一种基于3×3卷积堆叠的残差结构
2022-02-16胡秀建
胡秀建
(亳州学院 电子与信息工程系, 安徽 亳州 236800)
0 引言
2015年来自微软实验室的He Kaiming等人提出了残差结构并设计ResNet深度神经网络模型[1], 斩获了ILSVRC2015挑战赛中分类任务第一名和目标检测第一名, 并获得COCO数据集中目标检测第一名和图像分割第一名. 残差结构对深度神经网络模型设计产生深远影响, 随后出现了很多基于残差结构以及相关变体的算法模型, 比如ResNetV2[2]、 WResNet[3]、 DenseNet[4]、 ResUnet++[5]、 ConvNeXt[6]等, 并在计算机视觉领域的各个下游任务中均有出色的表现. Ross Wightman等人通过大量的优化实验再次证明了残差结构的优势[7]. Vision transformer(ViT)的引入很快取代了卷积神经网络成为最先进的图像分类模型[8], 然而ViT在应用于一般的计算机视觉任务(如对象检测和语义分割)时面临困难. 分层的transformer(例如Swin transformer)重新引入了几个卷积神经网络的先验[9], 使得transformer实际上可以作为通用的视觉主干, 并在各种各样的视觉任务中表现出显著的性能. ConvNeXt重新审视了设计空间, 并测试了纯粹的“卷积神经网络”所能达到的极限, 在准确性和可扩展性方面优于transformer, 证明了全卷积神经网络的性能依然强大.
全卷积网络的特征提取能力与卷积核尺寸大小密切相关, 大的卷积核将获得更大的感受野, 能提取准确的高级特征, 而小的卷积核在降低网络参数和计算量方面有更大优势, 而超大卷积核并不适应于较小尺寸的图像任务. 为了提高网络的鲁棒性, 本系统采用了3个Conv3×3卷积堆叠来设计新的Base残差结构, 以替换ResNet中的2个Conv3×3卷积和Conv1×1+Conv3×3+Conv1×1的组合.
本文旨在验证新的残差结构的优异性能, 主要贡献包括以下3点:
1.提出了基于3个Conv3×3堆叠的残差结构以及一系列变体, 其在通道信息融合、 空间特征提取方面有着出色的性能表现.
2.将恒等映射中的Conv1×1改为Conv3×3,网络性能有着显著的提升.
3.基于新的残差结构设计的较浅层的卷积神经网络性能超过了诸多的深层网络, 网络结构有着进一步优化的可能, 可为视觉分类任务以及其他下游任务提供更大改进的空间.
1 相关工作
1.1 残差网络
神经网络性能指标主要包括神经网络的深度(deepth)、 宽度(width)、 参数量(parameters)和计算量(FLOPs). 增加网络宽度带来的成本远比增加网络深度大, 但是增加网络深度又给优化带来困难[10], 这是因为梯度反向传播的路径增长而导致的梯度消失, 从而加大了网络训练难度. 这种随着网络深度的增加而使得训练误差越来越多的现象被描述为网络退化.残差结构不仅有助于解决梯度消失问题, 还可以解决梯度爆炸问题, 即使大幅度提升网络深度也能有稳定出色的性能表现. 残差单元的设计是通过具有恒等映射功能的跳跃链接来完成的. 在ResNetV2中, 作者又对残差结构做了调整, 并证明了采用前标准化方法的残差结构性能更出色.
ResNet浅层网络中特征提取路径采用2个3×3卷积堆叠的组合方式来实现, 而在深层网络中采用Conv1×1+Conv3×3+Conv1×1卷积的组合以增加网络深度, 同时没有大幅增加参数量. 本文经过实验证明, 在残差结构中, 除了标准化、 激活函数以外, 恒等映射和特征提取路径中的卷积操作也是可优化的, 并提出了新的完全基于3×3卷积的残差结构(图1).

图1 Base残差结构与ResNetV1和ResNetV2结构比较
1.2 结构优化
在视觉任务中, 深度神经网络的性能表现依赖于其低级特征和高级特征提取能力. 对于一个(B,C,H,W)的输入, 将通道信息和空间信息进行充分融合, 有利于提高网络的特征提取能力. 采用FCNN(全卷积神经网络)设计网络架构, 卷积核大小、 网络深度和宽度一直是网络结构优化所考虑的重点. 尺寸为7×7大小的卷积核的有效性在ConvNeXt中得到最新验证[6], 采用更大尺寸的卷积核以发挥卷积神经网络更高性能, 其可在最新的研究成果中得到体现, 比如将卷积核尺寸设置为31×31[11]. 然而, 显而易见的是卷积核大小与图像的尺寸需要保持一定的适配性, 比如Cifar10和Cifar100数据集的图像尺寸为(32,32), 采用大尺寸的卷积核不能提取有效的特征信息. 3个3×3卷积的堆叠不只是获得了与7×7尺寸大小相同的感受野, 在通道信息的融合和特征提取能力等方面, 其明显优于后者.
在网络深度和宽度选择方面, 深度神经网络更倾向于增加网络深度以提高网络性能的同时而没有大幅增加计算成本[12-14], 但随着算力的提升, 在一定程度上提高网络宽度所带来的网络性能的提升是显著且必要的[3].
2 网络模型设计
为了验证Conv3×3卷积堆叠的性能表现, 本系统在网络模型设计上参照ResNet的网络模型结构, 设计了一个Base网络结构作为参照, 并结合组卷积、 可分离卷积、 拓宽通道、 通道膨胀、 添加通道注意力和空间注意力等技术设计了一系列Variant网络结构, 以对比3个Conv3×3卷积堆叠的低级特征和高级特征提取能力.
2.1 网络结构设计
为了与ResNet及其他主流网络进行公平的对比, 网络结构沿袭了ResNet的设计思路, 重新设计了基于残差结构的新的基础网络模型. 该网络结构首先是由一个3×3卷积构成的root模块, 其功能仅仅是将输入图像通道数变为64, 并没有进行2倍下采样. 然后设计了4个网络层, 每一层都都由若干个残差块堆叠而成并完成对原有通道数扩大2倍, 其中第一层的2倍下采样是可选的, 后面三层进行2倍下采样. 最后是一个分类器Classifier完成分类输出(图2).

图2 Base网络结构
为了较为完整地展示网络的性能, Base网络模型的设置采用了固定的网络宽度, 每一层(包括root模块)网络输出的宽度为[64,128,256,512,1024], Layers中的Residual Block的数量、 其参数量和计算量见表1. 我们采用了torchsummary工具估计参数量、 thop工具估算计算量FLOPs, 由于root模块包括一个Conv3×3卷积, 因此每一个尺度的网络模型其卷积层个数都加上2.
从表1可以看出, 网络层从14增加到29, FLOPs增加了大约1倍, 参数量增加了约42M.

表1 不同级别的基础网络结构
2.2 Variant网络结构设计
为了对比基于3个3×3卷积堆叠而设计的残差结构网络的低级特征和高级特征提取能力, 本系统主要从网络轻量化、 融合通道信息、 添加注意力机制等三个方面设计了一系列的Variant网络模型, 其中6个Variant是ResidualBlock结构变体(图3), 5个Variant是网络结构变体.
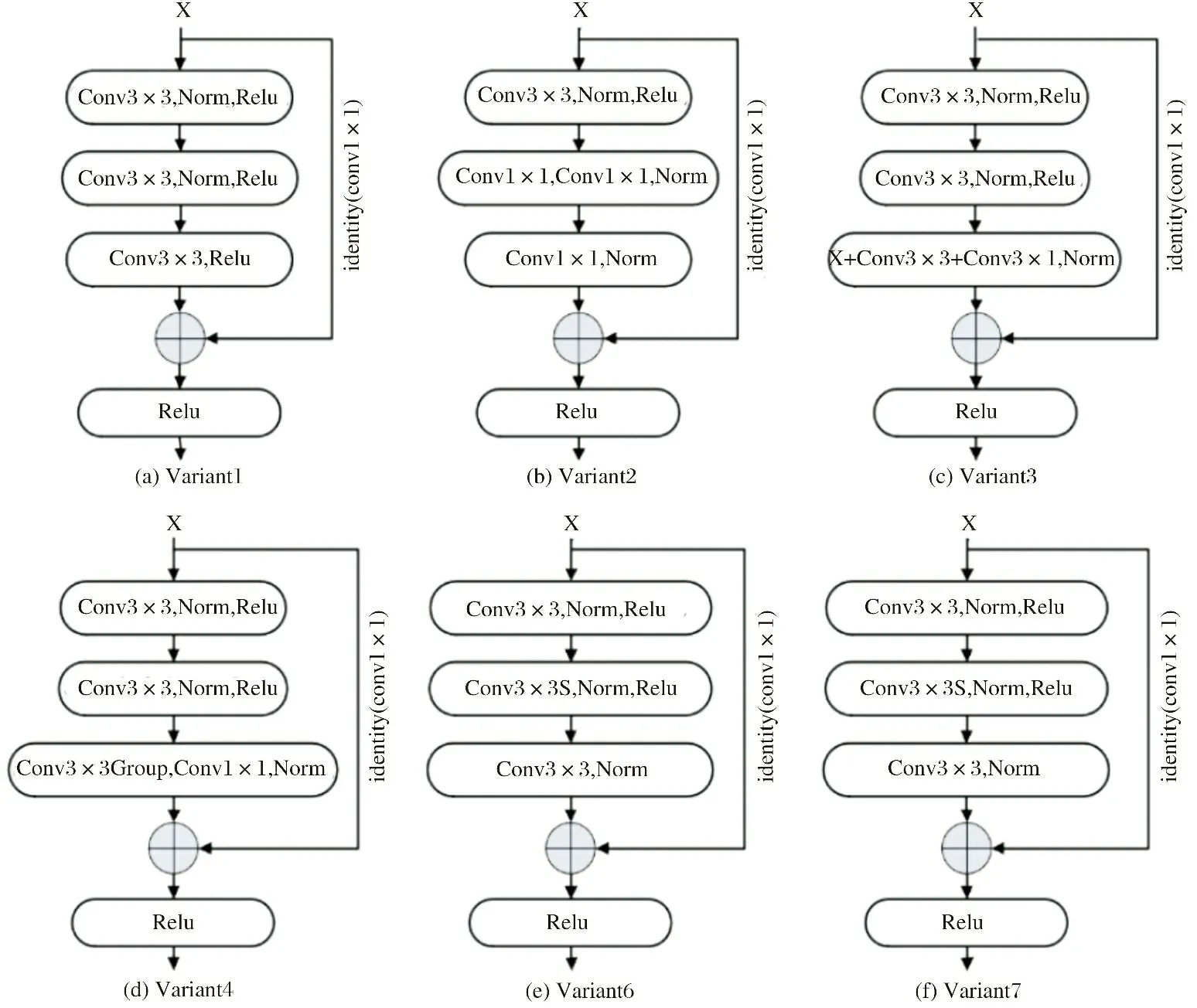
图3 ResidualBlock变体结构
Variant1(V1)修改了Base网络结构中ResidualBlock的恒等映射, 将Conv3×3卷积改成Conv1×1卷积. Variant2(V2)恒等映射采用了Conv1×1卷积, 用Conv1×1+ Group Conv3×3+Conv1×1替换ResidualBlock中的第二个和第三个Conv3×3. Variant3(V3)采用了非对称卷积Conv1×3+Conv3×1替换ResidualBlock中的第三个Conv3×3. Variant4(V4)在V1基础上做修改, 采用Group Conv3×3+Conv1×1替换ResidualBlock中的第三个Conv3×3. Variant5(V5)借鉴了ConvNe×t的膨胀操作, 在每一个layer之间增加了一个4倍通道膨胀模块. Variant6(V6)的恒等映射采用Conv1×1卷积, 在ResidualBlock中增加了膨胀和挤压操作, 通过第一个卷积操作将通道扩大到一个中间值(mid = out+ (out - in) / 2), 然后通过第二个卷积操作将通道数降低到out. Variant7(V7)在V6的基础上将恒等映射的Conv1×1改为Conv3×3. Variant8(V8)在每个layer之间增加了通道注意力机制. Variant9(V9)在Base基础上每个layer之间增加了CBAM[15](通道注意力+空间注意力). Variant10(V10)在V6基础上每个layer之间增加了通道注意力机制. Variant11(V11)在V6基础上增加了空间注意力机制.
与基础网络结构保持一致, 每个网络结构变体按照layers中的残差块的个数分别设置了5个不同级别, 表2分别给出了10个变体网络的Tiny_B和Deep_B模型级别的参数量和FLOPs.
3 实验
网络模型的主要性能取决于网络模型架构的设计、 训练超参数的设置以及数据增强技巧等三个方面的因素[7]. 模型之间性能的对比还需要考虑网络模型所面向的任务以及基准测试平台, 完全相同的实验环境和超参数设置也不能反映网络模型性能的真实差异, 迄今为止都没有统一的标准和方法来衡量网络模型对比的公平性[7]. 为了保证最大可能的公平性和凸显网络模型架构之间性能的差异, 本系统采用了统一的最朴素的方法对网络模型进行训练.
实验在Python3.8.6、 Pytorch1.8.2和Cuda11.2的环境上采取数据并行运算方式在2块GPU为Nvidia 3090的机器上进行网络模型训练. 基准测试平台为Cifar10和Cifar100数据集, 参数Epoch=150, Batchsize=128, momentum=0.9,weight_decay=5e-4优化器选择SGD, 初始学习率全部设置为0.1, scheduler=MultiStepLR, milestones=[60,100,130],gamma=0.1.
3.1 消融实验
在消融实验中相对于Base网络结构设计了11个Variant网络结构(表2), 挑选了6个全局随机种子对Base网络结构进行稳定性测试, 其他的实验全局随机种子seed均设置为1234.

表2 网络结构
3.1.1 Base网络结构稳定性测试
与上述的实验设置一致, 选择了6个全局随机种子在Cifar100数据集上通过测试. Base网络结构的Tiny_B测试结果见表3.

表3 稳定性测试Base Tiny_B
在6个不同随机种子情况下平均训练123个epoch便可获得78.49%的平均精度, 精度值上下浮动大约0.3%.
3.1.2 网络轻量化
V1结构比Base结构的参数量减少了21.25M, 但在5个不同尺寸的模型上精度平均下降了1.41%. V2在V1基础上做修改, 采用Conv1×1+ GroupConv3×3+Conv1×1, 其参数量有大幅下降, 与Base相比精度平均下降1.63%, 但与V1相比性能接近. V3在Base基础上做修改, 采用非对称卷积, 性能平均提升了0.3%, 同比最大提升了0.89%. V4在V1基础上做修改, 参数量有大幅下降, 与Base相比精度平均下降1.01%, 与V1相比性能平均提升0.4%, 同比最大提升了0.65%. 表4数据表明, 恒等映射中使用Conv3×3其性能远超Conv1×1, 在保证感受野不变的情况下降低参数容量, 采用GrupConv3×3+Conv1×3+Conv3×1和GroupConv3×3+conv1×1替换最后一个Conv3×3卷积的做法是有效的, 且GroupConv3×3+conv1×1降低参数量的幅度更大. 将V4结构中的恒等映射Conv1×1卷积改成Conv3×3, 其性能在理论上还有进一步提升的空间, 因此保留了V3和V4的结构设计.

表4 组卷积、 1×1卷积、 对称卷积实验结果
3.1.3 融合通道信息
借鉴了ConvNeXt的做法, 在layer之间添加了SE模块(V5), 随着网络深度的增加其性能逐渐提升, 其超越Base结构约0.5%. 在ResidualBlock内增加网络宽度(V6)提升了网络模型的性能, 而在layer之间对通道信息进行SE(压缩扩展)操作并没有带来性能的提升, 反而拉高了网络模型的容量和计算量. 在V6的基础上将恒等映射中Conv1×1卷积改成Conv3×3卷积(V7), 总体进一步提升了网络的性能, 与Base结构相比同比最大提升0.98%. 实验数据表明在融合通道信息能力方面 V5与V6、 V7相比没有优势, 并进一步证实了将恒等映射中Conv1×1卷积改成Conv3×3卷积能提升网络性能表现.

表5 融合通道信息实验结果

表6 在Base和V6上增加注意力机制模块实验结果
3.1.4 添加注意力机制
经验性地认为添加注意力机制模块是有效的[16-17]. 本实验中, 在网络结构中添加空间注意力和通道注意力, 以观察网络性能的表现[17-18]. V8、 V9以Base模块为残差块分别在layer之间添加通道注意力机制和CBAM[15-17], V8、 V9与Base相比性能却是下降的. V10、 V11以V6为残差模块在layer之间分别增加了通道注意力与空间注意力机制, V10与Base和V6相比, 性能出现了下降, 增加了空间注意力的V11比Base性能稍有提高, 但与V6相比其性能也趋于下降. 实验结果表明, 通道注意力和空间注意力机制对Base和V6残差结构不能起到提升性能的作用, 进一步表明3个Conv3×3堆叠的残差结构在通道融合能力和空间特征提取能力方面已经足够出色.
通过以上的实验发现, 基于Conv3×3堆叠的残差结构有着出色的性能表现, 在通道信息融合和空间特征提取方面不需要额外的注意力机制, 且在不降低感受野的情况下可以对网络进行轻量化并能得到出色表现. 此外, 在多个变体结构中, 恒等映射中使用Conv3×3替换Conv1×1均获得了性能的提升. 为此, 我们保留了Base、 V3、 V4、 V6、 V7等五个残差结构并将对之进一步组合优化.
3.2 与主流网络模型对比
在本实验中挑选了Base、 V3、 V4、 V6、 V7与Vgg19bn[13]、 ResNet18、 ResNet50、 ResNeXt50[19]、 GoogLeNet[20]、 MobileNetv2[21]、 SeResNet50[22]、 ShuffleNetv2[23]等主流分类网络做了充分的对比, 还对比了根据原著论文的超参数设置以及训练方法的实验结果[24], 以验证基于3×3卷积堆叠的残差结构在ResNet网络结构中的性能表现.
在相同的训练参数条件下, 在Cifar10数据集上我们的网络模型性能表现全面超出了Vgg19bn、 ResNet18、 ResNet50、 ResNeXt50、 GoogLeNet、 MobileNetv2、 SeResNet50、 ShuffleNetv2等主流网络, 轻量化模型V3和V4取得了与ResNet18V2相近的精度值, 但在Cifar100上V3_Tiny-B比ResNet18高出0.74%、 比V3_Deep_B高出2.04%.
在Cifar100数据集上对比150个epoch训练的实验结果, V6_Deep_B最多超出ResNet50[1]3.08%, 最多超出ResNeXt50 1.38%, 最多超出SeResNet152[22]0.29%, 这是在没有进行大规模提高网络深度的情况下取得的性能表现, 其网络结构还可以进一步优化组合并提升性能.

表7 在Cifar10和Cifar100上运行训练结果比较
4 结论
本文旨在验证Conv3×3堆叠的残差结构在通道信息的融合和空间特征的提取方面的性能表现, 并设计了一系列残差结构及网络变体, 在Cifar10和Cifar100数据集上, 相对于目前主流的轻量级网络、 深层网络等有着优异的性能表现. Cifar100数据集每个类有600张大小为32×32的彩色图像, 其中500张作为训练集、 100张作为测试集[24], 相较于ImageNet其数据量和图像尺寸更小[25], 因此选择Cifar100数据集作为基准测试平台能反映不同网络之间的性能差异. 卷积神经网络模型的通道信息融合能力和空间特征提取能力决定着分类的性能, 并对下游视觉任务产生重要影响, 在设计网络模型时感受野的大小应与图像尺寸保持一定的适配关系, 采用Conv3×3堆叠的残差结构能在提升感受野的同时保持着较强的通道信息融合能力.
