基于多源数据融合技术的盐酸青藤碱制备工艺一致性评价方法研究
2022-02-18吴思俊吴红根贺兴立李文龙
吴思俊,王 龙,吴红根,贺兴立,仇 萍,李 正,李文龙*
(1.天津中医药大学 中药制药工程学院,天津 301617;2.天津中医药大学 省部共建组分中药国家重点实验室,天津 301617;3.湖南正清制药集团股份有限公司,湖南 怀化 418000)
盐酸青藤碱是从防己科植物青藤(Sinomenium acutum(Thunb.)Rehd. et Wils.)以及毛青藤(Sinomenium acutum(Thunb.)Rehd. et Wils. var. cinereum Rehd. et Wils. )的干燥藤茎中提取制备的生物碱单体,具有祛风除湿、消肿止痛、抗炎等多种药理作用[1]。因具有疗效确切、副作用较小等明显优势,近些年来,以盐酸青藤碱为活性药物成分的制剂,如片剂、注射剂及外用制剂等,已被广泛用于治疗风湿性、类风湿性关节炎等疾病[2]。
青藤碱微溶于水,在制备过程中往往需要借助有机溶剂辅助提取。目前,工业生产盐酸青藤碱多使用碱化水提取工艺,即药材中加入水及一定量的熟石灰,碱化一段时间后加入一定量工业苯,回流提取,最后酸化、静置、析晶。然而,苯为一级有毒溶剂,对人体危害极大,而且在溶剂的回收处理方面需通过繁锁的工艺方能达到环保要求,在一定程度上增加了企业的生产成本。因此,从寻找替代溶剂的角度出发,对提取工艺进行适当变更是非常必要的。然而,在药品生产过程中更改工艺需严格按照法规要求进行。2017 年,国家食品药品监督管理总局组织制定了《已上市中药生产工艺变更研究技术指导原则》[3],规定在不影响药品安全性、有效性和质量可控性的前提之下,可以考虑工艺变更。目前,盐酸青藤碱制备工艺明确且较为固定,不同厂家生产的盐酸青藤碱的纯度基本都能达到98%以上。在这种情况下,产品质量差异往往是受剩下的不到2%的杂质所影响。但中药是一个极其复杂的体系,由于药材自身质量的波动性和不同厂家工艺过程控制水平的参差不齐,依靠传统的分析技术(液相色谱、质谱等)难以鉴别原料中所有杂质的种类[4-5]。产生这一结果的主要原因是:①中药产品中杂质含量较低,当某些杂质含量低于仪器检测限时,无法获得相关信号;②高效液相色谱多用于检测具有紫外吸收的化合物,当杂质不具有紫外吸收时无法被成功检测;③杂质结构复杂且种类繁多,当缺少标准品时难以实现定性定量分析。而缺少产品杂质信息,则难以进行原料整体质量评价,要实现工艺变更更是无从谈起。因此,获取产品杂质信息需要借助其他的分析技术。近红外(Near-infrared,NIR)光谱技术因快速、无损、环境友好等优点,已在众多领域取得了广泛应用。NIR 光谱记录的含氢基团(C—H,O—H,N—H 等)的倍频和合频吸收峰,往往用于反映待测物的整体信息[6-8]。拉曼光谱(Raman spectroscopy,RS)技术则主要用于研究晶格和分子的振动模式、转动模式以及在某一系统中的其他低频模式,能够分析出化学物质的内部结构,与NIR 光谱有一定的互补性[9-10]。多源数据融合技术指对来自多种分析仪器的信号进行多级别、多方面、多层次的处理,在一定准则下加以分析、综合,产生新的有意义的信息,以弥补单一来源分析信号信息量不足的缺点[11-13]。如将盐酸青藤碱原料的两种光谱信息进行融合,即可获得既包含活性成分信息和杂质信息,又包含成分分子结构信息的综合数据,利用该数据进行产品质量综合评价具有理论上的可行性和实践上的可操作性[14]。
本研究收集了不同厂家分别利用苯和氯仿生产的盐酸青藤碱样品,同时采集样品的NIR 光谱和Raman 光谱,分别采用不同水平的数据融合策略对光谱数据进行处理,利用相似度匹配值(Similarity match value,SMV)、Hotelling T2和DModX 3 种统计量对样品间的质量差异进行表征,旨在开发一种用于评价工艺变更前后产品质量的新方法。
1 实验部分
1.1 实验仪器与材料
Antaris Ⅱ傅里叶变换近红外光谱仪(赛默飞世尔科技公司,美国),配有TQ Analyst 8.0 数据处理软件;DXR显微拉曼光谱仪(赛默飞世尔科技公司,美国);AL204型电子天平(梅特勒-托利多国际股份有限公司,瑞士)。
从A 公司购买的酸水渗漉-氯仿萃取后制得的盐酸青藤碱样品(含量大于98%),共32 批,编号1 ~32;从B 公司购买的苯提取后制得的盐酸青藤碱样品(含量大于98%)共20 批,编号33 ~52;从C 公司购买的酸水渗漉-氯仿萃取后制得的盐酸青藤碱样品(含量大于98%)共20 批,编号53 ~72。
1.2 样品质量评价方法
1.2.1 相似度匹配模型建立 运用Kennard-Stone 算法从32 份A 公司样品中选取16 份作为校正集,剩下的16 份作为验证集。运用TQ Analyst 8.0 软件建立相似度匹配模型,然后利用模型进行验证集SMV预测,根据模型预测出的SMV确定阀值。阀值确定原则:如果验证集SMV为正态分布,则可根据统计过程控制中的3σ原则确定阈值,即将阈值设置为SMV的平均值减去3倍标准偏差。待模型建立并确定阀值后,即可用于评估待测样品与建模样品的质量差异。如果待测样品的SMV 大于或等于阈值,则认为样品与A 公司样品质量一致性良好,相反,如果其SMV 小于阀值,则认为两者质量差异较大[15-16]。
1.2.2 Hotelling T2与DModX 值 在中药产品质量控制研究中,除将SMV 作为质量一致性判别指标外,还常常使用主成分分析(Principal component analysis,PCA)模型的统计量进行质量评价。利用A公司的32批样品建立PCA 模型,计算样品的Hotelling T2和DModX 统计量数值并求得控制限。Hotelling T2统计量由所有主成分的归一化得分累加得到,指样品偏离模型中心的距离,反映了模型内部数据变化的程度[17]。样品k的Hotelling T2可由如下公式表示:

式中,λA表示数据矩阵前A个主成分对应的特征值组成的对角矩阵,Tk是第k个主成分的得分向量。
计算Hotelling T2的控制限是构建T2控制图的重要环节,该值根据F分布计算得到,计算公式如下:

其中,I为训练集批次数,A为主成分数。Fα(A,I-A)表示置信度为α,第一自由度为A,第二自由度为I-A时F的临界值。
而DModX 统计量则主要用来监测输入的数据结构是否发生变化,反映样品偏离模型的绝对距离,是一种衡量模型外部数据变化程度的度量[18]。当Hotelling T2统计量不能监测到样品发生的异常变化时,常使用DModX统计量进行监测。样品k的DModX可由下式表示:

式中,en为变量xn初始值的残差,Xnk是变量xn的估计值。DModX统计量的控制限可由(4)式计算:

需要注意的是,在评判待测样品与A 公司样品间的差异时,往往需将Hotelling T2与DModX 两种统计量相互结合、综合分析。
2 结果与讨论
2.1 近红外光谱采集
每批样品精密称取8 g,过200 目标准药筛(符合2020 版药典标准)后,对细粉进行NIR 光谱采集。NIR 光谱仪采用积分球漫反射采集模式,以空气为背景,扫描范围为4 000 ~10 000 cm-1,分辨率为16 cm-1,扫描次数为64次。共采集到72张NIR光谱,如图1A所示。
2.2 拉曼光谱采集
将每批过筛后的细粉分别精密称取0.1 g置于Raman光谱仪配备的载玻片上,进行Raman光谱的采集。Raman 位移为50 ~3 500 cm-1,激光波长为532 nm,激光能量为10.0,分辨率为2.7 ~4.2 cm-1,样品曝光时间为2 s。共采集到72张Raman光谱,如图1B所示。

图1 72批盐酸青藤碱样品的近红外原始光谱图(A)和拉曼原始光谱图(B)Fig.1 The raw NIR spectra(A)and raw Raman spectra(B)of 72 batches of sinomenine hydrochloride samples
2.3 光谱预处理及多源数据融合
从图1 中可以看出,NIR 光谱和Raman 光谱均存在明显的基线漂移,推测可能是由仪器噪声、环境变化等因素造成。为消除基线漂移对数据分析的干扰,采用Savitzky-Golay 卷积平滑和一阶导数对光谱数据进行处理,处理后的光谱如图2 所示。经过预处理之后,利用多源数据融合技术对光谱数据进行融合。分别考察了3 种不同水平的数据融合方式,第一种融合方式为低水平融合即像素级融合,指在未经任何处理的情况下将光谱数据进行首尾拼接;第二种融合方式为中水平融合即特征级融合,指在对各部分数据进行特征提取后进行的数据融合;第三种融合方式为高水平融合即决策级融合,指将各部分数据分别处理并做出判断,最后对所有决策进行融合。对比每种数据融合方式下样品质量的差异,从而综合评判经不同溶剂制备的盐酸青藤碱样品的质量差异,并探究不同水平的数据融合策略可能对分析结果产生的潜在影响。
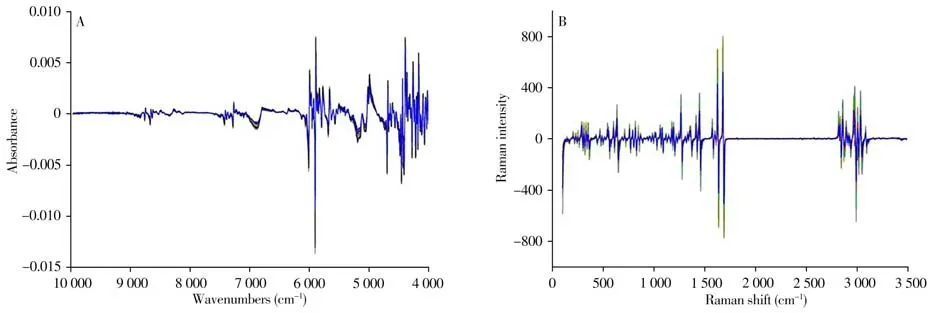
图2 经Savitzky-Golay卷积平滑和一阶导数处理后的样品近红外(A)和拉曼(B)光谱Fig.2 The NIR spectra(A)and Raman spectra(B)of samples pretreated with Savitzky-Golay smoothing combined with first derivative
2.4 基于低水平融合模式的样品质量判别研究
由于NIR 光谱与Raman 光谱的响应值差异巨大,且不在一个度量之下,因此在进行光谱数据的首尾拼接之前,需要先进行归一化处理使响应值处于同一度量。建立相似度匹配模型,模型对验证集(No. 17 ~32)SMV 的预测结果如表1 所示。对预测结果进行正态性检验,得到P值为0.764,大于0.05,表明结果符合正态分布。根据3σ原则,计算得到阀值为94.21。利用相似度匹配模型对B 公司和C 公司共40 份样品进行SMV 预测,结果如图3A 所示。从图中可以看出,40 份样品的SMV 均大于94.21,表明样品质量与A 公司样品无明显差异。然后,利用SIMCA 分析软件(V14.1,Umetrics 公司,瑞典)建立A 公司样品的PCA 模型,获得Hotelling T2和DModX 统计量及其控制限。最后分别求得40 份样品的两种统计量值,结果如图3B 和3C 所示。结果显示,所有样品的Hotelling T2都处于控制限以下。从DModX 控制图中可以看出,A 公司的32 份样品中有3份略超出控制限,另两家公司提供的样品中均有3份超出了控制限。推测原因在于:①将光谱数据进行低水平融合可能会包含过多冗余信息,从而对分析结果的准确性产生影响;②9份样品的质量可能与A公司样品存在一定差异。为探究是何种原因造成的这一结果,将进行进一步的中水平数据融合分析。

表1 相似度匹配模型验证集预测结果Table 1 Prediction results of the similarity match model on the validation set
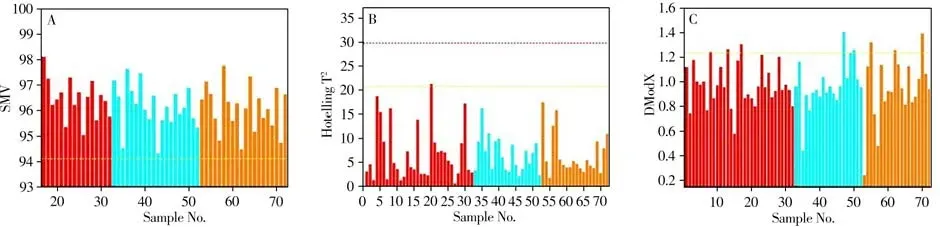
图3 基于低水平融合模式的盐酸青藤碱样品质量评价控制图Fig.3 The control charts of quality evaluation of sinomenine hydrochloride samples based on low level fusion mode
2.5 基于中水平融合模式的样品质量判别研究
由于算法可解释性强、所建模型性能稳健等优势,中水平融合模式是数据融合研究中使用最为频繁的方式之一。在本研究中,为提取光谱信息中的特征信息,利用主成分分析法对NIR 和Raman光谱数据分别进行降维处理。结果显示:针对NIR 光谱数据,当主成分数设置为13 时,能解释光谱变量间95%以上的差异;针对Raman 光谱数据,当主成分数设置为22 时,能解释变量间95%以上的差异。当主成分能解释原始数据95%以上的差异时,即具有良好的数据代表性。本研究将提取的主成分进行融合,最终得到35 维的特征数据。利用训练集数据建立相似度匹配模型后,对验证集SMV 进行预测,结果如表2 所示。对预测结果进行正态性检验,得到P值为0.947,大于0.05,因此数据符合正态分布。根据3σ原则,计算得到SMV 阀值为93.23。利用相似度匹配模型对40 份样品的SMV 进行预测,结果发现第52 份样品的SMV 低于控制限,其余样品的SMV 均在控制限之上。另外,所有样品的Hotelling T2和DModX 统计量数值均在控制限之下。与低水平融合模式结果比较可以发现,通过提取数据特征的方式可以有效剔除冗余信息的干扰,40 份待测样品中有39 份与A 公司样品无明显质量差异。而第52 份样品可能存在质量问题,需要利用其它手段进行单独检测。
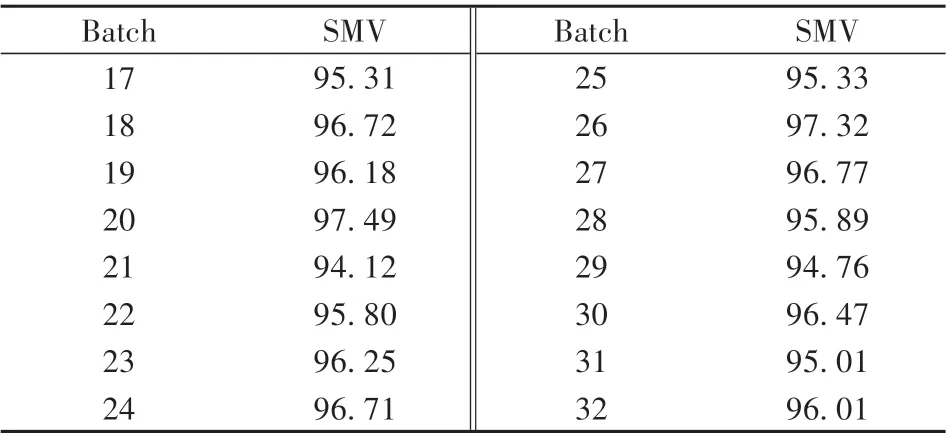
表2 相似度匹配模型验证集预测结果Table 2 Prediction results of the similarity match model on the validation set
2.6 基于高水平融合模式的样品质量判别研究
高水平融合又称决策级融合,当所检产品附加值高,或会因质量不合格而对人体健康、经济效益产生重大影响时,往往使用高水平融合模式。首先,利用NIR 光谱数据进行产品质量分析。建立基于NIR光谱的相似度匹配模型,模型对验证集的预测结果如表3所示。对预测结果进行正态性检验,得到P值为0.550,大于0.05,因此数据符合正态分布。根据3σ原则,计算得到SMV阀值为93.64。由图4的控制图可以看出,第38 和第52 份的SMV 在控制限以下,第42 份的DModX 统计量超过控制限。因此,需要对这3份问题样品进行单独质量检测。而在A 公司样品中,第1 和第27 份样品的DModX 统计量超出控制限,在低水平融合分析中同样出现了A 公司样品DModX 数值超出控制限的现象,而在中水平融合分析中则未出现该现象。推测原因可能是,在未进行特征信息提取时冗余信息对数据分析产生了影响。

表3 基于NIR光谱数据的相似度匹配模型验证集预测结果Table 3 Prediction results of the similarity match model on the validation set based on NIR spectral data

图4 基于NIR光谱数据的盐酸青藤碱样品质量评价控制Fig.4 The control charts of quality evaluation of sinomenine hydrochloride samples based on NIR spectral data
利用NIR 光谱数据进行产品质量分析后,对样品的Raman 光谱数据进行整理、分析。表4 中列出了基于拉曼光谱的相似度匹配模型对验证集SMV的预测结果,对结果进行正态性检验,得到P值为0.384,大于0.05,因此数据符合正态分布,最终求得A 公司样品的SMV 阀值为94.24。计算所有样品的3 种统计量,并描绘出控制图。从图5 中可以看出,第40份样品的SMV处于控制限以下,第3和第17 份样品的DModX 统计量值超出控制限。结合基于NIR 光谱数据的分析结果,第1、3、17、27、38、40、42、52份样品需要进行仲裁分析来判断是否为异常样品。从以上结果可以发现,由于两种光谱信息所包含的样品信息不同,当单独使用NIR光谱数据或Raman光谱数据进行分析时,判别出的问题样品各不相同。此时,运用决策级融合即可有效避免问题样品的遗漏,为产品质量一致性提供保证。

表4 基于拉曼光谱数据的相似度匹配模型验证集预测结果Table 4 Prediction results of the similarity match model on the validation set based on Raman spectral data
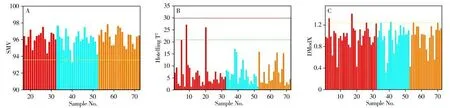
图5 基于Raman光谱数据的盐酸青藤碱样品质量评价控制Fig.5 The control charts of quality evaluation of sinomenine hydrochloride samples based on Raman spectral data
在本研究中,低水平融合方式和高水平融合方式所判断出的问题样品出入较大,而通过中水平融合方式判断出的问题样品被包含于高水平融合判别出的问题样品中。实际上,在应用数据融合技术时,需要根据数据特征合理选择融合水平。低水平融合方式方便快捷,不需要对数据进行任何处理即可进行融合分析,但当数据维度高且可能包含一定量的冗余信息时,这种数据融合方式往往不适用。此时,中水平融合方式可以被考虑用于数据分析,其复杂程度虽然比低水平融合方式高,但能有效剔除冗余信息的干扰,提取出关键信息。高水平融合方式最为复杂,需要利用不同来源数据进行单独分析后产生统筹结果。在进行高附加值样品或毒副作用较强样品的质量控制时,一般使用高水平融合方式。
3 结 论
本研究利用NIR 光谱技术、Raman 光谱技术结合多源数据融合技术,提出了一种用于中药产品制备工艺变更前后质量一致性评价的新策略。研究发现,在低、中、高3 种数据融合模式下,除个别盐酸青藤碱样品需要仲裁分析进行质量确认外,苯提取和酸水渗漉-氯仿萃取后所制得的盐酸青藤碱样品的质量无显著差异。在盐酸青藤碱生产过程中,酸水渗漉-氯仿萃取有望有效替代苯提取,对降低生产成本和环境保护具有重要意义。
