基于关联数据的高校机构知识库服务模式探究
2022-02-16吴晓彤刘玉博
吴晓彤 刘玉博
(山东农业大学图书馆,山东 泰安 271018)
0 引言
关联数据是一种链接各类数据信息的技术规范,可以实现机构知识库内部、外部的数据集的互连[4]。因此,将关联数据作为一种关键技术应用于机构知识库的服务中,探索基于关联数据的高校机构知识库服务新模式,提高机构知识库的知识发现和资源共享能力,将是机构知识库未来的发展趋势。
1 相关研究综述
针对基于关联数据的机构知识库的构建研究,从2019—2021年[5-9],学者们开始从关联模式、体系架构以及服务模式等方面构建基于关联数据的机构知识库。一些学者结合本单位的实际,探讨了机构知识库中关联数据的构建模式,或是将关联数据与资源描述的标准相结合提出了一种图书馆机构知识库的构建策略。
这些研究为关联数据技术在我国机构知识库中的应用提供了有价值的参考,并衍生出一条新的知识发现服务模式,对我国机构知识库的建设具有一定的理论指导意义。然而国内基于关联数据的机构知识库研究主要存在两个特点:(1)由于关联数据方式和系统模型的多样化,多数研究需要对多个分布式异构系统中的不同本体模型进行映射;(2)国内研究多数是在针对自身的情况下采取特定的服务模式,或是针对某个关键的技术进行说明,而在构建通用的机构知识库服务模式方面的研究较少。
综上所述,我国目前尚未形成通用的机构知识库服务模式及关联数据方法,但由于通用模式的开放性和标准化程度更高,是未来机构知识库发展的主流。因此,笔者旨在探索一种较为通用的基于关联数据的高校机构知识库服务模式和体系架构,充分利用机构知识库海量的数字化信息资源及其与整个互联网中学术资源的多维度关联,为我国高校机构知识库的建设和服务提供参考。
2 关联数据在高校机构知识库中的关键技术
2.1 基于关联数据的高校机构知识库资源语义描述与关联
将关联数据技术应用在机构知识库中,首先,需要对机构知识库中的数字化资源进行语义描述。即选择合适的语义关联模型,根据机构知识库中资源实体之间的关联和映射关系,由机构知识库中的资源主体本身扩展到其他任何一个存在该资源主体的数据源或属性中。由于本文旨在探索一种通用的基于关联数据的机构知识库服务模式,因此选择数字图书馆领域资源,通常采用RDFS和OWL结构进行机构知识库本体类的实现,并使用DC元数据对原生数字资源进行语义信息的描述。
就高校机构知识库而言,其包含的数字资源主要包括两部分:本校图书馆涵盖的数字资源和高校人员的原生数字资源。因此,根据国家图书馆制定的信息资源名称规范表,机构知识库的数字资源可以细化为以下6类:
(1)科技成果(Technological Achievements):本机构人员发表或参与发表的学术期刊论文、会议论文、学位论文、报纸、专著、专利、软著、标准、研究报告、预印本等科技成果;
(2)教学资源(Teaching resources):用于日常教学的演示课件、教材、音视频、网络教学资源等资料;
以天津市和平区、河西区、河东区、南开区、河北区、红桥区6个区的养老机构作为调研对象,每区随机抽取8家养老机构,共发放问卷48份,回收有效问卷46份,有效回收率95.8%。
(3)科研项目(Research project):指校级、市级、省级、国家级的横向或纵向项目,且确保项目至少有两名本机构人员主持或参与;
(4)科 技 奖 励(Science and Technology Awards):本机构作为获奖单位或获奖者为本机构人员的市级以上学术奖励;
(5)新品种(New Breed):由本机构人员选育的、审(认)定机构通过的作物、植物等品种;
(6)责任者(Scholar):主要为较为长期的从属于本单位的专家学者、科研团队或者机构,相对较为稳定。
对于这些数字化资源实体,语义描述需要对资源实体的一些核心概念进行确定,即定义对象的类和属性,并根据实体间的关系对它们进行关联,例如科技成果与责任者之间可以通过作者这一属性进行一对多、多对一、多对多的关联。根据这些对象类与属性间的关系,通过复用业界标准词汇,进行各资源之间的语义关联(见图1)。
接下来,笔者对关联图进行分析解释。SKOS是一种以RDFS的设计方式描述知识组织的语言;FOAF是一种描述实体及实体之间关系的XML/RDF词汇表,通过FOAF对学者信息和机构信息进行描述,并通过机构知识库属性ir:相似研究方向(similar research direction)在学者之间建立关联;vCard用于扩展机构相关属性,通过此复用词将学者和机构两者关联起来;而机构知识库中的科技文献、教学资源、科技奖励、新品种和科研项目分别通过属性ir:作者(author)、ir:提供者(contributor)、ir:获奖者(acquire)和复用词foaf:项目(presideproject)与学者信息关联;科技文献和科研项目之间通过ir:成果(outcome)属性进行关联。

图1 高校机构知识库资源的语义关联图
在外部数字化资源的语义关联方面,对于一些网络检索平台,例如,谷歌、百度、维基百科等返回的查询结果(如XML、JSON格式等),关联数据技术可以对其数据集的API进行抓取和扩展,并转化为相对应的RDF格式,方便机器进行进一步的结果处理,在此过程中还能够通过RDF数据集关联外部的相关数据源。
综上所述,在关联数据的环境下,机构知识库内部的数字化资源语义关联程度能够更加紧密,同时也能够实现将机构知识库成员的检索结果关联到外部数据源,从而实现机构知识库内部、外部不同数据集之间的衔接,形成更为开放的、跨机构的、高关联的原生数字资源网络。
2.2 基于关联数据的高校机构知识库服务模型
基于关联数据的高校机构知识库构建的主要目的是通过对原生数字资源的语义化描述和语义关联,实现资源与机构知识库内、外部相关数据源的关联,提高机构知识库的知识发现和资源共享能力,为用户提供更为高效便捷的服务模式。因此,可以从数据层、关联层和应用层三个层面设计该模型(见图2)。
其中,机构知识库各类原生数字资源需要存储在数据层中,机构知识库需要对这些资源进行类型与格式的归类,并根据DC元数据规范,对每条数据进行语义描述和存储。为了保证机构知识库数字化资源的完整性,收集和存储数据的覆盖范围也并不限于本机构,对于其他科研机构、高校等一些合作机构的资源,数据层也可以共享。
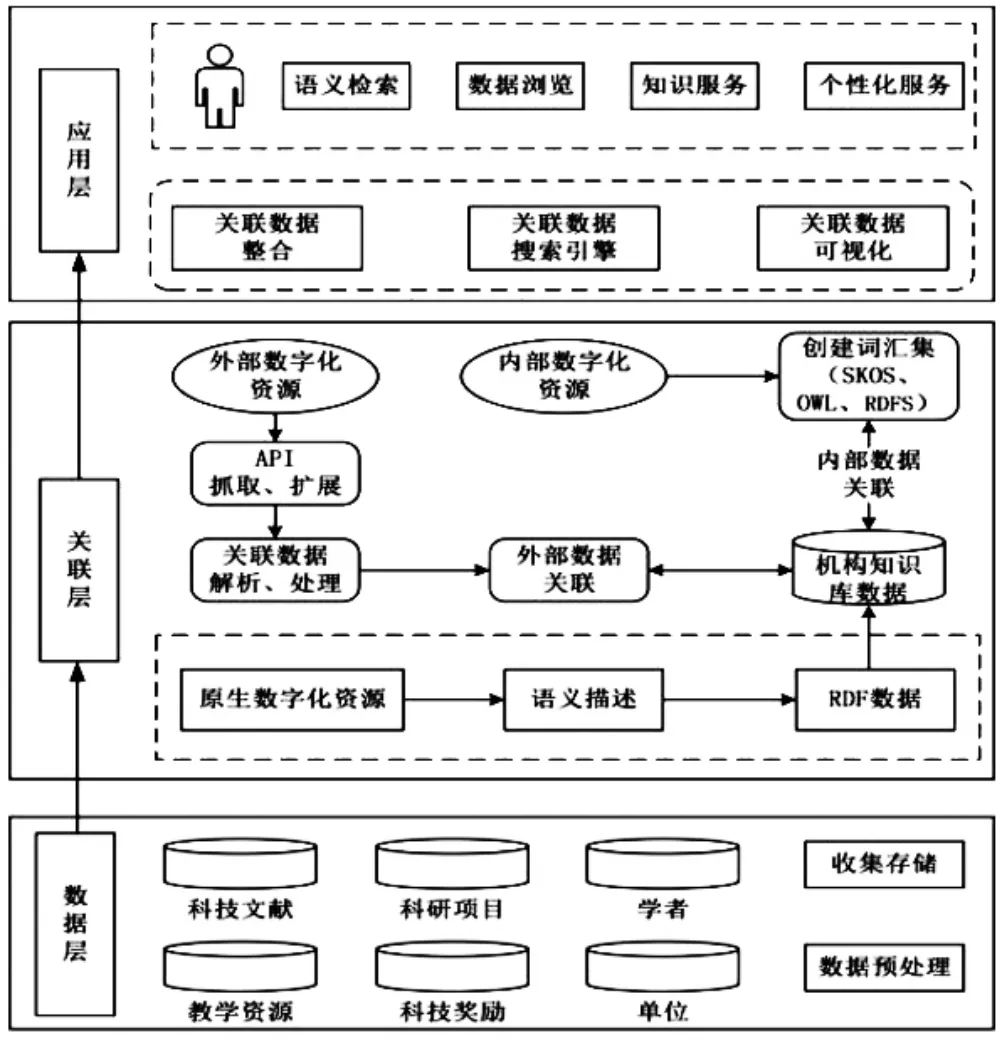
图2 基于关联数据的机构知识库服务模型
在关联层,机构知识库可以对数据层处理后的数字化资源进行统一的语义描述,应用RDF建立起机构知识库内部资源间的关联以及内部与外部资源间的关联,通过各资源之间的链接,将独立的数据资源整合、排序,形成一个全面完整的知识发现网络,进一步提高机构知识库数字化资源的开放性,为应用层中用户对原生数字资源的获取提供支持。
应用层在机构知识库数据资源充分关联与整合的前提下,主要为用户提供语义检索、数据浏览、知识服务和个性化服务四项内容。在这一层级,机构知识库可以根据用户的检索需求,高效准确地为用户推送相关资源,为用户提供一个原生数字资源更为丰富的空间,增强用户资源获取的体验感和对机构知识库的认同感。
3 结语
本文提出了一种较为通用的基于关联数据的高校机构知识库服务模式,分析了关联数据应用的关键技术,包括原生数字资源的语义描述与关联,在此基础上构建了服务模型,并详细论述了模型的构建方法和具体功能。
基于关联数据的高校机构知识库服务模式可以有效解决“信息孤岛”的问题,能够提高知识库知识发现能力,加强机构知识库资源的集成和共享,为我国高校机构知识库的建设提供参考。
