异质网中基于图卷积神经网络的链路预测方法
2022-02-15蒋宗礼张文婷张津丽
蒋宗礼,张文婷,张津丽
(北京工业大学 计算机学院,北京 100124)
0 引 言
随着信息网络的快速发展,对信息网络进行链路预测已成为数据挖掘领域中的研究热点。在社交网络中,对于任意两个还未互相关注的用户,通过链路预测可以判断他们是否是潜在的好友;在引文网络中,链路预测能够预测作者是否可能在未来进行合作。将网络中的对象和关系分别简化为节点和连边,则在社交网络和引文网络中,节点和连边类型都仅有一种,这样的网络称为同质信息网络。但是现实中网络的节点或连边类型往往不只一种[1],这样的网络称为异质信息网络[2]。
目前信息网络的链路预测方法主要分为基于相似度和基于网络表征学习的方法。基于相似度的方法在不同网络中的预测准确度差异明显,通用性较差;基于网络表征学习的方法大多数是针对同质信息网络提出的,无法应用于更为复杂的异质信息网络。由于异质网络的复杂性和异质性特点,导致在异质网中的链路预测研究依然较少。考虑到异质网中节点类型的不同,本文在经典图卷积神经网络算法的基础上进行改进,提出一种改进的逐层传递规则,有效处理不同类型的节点,对节点表征进行学习,并融合对抗学习优化节点表征。通过基于梯度提升树的二分类算法预测链路是否存在,为异质网中的链路预测提供了新思路,有效提升了链路预测的准确性和稳定性。
1 相关研究
目前常用的链路预测方法主要为基于相似性指标的方法,CN指标通过衡量两个节点之间的共同邻居的数量作为相似性指标,共同邻居越多,则连边存在的可能性越大。PA指标基于两个节点的度数作为相似性指标,连边存在的可能性与节点度成正比。此外,其它的相似度指标还有基于路径的KatZ指标、LP指标等,基于随机游走的ACT指标、SimRank指标等[3]。基于相似性指标的链路预测方法主要的局限是对于不同的网络,其预测性能并不稳定。另一类链路预测方法是基于最大似然估计的方法,主要有层次结构模型和随机分块模型,层次结构模型的问题是计算复杂度太高[4],随机分块模型的整体表现比层次结构模型好,但是对于大规模网络,其性能依然较差。
近年来的网络表示学习为链路预测提供了新方法,网络表示学习将信息网络简化为图的形式,将图中的节点嵌入到一个低维空间中[5]。通过网络表示学习得到节点的低维特征表示,便可以根据节点表征进行链路预测。DeepWalk通过随机游走和SkipGram算法得到节点的特征向量[6]。node2Vec[7]使用两个参数p、q控制随机游走的策略,使随机游走在宽度优先策略和深度优先策略中保持平衡。LINE[8]考虑了节点的一阶相似度和二阶相似度,在稀疏网络和稠密网络中都有良好的表现。图卷积神经网络GCN[9]结合网络结构和节点属性,学习到的节点特征有效融合了其邻居节点的特征。上述研究都是针对同质网的,而现实中的许多网络是包含不同类型节点或关系的异质信息网络。目前,异质网上的网络表示学习方法仍然较少,且绝大部分是基于元路径[10]的。Metapath2Vec[11]通过预先定义的元路径模式进行随机游走,生成符合元路径模式的节点序列,最后使用基于异质网的SkipGram算法学习节点的特征向量。Hin2vec[12]同时学习节点和元路径的特征向量,根据自动生成的多种元路径对节点特征进行联合学习。基于元路径的方法主要的局限在于元路径的选择,往往需要预先进行大量的实验和比较,才能在多种元路径模式中找到较优的模式。
针对以上问题,本文提出异质网中基于图卷积神经网络的链路预测方法。通过对图卷积神经网络GCN进行改进,解决了GCN算法只适用于同质网的问题。改进后的方法能充分利用异质网络的拓扑信息和属性信息,学习不同类型节点的表征。为进一步提高节点表征的效果,融合对抗学习对节点表征进行优化。获得节点的表征向量后,将链路预测问题转换为二分类问题,根据两个节点表征向量的Hadamard积构造节点之间连边的表征向量,并结合基于GBDT算法的二分类器进行链路预测。
2 问题定义
2.1 异质信息网络
对于一个信息网络G(V,E,Tv,Te),V表示节点集合,E表示连边集合,Tv表示节点类型集合,Te表示连边类型集合。每个节点v∈V都对应着其节点类型φ(v)∈Tv, 每条连边e∈E也都对应着其连边类型ψ(e)=Te。 当节点类型或连边类型大于1时,即 |Tv|>1或 |Te|>1时,称G为异质信息网络。图1所示的异质信息网络包含User和Store两种类型的节点。
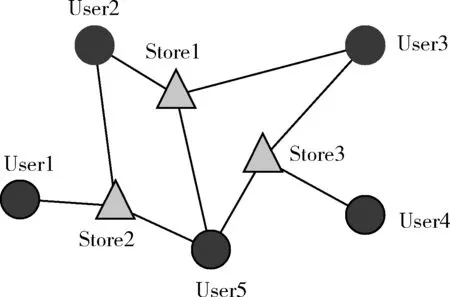
图1 异质信息网络
2.2 异质网中的链路预测
链路预测的目标是根据节点间已知连边及节点的属性,预测节点间未知连边存在的可能性[13]。例如,在异质信息网络G中,节点v1的类型为φ(v1)=a1, 节点v2的类型为φ(v2)=a2, 节点类型a1和a2之间存在连边类型r1, 但节点v1和v2之间尚未观测到连边。链路预测的目标就是通过网络中已知的拓扑信息和节点的属性信息,预测节点v1和v2之间是否存在连边。例如,预测User1和Store1是否相连接。
3 异质网络链路预测模型
本文提出的链路预测模型如图2所示。首先通过HeGCN层、对抗学习层对节点的表征进行学习,通过损失函数的最小化对模型进行更新、优化,最后构造连边表征并预测网络中的链路。
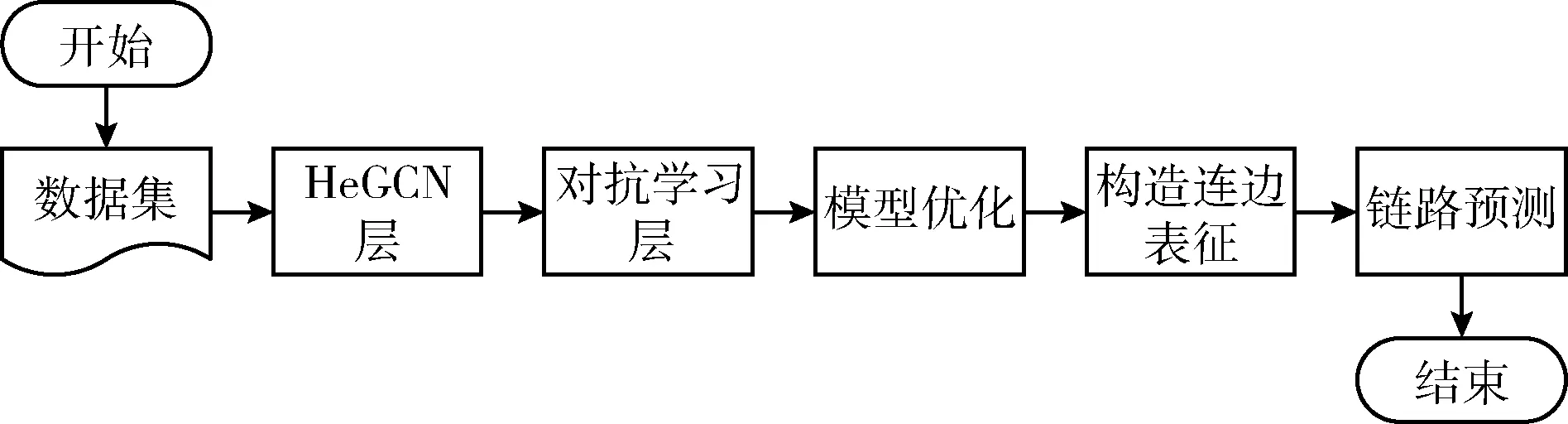
图2 异质网络链路预测模型
3.1 逐层传递规则
图卷积神经网络GCN是一种强大的网络表示学习方法,它结合网络的拓扑结构和节点的属性信息,将网络中的节点表示为低维稠密的特征向量,仅通过两层GCN得到的节点表征就能够十分有效地对原始网络进行表示。但是GCN的逐层传递规则只适用于同质信息网络,针对这一不足,本文提出一种改进的HeGCN逐层传递规则,可以同时处理两种不同类型的节点。
3.1.1 GCN逐层传递规则
图卷积神经网络GCN的逐层传递规则如下
(1)

(2)
(3)
由式(2)、式(3)可知,GCN只能接受N×N的方阵作为邻接矩阵输入,而异质信息网络中不同类型节点的个数并不相同,所以GCN的逐层传递规则不能直接用于异质信息网络。
3.1.2 改进的HeGCN逐层传递规则
由于GCN处理的是相同类型的节点,令节点vi的邻居节点表示为 {vj|Aij=1,j∈[1,N]}, 则vi的所有邻居节点vj的类型与vi相同,由此可知在同质信息网络中,全部节点的邻居节点集合Vneighbor⊆V。 因此在式(2)中的属性矩阵X是由集合V中节点的属性向量构成的。而在异质信息网络中,邻居节点的类型不同。表1给出了异质网络中节点的相关符号表示,令节点vi∈VN的邻居节点表示为 {vj|Aij=1,vj∈VM,j∈[1,M]}, 可以看出vi的所有邻居节点vj的类型与vi不同,即图中所有节点的邻居节点的集合Vneighbor∩V=∅。
本文在GCN的基础上进行改进,提出了适用于异质网的HeGCN逐层传递规则。对于所有vi∈VN, 其邻居节点vneighbor∈VM, 对于所有vj∈VM, 其邻居节点vneighbor∈VN。 由于每个节点的表征与其邻居节点的表征相关联,因此在改进的逐层传递规则中,令vi∈VN对应的属性矩阵为XM; 同理,vj∈VM对应的属性矩阵为XN, 如式(4)、式(5)所示。由于邻居节点的类型不同,在对邻接矩阵A的预处理方面,HeGCN应当做如下改变:

表1 符号表示
(1)节点与其自身无连边。因此不应将初始邻接矩阵与维度为N×N的单位矩阵相加;

综上,得到HeGCN中的两条逐层传递规则:
对于VN, 逐层传递规则为
(4)
对于VM, 逐层传递规则为
(5)
其中,A表示邻接矩阵,AT表示邻接矩阵的转置。DA是A的度数矩阵,DAT是AT的度数矩阵,即
(6)


3.2 HeGCNE模型设计
HeGCNE的模型结构如图3所示,下文将分别说明每部分的具体细节。
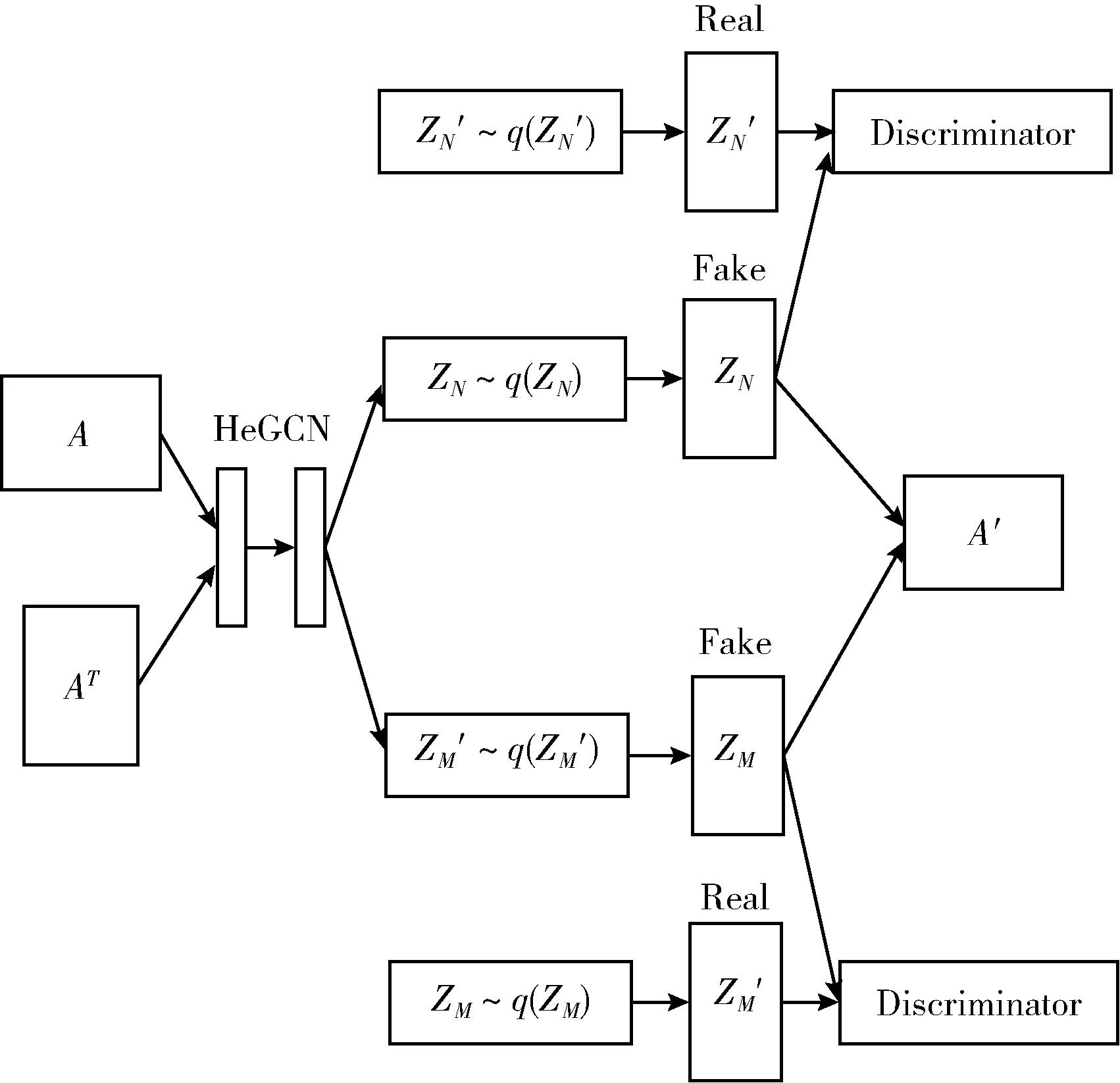
图3 HeGCNE模型结构
3.2.1 HeGCN层
将改进的逐层传播公式应用到HeGCN层中,通过两层HeGCN结构,生成节点表征的高斯分布,如式(7)所示
(7)
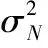
假设节点的先验分布和变分后验分布都服从高斯分布[14],则有
(8)
(9)
(10)
(11)
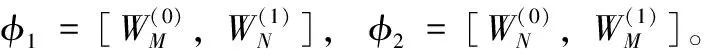
由于在使用后向传播算法对参数进行优化时,需要满足可微条件,因此通过重参数化[14]将节点表征的高斯分布qφ1(ZN|A,XN) 和qφ2(ZM|A,XM) 转换为确定且可微的ZN和ZM。 其中,ZN的维度为N×D,ZM的维度为M×D, 即节点的表征向量都是D维。
3.2.2 对抗学习层
为进一步优化学习到的节点表征,在HeGCN层的基础上进行对抗学习[15]。生成对抗模型一般由两部分组成,分别是生成模型和判别模型。HeGCN层可以看作是生成模型,生成节点的特征分布qφ1(ZN|A,XN) 和qφ2(ZM|A,XM)。 判别模型对输入的样本进行判断,当样本来自先验分布p(ZN) 或p(ZM) 时,将其判断为真样本;当样本来自生成的节点特征分布qφ1(ZN|A,XN) 或qφ2(ZM|A,XM) 时,将其判断为假样本。判别模型的目标是不断提高判断的准确度,也就是要尽可能准确的对真假样本进行区分;而生成模型的目标是生成尽可能混淆判别模型的样本。在两方博弈的过程中,判别模型和生成模型的能力都得到了提高,生成的节点特征分布更接近真实的节点特征分布,因此优化了学习到的节点表征。
3.3 HeGCNE模型优化

(12)
(13)
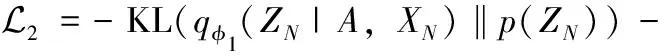
(14)
在对抗学习的过程中,一方面需要提高判别模型D准确判断的能力,即提高z~p(Zi)[log(D(ZN))] 和z~p(Zj)[log(D(ZM))], 对于从节点特征的先验分布中采样的样本,判别模型D要将其判断为真;对于从生成的节点特征分布中采样的样本,判别模型D要将其判断为假。另一方面需要提高生成模型G生成假样本的能力,即提高XN[log(1-D(G(XN,A)))] 和XM[log(1-D(G(XM,A)))], 使其尽可能混淆判别模型D,令判别模型D判断失误。因此,损失函数的第3部分为

(15)
3.4 连边表征构造与二分类
通过3.3节对模型进行训练,得到了节点表征ZN和ZM,本文没有直接根据重建的邻接矩阵或通过计算节点表征的余弦相似度进行链路预测,而是将链路预测问题转化为二分类问题,先构造连边表征,如图4所示。然后将连边表征与梯度提升树(gradient boosting decide tree,GBDT)算法相结合进行二分类,若节点对有连边存在,则其对应的标签为1,否则标签为0。通过对两个节点表征做hadamard积可以有效融合节点表征,构造出连边表征,如式(16)所示。其中,⊙表示hadamard积,
Feature(
(16)
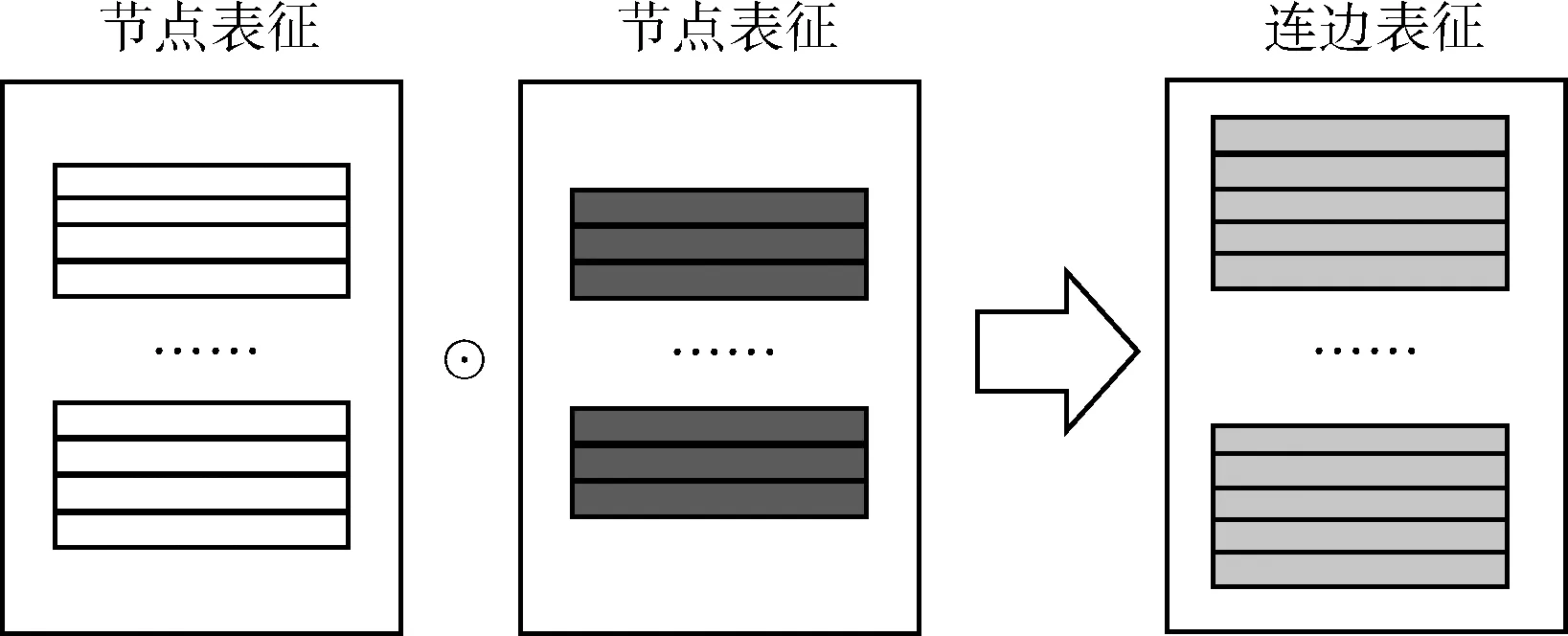
图4 连边表征构造
使用梯度提升树进行二分类时,在算法的每一步都会通过一棵决策树对分类器当前的残差进行拟合,训练出一个新的弱分类器,将所有的决策树综合起来,就可以得到一个强分类器。使用梯度提升树分类的优点主要有3点:①在每一棵决策树对残差的计算中,被正确分类的样本所占的权重减小,分类错误的样本所占的权重增大,即着重考虑那些被错误分类的样本,使得泛化能力得到增强。②梯度提升树中的非线性变化较多,分类能力强。③梯度提升树可以对每一维特征的重要程度排序,高效且自动地进行特征组合。
4 实验与分析
4.1 数据集
本文采用DBLP和YELP两个真实数据集进行实验。在DBLP数据集中,有论文和作者两种类型的节点,表示论文的节点共有14 376个,表示作者的节点共有14 475个,实验对“论文-作者”进行链路预测,即判断论文是否被作者所写。在YELP数据集中,有商店和用户两种类型的节点,表示商店的节点共有2614个,表示用户的节点共有1286个,实验对“商店-用户”进行链路预测,即判断用户是否去过商店。数据集的信息见表2。

表2 数据集的具体信息
4.2 评价指标
链路预测任务的常用评价指标为AUC和AP指标。AUC指标是ROC曲线下的面积,表示随机抽取一个正例和负例,分类器将正例排在负例前面的概率。AUC值越大,意味着分类器越有可能将正例排在负例前面,因此分类器的表现越好,AUC值越接近1,而一个纯随机分类器的AUC值为0.5。在链路预测任务中,AUC值越大,表示越有可能从所有的节点对中,选出有连边存在的节点对。AP指标是PR曲线下的面积,在链路预测任务中,AP指标也可以用来衡量预测的整体表现。
4.3 基准算法与参数设置
为了验证本文方法的有效性,分别与PA、DeepWalk、Hin2vec进行对比。HeGCNE的参数设置如下,HeGCN层的维度分别设置为64和32,对抗学习层的维度分别设置为32和64,迭代次数设置为200,学习率为0.01,采用Adam 算法进行模型的更新优化。
(1)PA指标:基于节点度数作为链路预测的指标,其思想是连边存在的概率与节点度数成正比,因此节点x和节点y之间连边的存在概率与两节点度数的乘积成正比。分别用k(x)、k(y) 表示节点x和节点y的度数,则PA的相似度计算公式为Sxy=k(x)·k(y);
(2)DeepWalk:通过一系列的随机游走生成固定长度的由节点构成的随机游走序列,将SkimGram算法应用到随机游走序列中学习节点表征。得到节点表征后,通过重建邻接矩阵进行链路预测;
(3)Hin2vec:同时学习节点和元路径的表征,结合多个元路径的信息,通过多任务学习生成节点的表征。得到节点表征后,通过重建邻接矩阵进行链路预测。
4.4 实验结果与分析
在DBLP和YELP数据集上,随机去掉20%的边作为测试集,剩余80%的边作为训练集,将HeGCNE和3种基准算法进行对比,实验结果见表3。
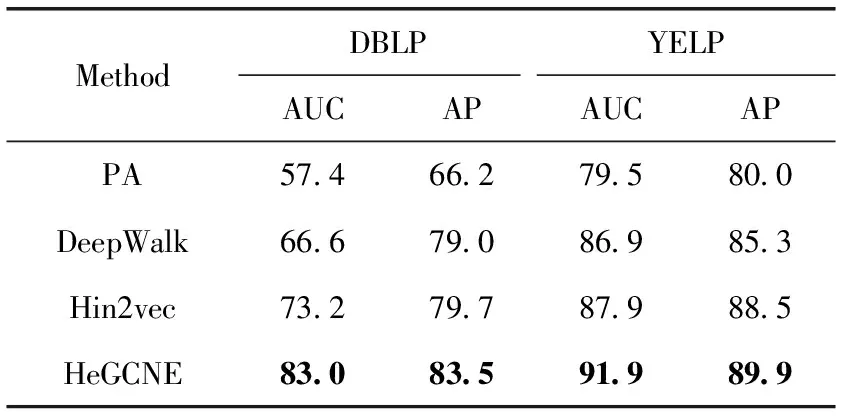
表3 不同算法的链路预测性能对比/ %
从表3的数据可以看出,在DBLP和YELP数据集上,HeGCNE相对于3种基准算法的性能均有所提升,且AUC、AP评价指标均达到83%以上,说明本文提出方法可以有效地对异质信息网络中的链路进行预测。在DBLP数据集上,HeGCNE的AUC指标比PA、DeepWalk、Hin2vec分别提高了25.6%、16.4%、9.8%;HeGCNE的AP指标比PA、DeepWalk、Hin2vec分别提高了17.3%、4.5%、3.8%。在YELP数据集上,HeGCNE的AUC指标比PA、DeepWalk、Hin2vec分别提高了12.4%、5.0%、4.0%;HeGCNE的AP指标比PA、DeepWalk、Hin2vec分别提高了9.9%、4.6%、1.4%。分析在不同数据集上4种算法的表现,可以发现在YELP数据集上4种算法的表现整体都优于DBLP数据集,这是因为YELP数据集的网络稠密程度相对更高,所以预测的准确性更高。而DBLP数据集的网络极为稀疏,在这种情况下,PA算法的准确性明显降低,说明了PA算法对于不同网络的预测性能并不稳定。本文方法在稀疏的网络中依然能够取得良好的表现,验证了本文方法的有效性和稳定性。
上述实验结果表明,本文方法能够有效提高链路预测的性能,而训练集与测试集的划分比例、学习节点特征时的迭代次数也会对链路预测的结果产生影响,因此采用控制变量法,分别改变训练集的比例、迭代次数进行实验,并对实验结果进行比较,如图5~图8所示。

图5 不同训练集比例的AP值

图6 不同训练集比例的AUC值

图7 不同迭代次数的AP值
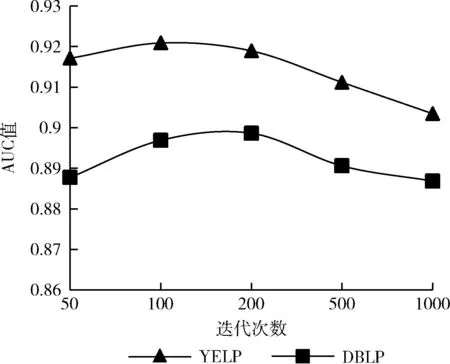
图8 不同迭代次数的AUC值
首先,固定训练次数为200次,将训练集的比例分别设置为10%、30%、50%、70%、90%。从图5、图6可以看出,在数据集YELP和DBLP上,AUC指标和AP指标均随着训练集比例的增加而增大,且增长幅度呈逐渐减弱的趋势。当训练集的比例为70%时,在两个数据集上都有着不错的预测效果,AUC指标和AP指标都在0.8以上,在YELP数据集上,两个指标可以达到0.9左右。另外,当训练集比例为30%时,在YELP数据集上两个指标接近0.8,这说明对于较为稠密的网络,仅已知小部分的拓扑信息,也可以达到良好的预测效果。
其次,固定训练集的比例为80%,将训练次数分别设置为50、100、200、500、1000次。从图7、图8可以看出,当迭代次数在200次左右时,AUC指标和AP指标达到较高水平,之后随着迭代次数的增加,呈现持平或下降趋势,这是因为当模型训练的迭代次数过多时,会出现过拟合现象,因此迭代次数并不是越多越好,选取合适的迭代次数即可。对于本文所提方法,较少的迭代次数即可获得不错的预测结果。
5 结束语
本文提出了一种异质网中基于图卷积神经网络的链路预测方法,综合异质网络的结构信息和语义信息,学习不同类型节点的表征,并融合对抗学习来优化节点表征。获得节点表征后,通过求Hadamard积构造连边表征,使用基于梯度提升树的二分类方法进行链路预测。在数据集DBLP和YELP上,将本文方法与PA、DeepWalk、Hin2Vec这3种基准算法进行对比。实验结果表明,本文方法使异质网络中链路预测的准确性和稳定性都有所提升。但本文方法只能同时处理具有两种类型节点的异质信息网络,在未来研究中,可以从多类型节点的输入和并行性方面进行改进。
