量白色地膜覆盖区域,且主要集中在西部地区。然而方案S(图6a)与方案S+I(图6d)获取的覆膜农田分布范围较小且分散,方案I(图6b)得到的覆膜农田分布中白膜和黑膜分布范围差异较大,同时白色地膜分布信息缺失较多,因此均存在严重的错分漏分现象。方案T1(图6c)、方案S+I+T1(图6e)以及方案S+I+T2(图6f)得到的分类结果差异不明显,提取的覆膜农田结构均较为明显,空间分布基本符合目视解译的结果,错分漏分现象较轻。

图6 基于随机森林算法和不同特征组合下的研究区覆膜农田空间分布Fig.6 Spatial distributions of plastic-film-mulched farmlands in study area based on random forest algorithm and different feature combinations
对研究区内随机选中区域在不同方案下的分类结果的细节进行对比分析(图7),可见与对应的Google Earth实景影像和Landsat-8 OLI标准真彩色合成影像相比,6种方案的分类结果在像元上均存在不同程度的误差。其中,方案S(图7c)、方案S+I(图7f)和方案S+I+T1(图7g)的分类结果与实际情况吻合程度相对较高,像元误差相对较小。

图7 研究区某一随机覆膜农田区域在不同特征组合下的分类结果对比Fig.7 Comparisons of classification results of plastic-film-mulched farmlands at random site in study area based on different feature combinations
2.4 不同特征组合下随机森林分类精度对比
根据混淆矩阵计算的不同特征组合下的地物分类精度(表2),可知6种不同特征组合下地物分类的总体精度均超过80%。其中方案S、方案I和方案T1这3种单一特征方法的总体精度分别为92.57%、80.50%和87.62%,Kappa系数分别为0.91、0.76和0.84,表明光谱特征在影像分类过程中发挥着重要作用。与方案S相比,方案S+I中添加指数特征可有效提升分类精度,总体精度和Kappa系数分别提高1.24个百分点、0.01。此外,在“光谱+指数”特征的基础上加入纹理特征也可改善分类精度,与方案S+I相比,方案S+I+T1和方案S+I+T2的总体精度分别提高了1.24、0.62个百分点,Kappa系数分别增加了0.02和0.01。单从覆膜农田的分类精度上来看,无论是生产者精度还是用户精度,白膜都远高于黑膜,表明白膜的可分离性优于黑膜。对不同特征组合下白膜的分类精度进行分析,可知方案S、方案S+I以及方案S+I+T1的生产者精度最高为98.68%;而用户精度在方案S+I+T1时达到最大值97.40%。同样分析黑膜的分类精度,发现方案S+I+T1下生产者精度最高为92.50%,方案S的用户精度最高为95.83%。综合考虑分类性能和工作效率,确定本研究的最佳分类方案为S+I+T1,即光谱+指数+优选纹理特征。

表2 基于不同特征组合和随机森林算法的研究区地物分类精度Tab.2 Classification accuracies of land covers based on different feature combinations and random forest algorithm in study area
2.5 不同机器学习算法对覆膜农田识别精度的影响
在特征组合S+I+T1下,与RF算法(图8a)相比,SVM(图8b)、DT(图8c)和MDC(图8d)算法的分类结果差异明显,尤其是DT和MDC算法提取的覆膜农田没有从整体上呈现出其空间分布特征。进一步对比不同算法的分类精度(表3),可知RF算法精度明显高于SVM、DT和MDC算法,总体精度分别高3.10、7.74、50.78个百分点,Kappa系数分别高0.04、0.10和0.62。由于RF、SVM和DT均为非参数监督分类方法,只有MDC属于参数监督分类方法,这表明非参数监督方法相比参数监督方法更适合用于地貌复杂地区的地物分类。单从覆膜农田的分类精度来看,在RF算法下,白膜的生产者精度和用户精度达到最大值,分别为98.68%和97.40%;黑膜的生产者精度和用户精度也达到最大值,分别为92.50%和91.36%。
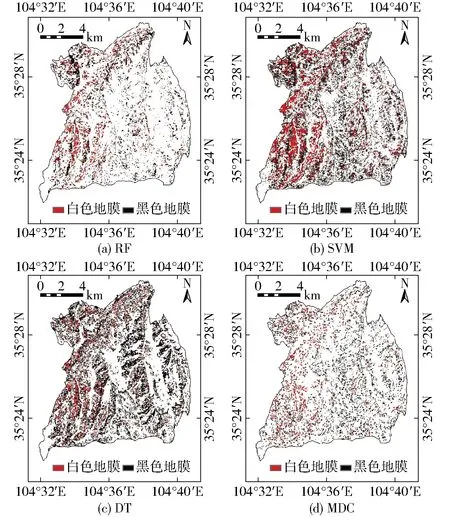
图8 方案S+I+T1下基于不同机器学习算法的研究区覆膜农田空间分布Fig.8 Spatial distributions of plastic-film-mulched farmlands based on scheme S+I+T1 and different classification algorithms in study area

表3 方案S+I+T1下基于不同机器学习算法的研究区地物分类精度比较Tab.3 Classification accuracies based on different classification algorithms of scheme S+I+T1 in study area
此外,根据RF、SVM、DT和MDC算法分类结果的McNemar’s检验,可知RF算法与SVM、DT、MDC算法之间的Z值分别为2.89、5.00和12.88,结果均大于1.96,表明在0.05检验水平下RF算法与SVM、DT、MDC算法的分类精度差异性显著。综上可知,4种机器学习算法中RF算法在地物分类和覆膜农田识别上优势明显,能够有效地提高识别精度和工作效率。
3 讨论
本研究提出了基于GEE平台快速提取覆膜农田的方法,获得了甘肃省定西市安定区团结镇的覆膜农田空间分布情况,识别精度和效率比已有相关研究有所提升。LU等[40]基于Landsat系列数据开展新疆地区的覆膜农田识别工作,总体精度和Kappa系数分别达到97.82%和0.97,由于新疆地区覆膜农田几乎呈连片分布状,在一定程度上降低了工作难度。哈斯图亚[41]选择了同样位于黄土高原的宁夏固原地区作为研究区进行覆膜农田提取,总体精度和Kappa系数为90.67%和0.87。本文地物分类的总体精度和Kappa系数分别为95.05%和0.94,实现了地膜分布相对破碎地区的精准识别,可为地貌复杂地区应用农业遥感技术提供参考。此外,研究同时考虑了白膜和黑膜覆盖农田,并成功对其分别进行提取,这也弥补了XIONG等[42]在其研究结果分析中提出的未考虑研究区中的黑膜而导致精度降低这一缺陷。
目前大多数研究对于随机森林算法关键参数的选取多参考经验值,如哈斯图亚[41]、张鹏等[43]根据经验将决策树数量T设为500、节点分裂特征个数M取输入特征数的平方根;侯蒙京等[44]参考大量研究将参数T设为1 000、参数M保持默认,这在一定程度上限制了RF算法高精度优势的发挥。本研究首先根据参数T和M的经验值确定了它们的取值范围,然后遍历所有参数组合来执行RF算法分类,最终选择运算效率可接受范围内使袋外误差最低的参数值,作为下一步研究中RF算法的输入参数。结果表明,在利用RF算法进行影像分类时,参数T和M均对袋外误差有明显影响,且参数T的影响大于参数M。当参数M一定时,并非参数T越大,袋外误差就越小,因此通过不断提高参数T的值来降低袋外误差往往是无法实现的。这与RODRIGUEZ-GALIANO等[32]的研究结果相近。本研究中,参数T取600、参数M保持默认值的组合可在运算效率承受范围内使袋外误差最低。这表明RF算法关键参数的优化是提高覆膜农田识别精度的有效途径。
遥感识别特征决定了各类地物之间的相似性和差异性,是判读识别各类地物的依据。本研究基于RF算法对纹理特征进行重要性分析,按照重要性排序逐一添加纹理特征并进行分类精度验证,确定前15个特征为优选纹理特征,并结合光谱和指数特征制定了6套方案进行覆膜农田识别。结果表明,基于“光谱+指数+优选纹理”特征的总体精度和Kappa系数最高,分别为95.05%和0.94。这与朱秀芳等[45]的研究结果相近,该研究认为纹理特征越多并不代表分类精度越高,分类前进行特征优选是必要工作。然而该研究仅依靠优选纹理特征进行分类,总体精度和Kappa系数分别为94.84%和0.89,并提出可通过增加指数特征来改善分类精度。本研究针对其提出的不足之处加以改进,明显提高了覆膜农田的识别精度。
作为目前机器学习领域的研究热点,随机森林被广泛应用于地物分类研究中。本研究基于“光谱+指数+优选纹理”特征评价不同算法的分类性能时发现,无论是从生产者精度、用户精度、总体精度和Kappa系数还是McNemar’s检验结果来看,随机森林算法均显著优于其他算法,这与哈斯图亚[41]、侯蒙京等[44]的研究结果相符。沙先丽[12]基于Landsat系列数据,利用决策树模型和多特征结合方法提取新疆地区的覆膜农田信息,但是在研究区地膜覆盖连片、地物特征明显的前提下分类的总体精度和Kappa系数仅为91.35%和0.89。究其原因,在所用数据和特征子集相同的情况下,关键因素可能在于所采用的算法。这也再次印证了随机森林算法在覆膜农田识别中的有效性。
本研究主要考虑的是春玉米、马铃薯等春播作物地膜覆盖种植区域的单一时相识别,尽管其种植面积占全年覆膜农田面积的90%左右,但仍然缺失其他季节的覆膜农田信息。在其他季节,研究区主要的覆膜作物为蔬菜,而蔬菜的播种时间几乎取决于农户本身,不确定因素很多,因此对覆膜蔬菜种植区域进行提取难度较大,有待后续进一步深入研究。此外,本研究仅考虑了基于像元的遥感影像分类方法,而裴欢等[46]的研究表明面向对象分类方法为土地利用/覆盖信息提取提供了新的有效途径,该方法在覆膜农田识别中的应用潜力还需要进一步深入探讨。
4 结论
(1)确定随机森林算法关键参数的最佳取值能够大幅提高遥感影像的分类精度。在非关键参数保持默认的条件下,在一定阈值范围内存在决策树数量T和节点分裂特征个数M的最佳参数组合,能够在运算效率可承受范围内使袋外误差最小。因此,在利用随机森林算法实现影像分类之前,对其关键参数进行了优化,以获取更为可靠的分类结果。
(2)基于优选纹理特征的分类性能优于基于全部纹理特征的分类,且相比其他方案,基于“光谱+指数+优选纹理”特征的识别结果最佳。基于“光谱+指数+优选纹理”特征分类的总体精度达95.05%,比基于单一特征方案的总体精度高2.48~14.55个百分点,同时也比“光谱+指数”特征、“光谱+指数+全部纹理”特征方案分别高1.24、0.62个百分点。因此,在实际应用中建议采用优选纹理特征和多特征相结合的方法进行覆膜农田识别。
(3)随机森林算法的总体精度比支持向量机、决策树和最小距离分类算法分别高3.10、7.74、50.78个百分点。结合McNemar’s检验结果,随机森林算法与其它3种算法间的Z值分别为2.89、5.00和12.88,表明随机森林算法与其它算法间的分类精度存在显著性差异。因此,随机森林算法是较适于覆膜农田识别的方法。
