强化学习A3C算法在电梯调度中的建模及应用
2022-02-15刘宇,张聪,李涛
刘 宇,张 聪,李 涛
(1.武汉大学 计算机学院,湖北 武汉 430000;2. 武汉轻工大学 数学与计算机学院, 湖北 武汉 430000;3.国网湖北省电力有限公司荆州供电公司 发展策划部,湖北 荆州 434000)
0 引 言
楼宇电梯调度[1]是一个复杂的过程,调度算法的设计复杂性一般取决于调度环境的复杂性,当调度电梯数量越多楼宇楼层越高时,从众多调度策略中选择最优调度策略这本质上类似一个NP完全问题。当前随着认知智能技术的发展,探索更加智能的调度算法,让调度算法更具多环境适应性、调度高效性和低能耗性成为新的研究热点。
目前电梯调度算法往往基于特定需求方面进行建模,例如基于最短等待时间的算法(先来先服务算法、扫描算法和LOOK算法等),这类算法往往以满足各楼层用户需求为目的,但在多梯复杂环境下建模往往困难且缺乏适应性,特别是在人流高峰阶段的复杂环境之下,整个电梯群控效率较低[1]。同时基于算法进行最优解搜索也是研究点之一,如刘桂雄等通过引入统计方法提出了以节能优先的电梯调度算法[2],仲惠琳根据客流量变化同时引入启发式算法提出了基于神经网络的电梯调度重规划算法[3],郎曼等基于现有算法控制参数多和计算较复杂特性提出了采用人工蜂群算法的电梯群控系统[4]。刘清等针对传统的电梯群控系统的问题,提出一种模糊控制结合神经网络算法的电梯群控系统来进行优化调度[5]。刘剑等提出了基于Fast R-CNN的多轿厢电梯调度算法[6]。
电梯调度算法设计需要考虑用户体验、电梯能耗和空载情况等多个目标,上述文献的调度算法往往基于特定环境建模,存在很难平衡多个调度目标的问题。因此,本文提出了基于A3C的电梯调度算法,利用强化学习自主智能学习的优点,让调度算法在电梯和环境地不断交互中学习得到使调度目标收益最大化的调度策略[7]。同时对调度环境、电梯行为和调度目标3个方面进行统一建模,这极大方便模型在新调度环境和新目标下的低成本部署。本文基于开源LiftSim电梯调度仿真环境[8]进行了相关实验,实验结果表明A3C算法运用于群组电梯环境下进行电梯调度具有建模便捷、多环境移植适应性强、调度效率高和有效平衡多个调度目标的优势。
1 电梯调度环境
基于强化学习的电梯调度算法建模需要将不同的电梯调度环境归纳为统一的表达形式。近年来相关研究者针对电梯调度环境进行研究,开发了众多的电梯运行环境实例[8,9],电梯调度环境可用图1进行表示。本文将电梯调度环境分为楼宇环境和电梯环境,楼宇环境主要反映楼宇基本信息和楼宇各楼层用户乘梯需求信息,其中楼宇信息包括楼层和电梯桥箱数等信息,电梯调度同一时间内乘梯需求主要包含上下行需求和用户所在楼层。楼宇环境作为电梯调度算法需要考虑的主要环境,是当前调度算法的主要考虑因素。电梯环境主要指具体电梯桥箱内环境,这往往包括电梯桥箱内用户的意图楼层、载重量、桥箱所在楼层和桥箱开关门情况等信息。

图1 电梯调度环境
高层楼宇的发展让电梯调度算法面对的调度环境越来越复杂多样[10],越来越多的楼宇具备更高楼层的同时也具备了更多的电梯数量,同时不同楼层不同时段的人流往往呈现较大波动。将电梯调度环境以楼宇环境和电梯环境进行表示,一方面能较完整反映瞬时电梯调度环境,另一方面为强化学习中环境状态建模提供依据。
2 强化学习
强化学习(reinforcement learning,RL)学习方式类似人类的学习模式,通过在实践环境中执行相应动作以期望获得环境给予的最大奖励值,从而依据奖励不断地进行试错学习来不断地修正自己在具体环境中的动作策略。强化学习典型学习模式如图2所示,图示中智能体在和环境交互过程中会根据环境状态St选择执行相应的动作策略At,执行动作At后环境的状态值St会变为新的状态St+1,同时会得到在环境St下执行动作At的奖励Rt,然后智能体对于新的状态St+1又会选择执行相应的动作策略At+1,以此往复不断地在和环境交互过程中进行学习以期获得更多奖励[11,12]。
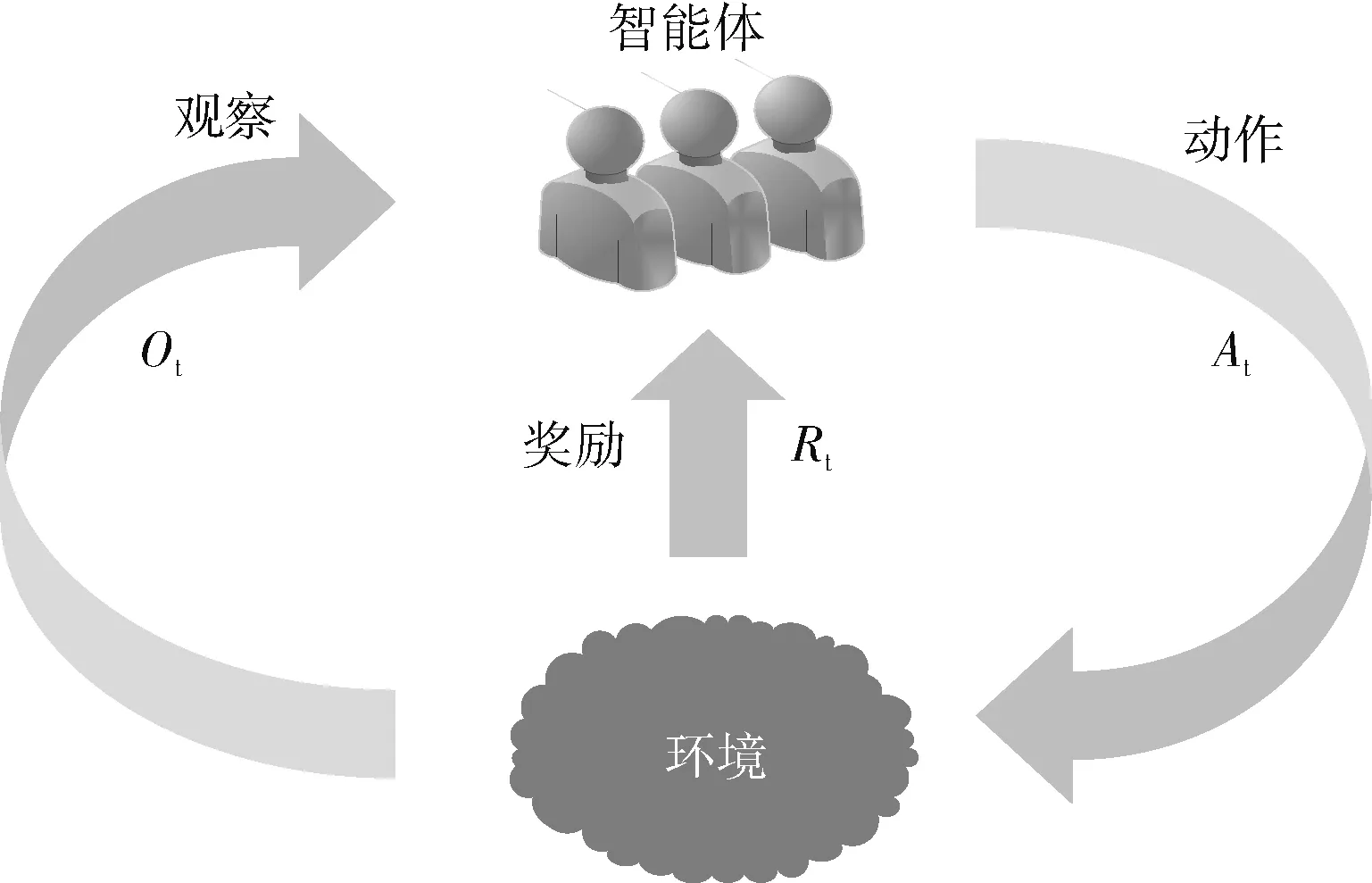
图2 强化学习框架
强化学习模式和电梯调度模式二者建模之间存在一定的相似性,基于强化学习的电梯调度算法建模中可将电梯调度环境和电梯分别视为强化学习中环境状态(State)和智能体(Agent),同时电梯调度目标和电梯上下行动作可视为强化学习中的奖励函数(Reward)和动作策略(Action)。电梯调度算法中引入强化学习方法,让电梯智能体在不断地和环境交互中自主学会最优调度策略,这对目前设计电梯调度算法具有一定的实用价值。近年随着强化学习的发展也逐渐涌现出众多的强化学习算法[13,14],例如DQN和MADDPG算法,探索强化学习算法在电梯调度领域的运用潜力具有一定研究意义。
3 基于强化学习A3C的电梯调度算法建模
基于强化学习的电梯调度模型通过强化学习实现电梯的自主调度策略学习,这大大减少了不同调度环境目标下的建模成本,实现了电梯的智能高效调度。本文基于强化学习A3C的电梯调度算法建模如图3所示,图示中首先需要对调度环境、奖励函数和电梯动作行为3个方面进行定义并进行编码,然后基于Actor和Critic角色构建融合网络实现A3C算法的自主策略输出以及模型参数更新,最后通过多线程异步训练的方式对模型进行训练直至收敛。
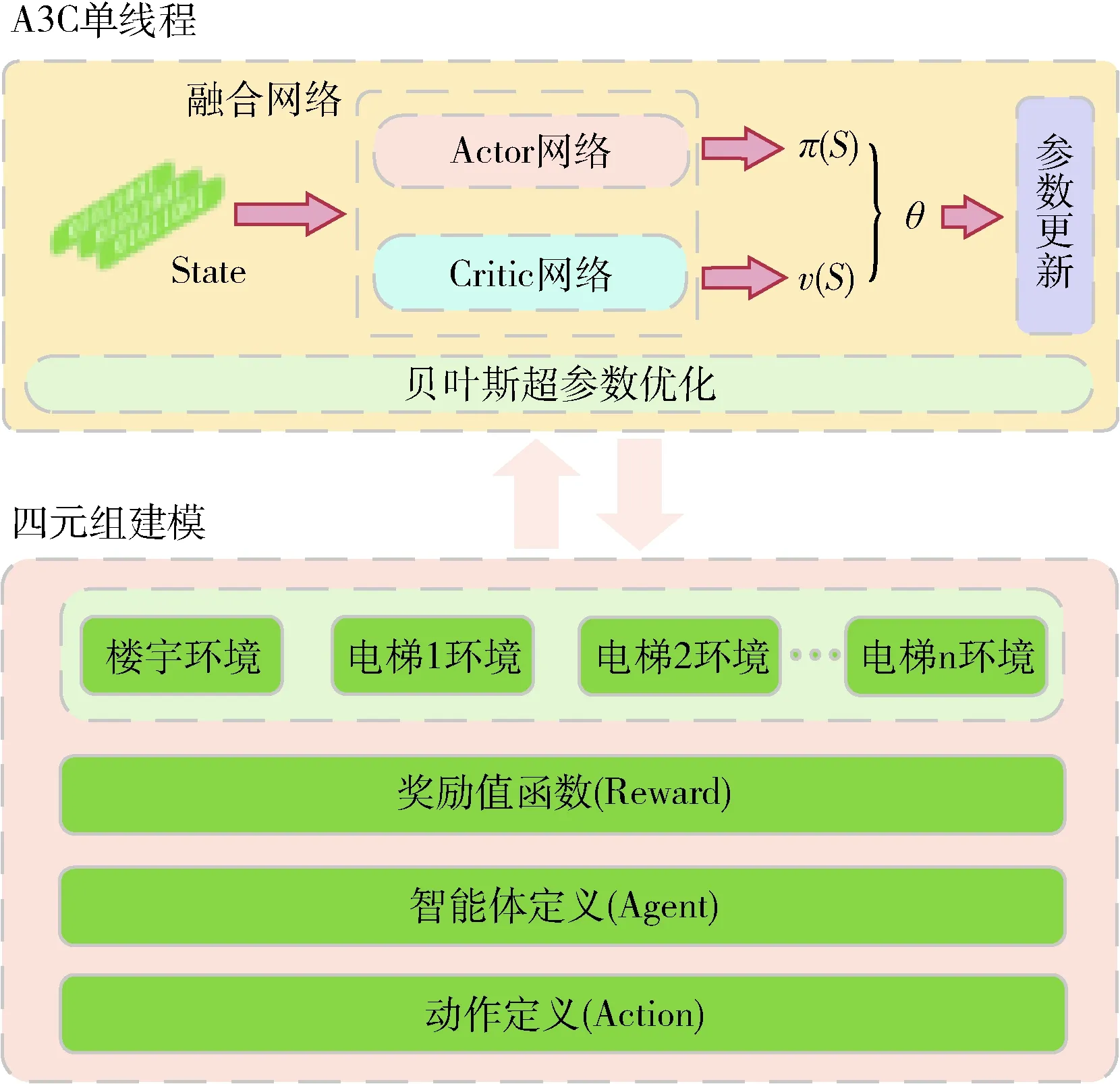
图3 基于强化学习A3C的电梯调度算法模型框架
3.1 强化学习四元组建模
基于强化学习算法的电梯调度算法建模依赖马尔科夫决策过程,需要对其四元组
复杂环境下电梯调度算法的调度目标是在提升用户体验的情况下,使电梯的能耗尽可能低,因此建模过程中奖励函数的设计需要充分考虑用户体验和电梯能耗两方面。本文强化学习的奖励函数R设计如式(1)所示,式子中time表示所有乘客在一个时间周期内的等待时长总和,energy表示一个时间周期内电梯消耗的电力,person表示一个时间内放弃的人数,实验仿真环境中默认排队等待一定时间后自动放弃等待。式子中调节参数α、β和γ分别调节各自比例,本文α、β和γ调节因子取值分别为0、0.01和100
R=α×time+β×energy+γ×person
(1)

表1 电梯调度环境建模参数项
电梯调度算法中电梯作为智能体,需要在强化学习中定义其动作空间A,电梯实际调度过程调度动作由目标楼层和方向构成,则其动作空间A可由二元组
3.2 贝叶斯优化下A3C算法建模
强化学习A3C算法来源于Actor-Critic算法,经典A3C算法基于Actor-Critic算法在网络结构、Critic评估点和异步训练框架3个方面进行了优化,这一定程度上克服了Actor-Critic算法收敛性问题[16]。但在实际建模训练过程中很多时候依然存在收敛慢和调参困难的问题,基于A3C算法依然存在性能提升的可能性,本文基于经典A3C算法引入贝叶斯优化算法对超参数进行学习,同时借鉴著名算法Alpha Zero中使用的融合网络结构设计Actor和Critic网络结构对整个A3C算法进行建模。
A3C是Actor-Critic算法的改进升级,Actor-Critic算法[16]是一种策略(Policy Based)和价值(Value Based)相结合的强化学习方法。如图3所示A3C算法建模主体亦包括演员(Actor)和评论家(Critic)两部分,A3C算法中Actor负责生成动作和环境进行交互,Critic则对Actor的行动进行评估,指导Actor的动作。Actor网络输入环境状态S,输出为当前环境下的动作策略π(S), Critic网络输入环境的状态S,输出为对状态S的评估值v(S), v(S) 表示状态下S的平均期望价值[17]。A3C算法中采用优势函数(动作价值函数和状态价值函数的差值)作为Critic评估标准,同时结合N步采样加速收敛,A3C中优势函数表达式如式(2)所示,式中A(S,t) 是优势函数,其表当前状态S的价值,γ是衰减因子
A(S,t)=Rt+γRt+1+…γn-1Rt+n-1+γnv(S′)-v(S)
(2)
Critic网络的评估值直接作用于Actor网络的参数更新,由于策略函数损失函数中加入了策略的熵项,Actor网络参数θ更新公式如式(3)所示
(3)
A3C算法中Critic网络则通过计算TD误差值δ,使用均方差作为损失函数对自身网络参数w进行参数更新,相关计算式如式(4)所示
δ=R+γv(S′)-v(S)loss=∑(R+γv(S′)-v(S,w))2
(4)
强化学习中超参数的设置对于结果收敛性起到一定程度的作用,A3C算法建模过程中需要设置部分的参数项,例如需要设置全局共享迭代轮数T、相应网络参数更新步长、熵系数值和衰减因子等,本文为了A3C算法性能有效提升引入经典贝叶斯优化方法对部分超参数进行搜寻,贝叶斯优化作为最受欢迎的方法,其充分利用相关历史信息来指导进行最优解的搜索。贝叶斯优化中假设待优化参数为X=(x1,x2,…,xn), 同时存在一个与X相关的损失函数f(x),贝叶斯优化目标函数即是寻找X得到最小损失函数f(x)。本文基于A3C算法的电梯调度算法建模中采用Hyperopt工具来实现贝叶斯优化算法。
A3C算法中Actor网络和Critic网络一般针对实际任务可采取融合网络和分离网络两种网络形式,本文基于强化学习A3C算法的电梯调度算法建模中Actor网络和Critic网络采用融合网络,融合网络即是让Actor网络和Critic网络为同一个神经网络,融合网络的输入状态为S,输出为状态的价值V和对应的策略,强化学习著名算法Alpha Zero中也使用融合网络结构[18]。
3.3 多线程异步训练
A3C算法相比较Actor-Critic算法更容易收敛,同时A3C强化学习算法借用DQN经验回放的技巧,利用多线程训练的方法。本文A3C算法多线程异步训练部署框架如图4所示,训练过程中多个线程分别和环境进行交互学习,同时将结果汇总保存到一个全局线程中进行智能体学习和参数更新,而各个线程智能体则定期从全局线程获取参数指导后面和环境的交互。通过多线程交互A3C算法避免了经验回放相关性强的问题,同时多线程训练能够确保电梯智能体能在最短时间学习得到最优调度策略。

图4 A3C算法多线程训练部署框架
4 实验仿真及结果分析
为了充分验证强化学习A3C算法运用于楼宇电梯调度的可行性,本文进行了相关的仿真实验,实验环境基于百度飞桨和百度 AI Studio平台进行,实验GPU采用英伟达Tesla V100。电梯仿真环境采用LiftSim进行,LiftSim是一款类似gym的仿真环境[8],同时基于LiftSim开源代码能够方便进行环境的自定义。本文通过在单电梯环境和多电梯复杂环境下对强化学习A3C调度算法和部分常用的传统电梯调度算法进行了对比实验,同时在多电梯且具有分时人流的复杂环境下引入多种强化学习算法和A3C算法进行对比实验。
4.1 单梯环境下电梯调度
单电梯调度环境下假设整栋楼宇只存在一部电梯,为了验证在单电梯调度环境下强化学习A3C算法和传统调度算法的有效性,本文基于LiftSim进行了仿真实验,传统调度算法中选用FCFS、SCAN、SCAN-EDF和LOOK算法作为对比算法。其中FCFS算法是一种先来先服务算法,它根据用户楼层的请求电梯先后次序进行依次调度。SCAN算法即扫描算法,是一种按照楼层顺序依次服务请求,它让电梯在最底层至最高层之间往返运行。SCAN-EDF算法是一种实时调度算法,结合了调度算法SCAN和EDF的优势,SCAN-EDF首先按照EDF算法选择请求队列中下一个服务对象,而对于相同时限的请求,则按照SCAN算法选择下一个服务对象。LOOK算法调度电梯在最底层和最顶层之间运行,当电梯前进方向未有用户请求时则立即改变运行方向运行。
本实验设计强化学习A3C算法和传统算法得分评价标准为对10层大楼的4小时人流进行调度,综合得分计算公式如式(3)所示,所得得分值为负,分值越大代表电梯能耗和用户等待时长越短,电梯调度效率越高。调度环境大楼人流产生是一个均匀随机过程,与时间无关。强化学习A3C算法超参数学习率设置为0.001,训练线程数设置25线程,A3C训练过程每一万次迭代进行评测一次。整个A3C算法训练过程情况如图5所示,图示为A3C算法60万次迭代训练过程图。

图5 单梯环境A3C算法训练过程
由图5强化学习A3C算法在不断地和环境进行交互过程中,可以明显看出A3C算法获得的奖励值逐渐增加,调度综合得分逐渐增大这说明电梯的能耗和人员等待时间逐渐降低,智能体逐步学到了最优调度策略。图5中大约在50万次迭代后得分达到-22分左右,大约60万次迭代后得分达到-21分左右。利用收敛后的算法和传统相关算法进行对比实验,对比实验调度得分如图6所示,图示中A3C_50算法采用约50万次迭代训练后的模型,A3C_60算法采用约60万次迭代后的模型。

图6 单梯环境下各调度算法性能对比
由图6可知A3C强化学习算法60万次迭代后调度效果最好达到-21.06分,调度效果超过其它传统电梯调度算法,传统调度算法中SCAN-EDF算法具有较好调度效率,最终得分为-21.88分。A3C算法50万次迭代后调度得分-22.36分,相比较SCAN-EDF算法存在不足。在单电梯环境中A3C调度算法随着迭代数上升相比较传统算法存在一定优势,但迭代数的增加一定程度上也将消耗一定的GPU资源。综合来说单电梯环境中传统调度算法具备一定的运用价值,但强化学习A3C算法在一定的迭代训练之后相比较传统调度算法也存在一定优势。
4.2 多梯复杂环境下电梯调度
多梯复杂环境下电梯调度算法建模更加复杂,需要考虑调度电梯的运行情况和其它电梯的调度情况,而强化学习中,通过在多电梯环境下增加环境状态S维度就容易达到算法建模的要求。为了验证本文所提调度算法的有效性,本文针对A3C算法和传统SCAN-EDF算法进行了对比实验,基于SCAN-EDF算法在多部电梯情况之下采用最近派遣法则,即电梯距离需求楼层最近则派遣此电梯。同时本文为了验证不同强化学习算法的性能,引入了调度算法DDQN和MADDPG进行了相关对比实验,DDQN是经典的强化学习算法[19],而MADDPG则是DDPG算法运用于多智能体的升级版算法。对比实验是在固定4小时时长情况下对大楼4部电梯进行联合调度,同时设定4小时人流分布呈现一定非随机性,在初期1小时左右引入早高峰上行,在后期3小时左右引入晚高峰下行,通过引入早晚高峰上下行人流可以模拟当前高层楼宇写字楼的调度环境。
由图7可知在模型训练初期MADDPG算法能够比较好的到达分值区间(-50,-60),但是随后在训练过程中MADDPG却没有表现出更高的分值区间,相反针对DDQN算法和A3C算法在训练初期阶段其得分情况波动较大,大约在60万次训练之后A3C算法表现出了综合得分逐步上升的趋势,最终抵达得分区间大约为(-30,-35),而DDQN算法则达到了得分区间(-45,-55),这说明A3C算法运用多梯电梯调度环境具有一定的优势。同时本实验待强化学习模型训练较收敛后和传统调度算法SCAN-EDF算法进行了对比实验,最终实验调度得分情况如图8所示。
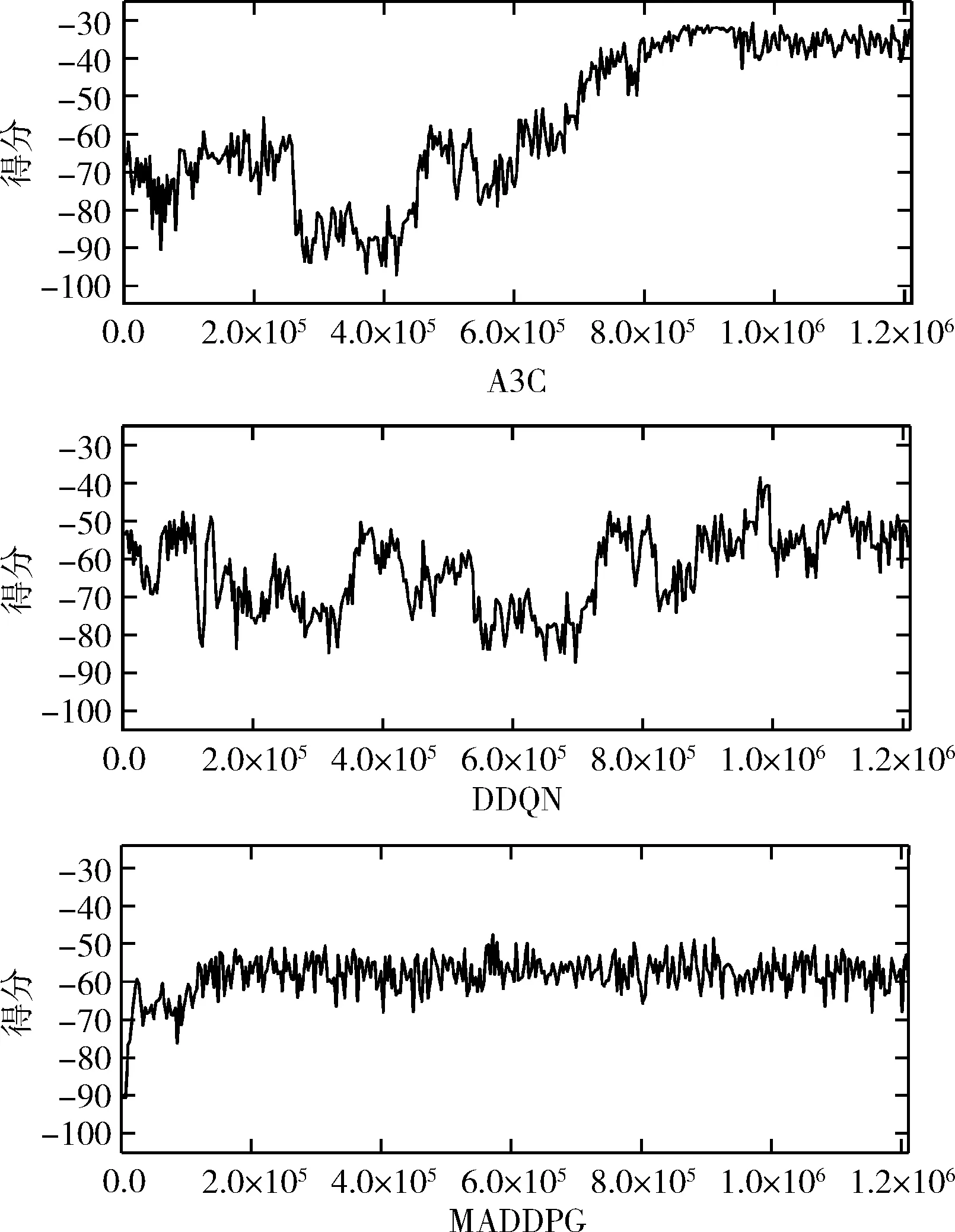
图7 多梯复杂环境下强化学习算法训练过程
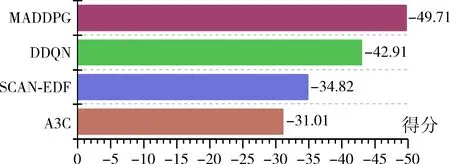
图8 多梯复杂环境下各调度算法性能对比
由图8各调度算法调度综合得分可知,在复杂多电梯环境下由于传统电梯调度算法建模困难,很难做到用户体验和电梯能耗的平衡,而强化学习算法中建模相对简单,由于长时间的模型训练让模型逐渐从和环境的交互过程中学习得到了最佳的调度策略,这说明强化学习运用于复杂环境下电梯调度算法具有可行性,同时对比相关强化学习算法调度分值发现其中A3C算法运用于电梯电梯调度具有一定的优势,更容易收敛。
5 结束语
本文基于强化学习A3C算法构建电梯调度算法,通过对调度环境、电梯行为和调度目标3个方面进行统一建模,让电梯在不断地和调度环境进行交互过程中学习最优调度策略,一方面克服了传统调度算法的建模复杂性,让调度算法在新环境下的也能方便移植,另一方面利用强化学习设计满足用户需求和能耗的奖励函数能有效平衡用户体验和电梯能耗等多方面调度目标。通过进行单电梯和多电梯复杂环境下电梯调度对比实验,实验结果表明强化学习A3C算法经过一定迭代次数的训练之后相比较传统调度算法具有一定的优势,能有效平衡用户用梯和电梯节能需求。同时本文通过对比A3C、DDQN和MADDPG强化学习算法运用于复杂环境电梯调度中的效果,实验结果表明A3C算法具有更好的调度性能,更易收敛。本文所提基于强化学习的调度方法同时也在国网湖北省电力公司科技项目的湖北电网运营监控实用化关键技术研究项目中有进行相关研究,强化学习在诸多调度领域存在运用可能。在以后的进一步研究中,可以结合强化学习和相关深度学习方法进行电梯调度的建模和算法优化,让电梯调度模型更快收敛。
