基于SVM和DS证据理论的图书馆读者借阅行为分析
2022-02-15姜笑楠
姜笑楠
(大连职业技术学院图书馆 辽宁大连 116000)
1 引言
图书馆能够依靠其海量馆藏图书和数字资源为各类读者提供文献信息服务[1]。我国图书馆管理系统已经十分成熟,经过数十年的发展也积累下了丰富的实践数据[2],如读者数据、图书数据等。通过深度挖掘这部分数据能够帮助我们更好地了解读者借阅习惯及规律,进而为后续改善图书馆服务质量提供有力依据[3]。总的来说,研究图书馆读者借阅行为对于改善我国图书馆管理水平具有显著意义[4-5]。
考虑到早期图书馆读者借阅行为历史数据并不多,所以研究者在统计分析读者的借阅行为时往往会以人工方式进行。这种方式由于过于主观所以很难全面、准确地得出读者借阅行为规律,难以为有效提升馆藏资源利用率提供决策依据[6]。现代信息技术的日新月异,使得大量基于数据挖掘技术的读者借阅行为分析方法应运而生[7],比如基于时间序列的分析法[8],即以时间先后来对读者借阅行为进行采集。不过这种方法也难以得出读者借阅行为的总体变化特征,导致所得出的结果可信度较低[9]。再如,基于关联规则算法的分析方法,旨在对借阅活动和读者间的联系进行综合反映[10],这种方法是典型的线性分析技术,但借阅活动和读者间联系是非线性的,所以其分析结果往往具有较大误差[11]。还有基于流通日志的分析方法[12],即通过流量日志来了解读者借阅规律,不过随着读者人数规模的提升,流通日志的数据量也日益庞大,这将大大影响到这种分析方法的效率[13-15]。由于以上方法都存在一定缺陷,本文提出一种基于SVM与DS证据理论的分析方法来对读者借阅行为进行综合分析,同时引入实证分析法验证其结果的科学性。
2 图书馆读者借阅行为特征
2.1 特征提取
不同的图书馆其读者在借阅行为特征上都互有差异,我们可以这部分特征来进行读者借阅行为规律的识别,本研究拟定提取以下特征(见图1)。
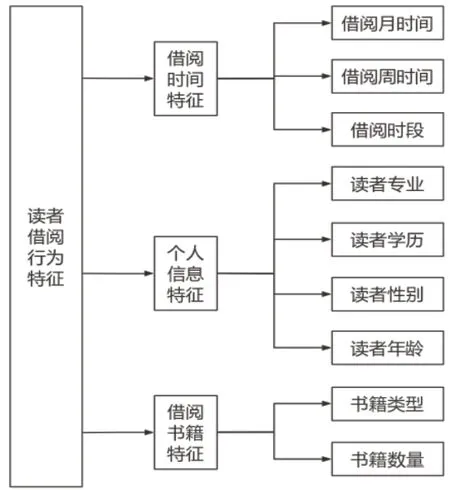
图1 读者借阅行为特征
2.2 读者借阅行为特征聚类
针对数量为n的读者而言,其借阅行为特征数据为X={x1,x2,L,xi,L,xn},设聚类数量为k,聚类分析算法原理如下:随机选取k个读者借阅行为数据作为总数为n的读者借阅行为数据的初始聚类中心,其余数据则按照其和聚类中心的距离来和其最相似类别进行匹配。
(1)第j类读者借阅行为类中心用cj表示,此时xi与cj之间距离:

xi与cj之间相似度为:

(2)更新各聚类中心,设第j类读者借阅行为分析样本集合{xj1,xj2,L,xi,xjnj},其聚类中心为cj=的第k个属性用代表:
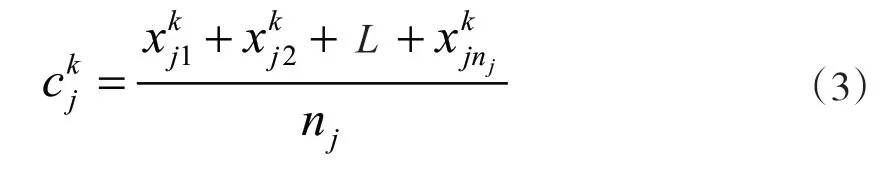
(3)反复以上操作,直到最终更新出前后一致的类中心为止,以均方差为本次测度标准,有:

经过上述步骤我们即可得出有关读者借阅行为分析样本的相似历史样本数量,进而完成建模。这种方式摆脱了对历史样本的依托,大大提高了分析效率。
3 SVM-DS多特征融合行为分析算法
3.1 SVM算法
作为典型的广义线性分类算法,SVM算法在处理分类问题时尽管不能完全依托线性来完成二分类,不过可通过采用核函数方法在希尔伯特空间中映射出样本数据,从而通过建立超平面来把不可线性二分问题转化成线性可分问题。在确定这一超平面时应尽可能与其他样本保持最大距离,并且最终的分类误差要尽可能小。经超平面判别所得的最终样本会被分成两类分类函数,即:

其中,SV代表支持向量,ia代表拉格朗日乘子,代表核函数,xi、yi均为支持向量,b代表阈值,c代表惩罚系数。
3.2 DS证据理论
DS证据理论属于模糊推理理论,由Dempster和Shafer提出。其原理就是通过整合两个或更多正具体的基本概率分配来得到作为评估依据的BPA,在此期间内,识别框架U中的目标是主要整合目标,它包含了若干目标对象,这些对象彼此排斥,互无联系,m:2U→ [0,1]为定义函数(U的幂集为2U),满足条件识别框架上的BPA用m表示,信任A的程度通过m(A)体现。
如果m1,m2与同一识别框架U上的BPA属于一一对应的关系,然后用A1,A2,...,Ak和B1,B2,...,Bk,表示焦元,且满足 的条件,那么可以得到如下公式所示内容:

3.3 SVM-DS融合算法
在分析借阅行为期间,若引入了SVM-DS融合算法,那么操作步骤如下:先构造BPA,即先对特征参数进行提取,然后基于SVM识别单特征,整合BPA和DS证据理论,得到相应的结果(见图2)。

(1)对特征进行提取,然后基于SVM识别单特征,先提取读者借阅行为的特征,然后基于SVM初步识别基于3类9个单特征,然后得到公式(7)所示的正确率:

在公式(7)当中,无误的样本数量用N表示,总样本数用M表示。
(2)构造BPS函数。目前有数种标准的SVM输出类型,既不能构造证据体的BPA,又不能对各种判别结果的概率进行输出,所以,在[0,1]区间内用sigmoid函数[16]实现SVM输出的映射就可以明确后验概率,如公式(8)所示:
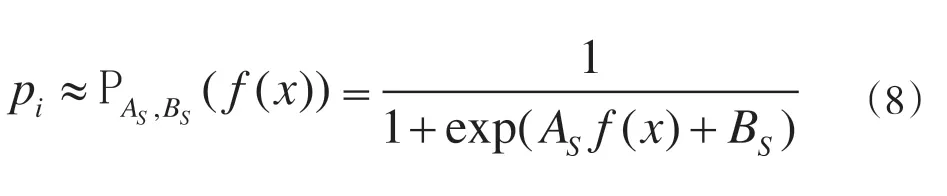
在上述公式中,SVM输出的类型用x表示,As,Bs是对sigmoid函数形态进行控制的参数。
所以对于随机1个或更多的 SVM类而言,满足如下条件:

(3)对DS融合评估准则进行设计。假设借阅行为有三种,记作Ar(r = 1,2,3) ,分析结果用Aw表示,然后要按照的准则用BPA划分证据类型,也就是当目标类的信度比某门限值大时,那么信度最大的类就是这个目标类。
4 实验仿真
用K表示仿真的初始聚类中心,然后对全体特征进行量化,具体为:以数字的方式将图书的借阅时间、周期,以及借阅者的年龄和借阅书籍量表示出来;用数字表示借阅图书的时段的中点;借阅者专业上,用数字1~13来表示具体的学科门类,包括艺术学、军事学、农学、教与学、法学、哲学、历史学、文学、经济学、医学、工学、理学等,0表示无专业;借阅者学历上,用1~4分别对应高中及以下、专科、本科、研究生;借阅者性别方面,用1表示男性,0表示女性;按照《中国图书馆分类法》中列出的类别来细分书籍类型,一共有22类,也用数字表示。这样得到的实验样本集,可用于训练和测试模型(见表1)。

表1 部分实验样本
本实验分两组进行,实验一先综合对比了各单特征SVM算法与多特征SVM-DS融合算法,结果发现,与单特征评估相比,多特征评估更为科学;实验二对比了SVM-DS融合算法、人工神经网络(ANN)算法、多特征算法(SVM输入包含了9类特征)。结果显示,这些算法当中,以SVM-DS融合算法的准确性最为理想。其中,SVM通过优化粒子群算法得到核函数参数g、惩罚系数c以及BRF径向基核函数,以BP神经网络作为神经网络,以tansig作为传递函数,设置了13个中间层神经元,两组实验的次数都是10个,选取225个训练集,25个测试集,二者在总样本中的占比分别是90%、10%。
表2 所示即实验一中单特征SVM和多特征SVMDS分析结果,通过对信度函数值进行分析不难发现:①实际借阅行为因为应用了多特征SVM-DS融合而有着较为理想的信任度;②在某些单特征判定存在冲突的情形下,多特征融合可以通过分析保证结果的准确性。
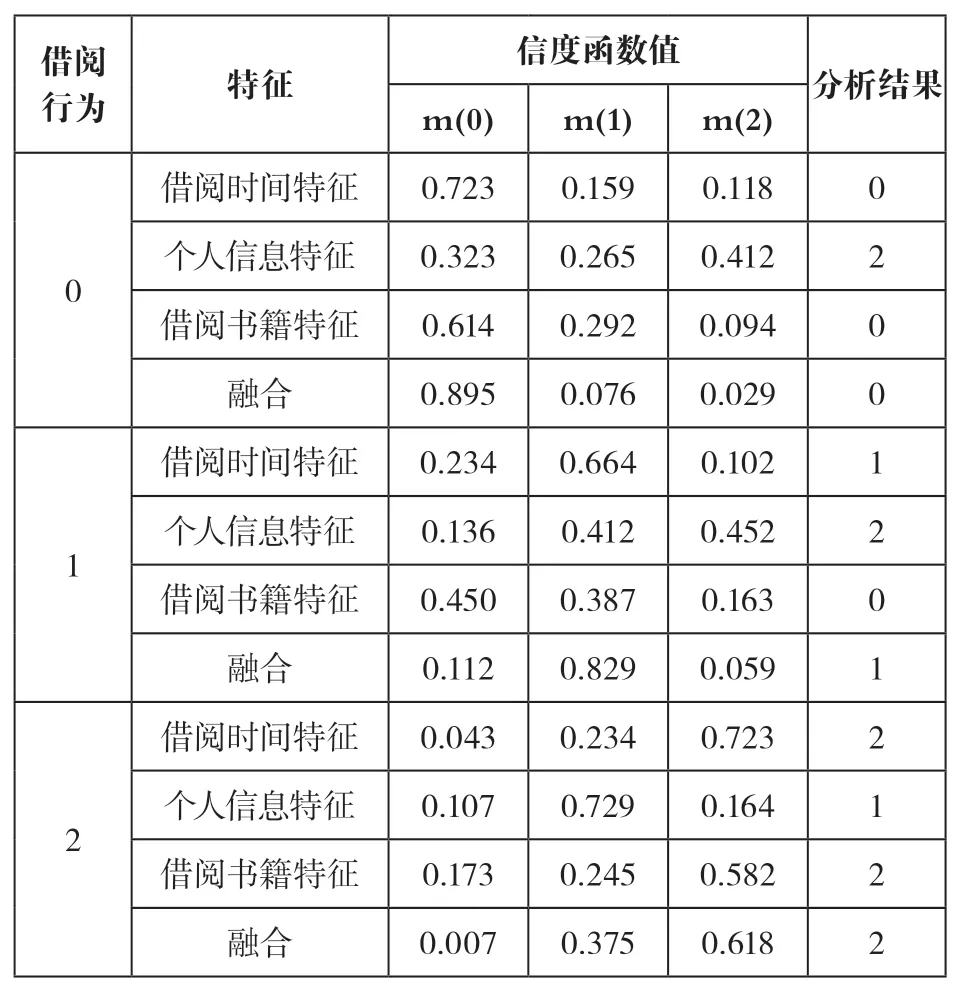
表2 单特征SVM与多特征SVM-DS分析信度对比
图3 给出了实验二内不同算法分析结果和准确率结果,其中分析行为与实际行为重合率越高则准确率越高。ANN分析、SVM多特征分析、SVM-DS分析的准确率分别是68%、72%和88%。通过对比不难发现,准确率较为理想的分析方法主要是多特征SVM和SVM-DS融合算法,这主要是训练样本数量有限的缘故,说明ANN在样本有限的情况下无法发挥优势,但是随着特征维数的变多,多特征SVM分析方法的准确率虽然也有所保证,但却不够稳定,无法充分融合不确定、不完全的信息,而且有些奇异值对其影响十分显著,会影响判别效果的可靠性,SVM-DS算法对多特征的信息进行了整合,且算法容易操作,鲁棒性也比较强。
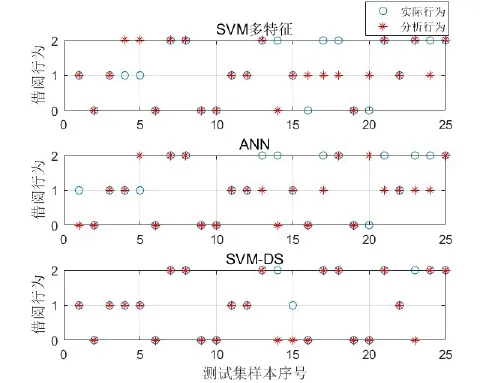
图3 各算法对借阅行为的分析与准确率结果
5 结论
本文归纳了会对借阅行为造成影响的三个因素,通过分析进一步掌握图书馆读者借阅行为。文中所构建的特征集是针对书籍信息特征、读者信息特征、借阅时间特征进行的,并提出了一种新的分析方法,即DS证据理论和SVM算法相融合。新的分析方法不但可以通过基本概率分配函数克服DS证据理论BPA的缺陷,而且可以很好地保证分析结果的客观性和时效性。同时发现采用多特征融合的SVM-DS算法可以获得88%的准确率,解决了传统SVM算法处理不全面、信息不确定的弊端,有效强化了人们分析图书馆大数据行为的能力。
