图像识别技术在钢企热轧成品库的应用
2022-02-19首钢京唐钢铁联合有限责任公司信息计量部张雪聂军山孙彬涛高焕博
首钢京唐钢铁联合有限责任公司信息计量部 张雪 聂军山 孙彬涛 高焕博
近些年来,图像识别技术在企业质量管理、智能制造方面应用越来越广。本文针对钢企热轧工序钢卷喷码的实时检测、判定进行了图像识别技术应用的探索,旨在实现无人化检测与管理的目的。通过现场实物图像读取,灰度处理和二值化等技术措施,进行字符分割,采用人工神经网络(ANN)识别喷码数据,实现了高准确性的图像检测与识别,提高钢卷入库的准确性,为现场无人化操作与管理给出了解决方案。
随着热轧成品库生产线产量的不断提升,公司提高员工劳产率的要求,热轧成品库需要不断地优化工作方式,提升工作效率,逐步向自动化、智能化方向打造。传统的钢卷库通过人工对下线的热轧卷进行卷号的检查,用摄像头拍下钢卷喷码,再与制造执行系统中的钢卷号对照,核对是否符合生产计划,效率低,由于人工的不准确性,容易造成失误。通过对成品库进行智能化改造,通过接入L3级网络,与制造执行系统通讯获取生产计划,热轧卷下线后,通过图像识别技术,自动对卷的喷码与计划中的卷号进行比对,提高了核对质量和效率,减少人员配备,降低成本。
1 系统总体方案
系统总体方案如图1所示,该方法首先读取图片,然后进行灰度处理和二值化,之后对图像进行膨胀操作,通过方法进行字符的分割,对分割出来的字符进行样本的训练和单个字符的识别。检测时对训练样本进行对比,并做出决策判断。
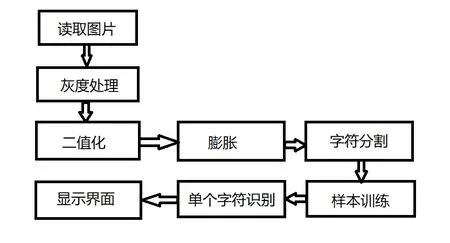
图1 系统框图Fig.1 System block diagram
2 图像处理
2.1 读取图像
利用代码得到钢卷原图像的灰度图,取其中的一卷为例,得到的其灰度图效果如图2所示:

图2 原图Fig.2 Original image
灰度处理代码如图3所示:
图3 灰度处理代码Fig.3 Gray code
处理后的灰度处理效果如图4所示:

图4 灰度处理效果Fig.4 Gray processing effect
2.2 二值化[1]
将图像上的点的灰度值设为0或255,使全部图像呈现出黑白效果,这个过程被称为图像的二值化。换种说法,就是通过选取适当的阈值,使256个亮度等级的灰度图像可以反映图像整体和局部特征的二值化图像。
二值化在数据图像处理领域占有很重要的地位,尤其是在实用图像处理过程中,很多系统都是通过二值图像处理实现的。为了使二值化的处理变得更加简单,在处理和分析过程中,先通过灰度图像二值化得到二值化图像,使得图像的性质只与像素值为0或者255的点的位置有关,这样会使之后的处理与分析变的更加简单清晰。特定物体的灰度值为255,它们的灰度大于或者等于阈值的像素;被排除在物体区域以外的像素点灰度值为0,它们用来表示背景或者例外的物体区域。通过采用连通、封闭的边界来定义不重叠的地方,这样通常能得到相对理想的二值化图像。
通过调节阈值实现图像的二值化便可以动态观察分割图像的具体结果。某些特定物体如果处在有其他等级灰度值的均匀背景下,并在在物体内部的灰度值也是均匀的,可以采用阈值技术,这样能得到比较好的分割效果。如果某些物体与背景的不同不是体现在灰度值上,例如纹理不一样,可以通过将纹理差别转换为灰度的差别,再采用阈值法来分割该图像。
以下是二值化的代码及经过二值化处理后达到的效果图,其中二值化代码如图5所示:

图5 二值化代码Fig.5 Binary code
处理后的二值化效果图如图6所示:

图6 二值化效果图Fig.6 Binary effect diagram
2.3 膨胀
膨胀的目的是为了提取图像中ROI(兴趣)区域,通过对图像X方向和Y方向进行膨胀操作,使图中白色字符喷码区域连通,然后矩形框将最大连通区域提取出来,为后续字符分割做准备。经过反复调试,X方向膨胀的模板设置为(2,1),Y方向膨胀的模板设置为(1,2)时,产生的效果是最好的,代码实现如图7所示。

图7 图像膨胀操作Fig.7 Image expansion operation
2.4 字符分割
把图像中的每个字符从多字符或者多行的图像中分离出来,使每个字符都成为单独的一个,称为字符分割技术。字符分割在字符识别过程中具有重要的作用,它是字符识别的基础,字符分割的质量好坏直接影响字符识别的效果。字符切割的过程中需要考虑字符间的粘连,对字符中关键特征的部分,还要进行特征加强。得到分割之后的单个字符图像,建立各个字符所对应的字符库,以便于训练的时候使用。
2.5 人工神经网络(ANN)
以信息处理的角度,通过对人脑神经元网络进行抽象,来建立某种简单的模型,并按照不同的连接方式组成不同的网络,称为人工神经网络[1]。神经网络与人脑中的神经元的作用有很多相同之处,每一个神经元都有很多神经元作其输入,而且它本身也是其他神经元的输入,数值向量像电信号一样在不同神经元之间传导,只有满足了一定条件,每一个神经元才会发射信号到下一层神经元。
2.6 样本训练
对分割出来的字符在程序上进行分类,字符中共有样本12种,其中数字字符10种,如0-9;其他字符2种,如H、J,按照字符种类建立对应的文件夹,每种分类图片数量共20张,训练样本分类如图8所示:
图8 训练样本分类Fig.8 Training sample classification
进行样本训练和识别前,应把分割出来的字符图片,统一尺寸为(45,65),部分样本出现频率低,要分割很多图片才能得到足够的样本数量。样本数量应尽可能多一些,有助于提高识别准确率。实现代码请如图9所示。

图9 字符训练Fig.9 Character training
2.7 识别
图片训练后保存训练文件格式*.xml。识别时用训练好的.xml文件,对现场采集的下线钢卷图片进行识别,采集热轧下线的上千张钢卷图片,提取大量字符训练样本,测试图像充足,单个字符识别率为95%以上。实现代码如图10所示。

图10 钢卷号识别Fig.10 Steel coil number recognition
3 结语
热轧下线钢卷在制造执行系统的喷码信息存在与实际不符情况,导致入库信息错误,进而影响后续钢卷倒库、出库等后续流程,增加了人工盘库的工作量。采用机器视觉技术后,能够自动识别喷码设备喷印的钢卷号码,并及时反馈给制造执行系统,比对钢卷信息是否错误,并及时纠正,大大提高了下线钢卷入库信息的准确性,避免的出库错误,提高了生产效率。
