基于优化ELM的信息物理融合系统入侵检测
2022-02-15肖韵婷张立臣
肖韵婷,张立臣
(广东工业大学 计算机学院,广东 广州 510006)
0 引 言
信息物理融合系统(cyber physical system,CPS)以网络作为信息核心承载,将信息与物理系统紧密联系,有效提升自动化水平与运行效率。但一旦其安全性被破坏,对应的物理系统会受到严重影响。入侵检测作为一种主动的防御技术,能通过收集分析相关网络数据及时发现攻击行为,降低网络威胁,因此,研究CPS的入侵检测显得尤为重要[1]。传统网络中基于机器学习算法及神经网络的单一和混合模型的入侵检测方法已有许多研究。作为一种新型神经网络,极限学习机(extreme learning machine,ELM)与传统神经网络相比学习速度更快,精度更高,参数设置更简单,与支持向量机相比,可通过扩展类标签矩阵的方法直接实现多分类,无需分解为多个二进制子问题,在许多领域包括入侵检测领域应用中都取得成功。文献[2-9]均使用基于ELM的入侵检测模型,分别与联合熵、K均值聚类、卷积神经网络、自编码器、深度信念网络等相结合,并获得较好的效果。但以上算法均未解决ELM性能受权重阈值随机性与不平衡数据和离群点影响的问题。随机权重阈值容易导致隐含层不具有稀疏性和调和能力,无法得到精确的解析解[10]。对此,文献[11]对量子粒子群优化算法改进并用于ELM的参数优化,构建工控系统入侵检测模型,取得了较好的效果。针对ELM在不平衡数据集的性能,文献[12]中归纳的两种样本权重计算方法均未对样本离散程度进行考虑。
本文对WRELM权重赋值方式进行改进,提出基于局部距离的加权正则化极限学习机(local distance-based weighted regularized extreme learning machine,LDWRELM)减轻数据不平衡及离群点对模型性能的影响。并提出一种自适应性和动态变异的改进头脑风暴算法(modified brainstorm optimization,MBSO)用于LDWRELM初始输入权重阈值优化,提高其稳定性及检测能力,构建用于CPS系统的MBSO-LDWRELM入侵检测模型,在NSL-KDD数据集对比实验验证模型的性能与改进的有效性。
1 MBSO-LDWRELM算法
1.1 LDWRELM
ELM是一种新型单隐层前馈神经网络,结构可分为输入层、隐含层与输出层3部分。对一个具有L个隐层节点的单隐层神经网络,设输入N个训练样本 (xi,yi),i=1,2,…,N。 其中xi=[xi1,xi2…,xin]T,yj=[yj1,yj2,…yjm]T。 则网络的输出可表示为
(1)
其中,g()为激活函数,对于第i个隐层节点,wi为与各输入节点的权重,bi为偏置,βi为该隐层输出权重。tj为实际输出。网络的实际输出越接近Yi越好,为得到在训练样本上具有良好效果的参数,可使用训练误差作为目标函数,如下所示
(2)
即问题转化为求解存在βi,wi与bi使
(3)
简化为矩阵形式
Hβ=Y
(4)
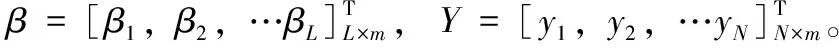
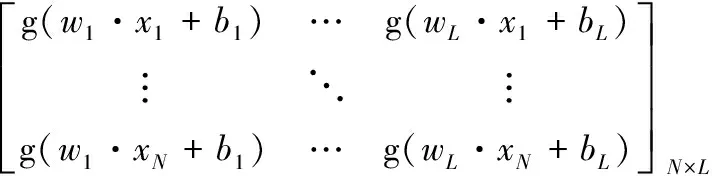
其中,H为隐层输出矩阵。与传统BP神经网络等通过梯度下降法反向传播迭代调整权重阈值的学习方法不同,ELM固定输入权重wi与偏置bi,把问题转换为仅需要求解隐含层输出权重矩阵β。可使用最小二乘法求解线性系统式(4)的解为β*=H+T, 其中H+为H的广义逆矩阵。
ELM算法是一种基于经验风险最小化原则的学习算法,但是真实的数据集往往包含噪音、离群点,仅考虑经验风险容易带来过拟合与鲁棒性低等问题。经研究结果表明,通过结合正则化理论,使用权值系数权衡经验风险与模型复杂度,能有效缓解此问题。使用加权与正则化可以使ELM的求解达到更小的训练误差,提高对离群点的抗干扰能力。则优化问题变为
(5)
(6)
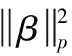
由式(5)、式(6)建立拉格朗日方程得
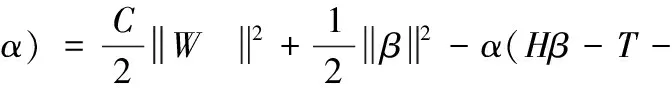
(7)
其中,α=[α1,α2,…,αN] 为拉格朗日算子,解式(7)得
(8)
其中,I为单位矩阵。当数据集中离群点少时,可以令矩阵W为单位对角矩阵,即每个样本的样本权值相等。对于带权的RELM,文献[13]对两种常用加权方式进行了阐述,其两种权重赋值方法的核心都是根据各个类的数据量进行赋值,提高少数类的权重,从而达到平衡数据集的目的。但仅从数据量层面考虑而未考虑到类内数据间的稀疏程度和离群点的影响。文献[14]提出一种基于数据离散度的加权极限学习机,把每类样本均值作为样本中心,以每个样本到类中心与到其它类中心的最小值的比值作为权重。但其以类均值为中心点的方法在一定程度上已经受离群点的影响,可能会使离群点的权重偏大,从而影响模型性能。因此本文针对样本的加权方式进行了改进,具体定义如下
(9)
(10)
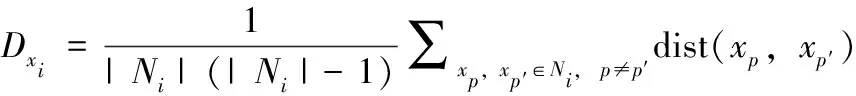
(11)
其中, dist(xi,xp) 表示样本xi与xp间的欧氏距离,Ni为样本xi所属类别的集合, |Ni| 为每个类别中的样本数量,Dxi的含义为样本xi所在类的内部平均距离,dxi为样本xi与类内其它样本的平均距离。二者之比可反映当前样本与其它样本间的局部距离关系,当Wii≥1时,说明当前样本与其它样本距离较近,xi处于样本相对稠密的区域;反之,则说明xi处于稀疏区域,样本离群程度高,分类器若受这类样本干扰,会使分类边界模糊,因此应降低其权重。
1.2 BSO算法
BSO算法是在2011年在国际智能团体会议中提出的一种新型的、有前途的群体智能优化算法[15],该方法通过模仿人类通过头脑风暴会议集思广益产生问题解决方案,其参数设置简单、进化过程易于理解、求解时间相对短,适合解决高维多峰值问题,并成功应用于多个领域[16]。算法主要由初始化与评估、聚类、变异与更新4个模块组成,通过实现在搜索空间递归解的发散与收敛,以得到“足够好的”最优解。其中最核心的为变异与更新模块,其具体步骤如下:
选取一个或两个个体后通过下式产生新个体
Xnew=Xselected+ζ×N(μ,δ)d
(12)
ζ=logsig((T/2-t)/k)×rand(0,1)
(13)
其中,Xselected为选择的一个个体或由两个个体融合生成的个体,N(μ,σ)d为d维的服从期望为μ、方差为σ的高斯随机函数,T为最大迭代次数,t为当前迭代次数,rand()为[0,1]间随机实数,logsig()函数为对数S形传递函数,k为logsig函数的斜率。
若选取的是两个个体,通过下式进行融合
Xselected=ω×Xselected_1+(1-ω)×Xselected_2
(14)
式中:Xselected为融合生成的个体,Xselected_1与Xselected_2为分别从两个类中选取的个体,ω为[0,1]之间的随机实数。
头脑风暴优化算法与其它优化算法都有容易陷入局部极小而导致算法的优化性能达不到理想效果的问题,本文提出一种针对更新策略与变异方式进行优化的MBSO算法。
1.2.1 对更新策略的改进
个体更新策略是头脑风暴优化算法的关键之一。基于同一类个体的候选个体生成方式可看作组内交流,基于不同类个体的候选个体生成方式可看作组间交流。组内交流经过扰动产生的新个体较大概率落在候选个体的周围,更适合在后期进行局部细致的搜索以更好地接近极值点;组间交流进行随机扰动后生成的新个体较大概率落在两个类的中间,更适合用于前期的全局搜索,更快将搜索范围缩小至更可能存在潜在解决方案的区域。
针对算法搜索过程的推进,考虑了控制调节组内交流与组间交流的概率大小对搜索性能的影响,我们期望算法在迭代早期具有较强的全局搜索能力,进行充分搜索,以跳出局部极小值,在迭代后期能以当前局部最优区域为中心进行局部搜索。因此可以令
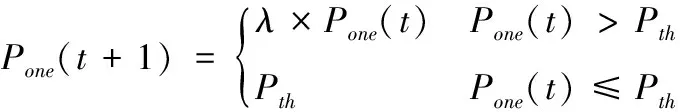
(15)
(16)
其中,t为当前迭代次数,T为最大迭代次数,Pone(t)表示第t次迭代中概率Pone的取值,Pth为Pone的最小取值,u,v为调节系数。式(15)中上式为单调递减函数,随着迭代的进行Pone逐渐减小,减小到小于Pth时下一代概率等于Pth,这一设定保证了算法在后期不完全丧失全局搜索的能力。
1.2.2 对变异策略的改进
影响算法效果的另一个关键在于个体的更新方式。传统BSO在选定个体加上高斯随机扰动实现新个体的产生。式(13)中系数ζ通过对数S形传递函数logsig()与[0,1] 间的随机向量相乘实现,logsig函数值域为(0,1),因此系数ζ的值域也为(0,1)。且根据高斯分布的“3σ”原则,高斯随机函数产生的值落在横轴区间(μ-2.58σ,μ+2.58σ)的概率约为99.73%。图1为当μ=0,σ=1时,令式(13)中T=1000,随机扰动的取值情况,可见迭代的前期随机扰动的取值范围固定,大部分位于区间[-2.5,2.5]之间,以0为中心向正负极分散,越靠近0处取值越密集。在迭代次数550后,扰动大小数量级基本小于1e-01。可见,传统BSO随机扰动范围集中在以μ为中心的局部区域,最大步长固定,每次的随机扰动大小与迭代所处的阶段并不匹配,造成迭代前期算法寻优速度慢,后期在最优值附近反复震荡,无法快速收敛,且容易出现早熟现象。

图1 高斯变异下的随机扰动
由此可见,传统BSO采用的高斯变异的局部搜索能力较强,但是引导个体跳出局部最优的能力较弱,容易出现“超级个体”导致早熟,不利于全局收敛。且这种变异方式没有充分利用当前种群的信息。本文对算法中的变异策略进行改进,引进自适应的差分变异思想,设计与搜索阶段相匹配的新个体产生策略。具体如式(17)、式(18)所示
(17)
ζ=ζmax-(ζmax-ζmin)×t/T
(18)
其中,i∈[1,2,…,n],Xselected为选中个体,X1、X2为种群中随机选择的两个个体,t为当前迭代次数,T为算法最大迭代次数,ζmax表示变异系数ζ的最大值,ζmin表示变异系数ζ的最小值。Pc为交叉概率。Li、Hi为第d维搜索范围上下界。
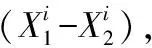
1.2.3 算法流程
根据上述介绍,MBSO算法的算法具体执行流程如下所示:
步骤1 初始化种群Xi(i=1,2,…N), 问题维度d,最大迭代次数T,分类个数m,变异系数最大最小值ζmax、ζmin,概率Preplace,Pone,Pone_center,Ptwo_center,Pth,Pc,所优化问题的适应度函数f(x);
步骤2 将个体聚类为m类,计算各个体适应度值,并以每个类中的最优解为各类的中心。
步骤3 产生随机数,若小于Preplace,随机生成个体替代选中类的中心个体;
步骤4 使用式(15)更新Pone,产生随机数r1;
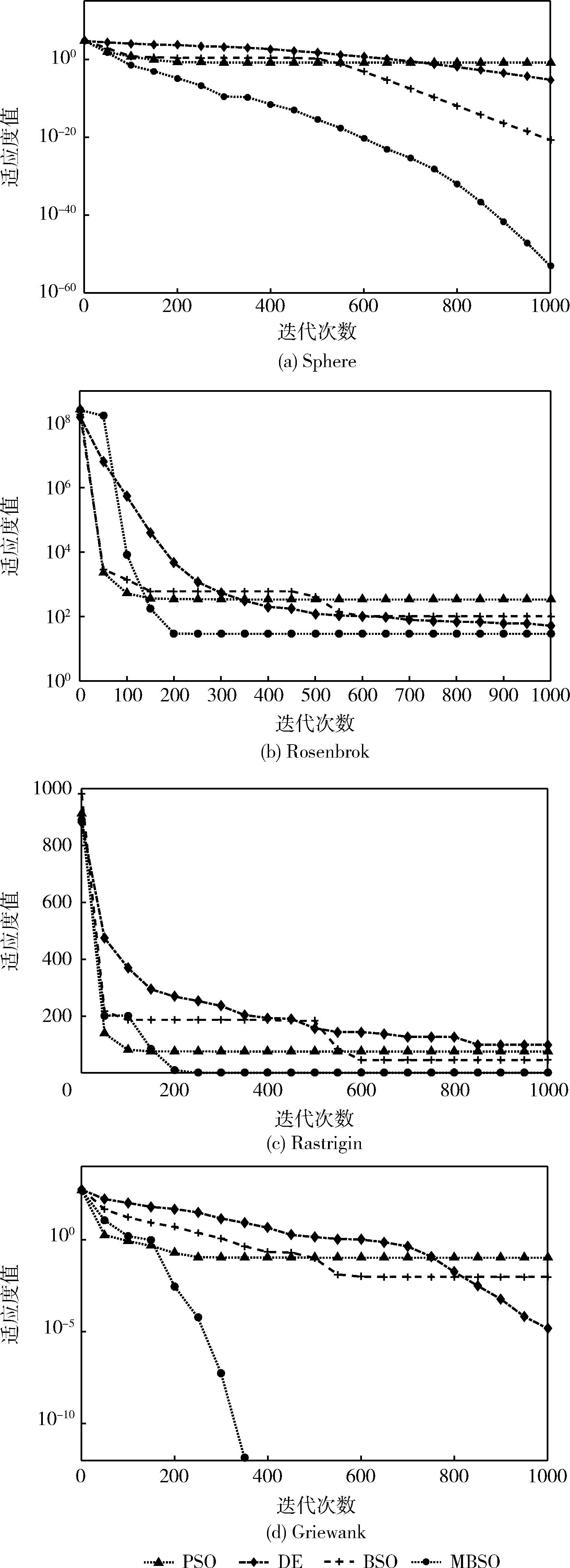
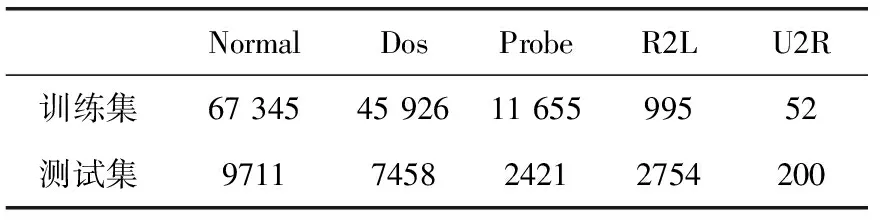
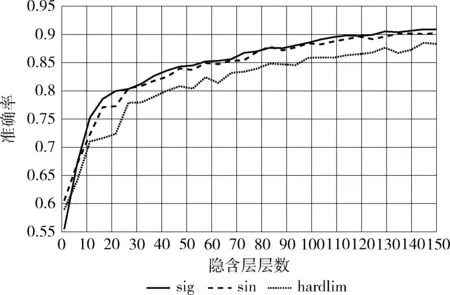
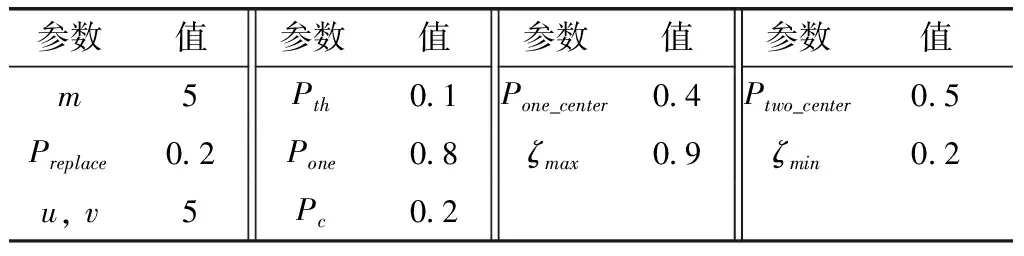
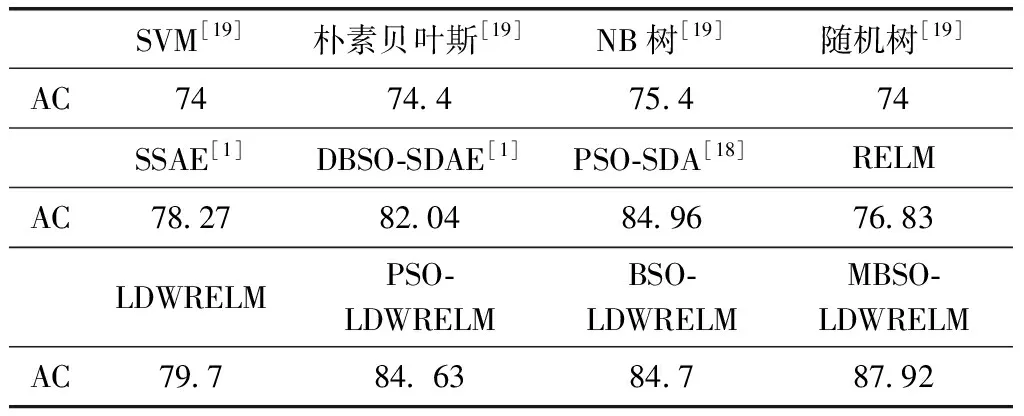
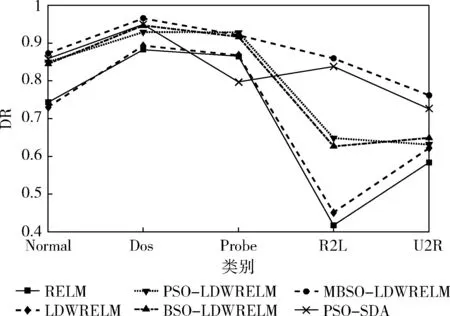
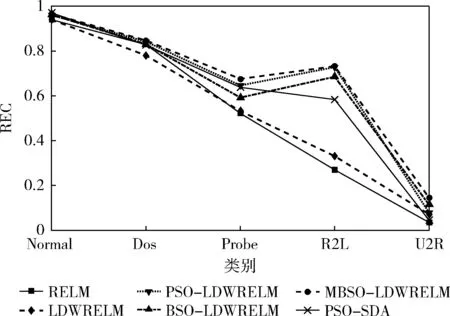
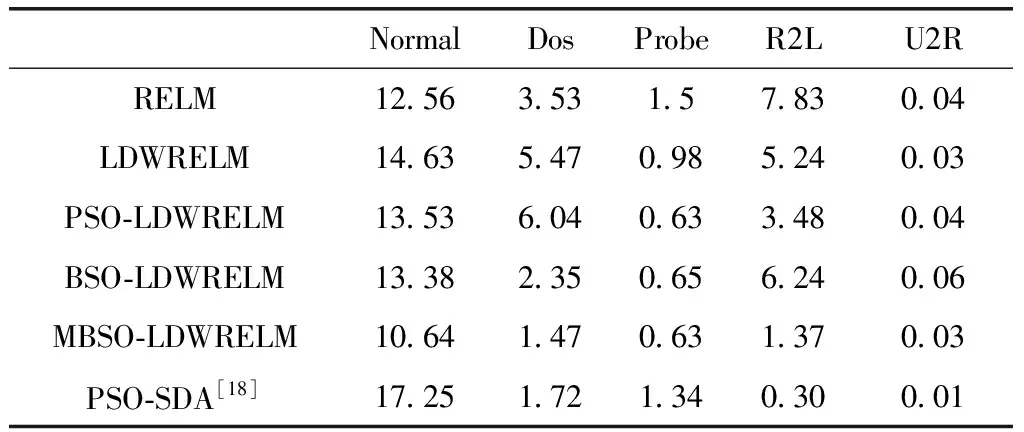
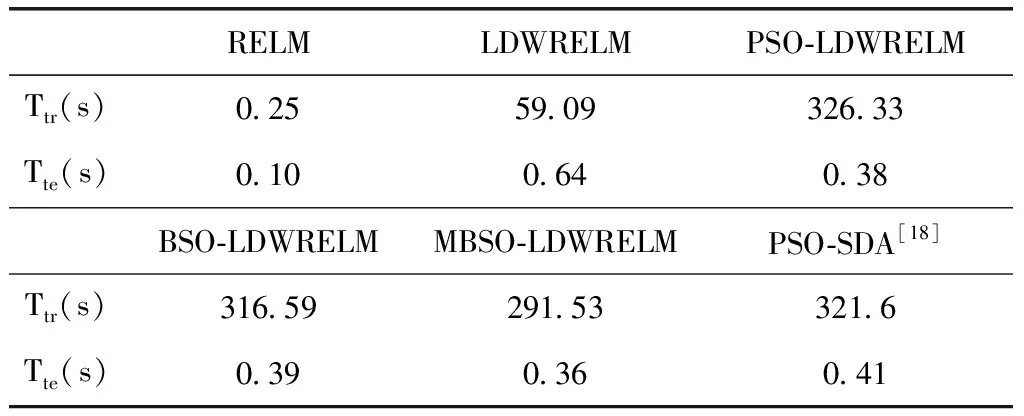
(1)r1 1)若小于Pone_center,选类中心个体为Xselected; 2)若大于Pone_center,选类内个体为Xselected。 (2)r1>Pone,随机选择两个类的个体通过式(14)融合作为Xselected,产生随机数; 1)若小于Ptwo_center,选择两个类的中心个体; 2)分别选择两个类的非中心个体。 步骤5 根据式(17)对个体进行变异,计算生成个体适应度值,保留更优个体; 步骤6 完成N个个体更新,则执行步骤7;否则转到步骤3; 步骤7 若达到最大迭代次数,则终止循环,输出最优个体;否则转到步骤2。 1.2.4 性能测试 为验证本文提出的改进后的算法性能,将MBSO与传统差分进化算法(differential evolution algorithm,DE)、传统PSO算法、传统BSO算法进行对比。采用4个具有代表性的经典标准测试函数对算法效果进行评估比较,包括单峰函数Sphere与Rosenbrok,多峰函数Rastrigin与Griewank。各函数表达式与寻优范围见表1。 表1 标准测试函数 实验中,4种算法的种群个体数量N均为100,问题维度d为30,最大迭代次数T为1000,种群均采用均匀初始化。DE算法中交叉概率CR为0.3,变异率F为0.5。传统PSO算法学习因子c1=c2=1.49,惯性权重ω为0.8。为保证对比公平,BSO对应参数与MBSO一致,MBSO算法参数设置见表2。 为验证改进的有效性,本文使用Matlab2014a对4种算法进行编程实现,并分别对各测试函数进行寻优,每种算法均独立运行50次,记录每次寻优的结果进行分析。图2为各算法在优化不同测试函数时的收敛特性曲线图。 表2 MBSO参数设置 图2 各算法对标准测试函数进行优化的收敛特性 由图2可以看出,进行优化后的MBSO在收敛速度与寻优所达到的精度均优于其它3种算法。Sphere函数与Rosenbrok函数均为单峰函数,主要目的在于考察算法跳出局部最优后的收敛效果与寻优前进方向的正确性。Sphere函数的三维图是一个凹型碗状平面,有唯一的一个全局最优值,PSO算法陷入了局部最优,DE算法收敛速度较慢且寻优结果不理想,BSO与MBSO多次跳出局部最优,且MBSO的收敛速度和寻优结果较BSO更优。Rosenbrok函数全局最小值位于抛物线型山谷中,越靠近山谷越平坦,因此即时找到山谷所在的位置也很难收敛的全局最小值。MBSO在迭代200次后也陷入了局部最优,但此时的适应度值已经优于其它算法迭代1000次后的适应度值。 Rastrigin函数与Griewank均为多峰函数,存在众多的局部最小值,主要考察算法是否能克服早熟现象与全局寻优的效果。Rastrigin函数优化中,PSO、BSO与MBSO在前50次迭代中表现相近,MBSO在100次迭代后开始跳出局部最优,在250次迭代后无限接近于全局最优值。Griewank函数优化过程中,MBSO在前200次迭代寻优结果与PSO相近,在200后不断跳出局部最优值,在第350次迭代达到了理论最优值,而PSO与BSO优化均出现了停滞现象。 由图2还可发现,MBSO在对Rosenbrok、Rastrigin与Griewank的优化过程中,在迭代前200次适应度值优势不大,甚至高于其它算法,但是经过一小段平台期后,适应度值迅速下降,表明算法在达到局部最优点后能迅速调整寻优方向,搜索到新的最优点,在迭200次迭代后展现出优势。 表3对各算法运行结果的最优值与平均值进行了统计,对于较简单的Sphere函数寻优问题,各算法均能达到较好的精度,MBSO的寻优结果最优。对Rosenbrok函数PSO寻优结果波动较大,MBSO寻优结果的稳定性较好,每次运行均能达到相似的效果。对于多峰函数,MBSO的克服早熟现象的能力在寻优过程中展现出更大的优势。在对Rastrigins的寻优中,各算法每次运行所求得的最小适应度与均值相近,但只有MBSO寻找到全局最优点;对Griewank函数,BSO与MBSO均成功命中全局最优点,但MBSO的寻优结果更稳定。表明了MBSO在每次优化中都能带领种群找到正确的优化方向。 表3 实验结果对比 实验结果表明,MBSO采取的策略能有效抑制算法陷入局部最优,充分结合种群内个体的信息,更好地平衡算法的全局搜索与局部搜索能力,加快算法寻优速度,同时提高了算法的稳定性,验证了算法改进的有效性与必要性。 适应度函数是衡量个体优劣的指标,指引着算法迭代进化的方向,因此适应度函数的选择直接关系到算法寻优是否能找到最优解以及算法收敛的精度。本文采用均方误差函数作为预测值与真实值之间偏差的度量,其计算公式如下 (19) 式中:N为输入样本数,xn为真实值,tn为预测值,mse值越小,表明预测效果越好。 如上文所述,ELM作为一种快速、泛化能力好、参数设置简单的新型神经网络,ELM采用随机选择输入权重值及其隐含层偏置,其随机性可能导致某些权重阈值赋值接近0等情况,使某些隐含层节点失效,令算法泛化能力与求解精度达不到理想效果。 而MBSO具有良好的寻优能力,可以对LDWRELM随机确定的参数进行优化,寻找更优的初始权重阈值。 因此,考虑到CPS对入侵检算法轻量、快速、简单、稳定等要求及入侵检测数据的海量和不平衡等特点,本文将MBSO算法与LDWRELM相结合,构建基于MBSO-LDWRELM的入侵检测分类模型,将LDWRELM初始权重阈值设置问题映射为MBSO寻优问题,寻找更好的LDWRELM 初始权重阈值,进而得到最优输出权重值。参照文献[17]分析总结的典型CPS体系结构,检测模块将部署于CPS系统的应用层。 基于MBSO-LDWRELM入侵检测模型流程如下: 步骤1 数据收集预处理。截取网络数据包并进行解析,将所得数据划分为训练集与测试集,对数据进行预处理; 步骤2 使用MBSO算法优化LDWRELM; (1)初始化LDWRELM参数:输入层节点数inputnum,隐含层节点数hiddennum及输出层节点数outputnum进行赋值,对权重阈值进行初始化; (2)确定MBSO种群个体数N,所求问题维度计算公式为hiddennum*(inputnum+1),最大迭代次数T,及个体初始值; (3)根据适应度函数计算各个体的适应度值并排序,直到达到最大迭代次数或满足终止迭代条件; (4)输出最优个体的值,即为模型的最优参数,从而建立入侵检测模型。 步骤3 测试模型。将测试数据集作为模型输入,得到样本分类结果。 MBSO-LDWRELM的入侵检测模型构建流程如图3所示。 图3 MBSO-LDWRELM的CPS入侵检测流程 本文实验选取了NSL-KDD是对KDD99流量数据集进行去冗余及调整比例产生的。NSL-KDD数据集中每一数据包括41维连接特征与1维类型标签。其中连接特征中有32维为连续型数据,3维为字符型数据,6维为二值型。类型标签为字符型,包括攻击类型标签共40小类,可分为5大类:Normal,Dos,Probe,R2L与U2R。实验训练集使用“KDDTrain+”,测试集为“KDDTest+”,实验数据集构成见表4。由于测试集中有17小类为训练集中未知的攻击类型,因此要求模型不仅检测已知攻击类型,还应具有检测未知类型攻击的泛化能力。 表4 数据集描述 由于连接特征中的字符型数据不能直接用于入侵检测算法的输入,因此将其进行标签编码。如“protocol_type”中包含tcp,udp与icmp这3种不同字符类型,将其分标注为1,2,3。同理,“service”与”flag”特征按其字符类型分别标注为1~67与1~11。将数据类型标签按其攻击类型分为Normal,Dos,Probe,R2L与U2R这5类,分别标注为1~5。 为消除各属性间度量差异带来的影响,对数据进行归一化处理,将样本各特征都映射到0~1之间的数值,归一化公式如下 a=(a-min)/(max-min) (20) 数据集中冗余特征将增长训练时间,且特征越具有代表性,模型越能达到较好的效果。因此归一化处理后使用粗糙集工具箱Rosetta对特征属性进行约简,约简后得到特征属性共23项。 为验证MSBO-LDWRELM算法在入侵检测中的性能,本文基于NSL-KDD数据集进行了仿真测试实验,所使用实验环境为:Inter Core i5 2.9 GHz,8 GB内存,Windows 10操作系统,Matlab2014a。RELM与LDWRELM通过Matlab编程实现,并使用1.2.4中实现的PSO、BSO、MBSO进行初始参数寻优。 RELM与LDWRELM输出层神经元数为5,因为本文需要进行五分类。隐含层数通过选择不同的激活函数并逐渐增加层数的检测准确率进行选择。所得结果如图4所示,可见Sigmoid性能优于Sine与Hardlim,且在迭代120次后趋于平稳,因此本文选取隐含层节点数为120,激活函数为Sigmoid。 图4 不同激活函数与隐层数的准确率 PSO学习因子为1.3,惯性权重为0.8。MBSO参数设置见表5,BSO对应参数与MBSO相同。算法种群大小为50,最大优化迭代次数均为80。 表5 参数设置 实验结果采用准确率(accuracy,AC)、检测率(detection rate,DR)、召回率(recall,Rec)、误报率(false positive rate,FPR)、训练时间Ttr及检测时间Tte为性能评价指标,并将本文模型与传统RELM、LDWRELM、PSO-LDWRELM、BSO-LDWRELM进行对比。结果均独立运行10次后取均值。 表6列举出各算法的AC值的对比。文献[1]与文献[18,19]均使用KDDtest+数据集对算法性能进行比较。其中文献[17]使用PSO算法对堆叠降噪自编码器(stacked enoising autoencoder,SDA)进行隐层数及每层节点数结构寻优。文献[19]对几种常见机器学习在NSL-KDD数据集上的准确率进行了比较。由表可见,MBSO-LDWRELM的AC值最高为87.92%,优于其它对比算法,但由于NSL-KDD为不平衡数据集,仅使用准确率作为评价标准具有局限性,因此从各分类的DR、REC与FPR进行进一步比较分析。 表6 五分类下不同模型AC值/% 图5、图6对各算法分类的DR与Rec值进行了比较,由图可见,LDWRELM相较于RELM对少数类R2L与U2R的性能有所提升,反映了LDWRELM的正则化与权重选择策略对分类效果的提升。MBSO-LDWRELM在对Normal、Dos与Probe的检测效果基本持平或略有提升。相比之下,R2L与U2R的DR值与Rec值在数值上相对偏低,是由于R2L与U2R在训练集中的占比低,属于少数类,且这两类攻击类型中有新型未知攻击,尤其是R2L类型中的部分攻击条目特征与Normal类型数据十分相似,导致许多攻击条目容易被误判其它样本数量多的类。通过对U2R与R2L这两种攻击检测结果分析比较可知,RELM的检出率最低,MBSO-LDWRELM的AC值比PSO-SDA高2.2%与3.61%。并且其对这两种攻击的REC值最优,与RELM相比有很大幅度的提升,与PSO-SDA相比高14.87%与10.5%。说明MBSO对LDWRELM初始权重矩阵优化结果更好,所求的初始权重阈值能更好地提取训练集中的数据规律,尤其是对于少数类攻击。 图5 各模型DR值对比 图6 各模型Rec值对比 表7对算法误报率进行了对比。对Normal类型,MBSO-LDWRELM误报率分别比RELM、LDWRELM、PSO-LDWRELM、BSO-LDWRELM与PSO-SDA低1.92%、1.99%、0.85%、2.89%与6.21%,说明进行改进后,模型将其它攻击类型错判为Normal类型的概率更小,能更好地保证系统的安全性。同时,可观察到LDWRELM相比RELM在对少数类的误报率有所下降,但对多数类的误报率上升了,是由于基于局部距离的策略将与Normal相似的样本权重降低,造成误判为Normal的样本略有上升,但经过MBSO进行优化后,Normal误报率有所下降。而对于攻击类型Probe、Dos与R2L误报率均有所下降,对于U2R类型差异不大,原因在于U2R样本数量少,难以捕获到其特征,因此将其它样本错分到该类的情况更少。 表7 各算法FPR值对比/% 入侵检测算法的性能对检测的实时性有较强的要求,因此本文对各方法的训练时间与检测时间进行对比,结果见表8。经过MBSO算法优化后的LDWRELM在训练时间与检测时间相较RELM算法有所上升,原因在于增加的权重矩阵计算与MBSO的迭代寻优增加了对时间的消耗,但使用BSO算法优化后检测时间优于其它优化算法的时间消耗。 表8 各模型训练时间与检测时间对比 本文提出的LDWRELM通过优化样本权重设置减轻了数据不平衡和离群点对算法性能的影响,提高了对少数类的识别准确率。并对MBSO进行改进提高了种群的多样性,增强其跳出局部最优的能力,用于对LDWRELM的初始输入权重阈值寻优,提升LDWRELM的稳定性与泛化能力。实验结果表明,MBSO-LDWRELM相比传统的RELM有更好的性能,在保证高准确率与低误报率的同时对少数类样本的准确率有所提升,并有较好的实时性,为CPS在入侵检测方面提供新的可行方案,下一步考虑搭建实时入侵检测环境,进一步探索和解决模型在实际应用中遇到的问题。


2 基于MBSO-LDWRELM入侵检测模型
2.1 适应度函数
2.2 MBSO-LDWRELM模型描述

3 实验结果与分析
3.1 数据集
3.2 预处理
3.3 参数设置
3.4 实验结果
4 结束语
