基于用电行为数字特征画像的电力用户两阶段分类方法
2022-02-17王磊刘洋李文峰张杰许立雄邢哲铭
王磊, 刘洋,3,李文峰,张杰,许立雄,邢哲铭
(1.四川大学电气工程学院,成都市 610065;2. 国网河南省电力公司经济技术研究院,郑州市 450052;3.智能电网四川省重点实验室(四川大学),成都市610065;4.大连市大数据中心,辽宁省大连市 116000)
0 引 言
电力市场和综合能源系统的融合发展使电力用户在能源交易中的市场主体地位不断凸显,对用户用电行为开展精细化建模或画像,精准掌握用户用电规律,成为提升电力企业服务水平和市场竞争力的关键因素之一[1-2]。与此同时,电力市场化环境下用户用能需求和选择的多元化使用户用电行为的多样性和随机性不断增强,用户用电行为精细化画像对数据分析算法提出更高要求,传统电力负荷数据分析技术面临严峻挑战[1,3]。近年来,机器学习技术的革新和电力负荷数据的累积,使基于数据驱动的电力用户用电行为画像和用户分类研究受到关注[4]。
用户日负荷模式能从日时间尺度较为完整地刻画一个周期的用户用电行为,是用户分类研究中常用的用电行为画像方式。文献[5]提出一种基于两阶段聚类的用户分类方法,仅选取每位用户的一类典型日负荷模式代表其用电行为画像,难以充分表征用户全年用电行为。文献[6]提出基于快速小波变换和G-means算法的用户分类方法,并将用户的多种典型负荷模式作为其用电行为画像,但带来模糊用户分组的问题。文献[7]通过密度聚类获取每位用户一年四季的典型日负荷模式,从中提取六类特征作为用电行为画像并基于画像对用户分类。现有用户用电行为画像多基于用户自身的典型日负荷模式,忽视了从普遍共性的日负荷模式中关注用户对不同日负荷模式的偏重差异,画像结果较为片面。
基于用户用电行为画像开展电力用户分类是电网企业基于业务需要发掘目标用户的理论基础。以无监督聚类、有监督分类以及集成学习为代表的机器学习算法在电力用户及负荷分类研究中应用广泛。近年来,结合无监督聚类算法在划分类别标签方面的优势和有监督分类算法在拟合复杂非线性映射规律和算法容错性等方面的优势开展电力用户及负荷分类成为一种行之有效的思路。文献[8]提出一种结合负荷频域特征和长短期记忆(long short-term memory,LSTM)神经网络的日负荷曲线分类方法。文献[9]提出一种结合聚类算法和稀疏自编码器预训练支持向量机有监督分类的负荷曲线分类方法。文献[10]提出一种结合K-medoids聚类和Spark分布式神经网络的基分类器集成学习负荷分类方法。集成学习与负荷数据聚类分类的结合应用展现出良好的算法稳定性、准确度增益和算法普适性。但受基分类器差异性和准确度的制约,集成学习面临基分类器冗余的问题[11-12]。集成学习在生成基分类器集群时会产生部分训练结果雷同的冗余个体,导致集群差异性下降,极端情况下造成无效集成[12]。有效的基分类器选择集成策略对于改善基分类器冗余问题、保证集成学习对用户及负荷分类性能增益具有重要价值[13-14]。此外,学习能力更强的基分类器也是提升集成学习分类性能的重要方面。
类别不平衡问题广泛存在于电力用户负荷数据中,表现为分类模型中少数类样本的辨识度被多数类淹没,是电力负荷分类领域的重要难题之一[10,15]。以合成少数类样本过采样技术(synthetic minority oversampling technique,SMOTE)为代表的过采样方法,能避免将类别平衡过程与分类过程耦合,具有广泛的场景适用性。但SMOTE采样机制忽视了少数类样本的特征空间密度分布特性,合成新样本容易失真,且在不平衡比例较高时算法效能退化严重[15-16]。生成式深度学习模型通过学习样本分布规律能获取较高质量的新样本,但算法需要大量数据资源驱动。
针对当前电力用户分类研究中用户用电行为画像结果片面、集成学习负荷分类研究中的基分类器冗余问题及负荷类别不平衡问题,提出一种基于用电行为数字特征画像的电力用户两阶段分类算法。第一阶段,提出一种结合谱聚类(spectral clustering,SC)和集成强分类器的用户日负荷曲线分类算法:首先,针对集成学习基分类器学习能力弱的不足,提出一种基于改进长短期记忆网络的强分类器;其次,针对基分类器冗余问题,提出一种基于最小正则化代理经验风险的优化选择集成(optimal selective ensemble,OSE)策略;然后,提出一种基于密度的高斯过采样方法(density based gaussian SMOTE,DBGS)处理类别不平衡。第二阶段,基于负荷曲线分类结果,构建以日负荷模式发生概率为数字特征的用户用电行为画像,采用SC算法对用户画像实施分类。
1 电力用户分类原理概述
本文结合SC算法和集成强基分类器算法的优势,将电力用户的分类过程按照两阶段来实施。第一阶段,通过谱聚类算法对用户集群的部分日负荷曲线提取日负荷模式标签,采用集成强基分类器算法经标签样本训练完成对其余日负荷曲线分类。第二阶段,构建基于日负荷模式发生概率的用户用电行为数字特征画像,并通过SC算法对画像结果聚类以实现用户分类。
其中,采用改进LSTM网络作为集成学习的基分类器,引入模型压缩技术投影层(projection layer,PL)压缩LSTM网络的隐层参数,并采用Attention机制和层归一化(layer normalization,LN)方法提升其分类准确率,构建ALN-LSTMP(attention based and LN based LSTM with projection layer)压缩深度学习机参与集成决策;提出一种基于最小正则化代理经验风险的OSE策略,改善基分类器冗余问题对集成分类结果的影响;提出一种DBGS过采样算法,解决日负荷标签样本的类别不平衡问题。
2 类别平衡处理
DBGS算法基本原理是根据少数类样本的密度分布规律实施采样。其能自适应调节不同分布区域的少数类样本合成数量,经过平衡处理后样本的类别边界形态具有较好的保持效果,可有效降低类别不平衡程度,对边界样本的重叠程度影响较小[17]。DBGS的算法过程如图1所示。

图1 DBGS算法示意图Fig.1 Schematic diagram of DBGS algorithm
DBGS算法的基本流程如下:
步骤1:采用DBSCAN(density-based spatial clustering of applications with noise)对少数类样本实施密度聚类,得到聚类簇Cj集合:
C={Cj|i=1,…,q}
(1)
步骤2:对每个聚类簇构建直接密度可达图G,表示为:G(Cj,ε,τ)=G(V,E)。其中ε表示直接密度可达半径,τ表示构成密度核心样本点的最少近邻数目;V表示聚类簇Cj的所有样本点集合,E表示G的所有直接密度可达边集合,直接密度可达边表示为两样本点的欧式空间距离。
步骤3:提取每个聚类簇的伪质心样本s0,即距离聚类簇均值质心最近的样本点。
步骤4:采用Bellman Ford算法求取每个样本到s0的最短加权图路径π[18]。
步骤5:在π上随机选取一段线径πab(a,b代表π途经的样本点序号)作为采样区间进行插值,并根据Gaussian SMOTE采样机制[19],对合成样本施加适量高斯随机摄动合成新样本ss:
χloc~U(0,‖πab‖2)
(2)
ζper~N(0,‖πab‖2·σ)
(3)
ss=sa+(sb-sa)·χloc+ζper
(4)
式中:χloc表示插值坐标,服从均匀分布;ζper表示高斯随机摄动,服从正态分布;σ表示ζper的相对标准差;ss表示合成新样本;sa和sb表示ss的参照样本对。使插值坐标偏离πab以降低合成样本相似度。
3 基于优化选择集成压缩深度学习机的负荷曲线分类
3.1 负荷分类模型ALN-LSTMP
LSTM网络引入“门”机制(包括遗忘门、输入门以及
输出门),通过“门”来控制LSTM网络单元状态信息的保留或遗忘,可以挖掘数据的长时序关联特征。LSTM存在计算效率低的缺点,引入投影层PL构建LSTMP(LSTM with projection layer)单元缩减模型参数、加快运算速度[20],其内部结构如图2所示。
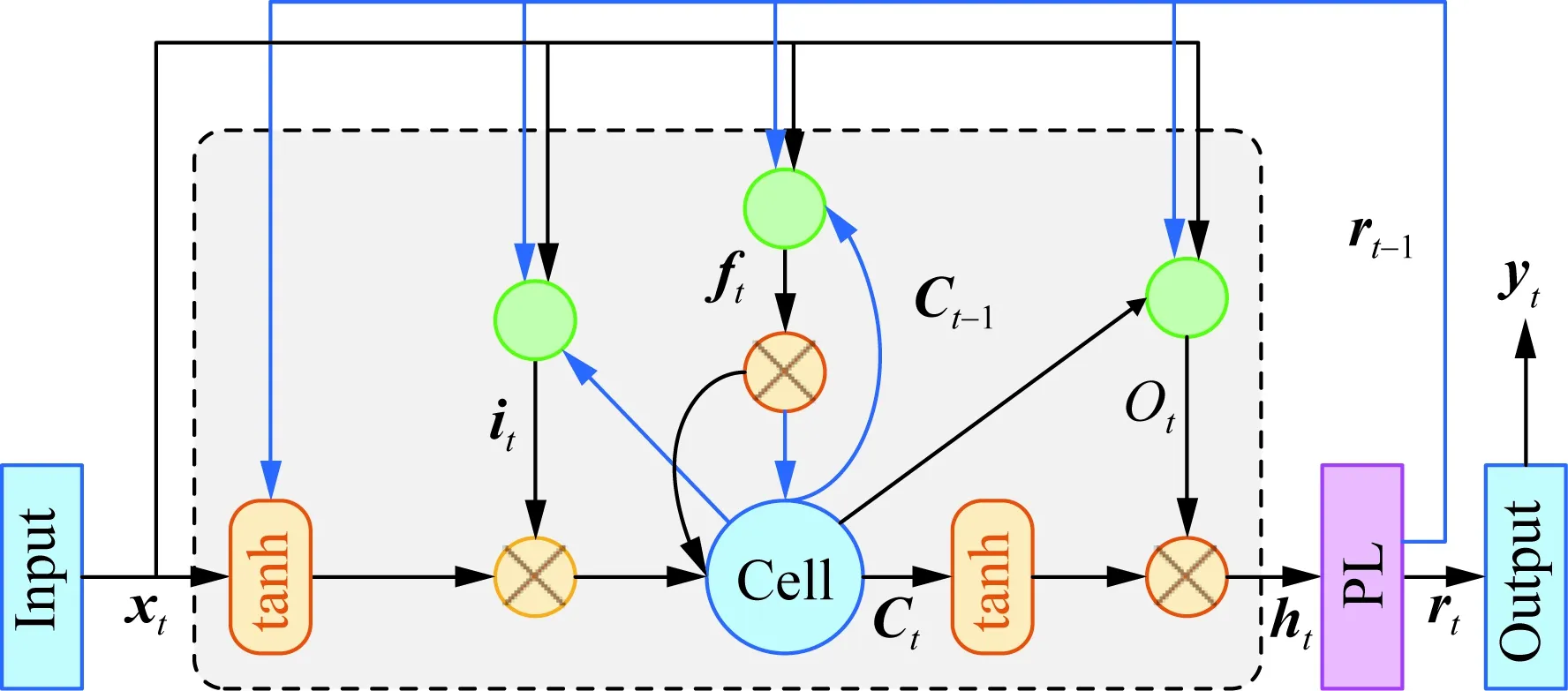
图2 LSTMP单元内部结构Fig.2 Internal structure of LSTMP unit
PL的原理是:在t时刻短时记忆状态ht进入下一时间步前对其线性降维以提取主要关联特征,在压缩模型参数的同时提升模型泛化性能。PL表达为:
rt=Wrhht
(5)
yt=φ(Wyrrt+by)
(6)
式中:Wrh表示t时刻短时记忆状态ht到PL层输出的权重矩阵;rt表示经权重矩阵Wrh降维后的短时记忆状态;Wyr和by分别表示rt到LSTMP最终输出yt的权重矩阵和阈值向量;φ(·)为网络层的输出激活函数,本文采用Relu函数[15]。加入PL后的各门结构如下:
it=φ2(Wixxt+Wirrt-1+WicCt-1+bi)
(7)
ft=φ2(Wfxxt+Wfrrt-1+WfcCt-1+bf)
(8)
Ct=ft⊙Ct-1+it⊙tanh(Wcxxt+Wcrrt-1+bc)
(9)
Ot=φ2(Woxxt+Worrt-1+WocCt+bo)
(10)
式中:it、ft和Ot分别为输入门、遗忘门以及输出门;Ct为LSTMP单元t时刻的长时记忆状态;Wix表示t时刻输入xt通过输入门的权重矩阵;Wir表示t-1时刻降维后短时记忆状态rt-1通过输入门的权重矩阵;Wic表示t-1时刻长时记忆状态Ct-1通过输入门的权重矩阵;Wfx表示t时刻输入通过遗忘门的权重矩阵;Wfr表示rt-1通过遗忘门的权重矩阵;Wfc表示Ct-1通过遗忘门的权重矩阵;Wcx表示输入xt保留到Ct的权重矩阵;Wcr表示rt-1保留到Ct的权重矩阵;Wox表示输入xt通过输出门的权重矩阵;Wor表示rt-1通过输出门的权重矩阵;Woc表示Ct通过输出门的权重矩阵;bi、bf、bc和bo分别表示输入门、遗忘门、长时记忆元胞Cell以及输出门的阈值向量;φ2(·)表示激活函数,本文均设定为Sigmoid函数。经过PL对模型压缩后,模型参数缩减数量nR为:
(11)
式中:nc为隐藏层神经元个数;nr为PL的输出维度;no为输出yt的维度。对长期依赖较强的数据如电力负荷的多时间步长学习,模型压缩具有更大的计算效率提升潜力。
ALN-LSTMP分类模型如图3所示,其由数据预处理模块、LSTMP层、LN层、Relu非线性层以及Attention模块级联,通过柔性最大概率层Softmax输出分类结果,表示为各类别的决策概率。数据预处理层完成输入数据的清洗和插补。LN层对网络层输入作归一化处理,可加快模型收敛速度[21]。经过Relu激活函数处理后,Attention层通过赋予输入信息不同权重可以快速捕捉信息关键特征[22],有助于加快模型学习速度,降低其训练时长。
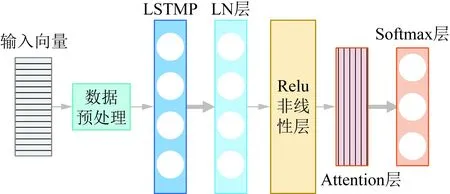
图3 ALN-LSTMP分类模型Fig.3 ALN-LSTMP classification model
3.2 OSE策略
所提OSE策略的基本思想是:基分类器的冗余度越高,被选择的可能性越小。此外,分类准确率高的基分类器具有优先选择权。所提OSE策略的具体步骤为:首先,构造评估集成学习误分类损失的正则化经验风险目标函数,使分类准确度高的基分类器能被优先选中。其次,采用皮尔逊相关系数(pearson correlation coefficient,PCC)构建量化基分类器之间相关性的冗余度指标,并基于该指标提出评估基分类器对集成学习贡献度的重要性指标。将重要性指标作为惩罚因子纳入优化问题的正则项中,目的是使OSE策略在尽量不牺牲分类精度的前提下,淘汰冗余基分类器。最后,将优化后权重为0的基分类器丢弃,其余通过多数投票法参与集成。
3.2.1 正则化经验风险函数
所提OSE策略,通过最小代理正则化经验风险函数Γ来确定基分类器的集成组合权重ω,公式如下:
Γ(ω)=λL(ω)+P(ω)
(12)
式中:L(·)为代理经验风险函数,度量集成学习在训练样本中的误分类损失;P(·)为正则项;λ为超参数。通过超参数λ调节经验风险项和正则项的比例,控制集成模型复杂度,抑制过拟合。
3.2.2 代理经验风险函数L
集成学习中,令ω=[ω1,…,ωn]T表示基分类器集合{h}={h1,…,hn}(共计n个)的集成组合权重(h和ω的下标代表基分类器序号,下同),定义第i个样本xi的集成分类结果:
(13)
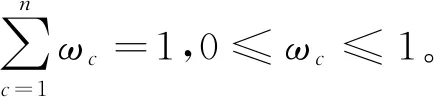
基于集成分类结果,定义其集成边界m(xi):
m(xi)=sign[yiH(xi)]=sign[yi(hi)Tω]
(14)
式中:yi为真实标签;m(xi)∈{-1,1},当分类正确时为1,反之为-1。
基于集成边界,定义训练集样本(数目为N)集成分类结果的经验风险函数L0:
(15)
由于所提经验风险函数属于非凸、不连续函数,采用代理损失优化方法能降低其求解难度[23]。本文采用截断huber损失函数用于原问题的代理优化求解。
(16)
式中:参数δ用于调节函数对于噪声和异常点的敏感度,本文设定为0.6。
最后代理经验风险函数L表示如下:
(17)
3.2.3 正则项P
PCC可以评估变量间的相关度。将基分类器对初始训练集的分类结果组织为向量形式,通过PCC度量不同基分类器学习结果的相关度:
(18)
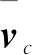
(19)
将待度量基分类器与其他基分类器的平均PCC作为其冗余度指标:
(20)
冗余度低且分类结果和样本标签相关度高的基分类器对集成分类的贡献更大,该基分类器更重要。因此,定义基分类器的重要度:
S(hc)=ρ(hc,y)-R(hc)
(21)
式中:y为初始训练集所有样本标签组成的“全1”向量。
将S(hc)纳入正则项中,对基分类器的集成组合权重施加惩罚,基分类器重要度越低受到的惩罚越重,被选中的概率越小。定义正则项P:
P=ωTS-1ω
(22)
式中:S=diag[S(h1),…,S(hn)]。
3.2.4 优化选择集成问题模型
综合考虑经验风险项及其正则项,构建如下优化问题:

(23)
3.3 多数投票法集成ALN-LSTMP
经过OSE策略遴选出去冗余后的ALN-LSTMP基分类器子集,采用多数投票法对各基分类器的分类结果组合决策,可以获得更好的集成泛化性能。多数投票法机制如下:
(24)
式中:nose表示优化后参与集成的基分类器个数;rc,test表示测试样本xtest在第c个基分类器中的分类结果,表征为独热编码向量,对其累加获得各类别的投票分数,选取最大分数值对应的类别g作为分类结果γtest。OSE-ALN-LSTMP的算法过程如图4所示。

图4 OSE-ALN-LSTMP算法示意图Fig.4 Schematic diagram of OSE-ALN-LSTMP
4 用户用电行为数字特征画像及用户分类
一定区域内电力用户受气象、节假日以及经济活动等因素影响宏观趋同,且随着信息化、数字化技术的应用普及,用户间用能习惯和用能需求的关联耦合不断加深,一方面用户用电行为呈多元化演进趋势,另一方面用户群体共性的用电行为特征愈发凸显。通过提取用户共性的日负荷模式,统计用户一年中不同日负荷模式的发生概率,可以实现对用户多元化用电行为的数字特征画像表征。因此,提出一种基于负荷模式发生概率的用户用电行为数字特征画像方法。定义所提取用户共性日负荷模式共计Θ类,近似统计一年中用户k日负荷模式θ的发生概率如下:
(25)

定义用户k用电行为数字特征画像如下:
γk=[γk,1,…,γk,Θ]
(26)
基于用户用电行为数字特征画像,采用谱聚类算法对用户实施分类或分组。基于分类结果计算各类画像的均值质心,选取最接近均值质心的画像作为不同类型用户的典型数字特征画像。
5 算例分析
算例在Intel(R) Core i3-7100 CPU @3.90 GHz,RAM 16 GB,操作系统Win10的计算机上实施。为验证所提方法的有效性,从四川省某地区抽选450家用户在2017年的实测负荷数据用于算例分析。日负荷曲线共计164 250条(采用所有日负荷曲线的最大值作为归一化基准值,对日负荷曲线实施最大值归一化),随机抽取25%的日负荷曲线实施谱聚类,获取日负荷模式标签。最佳聚类数目通过轮廓系数(Silhouette index,SI)和DBI系数(Davies-Bouldin index,DBI)来确定[10],确定为7类,如图5所示。
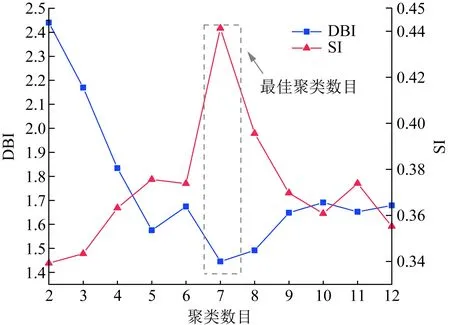
图5 最佳聚类数目选择Fig.5 Selection of optimal number of clusters
各类训练样本数量为10 746、10 955、5 104、1 667、4 270、4 024、4 291(判定第4类为少数类样本),采用DBGS算法对其少数类负荷样本进行过采样。ALN-LSTMP的输入特征维度为1,时间步长为48,隐藏层神经元个数为32,PL输出维度为16,参数缩减数量为1 792个,缩减比例为10.79%。训练生成ALN-LSTMP基分类器,当基分类器数目达到20时,Ensemble-ALN-LSTMP方法的分类正确率基本饱和。设置基分类器池的生成规模n为20个。
实验按照超参数设定、日负荷曲线分类实验和用电行为数字特征画像及分类实验三部分展开。
5.1 超参数λ设定
为使优化选择集成策略获得较好的集成分类结果,设置超参数λ的调节范围从0.01到100,按照数量级改变其大小,结果如图6所示。
如图6所示,当λ增加到1时,基分类器个数(集成权重不为0)和集成分类精度损失达到拐点,此时基分类器个数和集成分类精度损失的下降量处在适中区间,低于1或高于1的量级取值,无法同时满足分类精度和集成模型复杂度的调节要求。为此超参数λ设定为1,选择保留的基分类器数目nose为9。

图6 超参数λ调节特性Fig.6 Regulation characteristics of super parameter λ
5.2 日负荷曲线分类实验
首先测试不同算法对于日负荷曲线分类的提升效果。分别对比SC + LSTM、SC + ALN-LSTMP、SC + SMOTE + ALN-LSTMP、SC + DBGS + ALN-LSTMP、SC + DBGS + Ensemble-ALN-LSTMP以及SC + DBGS + OSE-ALN-LSTMP的日负荷曲线分类效果,采用SI和DBI系数作为评价指标,如表1所示。上述各模块在表1中名称采用简写形式,分别为:SL、SA、SSA、SDA、SDE、SDO。
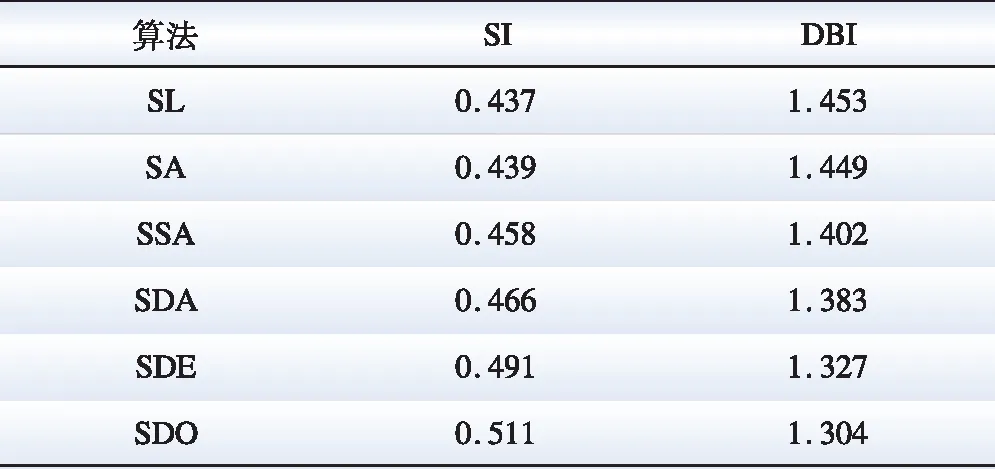
表1 日负荷曲线分类效果对比Table 1 Comparison of classification accuracy of algorithms
表1中,SA通过改进LSTM模型,使负荷曲线的分类效果得到整体提升;SSA和SDA在SA基础上通过过采样改善了类别不平衡问题对于分类器的影响,SI和DBI均有不同幅度提升,其中SDA分类性能更佳,验证了DBGS较SMOTE的优越性;SDE和SDO通过集成学习组合基分类器集群的分类结果,分类指标进一步提高,SDO因考虑了基分类器冗余问题,较SDE获得更好的分类效果。
其次,对比SC、常用分类器反向传播神经网络(back propagation neural network, BPNN)和卷积神经网络(convolutional neural network, CNN)以及SDO的分类效果(分类器均经过SC+DBGS处理),如表2所示。聚类算法与有监督分类算法相结合提升了负荷曲线类别的辨识度,较谱聚类具有更好的分类性能指标值,其中SDO的分类性能最佳。

表2 常用经典分类算法分类效果对比Table 2 Comparison of classification accuracy of algorithms
SDO的用户日负荷曲线分类结果如图7所示。

图7 负荷曲线分类结果Fig.7 Results of load curve classification
7类用户日负荷曲线代表了用户群体7种共性的用电行为,其中第1类和第2类日负荷曲线形态相似,但幅值差异明显,第1类负荷全天用电水平较低,第2类负荷晚间用电水平较高。第3类负荷午晚间用电水平较高,第4类负荷全天的用电水平较高。第5、6、7类日负荷曲线均呈晚高峰形态,但高峰时段分别集中在16:00、19:00以及20:00前后1 h的时间区间。用电幅值差异和负荷高峰时段分布差异显示了用户用电行为的多重多样性,精准把握这些细节特征,对电网企业针对目标用户开展更为精细的业务服务具有重要价值。提取SDO用户日负荷曲线分类结果中各类日负荷曲线的均值质心,作为典型日负荷模式,如图8所示。

图8 七类典型负荷模式Fig.8 Seven typical load patterns
5.3 用电行为数字特征画像及分类测试
统计450家用户2017年各类日负荷模式的发生频次在一年中的占比,近似估计其发生概率,构建维度等于日负荷模式类别数的数字特征向量作为用户画像,采用谱聚类算法对用户画像实施分类。各类用户的数字特征向量空间高维可视化窗口见附录图A1。
各类用户的数字特征画像呈现明显的群落分布特征,经过谱聚类划分为8类用户。附录图A1中:第1类用户负荷模式1的发生概率超过0.5,用电水平偏低,但其负荷模式5、6和7的发生概率平均达到0.13、0.15和0.12,存在较强的晚高峰特殊用电需求。第2类用户负荷模式1的发生概率接近0.8,全天用电水平较低,用电需求不活跃。第3类用户负荷模式2、5、6、7发生概率平均达0.2,晚高峰特殊用电需求较强。第4类用户负荷模式2、3的发生概率之和平均超过0.7,晚间用电水平较高;负荷模式5、6和7类发生概率平均为0.06,晚高峰特殊用电需求较弱。第5类用户负荷模式1、2和4的发生概率平均达到0.30、0.35和0.14,用电需求波动性较大,晚间用电水平较高,晚高峰特殊用电需求较弱。第6类用户负荷模式2、3和4的发生概率平均达0.18、0.33和0.30,全天用电水平较高,用电需求整体波动性较大。第7类用户负荷模式2和4的发生概率平均达到0.24和0.55,全天用电水平较高,用电需求整体波动性较大,在17:00—22:00用电需求较为稳定。第8类用户负荷模式3和4的发生概率平均达到0.20和0.55,全天用电水平很高,用电需求整体较为稳定。
基于用户分类结果,提取不同类用户的典型用电行为数字特征画像,结果如图9所示。就削峰型需求响应计划实施而言,第1、3类用户均具有较强的晚高峰特殊用电需求,适合参与激励型需求响应计划;第4、8类用户用电水平较高且较为稳定,同时适合参与价格型和激励型需求响应计划;第5、6、7类用户晚间用电水平均较高,但负荷需求波动性较强,预测和控制难度较大,更适合通过价格型需求响应计划引导其用电行为;第2类用户全天用电水平较低,不适合参与削峰型需求响应计划。

图9 8类典型用户画像Fig.9 Eight typical user portraits
为验证所提用户分类方法的优越性,与3种基于用电行为画像的用户分类方法对比各自的用户分类效果。3种用电行为画像方法均选用每位用户的一种典型日负荷模式(分别按数量最多、用电量最大以及负荷峰值最高选取[5])。被分为一类的用户用电行为正相关性越强表明分类效果越好,定义平均类内用户用电相关度ξ如下:
(27)
式中:U表示用户类别数;Nu表示第u类用户的数目;ρu(xp,i,xq,i)表示第u类用户中用户p和q一年中第i日负荷曲线的PCC值。ξ取值介于-1至1之间,值越大代表用户分类效果越好。
本文所提用户分类方法(M0)与上述3种基于不同用电行为画像的用户分类方法(M1:典型日负荷模式,按数量最多选取;M2:典型日负荷模式,按用电量最大选取;M3:典型日负荷模式,按负荷峰值最高选取)的ξ值如图10所示,用户分类实验共进行5次,红色曲线代表其均值。

图10 不同用户分类方法效果对比Fig.10 Comparison of user classification methods
图10中本文所提方法ξ值最高,平均达0.48。这表明,所提基于用电行为数字特征画像的用户分类方法兼顾用户对多元化用电行为的偏重差异,能促使每类用户达成更好的用电行为共识,分类效果更佳。
6 结 论
针对当前电力用户分类研究中用户用电行为画像结果片面、集成学习负荷分类中的基分类器冗余问题以及负荷类别不平衡问题,提出一种基于用电行为数字特征画像的电力用户两阶段分类算法。算例对比验证了所提DBGS、ALN-LSTMP以及OSE策略对负荷曲线分类性能提升的有效性以及所提SDO方法较传统LSTM、BPNN以及CNN分类模型的优越性。同时验证了基于用电行为数字特征画像的电力用户两阶段分类方法较传统基于用电行为画像的用户分类方法的优越性。分析表明,所提用户分类方法可实现电力用户多样性用电行为的显性化特征表达,其对于厘清用户精细化用电差异以及指导电网企业基于业务需求精准定位目标用户具有指导价值。
本文基于用户负荷数据开展用户用电行为画像和分类,并对需求响应潜力用户发掘作出了定性分析,后续将致力于多重用电关联影响因素下的用户用电行为画像及分类研究,并就需求响应潜力用户的定量评估与发掘开展深入研究。
