融合社交网络信息的长尾推荐方法
2022-02-17冯晨娇张凯涵梁吉业
冯晨娇 宋 鹏 张凯涵 梁吉业
在信息爆炸时代,用户难以高效地获取可能感兴趣的商品、服务等各类信息,同时,商家也难以准确地为目标用户展现相关的产品.因此,推荐系统逐渐成为一个重要的角色出现在亚马逊等电子商务网站.然而,现有的推荐算法常忽略冷门物品的推荐,即现有方法更倾向于推荐流行物品.
冷门物品,即长尾物品,具有独特的价值.首先,相比流行商品,长尾商品的边际效用更大,能为公司带来更高的利润,对于推荐系统来说,增加利润的关键在于长尾市场的开拓[1-3].Yin等[4]进一步解释,由于竞争对手以相同价格出售流行商品,导致这种商品的利润很低,而长尾商品恰恰相反,一旦成功被购置会使商家的收益增加.其次,长尾商品销售给用户带来更好的满意度.由于一站式购物便利效应,通过为客户提供一站式获取主流产品和利基产品的便利,可提高消费者满意度,使重复光顾成为可能.由于长尾商品推荐的重要性被人们广泛接受,Shi等[5]指出对长尾物品的推荐是推荐系统有效性的重要评测指标.
对于长尾物品而言,推荐难度在于数据稀疏程度更凸显,从现有研究进展上看,主要集中在聚类、多目标优化、二部图及消除流行偏差等.Park等[6-7]基于物品属性对长尾物品聚类,通过同类中长尾物品评分的共享,增加长尾推荐中可用的评分数目,运用已有的预测模型进行推荐.Grozin等[8]基于聚类方法,分组相似物品,并通过关联规则挖掘算法使用这种密集的数据表示,提高交叉销售推荐的质量.
随后,学者们开始尝试多目标优化方法,以多目标优化为出发点,将准确性、多样性、流行度、新颖性等不同指标按照一定的原则构建优化函数,实现在保证一定准确度的情况下提高推荐新颖性的折衷方案[9-13].此外也考虑利用附加信息(如用户评论、用户和产品属性、文本挖掘)挖掘用户的个性化偏好和长尾物品之间的关系.Johnson等[14]在二部图添加用户或产品属性额外的维度生成三部图,目的是利用该维度使随机游走具有更高的概率到达长尾物品.现有的消除流行偏差的主要方法是排名调整和无偏学习.Zhu等[15]对推荐列表进行事后重新排序.Abdollahpouri等[16]采用xQuAD(Explicit Query Aspect Diversification)改进版解决流行偏差问题,使系统设计者能对系统进行调优,达到预期的折衷目标.这两种方法都是启发式设计,旨在有意提高不太受欢迎的项目的分数,但缺乏有效性的理论基础.Liu等[17]采用因果嵌入模型,使用无偏均匀数据引导模型学习无偏嵌入,迫使模型丢弃物品流行度.然而,获取这种统一的数据需要将物品随机暴露给用户,存在损害用户体验的风险.尽管上述方法在一定程度上提高长尾物品的推荐效果,但均未考虑用户好友对长尾物品推荐起到的至关重要的作用.
Web 2.0时代的到来催生博客、P2P、维基、即时信息、社交网站等主要技术.这些技术在浏览网站的基础上,更注重用户之间的交互作用,为Web 2.0的蓬勃发展带来巨大的动力.社交媒体、社交网络、社交标签等网络应用的普及催生一个特殊的应用——社会化推荐.社会化推荐是建立在社会选择和社会影响效果基础上的推荐算法.社会选择是指人们倾向于接触具有相似属性的人,并且由于社会影响,社会网络中的相关个人互相影响变得更相似[9].如何有效融合两者之间的信息成为社会化推荐的核心问题.基于近邻的社会化推荐[18]是一种直观的做法,即利用社交网络中两位用户之间共同的好友数量计算用户之间的相似度,将其与传统的相似度结合后再进行近邻推荐或引入矩阵分解推荐方法中.基于图的社会化推荐[19-20]结合用户和产品的二分图与用户的社交网络图,产生表示社群的新节点后,再进行基于图的推荐.
上述两种融合策略因涉及用户数目庞大,给在线学习带来一定困难,而融合社交信任网络的矩阵分解方法由于其可扩展性及灵活性较高等特点被广泛使用.一些学者将社交网络与评分矩阵共享用户潜在特征矩阵,并有机结合两者[21-24].还有些学者通过社交网络将用户潜在特征矩阵重表示后,再进入矩阵分解环节[25-31].
从现有研究进展上看,上述方法的出发点是更多地追求推荐精度,而社会化推荐不单是追求精度,可通过好友的可信任推荐增加冷门物品的点击率.本文试图通过概率图模型的因果关系表示优势,将社交网络作为影响长尾推荐的一个重要影响因素有机融入推荐方法中,从而在保持精度的前提下,提高长尾物品的推荐效果.鉴于上述分析,本文提出融合社交网络信息的长尾推荐方法(Long Tail Re-commendation Method Based on Social Network Infor-mation, LTRSN),将用户活跃度、项目非流行度、用户项目偏好水平及好友推荐行为作为输入,采用变分推断方法得出模型中相关未知参数,实现预测功能.实验表明,文中方法能在有效实现长尾物品推荐的同时,保证较高的推荐精度.
1 参数定义
设G=(U,ε)为一个社交网络,其中
U={u1,u2,…,um}
表示用户节点集合,ε⊆U×U表示用户和用户之间的信任边.在社交网络中节点和节点之间的边通常为有序对(ui,uk),其中,ui表示信任者,uk表示被信任者.使用链接矩阵T=(tik)表示ε中边的结构:tik=1表示用户ui信任用户uk;tik=0表示用户ui、uk之间无信任关系.进一步,利用社交矩阵T可计算两位用户之间的社交关系强度,本文采用杰卡德相似度计算用户社交关系强度矩阵S=(sik),其中,sik表示用户ui、uk之间的社交关系强度.物品集合V={v1,v2,…,vn},用户与物品之间的评分矩阵R=(rij)m×n,rij为第i个用户ui对第j个物品vj的评分.评分通常采用5分制,1分表示最弱的偏好,5分表示最强的偏好.
2 融合社交网络信息的长尾推荐方法
社交信息不仅对用户的评分有影响,同时,对于长尾物品的推荐也有重要的推动作用,因此,本文从两方面融入社交网络信息:一方面,社交网络和评分矩阵共享用户的潜在特征向量;另一方面,社交网络中的好友推荐是长尾物品推荐的重要影响因素.
2.1 生成过程
融合社交网络信息的长尾推荐方法(LTRSN) 是一种融合评分矩阵和社会化信息的概率图模型.具体生成过程如图1所示.图中:□表示超参数;表示观测变量;○表示隐变量,即不可观测变量,但是对系统状态和能观察到的输出存在影响,故称为隐变量;有向边表示概率依存关系;矩形表示重复;数字表示重复次数.

图1 LTRSN概率图模型Fig.1 LTRSN based probability graph model
生成过程解释如下.



p(xij|ci,dj,zij,θij0=1)~B(σ(cidjzij)).
社交网络对xij的影响是指第k个好友生成
其中k=1,2,…,|fi|,η=(η0,η1).

3)影响长尾物品推荐的各部分权重βi生成θij.假设θij~Mult(βi),βi作为θij的先验服从狄利克雷分布,即βi~Dir(α),其中
α=(α0,α1,…,α|fi|),
βi=(βi0,βi1,…,βi|fi|),
θij=(θij0,θij1,…,θij|fi|).
2.2 变量描述
本文模型中的变量分为用户、物品和社会网络3类.
对于第i位用户:
4)用户自身偏好选择长尾物品和好友推荐长尾物品的权重βi~Dir(α),

对于第j个物品:

对于每个评分rij:
2)用户-物品偏好水平

4)贡献变量θij.
对于每个社交关系强度:
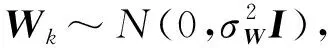

2.3 变分推断
本文采用平均场理论进行变分推断,目标是学习隐变量的后验概率分布的参数.首先给出观测变量和隐变量组合的联合概率分布及变分分布,得到证据下界表示.然后,推导目标函数的梯度,实现变分参数学习.最后,预测未知评分.
定义偏好z=(zij)m×n,用户偏置a=(a1,a2,…,am),物品偏置b=(b1,b2,…,bn),用户活跃度c=(c1,c2,…,cm),物品非流行度d=(d1,d2,…,dn),用户潜在特征向量U=(U1,U2,…,Um),物品潜在特征向量V=(V1,V2,…,Vn),用户潜在社交特征向量W=(W1,W2,…,Wm).概率图模型作为生成模型,首先考虑观测变量和隐变量组合的联合概率分布,设为p(R,x,T,S,Θ),其中,Θ={z,a,b,c,d,U,V,W,θ,β,η}为隐变量,R、x,T、S为观测变量.联合概率分布定义如下:

(1)
本文目标是求得后验概率p(Θ|R,x,T,S).
为了降低计算复杂度,目标变换为寻找q(Φ),使KL散度D(q(Φ)‖p(Θ|R,x,T,S)达到最小,称q(Φ)为变分分布,Φ为变分参数.q(Φ)通过平均场的假设变得清晰简单,下面介绍平均场变分推断.
此处平均场理论假设变分参数相互独立(贝叶斯理论中这些参数实际是条件独立的),即满足
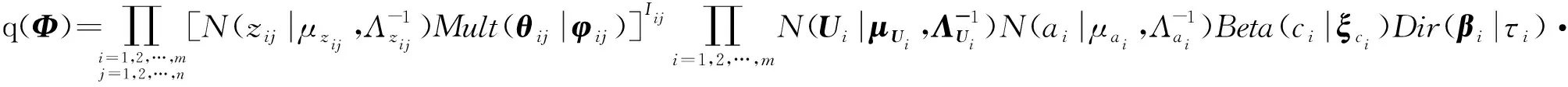
(2)
其中,Φ为变分参数,
变分推断最小化KL散度等价于用它最大化证据下界[33].证据下界为
L(q)=Eq(lnp(R,x,T,S,Θ))-Eq(lnq(Φ)).
证据下界包括两部分:1)对数似然函数关于变分分布q(Φ)的期望,2)变分分布q(Φ)的对数函数关于自身的期望,Eq(·)表示数学期望是对q(Φ)定义的.
由式(1)得

由式(2)可得
最终,可得到证据下界L(q),其中
利用全概率公式、Jensen′s不等式和对数函数的高斯下界[34]:
σ(x)≥h(x,ξ)=

且x=ξ时到达一致下界.故


根据上述计算,将证据下界L(q)中的
其它项可用类似方法求出期望,由于篇幅问题在这里不再赘述.
对于参数ξij,利用文献[34]的结论,有
ξij=Eq((cidjzij)2),
得到ξij的估计:
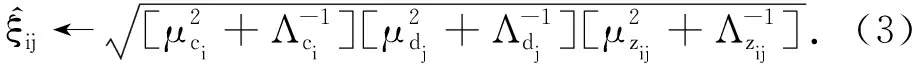
将ξij的估计代入高斯下界公式,得到λij的估计:
(4)
令偏导等于0,得到Λzij的估计:
(5)
其它参数估计方法类似,不一一详细计算,具体结果如下:
(6)
[(τi0-1)ψ(τi0)-
(7)
k=1,2,…,|fi|,
(8)
(9)
(10)
(11)
(12)
(13)
(14)
(15)
(16)
(17)
(18)
(19)
(20)
(21)
(22)
基于上述梯度,给出融合社会化信息的长尾推荐方法,步骤如算法1所示.
算法 1融合社交网络信息的长尾项推荐方法
输入R,x,T,ρ
输出变分参数Φ
从社交矩阵T计算社交关系强度S
随机初始化全局变分参数
Whileiter iter=iter+1 初始化局部变分参数 forrij∈Rdo While 不收敛 do end for fori=1,2,…,mdo end for forj=1,2,…,ndo end for fork=1,2,…,mdo end for end While 当所有参数更新完毕,得到最优q*(Θ),预测第i名用户对第j个产品的评分: 为了验证本文方法,实验数据集需要同时包含社交网络和评分矩阵,本文采用社会化推荐常用的FilmTrust、Epinions公开数据集.FilmTrust 数据集是2011年6月从整个FilmTrust网站上抓取的一个数据集,包含1 641 位用户,2 071部电影,35 497 个评分,1 853 条社交关系.评分范围为0.5~4,步长为0.5.Epinions数据集是2003年从评价网站Epinions上收集的数据集,包含49 290位用户,139 738部电影,664 824个评分,487 183条社交关系.评分范围为1~5,步长为1.2个数据集均是单向信任关系. 本文利用巴莱多定律(也叫二八定律)将电影分为热门电影和长尾电影.具体方法是将电影按照评分数量由高到低排列,取后20%的电影为长尾电影[35]. 本文选择如下5个指标刻画长尾推荐性能:与准确性相关的平均绝对误差(Mean Absolute Error, MAE),均方根误差(Root Mean Squared Error, RMSE),召回率(Recall),精确度(Precision),与流行度相反的新颖性(Novelty)[22].具体指标计算公式如下: 其中:|·|表示集合中元素的个数;Rtest表示五折交叉验证法中,随机选择出的一折测试集;Iu表示面向用户u推荐的前k个物品集合;Tu表示测试集上面向用户u推荐的物品集合;Lu表示用户u的topN列表;Ui表示曾对物品i评分的用户的集合. 在这5个指标中,MAE、RMSE、Recall、Precision均采用五折交叉验证方法.Novelty表示推荐结果的平均流行度,值越小,推荐结果越新颖.为了降低随机初始化导致的误差,本文在计算新颖性时,重复10次取平均值. 为了说明本文方法的有效性,选择如下对比方法. 1)PMF(Probabilistic Matrix Factorization)[36].已知用户评分,给出用户潜在特征和物品潜在特征的后验概率,并以对数后验概率最大化为目标函数,得到用户和物品的潜在特征向量的估计值,通过它们的内积预测未知评分.PMF没用融合社交信息,本文把PMF作为基准预测. 2)SoRec(Social Recommendation Using Probabilistic Matrix Factorization)[21].在上述PMF的基础上增加社交关系矩阵,通过共享用户特征向量联合分解评分矩阵和社交关系矩阵,达到两种信息的有效融合.SoRec的社交关系强度sik通过用户连接关系度计算[38]. 3)RSTE(Recommendation with Social Trust Ensemble)[25].在SoRec的基础上将目标用户好友的偏好与自身偏好进行加权平均,同时考虑目标用户及其好友对同一物品的综合影响. 4)SocialMF(A Matrix Factorization Technique with Trust Propagation for Recommendation in Social Networks)[26].基于信任传播机制,认为目标用户的偏好较大程度上由其好友的偏好决定,相应地,基于好友特征向量的加权平均表示目标用户特征向量,并引入模型的目标函数中. 5)SoReg(Recommender Systems with Social Regularization)[27].与SocialMF类似,同样在PMF的基础上添加社交正则项,区别在于SoReg对具有不同关系强度的好友进行区分. 6)TrustMF(Social Collaborative Filtering by Trust)[22].将社交矩阵分解为信任和被信任双向关系,将用户潜在社交特征向量分为信任者特征向量和被信任者特征向量,类似SoRec建模. 7)TrustSVD(A Trust-Based Matrix Factorization Technique)[28].将SVD++融入社交信息的推广,即将社交矩阵的显式关系作为隐式反馈信息加入SVD++中. 8)面向长尾推荐的三因素概率图模型(Three- Factors Based Probability Graph Model, TFPGM)[32].基于用户活跃度、项目非流行度和用户-项目偏好水平因素的概率图推荐方法. 9)FPMF(A Fusion Probability Matrix Factorization)[38].融合局部相似度信息和全局评价信息的概率矩阵分解方法. 在实验中,潜在特征空间维数设置为10,迭代步长均为0.01,迭代100次停止. 为了验证本文方法(LTRSN)的有效性,基于如下3类指标分析实验结果. 第1类指标是从用户预测评分误差的角度对比方法性能.不同方法在FilmTrust、Epinions数据集上的性能对比如表1所示.由表1可看出,在2个数据集上,本文方法的MAE、RMSE值仅次于TrustSVD和FPMF,均优于其它方法.这是因为TrustSVD在融合社交信息时利用SVD++的思想,而SVD++将评分矩阵看成隐式反馈和显式反馈两种信息的表现.类似地,TrustSVD将社交矩阵也分为隐式反馈和显式反馈,同时加入用户、物品偏置以优化预测评分.这些原因综合促成方法在预测误差方面性能最优.而FPMF是融合局部信息和全局信息的概率矩阵分解方法,信息全面,精度较高.本文方法沿用用户、物品偏置的概念,利用社交矩阵的显式反馈等信息,结果优于其它方法.之所以差于TrustSVD是因为添加用户活跃度、物品流行度等因素,增强长尾物品的推荐,从而在一定程度上降低预测误差.此外,从PMF的MAE、RMSE值可知,大多数情况下PMF劣于其它方法,这说明社交信息的融合在一定程度上可提高预测精度. 表1 不同方法在2个数据集上的性能对比Tabel 1 Performance comparison of different methods on 2 datasets 第2类指标是从排序的角度出发,给出topN推荐.各方法在FilmTrust、Epinions数据集上的召回率对比如图2所示.由图可知,在FilmTrust数据集上,本文方法在召回率上仅劣于TrustSVD和FPMF,优于其它方法.在Epinions数据集上,本文方法在召回率上优于所有方法. 各方法在FilmTrust、Epinions数据集上的精确度对比如图3所示.由图可知,在FilmTrust数据集上,本文方法的精确度劣于SoReg、TrustSVD、TFPGM,但优于其它方法.在Epinions数据集上本文方法的精确度劣于SoReg、TrustMF,但优于其它方法. 综合图2和图3,说明本文方法对于topN推荐是有一定优势的. (a)FilmTrust (b)Epinions图2 各方法在2个数据集上的召回率对比Fig.2 Recall comparison of different methods on 2 datasets (a)FilmTrust (b)Epinions图3 各方法在2个数据集上的精确度对比Fig.3 Precision comparison of different methods on 2 datasets 第3类指标是物品推荐的新颖性度量,定义为流行度的对立面,即长尾物品推荐的性能.由于SoReg 和TrustSVD在FilmTrust数据集上新颖性远大于其它方法,即长尾推荐效果明显劣于其它方法,因此不做对比.在Epinions数据集上,TrustSVD的长尾推荐效果显著劣于其它方法,因此不做对比.各方法在FilmTrust、Epinions数据集上的新颖性对比如图4所示. 由图4可看出,本文方法在2个数据集上均优于其它对比方法.这是因为本文方法添加长尾物品推荐的影响因素,有效提升长尾推荐性能. (a)FilmTrust (b)Epinions图4 各方法在2个数据集上的新颖性对比Fig.4 Novelty comparison of different methods on 2 datasets 本文从信息融合视角出发,基于社交矩阵和评分矩阵,提取长尾物品的重要影响因素,即用户活跃度、物品流行度、用户-物品偏好水平和好友推荐.在此基础上,面向长尾物品推荐任务,提出融合社交网络信息的长尾推荐方法(LTRSN).本文通过平均场理论降低模型的复杂表示,采用变分推断方法优化目标函数,得到变分参数的估计,并通过参数的估计预测未知评分.在2个具有社交信息的FilmTrust、Epinions公开数据集上进行算法的对比分析.实验表明,LTRSN在促进长尾物品推荐方面较有效,同时保证较高的推荐精度,这也进一步说明社会化信息融合的重要性.
2.4 概率推断
3 实验及结果分析
3.1 实验数据集
3.2 评价指标
3.3 对比方法
3.4 实验结果





4 结 束 语
