基于智能电表数据的家庭特征联合预测算法
2022-02-19马红明申洪涛孙勇强韩永禄罗茜文
马红明 申洪涛 孙勇强 韩永禄 罗茜文 潘 阳
(国网河北省电力有限公司电力科学研究院 河北 石家庄 050000)
0 引 言
能源供应商对单个家庭经济特征(如性别、年龄和婚姻状况等)的解析有助于其根据具体家庭情况自动调整用能建议,并提供更优质的服务,从而吸引更多新客户,保留原有客户。但是一般而言,住户特征信息不易获取,往往需要通过传输器进行人工采集。因此如何从智能电表数据中推断出家庭特征是至关重要的。
通过智能电表数据预测家庭特征的研究主要可以分为无监督学习方法和监督学习方法。对于无监督学习方法[1-2],应用模糊聚类[3-4]和自组织方法[5]来识别具有可重复负荷轨迹的家庭。具体而言,采用模糊建模方法,目的是获得比经典回归模型精度更高的透明可解释模型,自组织映射[5]可以使用具体的建筑信息创建对比客户群。然而,这些方法需要合理化获取模式,并且不易推导出家庭特征。因此,到目前为止,还没有在实际环境中应用这些方法。对于监督学习方法,文献[6]基于预先定义的特征从30 min智能电表数据中推断出家庭特征,对所有家庭中的分类精度能达到70%以上。然而,这些方法只为每个特征建立独立的分类器,忽略了特征之间的关系。由此本文着重研究如何将多任务学习进行应用,旨在通过对不同特征进行联合分析提高泛化性能。
大多数最新的多任务学习模型都试图探索不同任务之间的关系或选择共享的特征。根据如何同时从训练数据中学习模型参数,多任务学习模型可以大致分为任务学习和共享特征选择。对于任务学习[7-8],多层前馈神经网络[9]是多任务学习的最早尝试。在多层前向神经网络中,从训练任务中学习到的共同特征被表示在隐藏层中,输出层中的每个单元通常可以看作是一个任务的输出。然而,在许多实际应用中,这种强迫预测值在不相关的任务之间共享的假设可能会被违背,并显著降低性能。为了避免危及上述假设的风险,文献[10-12]提出了基于聚类的假设方法。其主要思想是将所有观测到的任务分为若干个簇,然后簇内任务的参数要么在某些距离度量中彼此接近,要么共享一个概率先验。该方法的优点是它对离群/不相关任务的鲁棒性高。然而,这些方法可能无法利用负相关任务。
对于共享特征选择,研究者们探索了通过正则化项,用于利用任务之间共享的公共特性,但在上述处理后,依旧具有局限性:① 在不考虑任务相关性的情况下为所有任务选择特征子集;② 无法揭示相关任务解的相似程度。为了缓解现有方法中存在的问题,将特征结构信息融入到任务关系中,本文采用两个协方差矩阵分别对不同任务和判别特征之间的关系进行建模,建立更具鲁棒性的模型。
综上所述,本文设计了一个MTLClass系统来同时预测各种特征,并提出了一种多任务学习模式—区分性多任务关系学习(Discriminative multi-task relationship learning,DISMTRL),在学习区分性特征的同时,通过捕捉不同特征之间的关系来预测家庭特征。具体而言,对于特征关系,本文假设在这个预测问题中存在三种类型的任务关系(即正相关、负相关和不相关),并且以任务协方差矩阵的形式捕获任务关系,而不是基于先验信息或启发式的经验预先确定。同时,学习了一组既可利用预测器又互不独立的判别特征,并用特征协方差矩阵对任务间的共享特征进行建模。此外,为了对这些模型进行建模,本文通过分别在行和列上假设不同的高斯分布,自适应地从训练数据集中学习权重矩阵。在将所提出的DISMTRL转换为等价的凸优化问题后,采用交替优化方法求解该凸问题,并对每个子问题进行近似算子。最终通过将模型应用到爱尔兰采集的智能电表数据集中,证明了所提算法的有效性和鲁棒性。
1 基于多任务学习的特征预测
假设对于m个分类任务,本文采用常用的最小二乘损失函数,研究以下线性模型:
(1)
式中:fl是第l个学习任务的预测因子;wl是第l个任务的相应权重向量。所有m个任务的权重向量构成权重矩阵W=[w1,w2,…,wm]。此外,多任务学习的目标公式可以概括为:
(2)
式中:第一项是训练数据的经验误差;第二项R(W)是正则化项,可以用来缩小模型的复杂度。
(3)
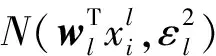
(4)
假设数据{X,Y}独立于式(4)中的分布,似然函数可以写成:
(5)
这里首先对W的不同列(特征)之间的关系进行建模。为了建立这种内在几何结构的模型,可以自然地期望如果内在两个特征i和j是紧密的,那么它们相应的表示系数wi和wj也应该是紧密的,并且诱导正的任务相关性。另一方面,两个不同的特征更可能是负相关。因此,我们在下面的W的列上加上一个先验。由于W是一个矩阵变量,所以用矩阵变量分布来建模。利用加权矩阵W1的结构,矩阵正态分布假设dm×dm可以分解为kronecker积:
vec(W1)~N(vec(M1),Id⊗Ω)
(6)
式中:M1是包含W1的每个元素的期望矩阵;Id是恒等式矩阵。列协方差矩阵Ω构建了不同任务之间的关系,而Id建模的特征是独立的。同时,我们为特征设计了一个正则化项,假设两个特征相互关联时,它们相应的权重系数(wi和wj)应具有相同或相似的模式,反之亦然。类似地,我们通过在W2上扩展以下高斯分布来分析W2中的行之间的关系:
vec(W2)~N(vec(M2),Σ⊗Im)
(7)
式中:行协方差矩阵Σ学习W2的不同行之间的关系(即判别特征);Im是恒等式矩阵。因此,本文中W的积分先验表示过程如下。
推论1假设W1和W2的对应先验为式(6)和式(7),则本文中W的先验可被投射为W1和W2的高斯密度的乘积:
vec(W)~N(vec(M1),Id⊗Ω)·N(vec(M2),Σ⊗Im)=
Con·N(vec(M),Σ*)
其中:
Con=Nvec(M1)(vec(M2),(Id⊗Ω+Σ⊗Im))=
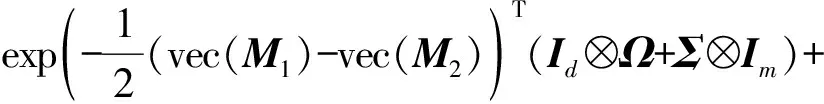
(vec(M1)-vec(M2)))
vec(M)=((Id⊗Ω)++(Σ⊗Im)+)+·
((Id⊗Ω)+vec(M1)+(Σ⊗Im)+vec(M2))
Σ*=((Id⊗Ω)++(Σ⊗Im)+)+
W的最大后验估计如下:
p(W|X,Y,ε2,M,Σ*)∝p(Y|W,X,ε2)p(W|M,Σ*)
(8)
结合式(5)和推论1,可以通过最小化得到W的解:
tr((W-M)T((Id⊗Ω)++(Σ⊗Im)+)(W-M))+
(9)
式中:tr(·)为矩阵的跟踪函数。为了推导出一个简单的模型,令M=M1=M2=0d×m,(ε)2=(εl)2,l=1,2,…,m。在忽略式(9)中的常数项后,可以进一步得到下式:
tr(WΩ+WT)+dm(log|Ω|+log|Σ|)
(10)
最后一项是Σ和Ω的复杂度惩罚。但是最后一项是凹函数。本文做了一个简单的假设,即Ω和Σ的迹线边界。这种假设在本质上与低阶约束(例如跟踪范数惩罚)的假设相似,其将使我们能够在实现过程中运用凸优化学习方法。
此外,在式(10)中用约束tr(Ω)≤k1和tr(Σ)≤k2来代替其最后一个项,以限制其复杂性,由此式(10)可以被重新表述如下:
s.t.Ω≥0,tr(Ω)≤k1,Σ≥0,tr(Σ)≤k2
(11)
尽管在式(11)中对权重矩阵W行和列之间的关系进行了建模,但分类问题可能会受到许多参数的影响。因此将目标矩阵W进行分解:
W=UA
(12)
式中:U∈Od,每列表示W的相应特征。可以进一步替换最小化问题:
(13)
由此可以得到以下定理:
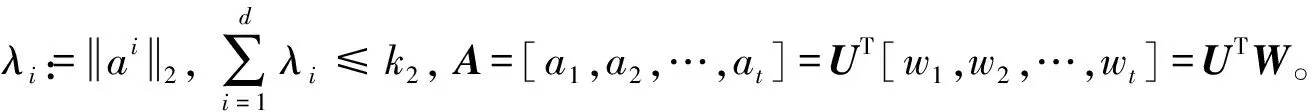

s.t.U∈Od,Ω≥0,tr(Ω)≤k1
(14)
式(14)中的模型保持了W和Ω的凸性,可以采用交替策略来进行求解。
2 模型优化
由于式(14)中存在约束UTU=I,Ω≥0,DisMTRL的目标函数和约束对于所有变量都是凸的。因此,在不同时刻优化三个变量的情况下,可以保证得到全局最优解。在此采用一种有效的方法迭代求解式(14)的W和Ω。
2.1 W和U固定,优化w.r.t.Ω
对于固定的W和U,Ω是此子问题中的变量。优化函数可以写为:
(15)
然后,使用柯西-施瓦兹不等式得到Ω的解如下:
(16)
式中:θ是一个相对较小的正参数,本文将其定义为10-6。
2.2 Ω固定,优化w.r.t.W和U
该种情况下,优化函数可以简化为:
s.t.U∈Od
(17)
最小化问题可以表述为:
(18)
二元极小化问题可以转化为一元极小化问题:
(19)
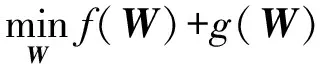
(20)
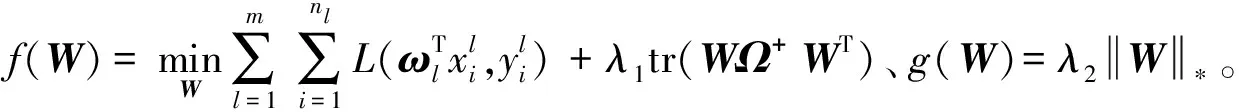
(21)
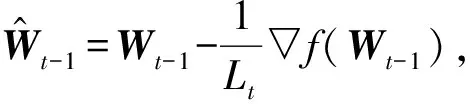
3 算例分析
本节针对具有代表性的单任务学习模型和多任务学习模型进行了实证比较。然后基于CER(Commission for Energy Regulation)3数据集进行实验。
3.1 算法比较与分析
实验中在两个单任务学习模型上评估了所提出的DisMTRL模型。算法中,当连续两次迭代中损失函数值的变化小于10-5或迭代次数大于105时,模型计算将终止。此外,对于分类问题,采用四个不同层次的标准进行评价:Aver_AUC、Micro_F1、Macro_F1以及ACC(accuracy)。上述参数的值越大,对应模型的分类性能越好。
3.2 智能电表数据
算例采用CER数据集以及客户调查数据训练和测试所提出的DISMTRL模型,同时向用户发放问卷进行调查。具体而言,电表数据集包括从4 232户家庭收集的,自2009年7月至2010年12月以30分钟为时间步长的用电量测量数据(总共75周)。问卷中的问题主要关于住户的特征(例如经济状况、家电概况、消费行为和财产)。应用目的是考察本文算法用于预测消费回馈对家庭用电量的影响的有效性。
本文分析了75周内第2周至第5周的平均用电量,因为调查数据早于CER数据集,而且更早的CER数据集通常更有说服力,足以准确反映家庭特征。此外,如果从调查数据中无法发现一个家庭的一个特征值,则该家庭不参与该特征分类问题的培训和测试。
(1) MTLCLASS系统的设计:本系统以多任务监督学习模型DISMTRL为基础,从家庭用电量数据中预测家庭特征。图1演示了所提出的特征估计过程的主要组成。

图1 模型应用图
(2) 特征定义:从4周的CER数据集中,我们定义了81个特征如表1所示。其中25个特征定义与文献[6]一致。本文还添加了56个功能,考虑到工作日和周末的用电量数据之间的关系。本文使用功能的主要类别包括每日消费(例如,一天中不同时间和不同日期的平均或最大消费)、比率(例如,白天或夜间比率,以及不同日期之间的比率)、统计类(例如,工作日和周末的差异,自相关和其他统计数字)和不同时间类(如用电量水平、重要时刻、峰值和时间序列分析值)。在提取之后,通过三种常见的数据变换(平方根变换、对数变换和逆变换)对每个均值和单位方差为零的特征进行归一化。由于式(4)中每个基于高斯分布的分类器都需要数据归一化。更具体地说,图2分别给出了特征con_week和r_min/mean的平方根变换的标准分位数图。分位数图的线性意味着变换后的特征得到了很好的归一化。
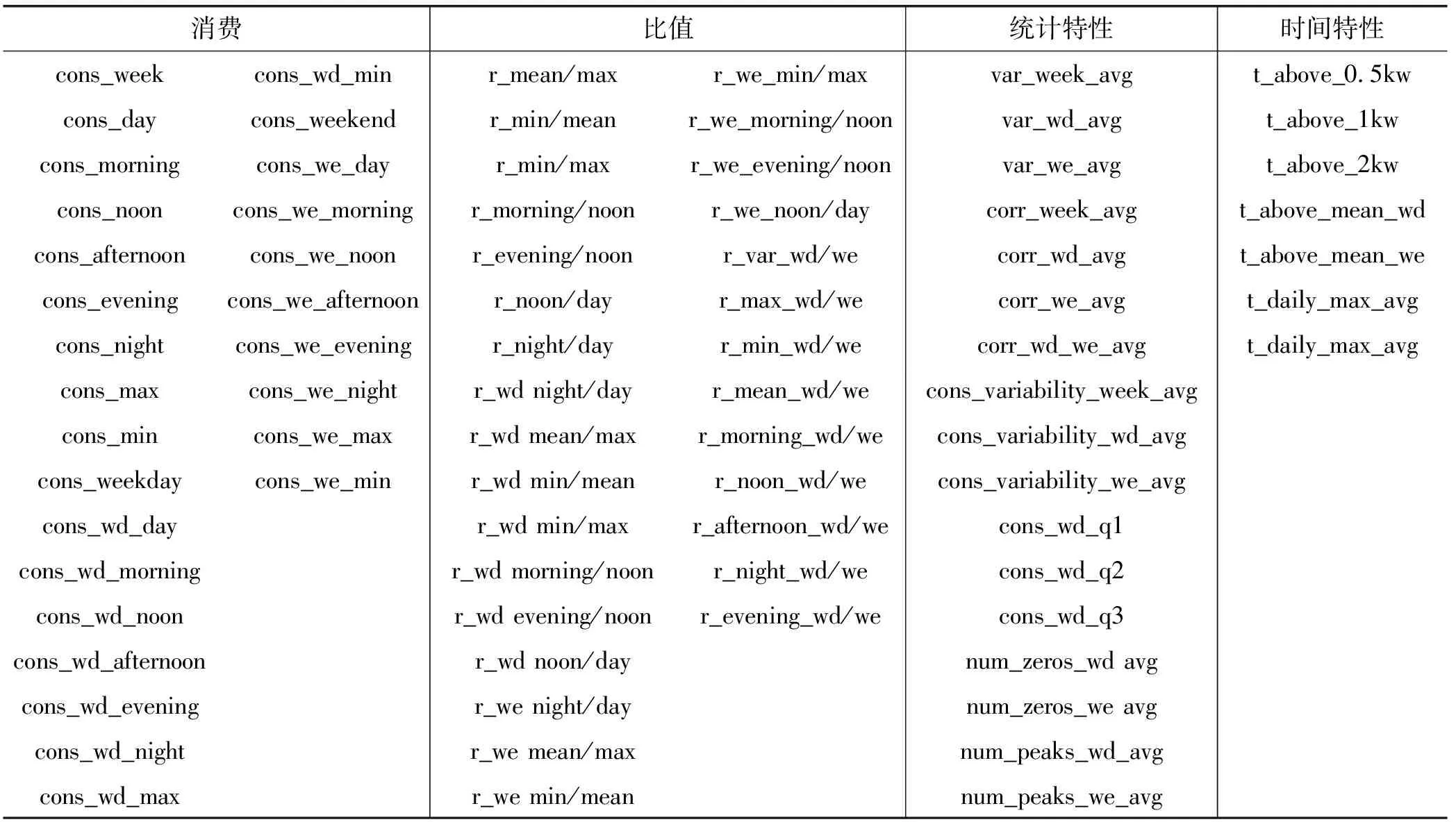
表1 已定义特征列表
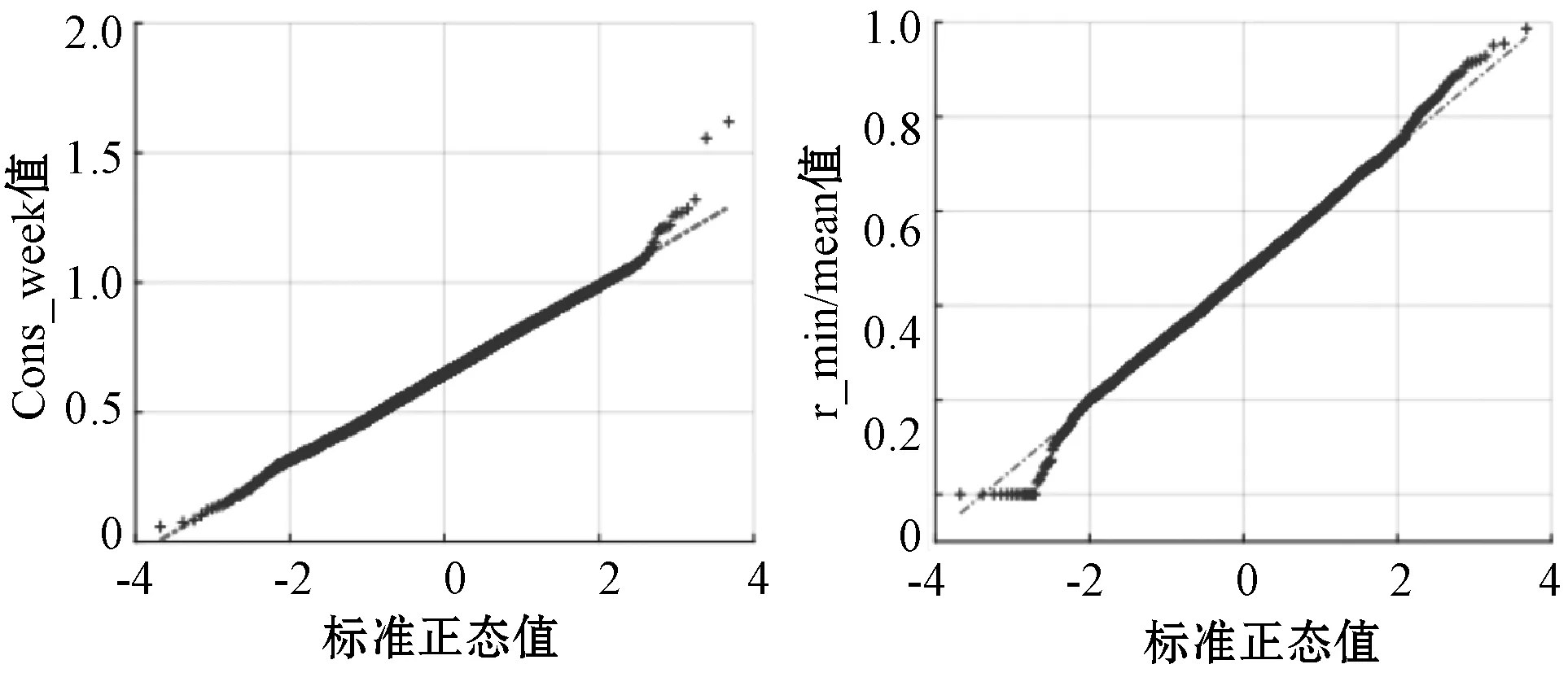
图2 特征con_week和r_min/mean分位数图
(3) 家庭特征:本文提取了16个特征,主要分为三类:社会经济地位(如儿童、就业、社会阶层等)、住房状况(如老年人住房、建筑面积等)和用电情况(如电视、电灯情况等)。
本文研究主要考虑二值分类问题。因为学习多个标签一致的任务是MTL设置中常见的场景。此外,在一些特征(如烹饪、就业和家庭等)中采用了与文献[6]相同的二价定义。对于其他特征,通过调整类标签的数量来重新定义房屋面积的标签,从而使每个类包含相似数量的住户。进一步,选择年龄、设备的类标签,测试不同阈值对分类结果的影响,并与参考文献结果进行比较。表2给出了原始测量数据的有偏随机猜测和KNN、具有文献[6]特征的KNN、含重新定义特征的KNN的性能。注意,重新定义后,这三个特征的分类准确率更高。可见本文验选择了正确的阈值。
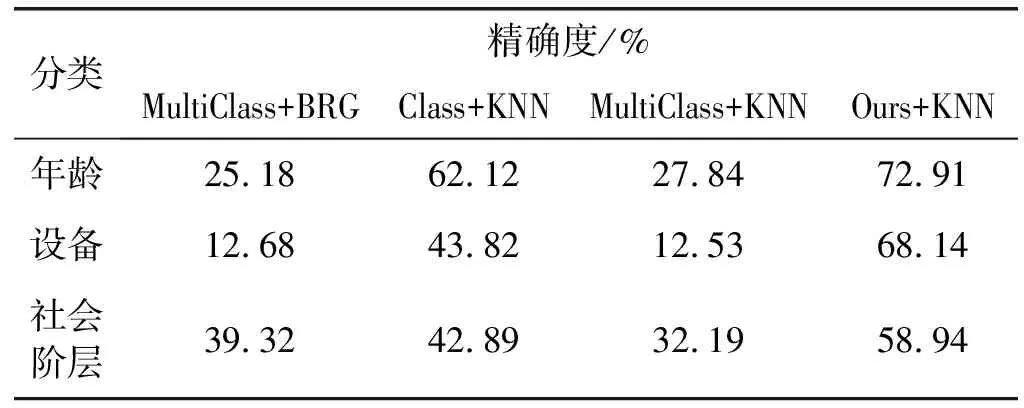
表2 四种分类策略的性能比较
在实验中,随机抽取10%、20%和30%的样本(每个特征)组成训练集,其余样本作为测试集。表3中给出了10个随机性能的平均实验结果。在训练集为10%的情况下,图3给出每个特征的准确度。
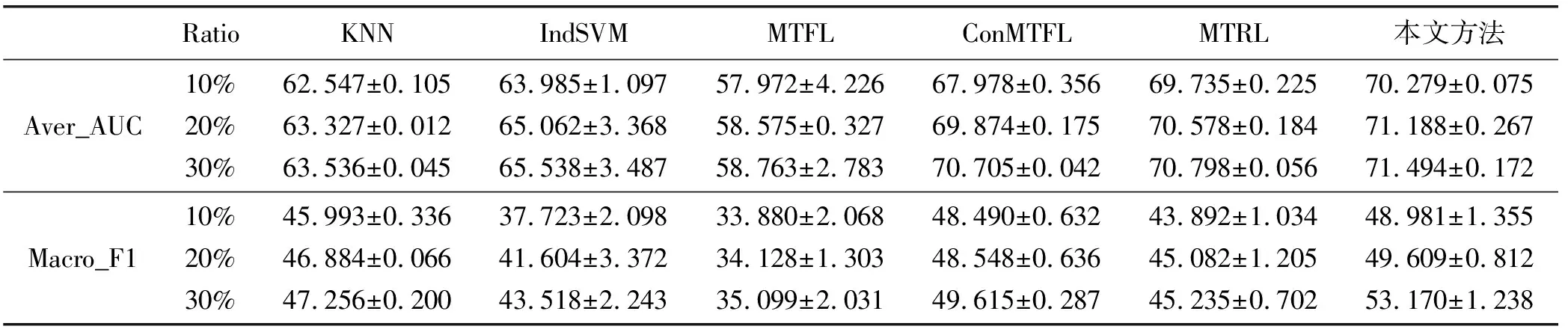
表3 算法性能对比

续表3
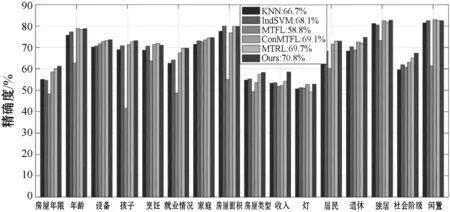
图3 六种监督学习算法的性能对比(训练率10%)
由表3可见,所提出的DISMTRL模型在本实验的竞争算法中(如MTFL和MTRL)取得了最好的性能。这为我们从多特征中同时学习任务关系和判别特征来提高泛化性能提供了有力的支撑。除了图3中的MTFL外,本实验中的多任务学习模型优于KNN和INDSVM,这也验证了通过联合预测多个特征提高泛化性能的效果。多个特征之间的关系(即模型中的Ω)如图4所示。

图4 智能电表数据的学习关系矩阵
可以看出:
(1) 有些特征是正相关的,例如第2个特征(老年人)和第14个特征(单身),这意味着老年人在失去伴侣后通常是单身的。此外,正相关系数占据了Ω的很大一部分,即大多数特征具有相似的模型参数,这也进一步验证了本研究中的MTL模型比单任务学习具有更好的性能。
(2) 有些特征是负相关的,例如第5个特征(烹饪风格)和第14个特征(单身),即大多数单身人士倾向于直接购买熟食而不是自行烹饪。此外,负相关也会减少模型参数的搜索空间。
(3) 只有少数特征是不相关的,例如第11个特征(灯泡)和第14个特征(单身),这意味着老年人不关心灯泡的数量)。可以看出许多观察到的特征可以通过日常用电量数据相互作用。
3.3 定义特征的影响
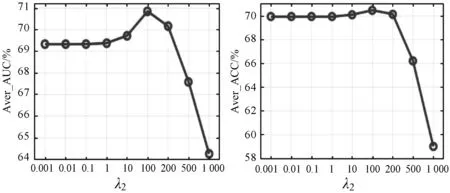
本节通过调整参数λ2来研究定义的特征对相应任务的影响,即λ2的值越大,对应模型的特征数就越少,反之亦然。实现过程中,随机选取10%~90%的智能电表数据集作为训练测试集。通过固定参数λ1=k2=1,约束参数λ2在[0.001,0.01,0.1,1,10,100,200,500,1 000]范围内。图5给出了Aver_ACC(所有测试任务之间的平均精度)和Aver_AUC的分类性能。
(a) (b)图5 Aver_ACC与Aver_AUC的分类性能
由此可以得出结论:
(1) 当λ2=100时,Aver_ACC和Aver_AUC的值都是最大的,即DISMTRL的性能是最好的。可以注意到,一些特征受所有特征的影响,例如第6个特征(就业)和第12个特征(居民)),这意味着这些定义特征的贡献几乎相等。而一些特征受较少特征的影响,例如第10个特征(收入),这意味着低/高收入可以通过不同时间段之间的比率来确认。
(2) 当λ2>100时,Aver_ACC和Aver_AUC值随λ2的增大而减小。这是因为λ2的值越大,可以在权重矩阵W中使用的特征数就越少。
3.4 模型参数k1的影响
本节研究了模型参数k1对Aver_ACC和Aver_AUC的影响,其中k1是所提方法与MTRL的主要区别之一。
随机选取10%的智能电表数据集作为训练集,其余的作为测试集。通过固定参数λ1=λ2=1,并在[0.001,0.01,0.1,1,10,100,200,500,1 000]的范围内调整参数k1,结果如图6所示。当k1值增大时,Aver_ACC和Aver_AUC都会发生波动,这说明适当的参数k1可以使泛化性能更好。这就是所提方法比MTRL更有效的原因之一。
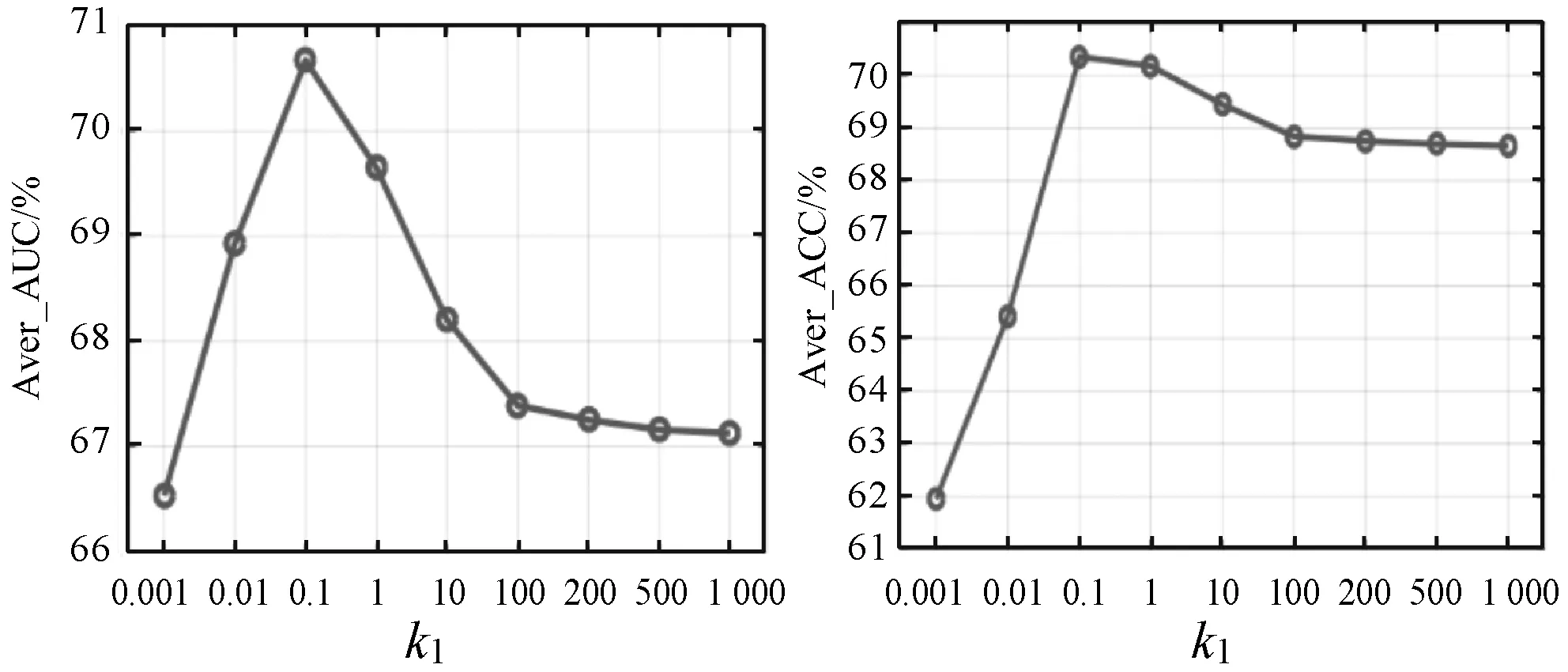
(a) (b)图6 通过改变k1值比较Aver_AUC和Aver_ACC
4 结 语
本文研究了从家庭用电量数据中学习家庭特征的问题。具体而言,本文将特征预测作为一个多任务分类问题,将每个特征的预测作为一个任务来考虑。为了将判别特征信息与任务关系推理结合起来,提出了基于两个协方差矩阵,即DISMTRL的任务关系与判别特征,同时耦合。将特征学习项转化为等价凸问题,利用交替极小化方法学习最优模型。基于CER提供的智能电表数据集,对该模型在预测家庭特征方面的有效性进行了评估。实验结果表明,多任务学习在预测家庭特征方面具有较好的前景。
