基于Hadoop的精准扶贫大数据的数据挖掘研究
2022-02-15张向荣
张向荣
(商洛职业技术学院,陕西 商洛 726000)
中国是世界上人口第一大国,尽管贫困人口的基数不大,但是贫困户的绝对数量依旧比较多。以习近平总书记为核心的党中央实施精准扶贫战略,持续增加扶贫投入,因人因地分类施策,从而更好地打赢脱贫攻坚战。扎实推进精准扶贫工作开展的关键是对精准扶贫大数据的数据挖掘,通过数据挖掘技术来提供准确、全面、高效、个性化服务,满足精准扶贫工作者对贫困人群海量信息的查询、检索需求[1]。分布式技术是当前提升数据检索效率的最佳选择,通过分布于不同节点的数据来执行数据检索任务,达到提升海量大数据检索整体效率的目的。Hadoop 是分布式系统基础架构,被广泛应用于海量大数据的数据挖掘中。王倩等[2]针对传统单机大数据集存储与计算能力不足的问题,构建了基于Hadoop 集群平台的中医数据挖掘系统,该系统具有良好的交互性与完备性功能,效率高、结果准确,能够有效推动互联网和中医药健康服务的深度融合发展。杨夏薇[3]针对传统人力资源决策技术对海量人力资源数据辨别能力不高的问题,构建了基于Hadoop 大数据平台的人力资源决策技术,通过决策树分类算法生成人力资源决策分析报表,该决策技术相对于传统的人力资源决策技术决策结果的完整度大大提升,能够更好地满足当前企业的发展需求。李爽等[4]提出基于Hadoop 框架的K 均值聚类算法,并将其应用于Higgs 数据集上进行聚类分析,表明该算法能够在确保聚类准确率的前提下大幅度提升K 均值聚类算法的运算效率。
本研究在前人研究的基础上,从检索工作前期预处理的角度出发对数据识别进行判断,挖掘和检索信息化高度相关的数据集进行定位来提升检索效果,提出了基于Hadoop 的分布式贫困户检索算法,有效规避全节点过滤不充分的问题,并将参数设置个性化应用于不同的场景中,达到个性化最佳效果,使得提出的数据挖掘算法具有更广的应用价值。
1 基于远程方法调用的查询系统体系
本研究采用Hadoop 实现分布式信息检索查询,其基础为面向对象的远程方法调用(Remote Method Invocation)RMI技术。
1.1 RMI远程方法调用
分布式系统的基础是远程通信问题,解决本地调用远程服务器。远程调用是分布式系统进行远程通信的核心,其实现了本地进行远程服务器方法的调用。RMI基本体系结构如图1 所示[5]。
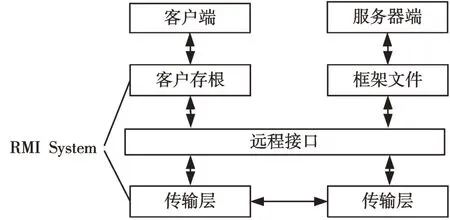
图1 RMI 体系结构
Stub/Skeleton 层,该层提供了客户程序和服务程序彼此交互的接口;远程引用层,该层是Stub/Skeleton 层和传输协议层之间的中间件,负责处理远程对象引用的创建和管理;传输协议层提供了数据协议,用以通过线路传输客户程序和远程对象间的请求和应答。
1.2 基于远程方法调用的分布式体系结构
并行系统软件设计包括分治策略、阶段并行、流水线方式、工作池方式以及主从模式5 种设计模式[6,7]。本研究设计的初始分布式检索模型以主从模式为拓扑结构、以RMI 调用为技术原型,使得Client 端的调用与Server 端的调用完全一致,无需再考虑消息的组包、拆包等网络通信问题。利用Java 反射机制,客户和服务器之间的通信直接传递对象。Server 端采用一个接收线程、多个处理线程结构,通过一个call对象队列连接。Client与Server 用一个线程保持一个连接,与同一个Server 的不同调用通过call对象的id 区分。系统结构如图2 所示。
该系统由若干个数据服务器和一个主服务器组成[8-10],主服务器主要完成用户查询词的向量转换,维护一个数据服务器列表文件,建立远程连接和检索结果合并等工作。向量模型表示该步主要用来完成将用户提交的检索词表示成向量模型。从查询串中分出的每一个词都是一个特征词,同时用系统默认或者用户自定义的方式为每一个特征词赋予权值。服务器列表文件用来存储数据服务器的访问地址,通过在主服务器上设置一个简单的数据服务器列表文件,方便管理员对数据服务器的了解。
1.3 基于数据特征的分布式检索系统的体系结构
由于体系架构上的每个信息节点检索系统仅对本地的数据对象建立索引。当用户提出一个检索请求时,由于该系统本身没有存储被检索数据的相关描述,每个检索请求会被统一地分发到整个系统中的每个数据节点执行计算,即为全文检索工作,信息节点的持续增加、服务器性能等原因会制约整个系统的性能与可靠性。因此,本研究提出了基于数据特征的Hadoop 分布式检索模型,将同类的数据聚合在一起,并且根据需要将聚合在一起的数据集模拟出一定维数的特征向量表示,当系统收到一个查询请求的时候,首先会将检索关键词和特征索引表中的各向量做相似性比较,计算出一个数值,只有当该数值大于某个阈值的时候才认为该向量所表示的数据是真正和检索项相关的,那么检索词被分发到此处进行检索,使系统既有好的检索结果,又有很高的搜索效率。基于数据特征的Hadoop 分布式检索系统的体系结构如图3 所示。
其中,数据分类模块运用文本聚类方法将原始数据分割成子数据集,每个子数据集里包含的数据有较高的相似性,而不同的数据集之间在内容上有较大的差异。初始数据被分割成一块块按照内容相似度排列的子数据集后,数据特征抽取模块负责抽取出各子数据集的特征向量。抽取得到的特征向量通过网络发送到主服务器。
主服务器使用特征合并模块,收集所有来自数据服务器的特征向量。根据各特征向量的相似度,将相似度较高的向量合并,合并后的特征向量被发送给数据特征索引表。该表记载最终的特征向量和该特征向量表示的数据集的访问地址。查询词被封装成特征向量后,进行全节点遍历被发送到和向量相关的数据集,而与查询向量内容不相关的数据集对于本次检索不做任何工作,从而提升检索效率。
2 基于Hadoop的分布式查询体系实现
2.1 分布式环境建立
基于数据特征的分布式检索系统体系结构搭建的Hadoop 分布式系统包括一个分布式主节点、一个分布式主节点备份节点和若干个分布式从节点,主要由语言层、存储层、执行层和业务层4 部分构成,如图4 所示。
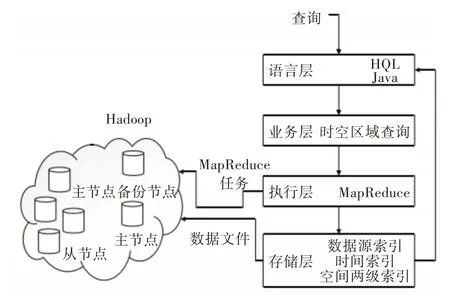
图4 Hadoop 分布式系统架构
语言层主要用于在Hadoop 基础上搭建的顶层Hive 组件,该组件支持HQL 查询语言以及Java 开发语言,存储层使用NHadoop 的时间优先的存储策略,按照数据特征项及其对用时间戳的存储结构HDFS中完成数据组织,执行层采用并行计算框架MapReduce 可以直接访问HDFS 中建立的时空索引结构。业务层将传统的空间区域查询操作以函数式编程MapReduce 的结构执行在分布式系统框架上。
2.2 建立数据特征索引表的生成和检索
数据特征抽取完成后建立数据特征索引表,基于数据特征的分布式检索系统就是利用数据特征索引表来存储节点的特征表示和访问地址的。数据特征索引表存储了三维数据,其结构可形式化地表示为<Id,Character,Address>,其中Id 表示类别编号,Character 表示数据特征,Address 表示与该特征对应的数据访问地址。特征索引表的建立过程如图5 所示。
从图5 中可以看出,使用数据特征抽取步骤的输出结果,对按权重排序的文件解析成向量模型,将这些向量统一发送到主服务器上,主服务器对这些向量进行相似性计算,合并相似的向量,并将合并得到的向量插入数据特征索引表中。
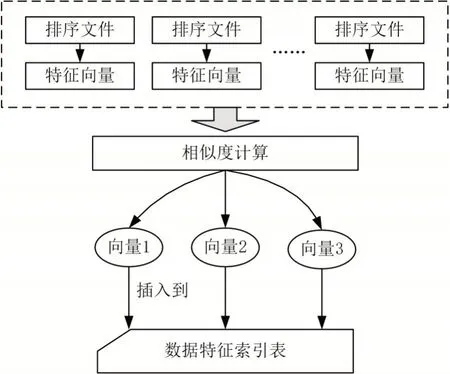
图5 数据特征索引表建立过程
虽然同数据点上的数据被分成了多个类别,但是不同数据节点上的数据集可能比较相似,因此该向量是计算了所有节点上的向量相似度后得到的最终综合向量。相似度的计算方法可用式(1)表示:
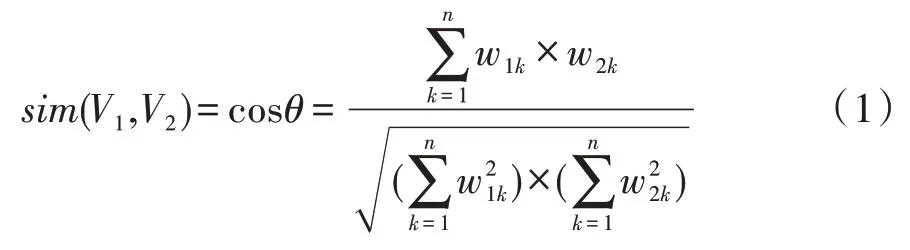
其中,w1k和w2k分别表示向量V1和V2的第k个特征项的权值。
生成一个聚类索引表的过程如图6 所示。
图6 特征索引表生成程序
2.3 相似性阈值设置
不同地区的精准扶贫大数据之间具有比较大的差别,使得相似性阈值的设置应该结合不同的应用场景进行个性化设置。计算查询向量与文档特征向量之间的相似性,通过相似度来判断查询词语数据群之间的相似关系。如果计算的相似性值大于设定的阈值,那么认为数据是相关的;反之认为数据是不相关的。
对于一维查询向量,直接给该维特征的权重设置为1。在这种情况下,查询向量和文档特征向量的相似性计算可以简单地理解为判断在文档特征向量中是否包含指定查询词的问题。如果查询向量超过一维,对于5 维以内数据系统设置了默认权重,按照查询关键词的出现顺序,初始值设置如表1 所示。
表1 查询向量初始权重
为了验证算法能够结合参数设置被广泛使用于不同的场景,选择12 个不同类别的精准扶贫数据集,包含家庭基本情况、家庭贫困原因等多个方面的信息,并将其抽象为12 个特征向量,同时设置权重最高的前6 000 维参与运算。提交20 次检索请求,统计平均值,统计结果如图7所示。由图7可知,当相似性阈值选择在0.15 左右时,具有较好的效果,结果集包含相似的数据点,同时又过滤不相似的数据点。
图7 相似性阈值统计
3 实证结果与分析
3.1 试验环境
系统基于Linux 环境,通过3 台PC 机组成6 个节点搭建Hadoop2.7.2 集群作为服务器。3 台PC 机的配置一样,CPU 为Intel(R)Core(TM)i7-7700 CPU@3.60 GHz,RAM 为8.00 GB,操作系统为Windows 7旗舰版,模拟程序由Java 编写。试验采用了TanCorpV1.0 的中文语料库,共有23 368 个文档,数据集的向量模型中特征词的个数一般都在15 000 以上。
3.2 检索结果测试
检索结果主要利用查全率和查准率两个方面来评价。查准率=(检索出的相关信息量/检索出的信息总量)×100%。查全率=(检索出的相关信息量/系统中的相关信息总量)×100%。
在全节点遍历和基于数据特征两种分布式环境下进行检索操作,数据结果如图8 所示。
图8 前N 条记录的查准率
系列1 代表的是在全节点遍历模式下N取不同值时,前N条记录的查准率的大小。
系列2 代表的是系统使用的文档特征向量占整个文档特征向量总长度的2/3 时,前N条记录的查准率的大小。
系列3 代表的是系统使用的文档特征向量占整个文档特征向量总长度的1/3 时,前N条记录的查准率的大小。
从图8 中可以看出,当N增大时,查准率降低,结果中包含的非相关文档出现的几率越大。本研究提出基于数据特征的分布式检索系统的查准率总体高于全节点遍历式的分布式检索系统好,且在相对于结果集长度而言,N不是很大,参与计算的文档特征维数在合理范围内越小,前N条记录的查准率越高。
系列1 为全节点遍历,系列2 和系列3 分别表示在基于数据特征的分布式检索系统中。由图9 可以看出,在检索结果文档数目相同的情况下,基于数据特征的分布式检索系统访问的数据远小于全节点遍历模式,减少了访问的数据源数量,节省了系统的总体计算和网络资源。
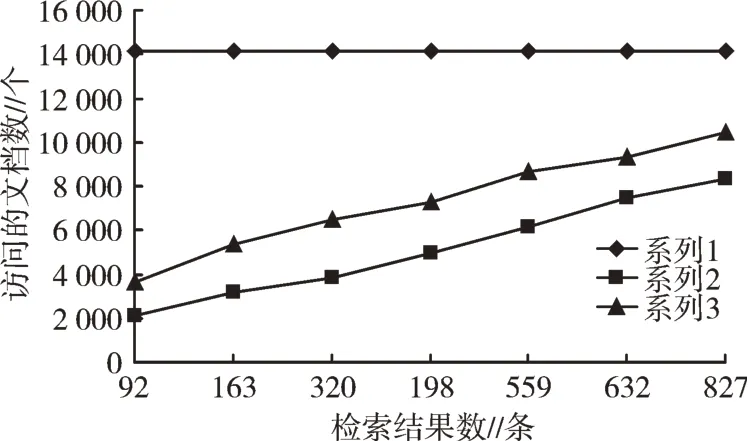
图9 检索结果与文档访问数量的关系
4 小结
本研究提出了基于Hadoop 的分布式贫困户检索架构,结合数据的特征项提取及文本聚类技术,对相似文本进行聚合,根据查询精度要求建立对应文本特征向量空间,同时,过滤关联性差的数据,使其不参与搜索,以提升系统的执行效率降低内执行速度。贫困户检索算法可以结合参数设置个性化使用不同的应用场景,查全率和查准率对比全节点遍历检索具有较高的查全率和查准率,减少访问的数据源数量,节省了系统的总体计算和网络资源,具有很大的应用推广价值。
