融合图像元数据的用户情感分类
2022-02-15吴彦文何华卿冉茂良
吴彦文,严 巍,何华卿,冉茂良
(1.华中师范大学 国家数字化学习工程技术研究中心,湖北 武汉 430079; 2.华中师范大学 物理科学与技术学院 信息处理与人工智能研究所,湖北 武汉 430079)
0 引 言
对社交网络上用户进行情感分析是个性化推荐、舆情监测等多个应用领域的重要手段。现有的情感分析大多从用户在网络上生产的文本入手,运用自然语言处理等技术进行分析[1,2]。随着卷积神经网络处理图像信息能力的大幅提升,通过上传的图像来分析用户情感的研究[3-5]也越来越多,取得了不错的情感分类效果。李志义等[5]利用改进的卷积神经网络(CNN)对图像的纹理、颜色作为输入,经过多层的网络自动提取图像的情感特征,构造出准确率更高的图像情感特征提取模型。LiL等[6]提出层次卷积神经网络,利用不同级别特征之间的依赖关系,对高低刺激进行学习表示后建模,基于融合刺激预测情感,同样取得了不错的效果。但是用户对图像情感具有一定主观性,而且人的情感是与人当时所处环境、所拍摄内容等多方面因素相关,以上单从图像层面进行情感分类的方法忽略图像背后的情境信息,而情境中却隐含了丰富的情感信息[7],因此很难对用户细粒度情感进行精准捕捉。
基于以上问题,本文在现有的基于深度学习图像情感分析的基础上,融入图像元数据中的情境信息,希望能够综合图像特征和图像背后的情境特征,从而扩大数据的特征域,利用卷积神经网络、embedding特征嵌入,多特征融合等深度学习方法提升情感识别的效果。
1 相关研究
1.1 图像情感分析
图像情感分析由于其主观性的原因,一直是图像领域的难点问题之一。其发展分成了两个阶段,其一是基于图像视觉低层次特征的提取,包括颜色、线条、纹理和形状等不具有语义信息的特征。周云蕾等[8]在风景类图像上,根据不同颜色特征和情感特点,建立图像颜色特征与用户评价之间的关系,结合图像的颜色直方图对风景图像的颜色特征进行提取,利用SVM进行情感分类,取得了较好的准确率。蔡国永等[9]考虑到图像整体和局部对于突显情感色彩的差异性,提出了嵌入图像整体特征和图像局部特征来预测图像情感极性的方法。其二是以卷积神经网络为代表的一系列深度学习方法,在图像分类和视频分析取得了巨大成功。研究证实[10]神经网络提取的特征比手动设计表现更好,原因在于神经网络能够学到在特定任务上的特征应该如何表示,这个选取特征的结果是网络学习的过程。Acar等[11]研究了如何通过可视化与其情感相关的局部图像模式,将CNN专门应用于视觉情感预测任务。Xu等[12]运用迁移学习的思路,首先在Image-Net数据集上训练好卷积神经网络,然后在情感图像分类任务上对模型参数进行微调,加快了模型的训练速度。
因此可见,低层次特征受限于人为主观意识的判断和手动设计特征提取的繁琐,分类效果不如端到端的神经网络方法,但是深度学习的方法目前只针对图像单一特征域进行分析,忽略了图像背后的情境信息,因此本文将利用图像元数据中的情境特征来增强图像情感分类的效果。
1.2 用户情境建模
情境是描述事物所处的位置、环境(包括温度、噪声、光照等)的一种客观的上下文信息。用户情境建模的目的是建立用户情境在该环境中统一的数字化表示,这方面的工作可以追溯到很早,移动设备还没大量流行时,主要依靠一些人工制定的规则,通过GPS等进行触发。随着移动情境数据开始丰富,一些学者运用机器学习的模型进行情境建模,吴书等[13]在进行用户行为预测的场景中,采取了基于表示学习的情境建模框架。K Luddecke等[14]利用面向对象的表示方法开发了CML(context modelling language)语言快速从数据库进行情境数据建模。利用图像元数据进行情境建模的应用和研究也有一些,Subudhi等[15]基于照片的位置信息分析游客的情绪活动,绘制出“情绪地图”,Hossain等[16]考虑到人们回忆照片的特点(场景式记忆),融合图像内容和照片位置等元数据打造场景式搜索平台,用户可以通过一场景式描述(比如:下午在武汉东湖骑车,天气晴朗),快速检索自己相册的相关照片,很大程度提高了检索体验和检索效率。
可见情境建模的方式比较灵活,不同场景、不同数据格式的侧重点不同,由于本文拍照场景中主要数据来源于图像元数据,利用图像元数据建模来增强图像情感分析的效果也是本文的创新点之一。
2 关键技术
本研究的思路和研究过程如下:在对用户的情感状态建模的过程中,一方面利用图像元数据进行情境-情感的特征embedding,得到情境特征fe, 另一方面,运用当前卷积神经网络在图像处理的优势,从vgg19预训练模型获取高维度特征feature map,再根据feature map计算gram矩阵以表示图像纹理特征fs, 最后与原始feature map中图像内容特征向量fc进行拼接得到最终图像特征f3。 情感识别网络结构较为简单,只含有一个隐层的神经网络,来进行情感分类,从而达到对用户情感状态精准捕捉的目的。本文研究流程如图1所示。
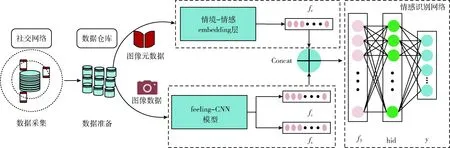
图1 本文研究流程
接下来从情境-情感embedding特征选取、数据预处理、特征编码,feeling-CNN的结构设计,gram矩阵表示纹理特征以及特征向量拼接的细节进行详细阐述。
2.1 用户拍照情境建模
该部分主要围绕了拍照场景的两个维度进行特征选取,分别为用户行为特征、上下文特征。其信息形式化表示为: UC={Behaviour_info,Context_info}。 为了研究的可行性,本节选取的特征都是可以通过移动设备或者社交软件直接或间接获取,Exif 是图像元数据的一种,能告诉我们这张照片完成时,在何时何处,用了什么参数、什么设备。它记录了照片的分辨率大小、拍摄时间、感光度(ISO)、快门时间、焦距大小、曝光等数据,通过经纬度还能查询出具体的位置信息,其中有些特征是连续值,比如ISO值,需要进行离散编码。情境建模工作流如图2所示,在进行本研究时应该考虑保护用户的隐私安全问题。
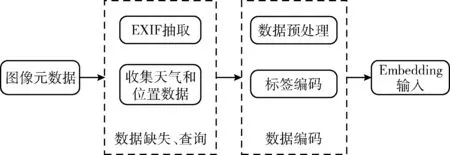
图2 情境建模工作流
2.1.1 用户行为特征
行为特征维度为了刻画出用户拍摄图像时的拍照模式,光圈大小,滤镜风格,比如小光圈的照片通常是使用在拍摄自然风景的远景上,能够推测用户在拍摄的时候想要表现的内容和情感,更有可能存在敬畏的正向情感。悲伤一类的消极情感的光线较暗,ISO感光度偏高,再比如滤镜风格是暖色调,通常预示着用户此时可能更多的感受是温馨一类的情感。
用户行为的信息化表示为: Behaviour_info={Photo_model,ISO,Aperture,Exposure-time,Filter_model}, 其中本文中选取Photo_model表示相机拍照模式(选取广角、夜景、慢拍、人像、微距等6个常用模式),ISO,Exposure_time和Aperture分别代表感光度,曝光时间和光圈大小,Filter_model表示用户对图像加以滤镜修饰的类别,由于滤镜风格太多,本文将滤镜分类简化成冷和暖两类,为了验证以上行为特征对于情感分类的有效性,对本文使用的IEST数据集中8种情感分类图像的这3个特征进行统计分析,对值进行归一化处理,结果如图3所示,不同情感的图像,这些特征的分布具有差异性,比如敬畏类的风景图居多,光圈值明显低于其它类别,说明这3个特征对于情感具有一定区分能力。因为接下来需要将这些特征通过embedding层,所以需要将连续值特征离散化,比如感光度,曝光时间和光圈大小离散化,然后进行类别编码,用户行为特征按照表1进行编码。
该部分还包括了用户的基本特征,比如用户的姓名、年龄、性别等。用户基本信息的标签信息化表示为: User_info={Uuid,Name,Sex,Age}, 其中Uuid为用户唯一标识,name是用户的姓名,sex为用户性别(本文划分为男/女),Age为用户年龄大小(本文划分为18以下、18~25、25~40、40~60、60以上5个区间),因此基本信息特征的编码分为3层layer分别嵌入,特征嵌入之后的维度为3,见表1。
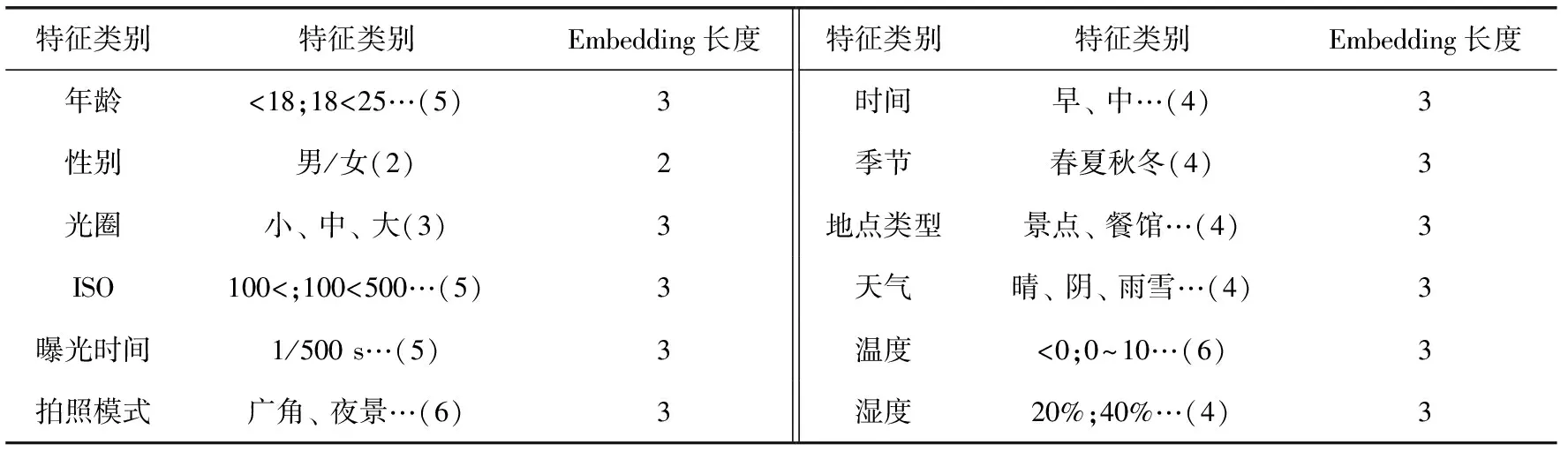
表1 特征Embedding细节
2.1.2 上下文特征
该部分包括了时间信息、位置信息和天气信息3个方面。
(1)时间从日期“年月日”到具体一天中时间段中的早中晚,比如人们在深夜更容易流露真实情感。形式化表示为: Time_info={datetime,season,parttime}, 其中datetime表示具体日期(2019年12月1日星期日),season表示季节(春夏秋冬),parttime表示一天中的时间段(早上、中午、下午、深夜)。
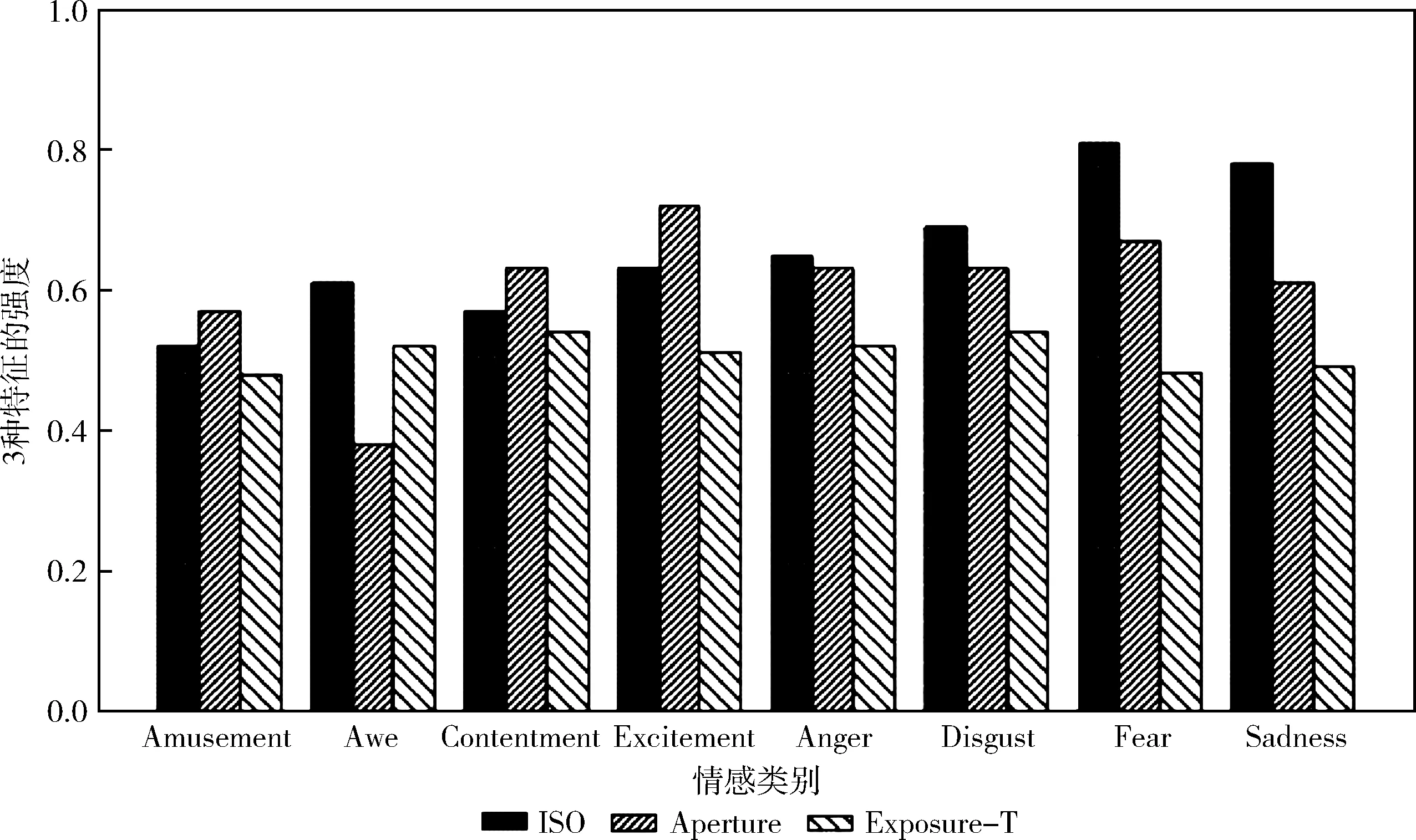
图3 不同情感类别行为特征分布
(2)位置特征划分成6个类别,分别是景点、餐馆、运动场、游乐场等。比如用户来到一些比较壮阔的景点,像黄果树瀑布,可能会充满对自然的敬畏之心,在游乐场更有可能产生积极的情感。信息位置标签形式化表示为: Location_info={city,position,pos_type}, 其中city代表城市,position代表城市中某个区域,可以是具体景点或者区域,pos_type表示该地点属于什么类型,本文选取了(景点、餐馆、运动场、游乐场等6个地点类型)作为特征进行embedding。
(3)天气特征,包括了具体天气、温度、湿度,比如在阴天、32 ℃、相对湿度60%的夏天,用户感到烦躁的可能性会增大。形式化表示为: Weather_info={weather,temperature,humidity}, 其中天气的类别有晴天、阴天、雨天、下雪,温度按照从低到高分成5个等级,湿度按同样规则划分。
综合上述特征,如表1所示,对不同的特征进行embedding嵌入,根据特征类别多少,选取不同的嵌入向量长度。
总的来说,以上情境特征选取的原则是尽可能捕捉用户在特定情境中的情感状态信息,从而为后面融合图像情感,综合对用户情感状态建模,其中某些情境信息(天气、地点类型等)不能直接获取,但通过位置和时间信息能够从气象台等网站或查询工具API 间接获取,最终得到更加精准的分析结果。
2.1.3 情境-情感embedding层
上面3小节我们通过对图像元数据进行标签编码,由于深度学习对于稀疏特征的训练会有收敛慢的问题,因此使用一层embedding层作为特征映射,词向量作为embedding的代表产物,在NLP(自然语言处理)领域的很多任务大放异彩,其可以通过学习的方式得到每个词语在低维度的向量表示形式,这是一种分布式的表示方式。后来广泛应用于深度学习的各个领域,作为神经网络的输入映射层,在众多应用中能够得到更好的分类效果[16],其核心思想是将高维特征通过训练学习的方式得到低维的向量表示。通过从图像元数据中抽取到的特征,一共组成了12种特征,相当于自建的词典,然后通过下面的embedding层映射到稠密低维向量,embedding层的设计如图4所示。
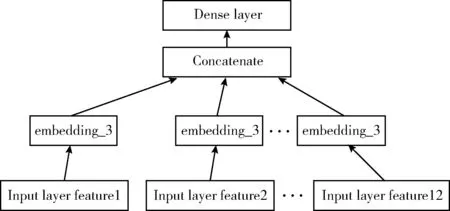
图4 嵌入层网络结构
根据图像元数据直接和间接获取的特征包含了用户基本特征、用户行为特征、上下文特征共12种特征,其形式化表示为
(1)
li表示的是特征i的one-hot编码向量,embedding层Mi是一个Rk×h的矩阵,k表示特征i的维度,h表示特征i经过embedding之后新的维度,得到的ei是一个h维的向量,也就是特征i新的向量表示,接下来对12种特征进行向量拼接形成Ldense, 因为拼接方式是Concatenate,最终得到Ldense的大小是36维的向量。
因此可见,情境-情感embedding的作用在于,将原本稀疏的图像元数据的one-hot情境特征经过embedding的方式映射成了稠密的低维向量形式,这样做的目的是为了神经网络训练更快地收敛,也提高了最终的情感分类效果。
2.2 基于CNN的视觉情感分析
卷积神经网络通过卷积核共享操作使得神经网络在图像分类领域取得了前所未有的成果,其中经典的vgg19网络由3部分组成,特征提取层、自适应池化以及最后全连接层构成分类器,很多后续关于图像的研究都是用在Image-Net上预训练的vgg19网络的特征提取层,固定其参数,根据需求重新构建然后微调全连接层参数,本文也是采取这个策略。但本文还单独抽取conv5_1的feature map,构建gram矩阵作为纹理特征的表示,前面研究已经证实,纹理特征也隐藏了图像的情感信息[3],最终实验也验证了,引入gram矩阵的确对分类效果有一定提升。图5是本文根据vgg19的基础架构改进得到的feeling-CNN架构图。
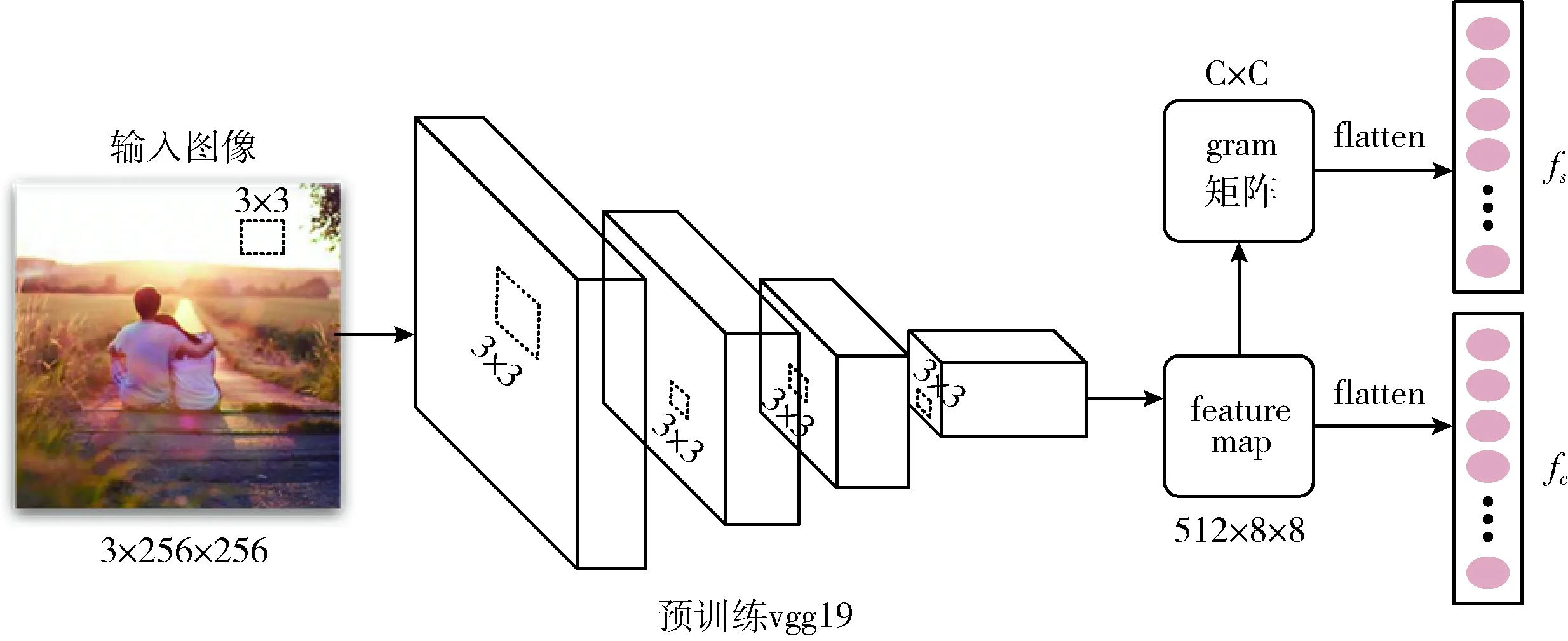
图5 feeling-CNN的网络结构
从上面的结构可以看出,feeling-CNN包含了两个阶段,第一阶段是特征提取,通过已经在ImageNet上预训练的vgg19的feature extraction模块,固定其模型参数,能够得到feature map,该feature map代表了图像的高层次语义特征。第二个阶段是对feature map进行两种处理,一个是纹理特征提取模块,通过对feature map 进行channel-wise的矩阵运算,得到了gram矩阵,表示图像的纹理特征,然后feature map原本就是图像内容特征的表示,最后通过Concatenate(向量拼接)的方式进行内容特征和纹理特征的融合,并且加入了融合系数进行两部分基本结构CNN采用的是联合学习的方式进行训练。
第二个阶段中,gram矩阵的计算由feature map通过channel-wise 维度的矩阵相乘得来,feature map的形状为RC×H×W, 其中C表示通道数,W和H表示宽和高,C的真正含义是上一层卷积核的个数,也就是代表了C种不同的特征,先将feature map变成RC×N的形状,于是,feature map可以重新表示成如下式所示
f=[α1,α2,α3,…,αc]
(2)
其中,αc表示的是通道c中每个神经元组成的N维向量,其中N等于H与W的乘积,gram矩阵的表示如下式所示
(3)
其中, 〈αi,αj〉 表示向量内积,得到的是一个标量,根据gram矩阵的计算公式得出,gram矩阵的大小是RC×C, 而且是对称实矩阵,G(i,j) 的含义是通道i与通道j的相关性,不同的通道代表不同的滤波方式,表示不同的特征,这里的feature map的通道数为512,为了使网络训练收敛更加快速,对每一行的元素的值进行softmax操作,归一化0-1的范围。考虑到重复的元素以及对角线的元素,对gram矩阵进行flatten操作,将其reshape成512×512/2的向量。至此得到了关于图像的纹理特征的向量表示方式。
对于图像内容特征的表示,则是直接对feature map 进行flatten操作,类似cnn模型全连接层的作用一样,对所有特征进行全局的融合,得到了形状为512×8×8长度的向量。
3 实验与结果分析
3.1 实验数据集
3.1.1 情感标注图片数据集
为了对本文模型和算法进行验证,选取Flickr社交网站上的照片整理的数据集作为图像情感训练数据集。对于图片情感标注的方式有3种,一是采取搜索图片时的情感关键词作为标注,二是人工标注,但是人工标注的工作量巨大,三是通过每张图片下面的用户评论文本分析来标注图片情感,Zhao等[7]已经用第3种方式将把标注的数据集开源出来。本文选用Image-Emotion-Social-Net(IEST)的图像作为实验数据集。
该数据集情感分类包括有趣(Amusement)、敬畏(Awe)、满足(Contentment)、兴奋(Excitement)、生气(Anger)、恶心(Disgust)、恐怖(Fear)、悲伤(Sadness)8种情感类别。
3.1.2 图像元数据获取
本文中,图像元数据是获取情境信息的重要途径,但是在社交网络上越来越多的用户隐私安全越来越重视,因此对于表2中的图片,有很多图片存在元数据缺失的情况,针对这一问题,我们重新对数据进行了筛选,剔除掉没有EXIF的图片,各情感类别的图片数量减少了近2/3,见表3,对于地理位置,天气等需要通过第三方API查询的信息,实验中位置信息使用百度地图开放平台-反Geocoding,给定图片EXIF中的经纬度参数,天气信息通过百度地图开放平台-天气查询获取,如图6所示。

表2 各情感类别图片数量

表3 各情感类别图片数量(with EXIF)

图6 Flickr网站上图像元数据以及 通过API查询的位置、天气信息
3.2 实验设计与结果分析
3.2.1 模型参数设置
根据前面对本文模型的叙述,模型分为3个部分,情境特征的embedding,feeling-CNN对图像内容特征和纹理特征的提取,以及最后综合3种特征进行分类的情感识别网络。由于整个模型包含的参数非常多,而且数据集的量还不够大,对于深度学习的训练来说是很大的挑战。为了解决这个问题,本文也借鉴迁移学习的思想,通过迁移图像分类的模型参数(相似领域)到图像情感分类当中,以提高模型的泛化能力以及加快收敛速度,具体做法是通过固定vgg19在Image-Net上训练好的参数,去掉其全连接层,然后在情感识别网络隐层中设置了1000个神经元,以及全连接层中修改为8个神经元,对于新的情感类别8类,并且用零均值,0.01标准差的高斯分布初始化网络参数。
模型训练的batch选择为32,即每一批次输入32张图片进行训练,激活函数选用Relu,为了防止过拟合,采用dropout,dropout参数设置为0.5,使用的深度学习框架为pytorch,模型的训练和测试均在Google colab深度学习平台进行实验,显卡为Tesla K80内存为11 G。
3.2.2 图像情感分类实验
根据本文中情感分类所使用到的特征的种类,分为来自图像元数据的情境特征、图像内容特征、图像纹理特征3种。为了验证本文提出的融合图像元数据对于图像情感分类效果的有效性,分类进行横向和纵向的实验进行比较。
纵向对比实验,选取了不同的模型,包括低维度图像特征+SVM分类器的方法、DeepSentiBank方法[17],以及基于CNN的各种基本模型以及对应的微调模型,这里选取准确率作为性能指标。通过表4可以看出本文方法对比之前模型的分类效果均有不小的提升,图7是把分类结果通过混淆矩阵的形式可视化出来。

表4 模型分类效果对比
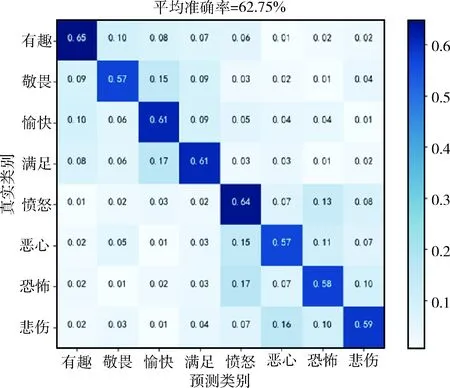
图7 多类别情感分类混淆矩阵
横向对比实验,针对本文使用的不同的特征组合方式进行实验,验证研究的有效性。为了让比较结果更加细致全面,这里性能指标选取了精准率、召回率、和F值,实验结果如图8所示。

图8 不同特征组合的分类效果
3.2.3 结果分析
由表4可知,加入情境特征和纹理特征后比之前的方法有明显的提升,具有更高的准确率,直接使用vgg19模型进行微调的准确率是58.63%,加入拍照情境特征和图像纹理特征后均有小幅度的提升,分别有2%和3%的提升,在图8中,更加详细的展示出了两种新的特征的融合对于精准率、召回率、F值的提升效果。说明图像元数据和图像纹理对于图像情感分类的有效性,而且特征组合的方式比单一的特征效果也更好。由图7可知,对于积极和消极的情感分类的类间效果较好,但是对于类内分类,比如消极情感中的悲伤和害怕的误分率较高,这也是情感分类中难点之一,细粒度情感分类效果也是本文后续研究之一。
4 结束语
社交网络上用户情感分析是一项具有挑战的任务,本文考虑到图像元数据中,不同情感类别情境特征分布的差异,并融合到现有的深度学习的图像分析方法来增强情感分类效果,该方法首先迁移预训练的vgg19网络参数构建feeling-CNN进行特征提取,并利用得到的feature map计算gram矩阵来表示图像纹理特征,然后结合embedding方法将图像元数据中的拍照情境特征融合进来,最后将多种特征向量进行拼接后,输入到只含一个隐层的情感识别网络进行情感分类。最终在Image-Emotion-Social-Net(IEST)数据集上进行实验,实验结果表明,本文提出的融合图像元数据的方法可以获得更高的情感分类准确率。
该方法虽然通过增加新的特征域来更精准的捕捉用户情感信息,但同时也带来了跨领域特征的问题,让深度学习训练难度增大,再加上用户隐私保护意识导致图像元数据不完整,部分特征存在数据稀疏问题,影响分类效果,如何更好处理这些问题有待进一步研究。
