K-means‖隐私保护聚类算法
2022-02-15冷碧玉
郑 剑,冷碧玉
(江西理工大学 信息工程学院,江西 赣州 341000)
0 引 言
随着大数据时代的降临,各类数据呈现出爆炸式地增长,为揭示数据中的内在规律和性质,聚类分析被广泛应用;但在收集分析数据获得数据价值的同时,还需保证数据的隐私安全,使数据不被有心人士利用造成难以弥补的损失。因此对于未标记数据信息的价值挖掘及隐私保护成为近年来的热门研究问题。因为k均值聚类算法原理简单、聚类速度快,故对k均值聚类算法的隐私保护研究热度只增不减,但基于已研究的k均值隐私保护算法都未考虑全面,如几十万条数据甚至几百万条数据进行聚类时,k均值算法聚类过程中k值和聚类初始中心点敏感、离群点[1]处理及分布式数据集聚类时如何保护数据隐私等[2-4]问题。文献[5]针对k均值聚类算法对初始中心点敏感及中心点更新会泄露隐私的问题,提出DPk-means++方法,对k均值的改进算法k-means++利用拉普拉斯机制[6]解决了k均值聚类算法随机选取k个中心点不能保证聚类精确度及数据隐私泄露的问题,但未考虑数据集中离群点问题;文献[7]提出在k均值算法中应用局部差分隐私以适应不同用户的隐私需求,但未考虑整体隐私预算;综合考虑k均值聚类算法对初始中心点的敏感及聚类过程中隐私泄露的问题,对存在离群点的大规模数据集聚类问题,借鉴文献[8]中的k-means‖聚类算法,结合差分隐私保护模型,提出适用于存在离群点的大规模数据集聚类分析的隐私保护方法DPk-means‖(differential privacy of k-means‖),在选取聚类初始中心点时引入且实现差分隐私保护机制,有效地保护了特定数据隐私,且由实验结果表明,DPk-means‖聚类算法在注入少量随机噪声的情况下,保证了对存在离群点情况的鲁棒性,能够保证聚类结果准确性的同时将数据泄露的风险控制在安全范围内。
1 相关知识
1.1 差分隐私
差分隐私(differential privacy)[9,10]建立在假定攻击者拥有最大背景知识的前提下,注入特定分布的随机噪声,定量地分析使用查询算法导致敏感数据被披露的风险,差分隐私使得目标数据记录是否在数据集中并不影响查询结果,即目标在或不在数据库中,算法查询得到相同数值的概率非常接近,使得攻击者分析不出目标数据的详细信息,因此在保证数据可用性的情况下,同时又保证了数据的隐私安全。
定义1 (ε,δ)-差分隐私[10]。给定一个随机查询算法M,对于任意邻近数据集D和D’,若M在数据集D和D’查询下得到的结果s(s∈Range(M)) 满足式(1),则称随机查询算法M满足(ε,δ)-差分隐私
Pr[M(D)∈s]≤eε×Pr[M(D’)∈s]+δ
(1)
其中,Pr[·]表示应用随机查询算法M数据可能被泄露的风险;ε表示随机查询算法M所能够提供的隐私保护水平,当ε=0时,敏感数据的隐私水平达到最高,但此时数据的可用性最低,故ε的最佳取值可使得输出结果的隐私保护程度与数据的可用性达到平衡;δ表示允许每个目标数据都会存在δ大小的概率隐私会泄露,δ的取值通常是很小的常数,当δ=0时,则称随机查询算法M满足ε-差分隐私。
定义2 拉普拉斯机制。给定一个数据集D,假定有一个函数f∶D→Rd, 函数f的敏感度为Δf,如果随机算法M满足式(2),则称算法M满足ε-差分隐私
M(D)=f(D)+Lap(b)
(2)
其中,Lap(b)服从位置参数为0,尺度参数为b,且b=Δf/ε。
1.2 差分隐私组合性质
如果需要保证复杂过程中数据的隐私不被泄露,一般都需要多次应用到差分隐私的组合性质。借由差分隐私的组合性质界定复杂过程中各个阶段的差分隐私预算,利用差分隐私的组合性质计算出为保护数据隐私每个细分过程中分配的隐私预算。
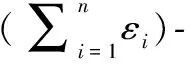
性质2 并行组合性。假设现有n个算法M1,M2,…,Mn, 其中每个算法的隐私预算分别为ε1,ε2,…,εn, 对于不相交数据集D1,D2,…,Dn, 则组合算法M(M1(D1), M2(D2),…,Mn(Dn)) 满足(maxεi)-差分隐私。
1.3 k均值聚类算法
k均值聚类算法采用数据点与中心点间的距离作为相似度评价的指标,认为数据点与中心点间的距离越小,则相似度越高,即数据的属性特征越接近,不同的聚类个数或聚类初始中心点会造成k均值聚类算法的聚类结果不同,因此k均值聚类算法对于聚类初始中心点的选择和聚类个数较为敏感;除此之外,若选择离群点作为聚类的初始中心点,会对聚类结果存在一定的影响,所以k均值聚类算法对离群点的存在也较为敏感;故k均值聚类算法主要存在3个敏感问题:
(1)聚类开始前事先人为给定的聚类个数k;
(2)聚类随机确定聚类初始中心点;
(3)数据集中的离群点。
事先给定聚类个数是针对已知所给数据集的数据可分为簇的个数而言的,确定的聚类个数能够使聚类精确度较高;对于未知簇的数据集来说,使用手肘法和轮廓系数综合分析能够得到未知簇数据集的较优聚类中心点的个数可解决敏感问题(1);本文主要对随机确定的聚类初始中心点及离群点敏感问题的解决,保证聚类数据集的可用性的同时保护聚类数据的隐私,具体细节在第2大节中详细说明。
1.4 k-means‖与k均值聚类算法初始中心点选择对比
k-means‖是对于k均值聚类算法的改进算法,解决了k均值算法对初始中心点敏感的问题。k-means‖聚类算法确定聚类初始中心点的步骤如下所示:
(1)先从数据集中随机选取一个点作为第一个聚类初始中心点c1;
(2)在数据集中选择剩下的k-1个聚类初始中心点。
1)使用欧式距离公式计算数据集中的每个数据点到c1的距离,取最短距离记为distmin以及所有数据点距中心点的距离和sum=∑idisti。
2)以log(distmin) 作为初始代价,循环计算每个数据点与中心点的距离。
3)按式(3)计算下个聚类初始中心点的选择概率(l为样本因子,每次选择的数据点个数,dist(x)为每个数据点距样本中心点的距离)
(3)
按照中心点选取概率确定下个聚类初始中心点,满足式(3)概率条件的数据点有可能不止一个,若存在多个数据点,则通过对每个数据点赋权值来确定下个聚类初始中心点。
(3)经过(2)选择出多个数据点,根据将每个数据点作为中心点时,簇中数据点的个数作为权值;根据权值大小选择下一个聚类初始中心点,直到k个初始中心点被选择出来。
k-means‖聚类算法解决了k均值聚类算法对聚类初始中心点敏感的问题,保证了对数据聚类的精确度。
2 基于差分隐私保护的DPk-means‖算法简析
针对1.3节k均值聚类算法随机选择聚类初始中心点及数据集中存在离群点敏感的问题,同时在计算距离每个数据点最近的中心点时会泄露隐私的问题[11](过程如图1所示),提出解决办法,标记离群点使离群点参与数据聚类过程,但是不参与聚类初始中心点的选择,在k个聚类初始中心点均被选出来之后,再根据k均值聚类算法进行迭代更新聚类中心点,直到聚类中心点收敛或是不再满足迭代条件时终止。同时利用满足差分隐私保护的机制注入适量特定分布的随机噪声,使数据一定程度的失真,保护聚类数据的隐私。
对于图1中所存在的隐私泄露问题,假设攻击者拥有最大背景知识的前提下,对于邻近数据集D={x’,x1,x2,…,xn} 和D’={x1,x2,…,xn}, 攻击者已经知道了邻近数据集D和D’的中心点分别为C和C’,故攻击者可以根据式(4)推断出x’的信息,从而造成数据x’的隐私泄露
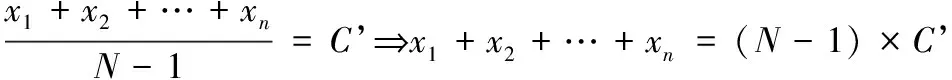
(4)
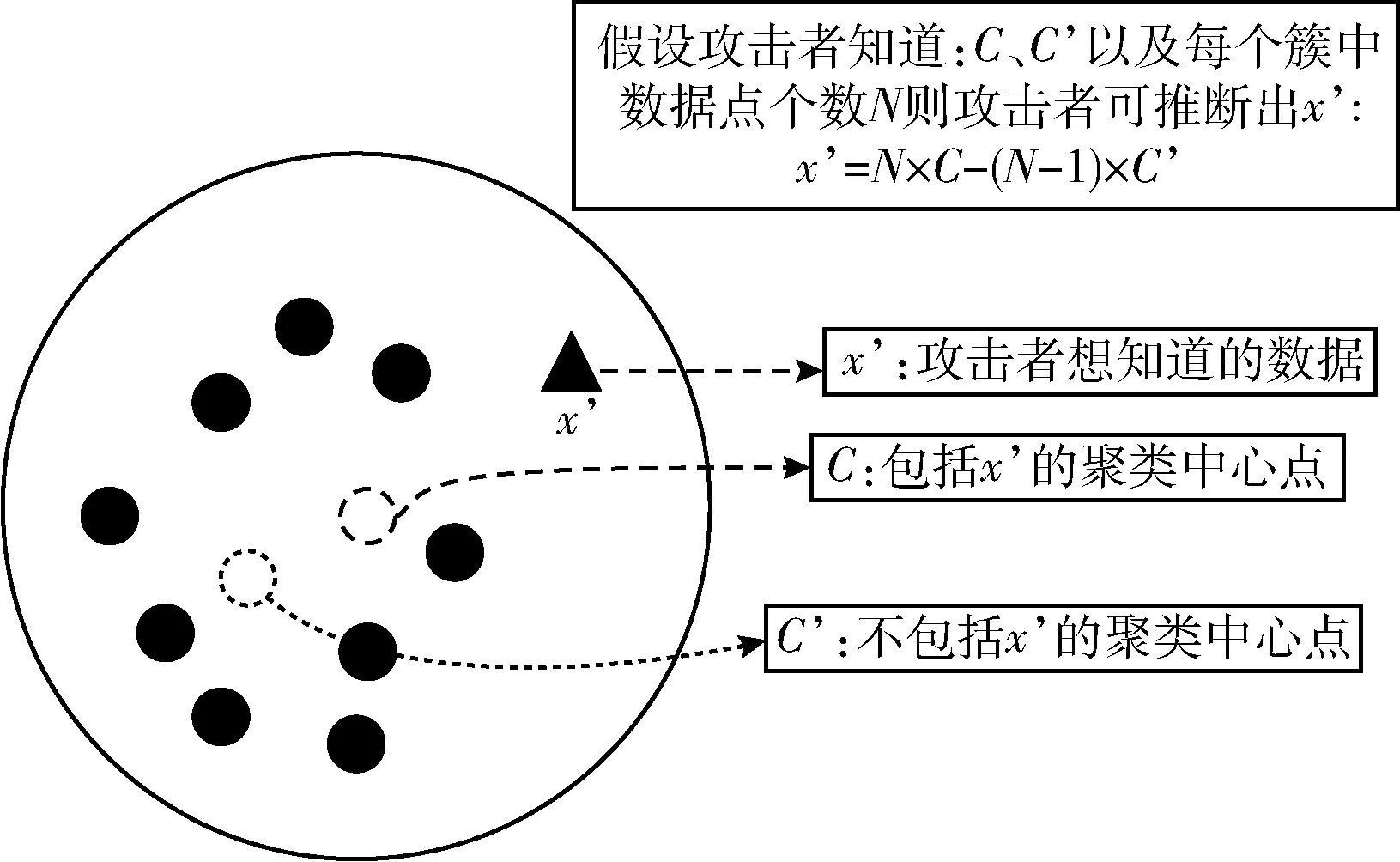
图1 聚类确定中心点过程的隐私泄露说明
针对k均值聚类算法所存在的隐私泄露问题以及算法对于选择聚类初始中心点敏感的问题,本文提出了保证聚类精确度以及保护聚类数据隐私的算法DPk-means‖,利用k均值的改进算法k-means‖聚类算法解决k均值对于聚类初始中心点敏感的问题,结合文献[6]中提出的差分隐私对算法中所涉及的隐私泄露的部分注入适量的特定分布的随机噪声,以便保证聚类数据的隐私,选择合适的隐私预算,对聚类数据的可用性和隐私性达到平衡状态。
其中DPk-means‖的算法流程如图2所示。

图2 DPk-means‖算法流程
其中DPk-means‖算法解决了k均值对于初始中心点敏感的问题,标记离群点,见于2.2节;除此之外,为保护数据的隐私性,利用差分隐私保护机制,牺牲数据的一定可用性,使得该算法在数据的可用性和隐私性上达到平衡状态,既能够保证数据的一定可用性,也能够保护聚类数据的隐私。
2.1 DPk-means‖算法中离群点处理
当大规模数据集中存在离群点时,因为离群点与其它数据点间相差较大,会影响数据聚类的精确度,直观上考虑如果数据集中的离群点不参与聚类中心点的选择时,其数据的聚类精确度就会提升。所以为保证数据聚类精确度,对数据集中的离群点进行标记,被标记的数据点不参与聚类初始中心点的选择,但参与数据的聚类过程,利用式(5)进行离群点的标记
(5)
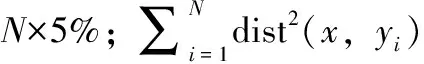
2.2 DPk-means‖算法聚类初始中心点选择
假定现有数据集合D={x1,x2,…,xm}∈Rd, 其中d为数据维度,指定聚类个数为k、抽样因子l,利用式(5)标记离群点,选择距离其它数据点较近的数据点作为第一个聚类初始中心点c1。记D1(x)={dist1,dist2,…,distn} 为c1跟剩下的数据点间的距离,其累加概率分布为
在计算每个数据点到中心点的最短距离的过程中会存在图1的隐私泄露的问题,所以利用差分隐私机制注入适量随机噪声即dist′i=disti+noise, 故得到
利用式(3)进行选择下一个聚类初始中心点,若满足条件有多个数据点,则赋权值选择下一个聚类初始中心点,直到k个聚类初始中心点被选择出来。
DPk-means‖算法是由算法1标记离群点选择聚类初始中心点;利用算法2迭代更新中心点进行数据聚类说明如何保护聚类数据的隐私安全以及保证数据聚类的精确度。
定理1 算法1满足ε1-差分隐私。
证明:DPk-means‖算法将数据点与中心点间的距离作为数据相似度的评判标准,故确定聚类初始中心点过程的敏感度为
(6)
其中,d为聚类数据集的维度,为了保护聚类数据隐私,在确定聚类初始中心点的时候,即在算法1中第(12)行和第(13)行中进行满足拉普拉斯机制的随机噪声添加,由差分隐私的序列组合性质可得算法1满足ε1-差分隐私。
算法1: InitCenter
Input: D={x1,x2,…,xm}-raw dataset;
k-the number of clusters;
l-oversampling factor;
r-the parameter of the outliers;
ε1-privacy budget.
Output:C={c1,c2,…,ck}-cluster initial center point;
D’-clustered dataset.
(1) Normalized D, initialCand the distance setd
(2) dividedε1intoε1/2 andε1/2
(3)fori← 0 to len(D)do
(4) calculate outliers(xi) according to formula (5)
(5)endfor
(6)outlier_set← sort(outliers(xi)) from small to large
(7) mark the first len(D)×routlier_setas outliers
(8)c1← the point of max(outlier_set)
(9)φ← the shortest distance ofxifromc1
(10)forO(log(φ)) timesdo
(11)d={disti|i=1,2,…,N} ← the distance between each pointxiandc1
(12) sum (dist1+dist2+…+distN) + Lap(2Δf/ε1)
(13)d← {disti+Lap(2NΔf/ε1)|i=1,2,3,…,N}

(15)C←ci∪c
(16)endfor
(17)forci∈Cdo
(18)wi←quantity of points in D closer tocithan any other point inC
(19) recluster the weighted points inCintokclusters
(20)endfor
(21)returnC, D’
算法1介绍了DPk-means‖算法如何处理离群点及初始中心点选择。算法1中的第(3)行~第(7)行就是对离群点的处理,标记离群点,使离群点不参与聚类初始中心点的选择;算法1中第(8)行对k-means‖聚类算法随机确定的第一个初始中心点进行了改进,避免了算法首次若选择离群点作为聚类初始中心点时使聚类效果不佳的情况;在选择剩下的k-1个聚类初始中心点的过程中保护聚类数据的隐私安全,算法1的时间复杂度为O(log(φ)); 选择满足概率条件的一个或多个数据点赋权值,根据权值大小选择合适的聚类初始中心点;算法1中第(13)行在计算数据点与中心点间的距离进行数据间相似度判断时注入服从拉普拉斯分布的随机噪声,使得选择聚类初始中心点的过程中满足差分隐私定义,使聚类数据隐私泄露的风险控制在安全范围内。
2.3 DPk-means‖算法簇中心点迭代更新
根据算法1确定的聚类初始中心点进行数据初步聚类,这时聚类的中心点可能并不是最佳的,故需要根据划分好的簇进行迭代更新簇中心点,进行数据的重新聚类,直到聚类中心点收敛或是达到迭代条件,利用传统k均值聚类算法进行聚类中心点更新,并且在该过程中也进行数据的隐私保护。
定理2 算法2满足ε2-差分隐私。
证明:由算法1确定的聚类初始中心点进行数据聚类之后,针对聚类好的各个簇,利用k均值聚类算法进行簇中心点的更新移动,算法2中的第(6)行为保护聚类数据的隐私安全注入满足差分隐私定义的随机噪声,计算均值作为中心点的过程中的敏感度由式(6)可得Δf=d(d为聚类数据集的维度),同时在更新簇中心点时其敏感度为Δf=1,故算法2中敏感度为d+1,由差分隐私组合性质1得出算法2满足ε2-差分隐私;其详细过程由算法2给出:
算法2: UpdateCenter
Input: D’-the output of algorithm 1;
ε2-privacy budget;
C-the output of algorithm 1.
Output:C’ -the set of center point.
(1) InitialC’
(2) dividedε2intoε2/2 andε2/2
(3)foreach cluster in D’do
(4)d← distance fromxitoci
(5)num← the number of the cluster
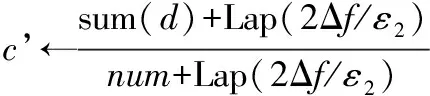
(7) if AMI(c’i)>AMI(ci)
(8)C←c’i∪C
(9) end if
(10)endfor
(11) update the set of center pointC
(12)returnC
算法2解决了在算法1确定聚类初始中心点将数据集划分为k个簇之后,针对簇中心点更新过程中可能泄露数据隐私的问题,其算法时间复杂度为O(N);算法2的第(7)行判断由k均值聚类算法得到的中心点是否比初始中心点的聚类效果更好而决定是否更新簇中心点。
DPk-means‖算法与k均值聚类算法相比,在处理大规模数据聚类任务时有效地降低了离群点对于聚类精确度的影响,不仅解决了k均值聚类算法对初始中心点敏感的问题,保证了数据聚类的精确度,而且还保护了聚类数据的隐私安全,提高了算法的适用能力。
2.4 DPk-means‖算法过程中敏感度的确定
在使用算法进行大规模数据聚类时,其中所涉及到注入随机噪声,包括用DPk-means‖算法确定聚类的初始中心点,以及确定聚类初始中心点将大规模数据聚类成k个簇后,针对每个簇迭代更新每个簇中心点的过程。
(1)确定k个聚类初始中心点的过程;假定有d维邻近数据集D1和D2;在确定聚类初始中心点的过程中,需要计算每个数据点到中心点间的距离,则该过程的敏感度为Δf≤d。
(2)确定k个聚类初始中心点之后,针对由初始中心点确定的每个簇,计算每个簇中数据点距中心点间的距离,此时Δf≤d,再迭代更新每个簇中的中心点,确定聚类中心最优解,此时Δf=1。
综上所述,DPk-means‖算法的敏感度为2d+1,在聚类过程中注入Lap((2d+1)/ε)。
定理3 DPk-means‖算法满足ε-差分隐私。
证明:DPk-means‖算法中泄露数据隐私的过程主要为两个部分:一是为确定聚类初始中心点;在确定中心点的过程中会造成数据隐私的泄露;二是在确定k个聚类初始中心点将数据集划分为k个簇之后,迭代更新每个簇中的中心点时会涉及到数据隐私的泄露。为了解决整个过程所涉及的隐私泄露的问题,分别给定隐私预算为ε1和ε2,在对应过程利用拉普拉斯噪声机制注入随机噪声;则由差分隐私的定义可知:随机算法M1对于邻近数据集D和D’的查询结果泄露的概率满足式(7),数据的隐私泄露在安全控制范围内,即
Pr[M1(D)∈Range(M1)]≤eε1×Pr[M1(D’)∈Range(M1)]
(7)
其中,邻近数据集D和D’中数据代表数据集中的每个数据点距离聚类初始中心点的最短距离,D和D’中的数据至多有一条数据不一样。在初始中心点确定之后,针对每个簇迭代更新中心点,直至聚类结果收敛或是达到迭代条件;在更新的过程中注入随机噪声保护数据隐私,即
Pr[M1(c)∈Range(M1)]≤eε2×Pr[M1(c’)∈Range(M1)]
(8)
其中,c和c’为聚类中心点数据集。根据差分隐私组合性质1,则DPk-means‖算法的整个过程满足(ε1+ε2)-差分隐私。且隐私预算越小,注入的随机噪声量越大,则选取的聚类中心点的误差就会越大,数据聚类的精确度就越小。
3 实验分析及数据
实验对满足差分隐私定义的DPk-means‖算法从两个方面进行分析评估:①动态调整ε1和ε2验证算法的有效性及隐私预算最优的情况;②对比隐私预算ε1和ε2验证算法在数据聚类过程中数据的可用性与隐私性能够实现平衡状态。
本文实验部分采用python语言编程实现,实验环境为Windows10 2.50 GHz,实验数据来自UCI machine learning repository中的公开数据集,其数据集的基本信息见表1。

表1 实验数据集信息
3.1 实验评价指标
(1)本文将采用调整互信息AMI(adjusted mutual information)作为聚类效果评价指标,AMI∈[-1,1], AMI值越大,则代表使用该算法进行聚类的聚类效果越好。AMI的计算公式如式(9)所示
(9)
其中,MI(mutual information)为互信息,用来表示两个数据分布吻合程度,测试基于聚类算法、预测标签与真实标签的一致性,MI的计算需要知道真实类别标签的分配情况;假设U和V表示对N个样本标签的分配情况,标签分配的不确定性用熵值表示,则U和V的熵值计算如式(10)和式(11)所示
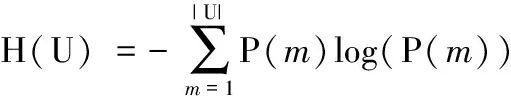
(10)
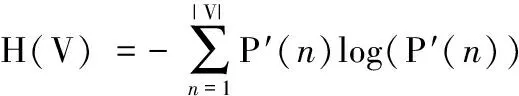
(11)

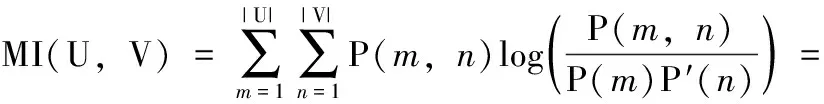
(12)

(2)通过隐私预算的大小进行评估聚类分析数据隐私保护水平的高低,由差分隐私的定义可知,隐私预算越小,注入的随机噪声量越大,数据的隐私保护水平就越高;反之数据的隐私保护水平越低,数据可用性的程度就越高。
本文为验证DPk-means‖算法的可用性,将通过AMI和隐私预算两个方面作为评估指标来综合说明算法的适用性,验证DPk-means‖算法在保证聚类精确度的情况下,同时保护聚类数据的隐私安全。
3.2 实验分析及比较
本实验旨在考察DPk-means‖算法进行数据聚类过程中,在确定k个聚类初始中心点过程分配隐私预算ε1及确定初始中心点将数据集划分为k个簇后,涉及到各数据点与中心点间距离的计算,更新每个簇中心点的过程中,分配隐私预算ε2。针对算法对对应过程提供不同隐私保护程度,用DPk-means‖算法聚类的精确度来证实算法的可用性,实验验证如图3和图4所示,针对数据集Occupancy detection dataset,给定k=2,在隐私预算ε1递减ε2递增情况下数据聚类的中心点分布较集中,数据聚类精确度高;而ε1递增ε2递减情况下聚类中心点较分散,使得数据聚类精确度不高。

图3 ε1递减ε2递增的聚类中心点分布
实验1:不同隐私保护水平对DPk-means‖算法聚类精确度的影响。
针对k-means‖聚类算法中影响聚类精确度及数据隐私会泄露的问题进行分析,利用DPk-means‖算法可以保证聚类的精确度的同时对聚类数据的隐私安全也起到保护的作用。将差分隐私应用到聚类算法设计中,实验分析对选择初始中心点和迭代更新中心点提供不同的隐私保护水平对数据聚类精确度的影响。
由图5和图6可以看出,ε2起始值为0.1(若值太小,注入的随机噪声量大),以步长为0.1逐步增大,簇中心点迭代更新注入噪声的影响比初始中心点选择时注入随机噪声(ε1=0)要大,并且由图5和图6可以看出,当ε2∈(0.42, 0.52) 时,初始中心点未注入随机噪声保护时算法聚类精确度要更高;但总体来说,对初始中心点与确定初始中心点之后,将数据划分为k个簇,对每个簇迭代更新簇中心点时注入服从拉普拉斯分布的随机噪声保护数据隐私,聚类精确度都比只关注簇中心点更新注入噪声的聚类精确度高,在ε1=ε2=0.5时,从数据聚类的精确度以及隐私保护水平角度来看,能达到数据可用性和隐私保护平衡的状态;所以若要保证数据聚类精确度及一定的隐私保护水平,保证聚类初始中心点和迭代更新中心点可行的前提下,ε1和ε2应该相等且接近0.5,可保证聚类结果的精确度且对数据提供有效的隐私保护水平。
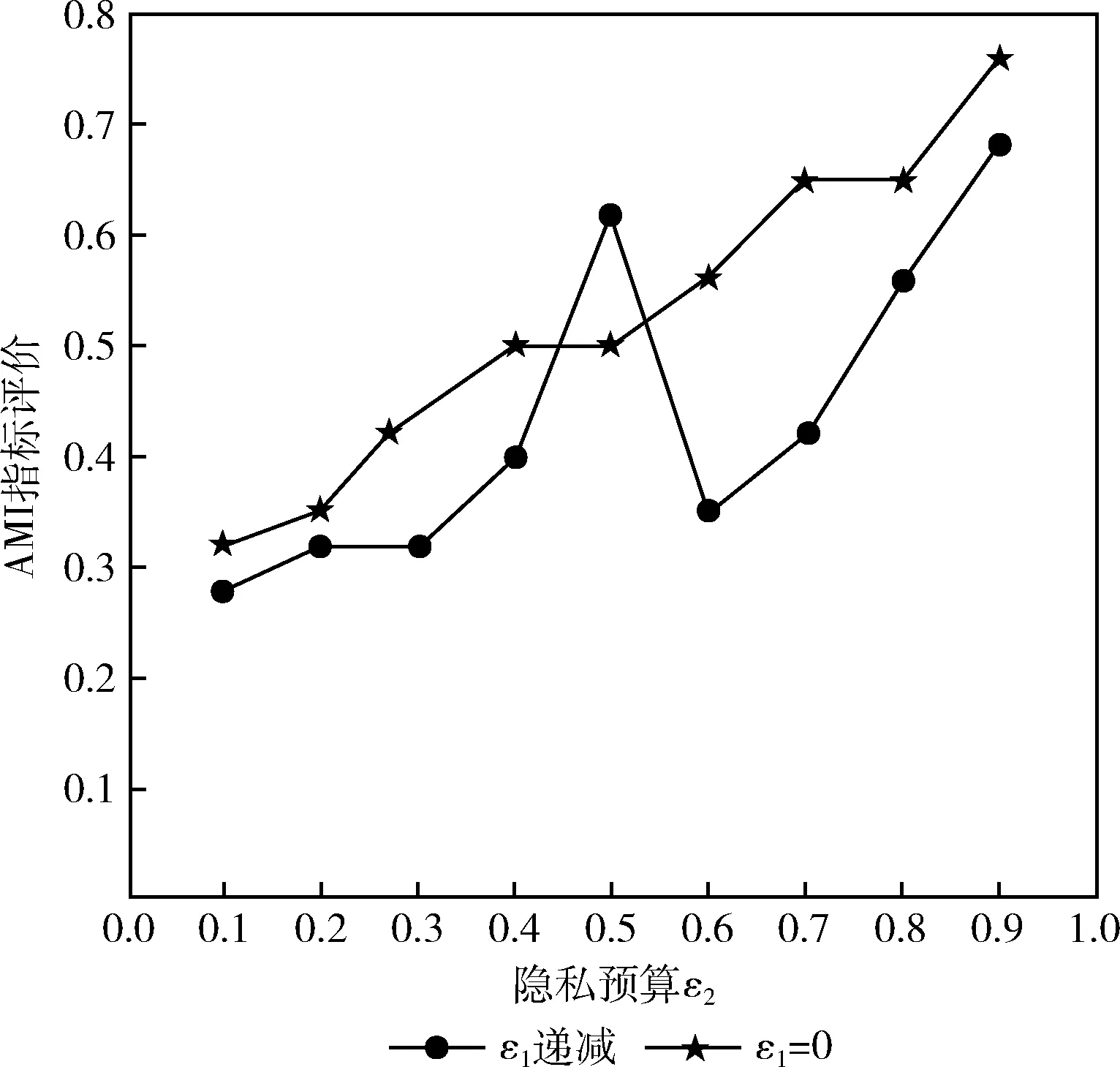
图5 Occupancy detection dataset聚类AMI指标评估
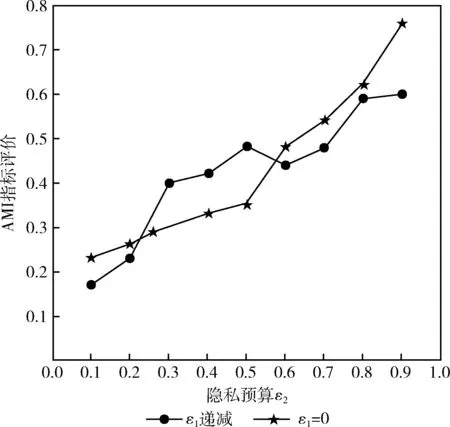
图6 PEMS-SF数据集聚类AMI指标评估
实验2:DPk-means‖算法和DPk-means++算法聚类效果对比。
本实验旨在比较DPk-means‖算法的有效性,在两个实验数据集上使用DPk-means‖算法和文献[5]中基于k均值改进算法k-means++的隐私保护算法——DPk-means++算法进行数据聚类精确度比较,且利用DPk-means++算法进行数据的聚类分析时,不涉及到对数据集中离群点的处理;
实验结果如图7和图8所示;由图7、图8可以看出使用DPk-means‖算法的聚类精确度高于DPk-means++算法,且用DPk-means‖算法能耗费较小的隐私预算达到较高的聚类精确度,其数据聚类精确度能够较快收敛;相比之下,使用DPk-means‖算法进行离群点的处理之后再进行数据聚类能够给数据提供更高的隐私保护级别,同时数据聚类的精确度更高。
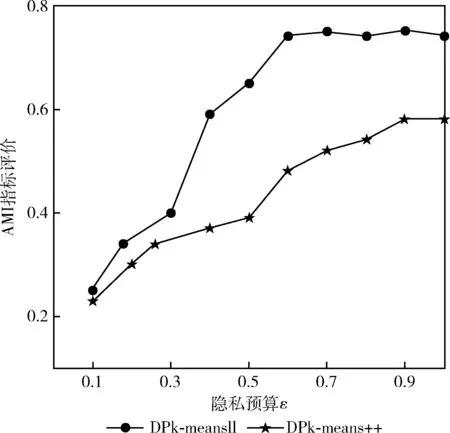
图7 Occupancy detection dataset上的AMI运行
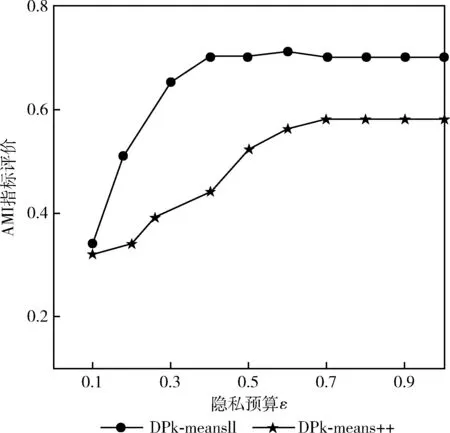
图8 PEMS-SF数据集上的AMI运行
4 结束语
本文既解决了传统k均值聚类算法对聚类初始中心点敏感的问题,同时对聚类初始中心点的选择进行了改进,降低了离群点对聚类精确度的影响,同时将差分隐私应用于聚类算法中,在确定聚类初始中心点以及每个簇迭代更新中心点的过程中选择合适的噪声注入机制,在不同隐私保护程度下揭示了数据内在的规律性质。通过实验动态设置不同的隐私预算,对数据提供了不同程度的保护情况下聚类结果的精确度表明,DPk-means‖算法对于存在异常离群点的大规模数据集聚类任务,能够保证一定的聚类精确度及数据的可用性。
