基于深度学习的车辆检测算法之特点分析
2022-02-16朱东弼
刘 哲 朱东弼
(延边大学,吉林 延吉 133002)
0 引言
随着科学技术的日益更新,家家户户的生活水平直线上升,私家车数量在不断增加,因此智能交通系统的概念被提出。车辆检测是智能交通系统的关键部分,对减少交通拥堵,减少交通事故的发生以及辅助驾驶应用都有着重要的意义。
车辆检测方法一般可分为传统的车辆检测算法和基于深度学习的车辆检测算法。传统的目标检测算法大多需要人工设计特征,精度差、模型鲁棒性不强。近年来,计算机视觉领域主要采用的是深度学习理论,现有的目标检测算法比较经典的主要分成两类:一类是Two Stage算法,如R-CNN、Fast R-CNN、Faster R-CNN;另一类的目标检测算法是One Stage,如YOLO系列,SSD算法。本文将对三种有代表性的车辆检测算法Faster R-CNN算法、YOLOv3算法、SSD算法的特点进行分析。
1 基于Faste r R-CNN的车辆检测算法分析
2015年Faster R-CNN算法问世,该算法检测框的生成使用了区域建议网络(Region Proposal Network,RPN),新的RPN会更快更有效地生成ROI[1],让目标检测又向前迈进了一大步。Faster R-CNN由四部分组成,分别是特征提取网络、RPN网络、ROIpooling(池化)层、分类与回归。特征提取网络由卷积层、池化层、激活层构成,首先将车辆图片输入,会经过13个卷积层和激活层,使用的激活函数是Relu,同时会经过4个池化层,每一个池化层会把图片变成原来的1/2,最后图片就变成了原图的1/16,这样就提取出了车辆图片的feature maps(特征),常用的特征提取网络有ResNet、VGG等。这些feature maps分为两个走向:第一个是直接映射至ROIpooling层,另一个则是通过RPN来生成候选区域。特征图输入至RPN中,为了集中特征信息首先进行3*3卷积。接下来同样有两个分支,一个分支我们手动定义一个base_anchor则会生成9个Anchor box,即特征图上的每个像素点会有9个Anchor box,使用softmax对其筛选出含有车辆目标的[2]。去掉超过原图边界线上的Anchor box,设置合适的IOU阈值,对于范围外的Anchor box也去掉,对剩下的检测框进行标记。另一个分支,我们可以得到每个anchor的四个坐标信息:中心位置(x,y)、宽w、高h,将计算得出的anchor box与ground truth的坐标信息偏移量训练学习,使用边框回归 (bounding box regression)方法对这四个坐标信息变化量进行回归,可以从fg anchors得出proposal大致位置。接下来在Proposal层再次生成anchors,并对其使用bbox回归,从而得到更加准确的proposals。ROIpooling层的输入是之前得到的特征图和proposals,将region proposal映射至特征图中,在将这个区域划分为7*7份,从而会有许多个固定长度的7*7feature map,这些固定长度的feature map是全连接层的输入。最终利用全连接层和softmax对车辆种类识别,并回归出准确的预测框得到位置。
Faster R-CNN检测精度较高,鲁棒性强,代码开源,方便使用。但是网络容易丢失原始图像的空间结构信息,而且两阶段网络的速度较慢,无法达到实时性的要求。
2 基于YOLOv 3的车辆检测算法分析
YOLOv3算法就是将一张车辆图片分成s*s个网格,如果物体的中心点落在网格上,那么该网格就负责预测这个物体的bounding box,每次预测时会有坐标参数(x,y,w,h)和置信度[3],置信度可以用IOU计算,我们选择IOU最大的作为车辆检测输出。YOLOv3使用Darknet53作为主干特征提取网络,Darknet53里面含有残差网络Residual,容易优化,可以通过增加网络深度来提高准确率。首先把图片转换成416*416尺寸,为了防止图片失真可以加入灰度条,经过一个卷积层(卷积层都是正常的卷积、标准化、激活函数),然后通过五个残差块,残差块均由一个1*1卷积、一个3*3卷积、一个shortcut path组成,有效缓解了梯度消失问题,这五个残差块重复次数分别是1,2,8,8,4,使用残差网络来提取特征。在这五次下采样过程中,图片的宽高不断被压缩,通道数扩张,这样就获得了一堆的特征层。我们使用后三个特征层构建FPN特征金字塔来加强特征提取,后三个特征层分别是52*52(预测小物体)、26*26(预测中物体)、13*13(预测大物体)。将这三个特征层结果分别进行五次卷积,卷积出来的结果一个分支用来做分类回归,另一个分支将结果卷积再进行上采样与前一个特征层堆叠,再重复的进行五次卷积,接下来重复两次上述步骤,我们就可以得到三个加强特征层。最后利用YoloHead对三个有效特征层进行预测,Yolo Head本质上是一次3*3卷积用来特征融合加上一次1*1卷积调整通道数。
YOLOv3算法将图片端到端目标检测,丧失了部分精度,难以检测小目标,但是速度快,漏检率低,对全局信息有较好表现。
3 基于SSD的车辆检测算法分析
SSD(Single-Shot MultiBox Detector)在2016年算法问世,不仅提升了识别速度,还提高了mAP值[4]。首先将车辆图片统一成300*300输入,SSD采用VGG16作为基础网络,并对VGG16做出了一些改进:全连接层(Fully Connected Layer)的6、7层分别转换成3*3卷积层和1*1卷积层,同时采用Atrous Algorithm方法指数级增加感受野;去除全连接层8和Dropout层;池化层5由2*2-s2变成3*3-s1;增加4个卷积层。显而易见,SSD算法网络结构中应用多个卷积层,每一个卷积层都可以提取feature map,那么我们在这个过程中获得多个不同大小的特征图,即SSD可以多尺度地检测车辆。在特征图中选择原卷积层Conv4_3,和新增卷积层7、8_2、9_2、10_2、11_2作为有效特征图,尺寸分 别 为:(38,38)、(19,19)、(10,10)、(5,5)、(3,3)、(1,1)。但是设置先验框(prior box)数目时这六个特征图是不同的,先验框是实际选用的默认框,prior box的设置包括尺度和长宽比的选择,式(1)是生成默认框(default boxes)的公式。
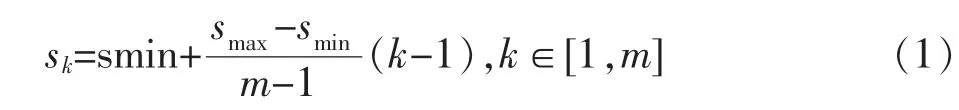
其中,m:特征图个数;sk,prior box大小相对于图片的比例;smin和smax,比例的最小值与最大值每个特征图有6个先验框{1,2,3,1/2,1/3,1'},但Conv4_3、Conv10_2、Conv11_2层只用{1,2,1/2,1'}这4个prior box。SSD算法不需要全连接层,直接使用这些不同的特征图来进行检测,会同时有两个3*3卷积,第一个用来检测车辆类别,以及先验框是否含有物体,第二个用来回归预测框的坐标信息(中心位置、宽、高)。SSD算法一共可以预测8 732个边界框,可以说是非常密集,不过计算量也变得极其庞大,因此采用非极大值抑制(NMS)方法设置合适的阈值,来去除掉一些重叠的Default boxes,最后对剩下的prior box检测,即可通过他们得出车辆类别和位置信息。
SSD算法在特征图上进行了大量采样,有效避免了漏检,提高车辆检测精度,分类回归同时进行,大大提高了速度,但是需要设计者手工依靠经验来设置default boxes的初始值,增加了工作量,而且不能很好识别检测出小目标,对大目标检测效果较好。
4 结语
随着深度学习算法的不断发展,深度学习在智能交通系统领域有着越来越广泛的应用。通过上述分析可知基于深度学习的三种经典的车辆检测算法——Faster R-CNN算法、YOLOv3算法、SSD算法,各有千秋,在选择网络的时候可以根据不同的应用场景和实际需求来实现。
