基于视点变换的酒标图像数据增强研究
2022-02-14李晓晴张孝昌才子嘉马尽文
李晓晴 张孝昌 才子嘉 马尽文
(1.北京大学数学科学学院信息科学系,北京 100871;2.军事医学研究院,北京 100850)
1 引言
深度神经网络模型已经在众多的图像处理任务中表现出顶级的水平,但这些模型的学习能力通常需要大量合理的训练数据作为保障。数据的规模越大、质量越高,训练出来的深度神经网络模型就能够拥有更好的泛化能力。本质上,数据的规模和质量直接决定了深度神经网络模型学习的上限。然而,在实际应用中,所采集的数据很难覆盖全部的场景,某些场景也无法获得大量数据。例如,同一场景拍摄的图像可能由于光线不同就会产生很大的差异性;医学图像的获取往往会受到条件的限制。另外,尽管可能存在大量的样本,人工标注往往是一件高成本的事情,需要付出很大的代价。这些问题都会影响数据的数量和质量,从而影响训练出来的深度神经网络模型的性能。数据增强技术则可以解决数据的不足或不平衡等问题,产生更多的等价数据,扩大训练样本的个数以及多样性,减小不同类别样本个数的不均衡,从而提升深度神经网络模型的鲁棒性和泛化能力。
在图像处理和检索领域中,数据增强算法大致可以分为两类:基本传统的图像处理技术的数据增强算法和基于机器学习的数据增强算法。基于图像处理技术的数据增强算法是对原始训练图像实施几何变换、色彩空间变换等传统的图像处理技术来生成一些新的训练图像。其中最为典型的方法便是几何变换,包括翻转、旋转、裁剪、变形、缩放等操作。例如,深度神经网络AlexNet[1]对CIFAR数据集[2]进行分类时,使用了随机裁剪和水平翻转等策略来增强数据。颜色变换型的数据增强[3]方法,包括增加噪声、模糊、颜色变换、擦除、填充等操作。例如Facebook 的人工智能研究人员则在实现ResNet 网络时采用了颜色抖动[2]的数据增强策略。它会随机改变图像的亮度、对比度和饱和度。这些传统的数据增强技术在深度神经网络的训练中起着重要的作用。然而,具体在实际使用中,需要结合数据形式选择相应的数据增强策略,比如数据集是汽车图像数据,训练集和测试集都是正常拍摄的图像,此时翻转策略应该只使用水平镜像翻转,如果加入垂直或者原点镜像翻转,会对原始图像产生干扰。此外,还需要考虑数据增强方法的安全性[4],它是指图像在转换后保留标签的可能性。例如,旋转和翻转这两种数据增强策略在ImageNet 挑战赛数据集中通常是安全有效的,因为这个数据集中含有猫、狗等物体的图像,但在数字识别任务中就不安全了,含有数字“9”的图像,进行翻转增强后得到的可能是“6”,这样数据增强后继续保持标签会影响模型的识别能力。
基于机器学习的图像增强算法是采用机器学习方式来进行数据增强[5-7]。这类数据增强算法主要有两种。第一种是通过机器学习模型来学习数据的概率分布,然后依此随机生成与训练数据集分布一致的图像。例如,Radford等人基于对抗生成网络提出了DCGAN模型[5],可以有效地生成手写数字图像。第二种算法是通过模型学习出适合当前任务的数据增强方法。AutoAugment[6]是这种方法的典型代表。它能够使用增强学习从数据本身寻找最佳图像变换策略,对于不同的任务学习不同的增强方法。基于机器学习的图像增强算法虽然可以极大地改善图像增强的质量,但是它对原训练集中每类的原始样本量要求都比较高,需要大量的样本才可能有比较的效果。实际上,我们所要解决的酒标图像检索任务的数据集难于达到这些条件。此外,这类算法往往需要很高的计算成本。通过上述分析,我们看到深度神经网络的学习效果与数据增强技术紧密相连,目前几乎所有的图像处理和检索任务都用到了数据增强策略[8-10]。
目前,随着人民生活水平的提高和红酒文化的发展,建立一个高效的自动化酒标图像检索系统变得越来越重要。然而,由于实际的酒标图像数据集来自于不同用户所提供的自己感兴趣的酒标图像,自然存在着类别样本量的不均衡、许多类样本量偏少的现象,使得基于深度学习的酒标图像检索模型难以进行有效的训练和参数学习。因此,进行适用于酒标图像的数据增强操作就变得更为必要和迫切。我们需要对一些酒标图像数据进行增强,扩大训练样本个数,减小不同类别样本个数的不均衡,提高检索模型的学习效果。为解决这个问题,本文提出了一个专门针对于酒标图像进行变换和扩展的数据增强算法。受视觉成像原理[11]的启发,我们将酒标看作是在圆柱体酒瓶表面立体成像和表示的,并通过一个拍摄视点投影到柱面切平面而形成了所拍摄的酒标图像。这样便可通过一幅图像对酒标进行柱面建模,并通过对视点的上下,左右,远近移动来对柱面酒标进行投影变换[12]而生成新的酒标图像。通过在大规模的酒标数据集上的实验结果表明,本文所提出的基于视点变换的数据增强策略能够有效地实现对酒标数据的增强,并且显著提高了酒标检索模型的检索能力。
本文的结构安排如下:在第2节中,我们详细介绍酒标图像检索中的数据增强任务;我们在第3 节中设计了基于投影变换的酒标图像数据增强算法,包括视线的左右、上下、远近移动三种增强方式;在第4节中,我们进行了对比实验,并验证了所提出的酒标图像数据增强算法的有效性;最后在第5 节中对本文工作进行总结。
2 酒标图像检索与数据增强
酒标图像检索是指当用户将随手拍得的红酒酒标图像输入到酒标图像检索系统中时,该系统能够返回输入图像中红酒的身份信息,包括主品牌(生产厂家)和子品牌(酒款),反映为不同的酒标。根据红酒的身份,检索系统则可提供出该红酒的生产厂家和地区、生产年份、价格、购买渠道等用户关心的信息。随着目前人民生活水平的提高和红酒文化的发展,建立一个高效的自动化酒标图像检索系统已经变得越来越重要。尽管人们已经开发出了一些APP 产品,但它们的检索的正确性还很低,难以满足人们的实际要求。随着深度学习技术的快速发展,酒标图像检索系统已经采用深度神经网络模型,并且显著提高了检索的正确率。然而,目前的酒标图像是来自于不同用户所提供的自己感兴趣的酒标图像,存在着类别样本量严重不均衡的现象,并且很多类的酒标样本量很少,甚至只有一个样本。这样所形成的酒标图像数据集会严重影响深度神经网络模型的训练效果,降低酒标图像检索模型的泛化能力,即只对训练集中类样本量多的酒标图像识别精度高,对类样本量少的酒标图像识别精度低,严重影响整体的检索性能。为了进一步提高酒标图像检索模型的性能,我们需要对这些酒标图像进行数据增强,设计一种专门针对于酒标图像数据的图像增强策略,有效扩大酒标数据集中训练样本的个数,减小不同类别样本个数的不均衡,提高酒标检索模型的学习效果。
3 酒标图像数据增强算法
我们所提出的红酒酒标图像数据增强算法主要由三部分构成:预处理部分、视点变换部分和后处理部分。图1 展示了该算法的大致流程。其中,在预处理部分中,酒标图像是通过训练好的全连接网络(Fully Convolutional Networks,FCN)[13]模型去除原始酒标图像中的复杂背景干扰,得到只含有酒标区域的分割图像。接下来,在分割后的酒标图像上,我们根据视点变换的类型(视点的上下,左右,远近移动三种类型),对酒标进行柱面建模,通过投影变换、逆投影变换[14],双线性插值[15]等一系列操作生成新图像。然而,此时的新生成图像通常含有黑色边缘,这会干扰检索模型的训练。因此,我们的算法又对其进行了后处理去除这些黑色边缘,最后输出增强后的酒标样本图像。我们下面对算法流程中的三个部分进行详细的描述。
3.1 预处理--酒标分割
为了减少酒标图像中背景因素对酒标数据增强过程的干扰,我们首先需要将酒标区域与背景区域进行分离,这本质上是一个二值语义分割问题。很多研究表明,全卷积网络(FCN)对于语义分割是非常有效的。本文提出的酒标区域分割和提取算法便是采用了FCN 模型。图2 展示了FCN 模型提取酒标区域的过程。我们首先将主体网络为VGG19 的FCN 网络在VOC2012 数据集上进行预训练,然后使用迁移策略,在我们自己构建的专门用于酒标分割的酒标数据集上进行微调得到最终的FCN 模型。这样,当原始酒标图像输入到训练好的FCN 模型后,我们便得到该输入图像的掩码图像。该掩码图像中的白的部分对应着原始图像中的酒标区域,黑色部分对应着原始图像中的背景区域。掩码图像作用在原酒标图像上,就可以实现对原图像的切割,提取出酒标区域,从而达到了去除背景区域干扰的目的。
3.2 基于视点变换的图像增强方法
根据实际情况,酒标是贴在圆柱体酒瓶的表面上。因此,我们可将真实的酒标理解为圆柱体表面,并通过一个拍摄视点投影到柱面切平面而形成了通常的酒标图像。反过来,我们则可通过一幅酒标图像对酒标进行柱面建模,得到立体表示的酒标。
3.2.1 基于视点左右移动的图像增强算法
当视点在水平面上左右移动,相当于圆柱体自身沿主轴进行旋转。因此,我们可采用由FCN 模型所提取的酒标图像,根据视点在水平面上的左右移动所产生的旋转角度进行坐标变换来建立新的酒标图像。图3 是视点左右移动的柱面建模示意图,注意这里是让视点E保持不变,而是等价地让柱面逆时针旋转θ角。圆柱上的一点A',在平面上的投影为A。当圆柱逆时针旋转θ角之后,A'点变换成为B'点,而B'点在平面上的投影为B。E点为视点,过E点作圆柱轴的垂线交圆柱的轴于点O。以O点为坐标原点,圆柱的轴为y轴建立空间坐标系。
为了便于直观理解,我们在图4 展示了视点左右移动的空间建模的俯视图。根据这个俯视图中的几何关系,我们求解其变换规则。设圆柱的半径为r0,坐标原点到视点E的距离记为r1。设原始的酒标图像的宽的像素点个数为W0,高的像素点个数为H0,每个像素的长度为a0。那么,在图中,有几何关系:
因此,可以得到:视点在水平面上前向移动所相当于圆柱顺时针旋转θ角。在旋转的过程中,原来的A'点到达了现在的B'点,在平面上看是A点到达了B点。新生成的图像将取不到AB之间的像素。新生成的图像的宽度变为‖CB‖+‖CA‖,其中:
因此,新生成的图像的宽包含的像素点个数W1为:
新生成的图像的高包含的像素点个数H1=H0。
接下来,我们按照图5所示的流程,经过一次逆透视变换(柱面投影),一次旋转变换,一次透视变换(平面投影),建立起A,B两点之间的对应关系,再利用双线性插值就能够生成旋转之后新样本图像。
图5生成新样本图像的流程图中每个步骤的具体变换关系如下所示:
(1)新图像的像素点(i,j) →B(x1,y1,z1)
(2)柱面投影变换B(x1,y1,z1) →由于:
(6)原图像点(i',j') →新图像点(i,j):
由于i',j'存在不是整数的情况,需要用双线性插值法进行处理,从原始图像I0(i',j')得到新图像I1(i,j)。首先令p=i'-s,q=j'-t,其中s、t分别是不大于i',j'的整数,则有:
3.2.2 基于视点前后移动的图像增强算法
通过3.2.1 节中的流程,我们实现了基于视点在水平面上的左右移动时的新酒标图像生成的过程。同样的原理,我们可以建立视点在水平方向上前后移动的模型。如图6 所示,圆柱上的一点A',在平面上关于视点E的投影为A,关于视点E'的投影为B,视点E与视点E'在水平方向上成前后关系。同样,为了便于理解以及推导公式,我们在图7展示了视点前后移动的空间建模的俯视图,基本的变量关系参见图4的设置。
从图7 可以看出,视点在水平方向上向前移动和向后移动所形成的投影平面的区域大小是不同的。视点前移,平面上的成像区域变窄;视点后移,成像区域变宽。设变换后像素间距为a,依据。设新生成的图像的宽包含的像素点个数为W2,新生成的图像的高包含的像素点个数H2,且有H2=H0。根据几何关系,可求得:
接下来,根据像素点变换关系生成新图像。
(1)新图像的像素点(i,j) →B(x1,y1,z1)
(4)A(x0,y0,z0) →旧图像的像素点(i',j'):
(5)原图像点(i',j') →新图像点(i,j):
由于i',j'存在不是整数的情况,需要用双线性插值法进行处理,从原始图像I0(i',j')得到新图像I2(i,j)。首先令p=i'-s,q=j'-t,其中s、t分别是不大于i',j'的整数,则有:
3.2.3 基于视点上下移动的图像增强算法
视点在竖直方向的上下移动,即俯视与仰视的柱面建模示意图与前两种视点变换的建模示意图不同。如图8 所示,需增加一个与新视点和酒标中心的连线垂直的平面,以用于模拟视点变换后生成的新图像。圆柱上的一点A',在原平面上关于视点E的投影为A,在新增加的平面上关于视点E'的投影为B。同样,为了便于推导公式,我们在图9 展示了视点向上移动的空间建模的俯视图,基本的变量关系参见图4 的设置。从图9 可以看出,视点在竖直方向向上移动平面上的成像区域变矮,设新生成的图像的宽包含的像素点个数为W3,新生成的图像的高包含的像素点个数H3,且有W3=W0。设变换前后像素间距分别为a0和a,同图3的几何关系,有:
接下来,根据像素点变换关系生成新图像。
(1)新图像的像素点(i,j) →B(x1,y1,z1)
(5)原图像点(i',j') →新图像点(i,j):
由于i',j'存在不是整数的情况,需要用双线性插值法进行处理,从原始图像I0(i',j')得到新图像I3(i,j)。首先令p=i'-s,q=j'-t,其中s、t分别是不大于i',j'的整数,则有:
至此,我们已经得到了视点在左右、前后和上下移动时生成新酒标图像的数据增强算法。
3.3 后处理--去除黑色边缘和规范化
由于视点的移动可能会出现一些边缘区域无法恢复,这样根据视点变换的计算公式所生成的新酒标图像会出现一些异常的情况,即所新生成的酒标图像的边缘像素的坐标值会出现复数。在这种情况下,我们的解决策略是将取值为复数的像素点的RGB 值统一设置为(0,0,0),即新生成图像的有部分黑色边缘。然而,如果用这样新生成图像直接训练酒标检索模型,模型会误将黑色边缘区域作为显著特征,从而会影响训练出来的模型的检索精度。为了解决这个问题,我们需要对视点变换部分生成的图像进行后处理,去除新生成图像中黑色边缘对酒标检索模型的影响。因此,算法的后处理部分的主要操作是:首先通过检测视点变换部分生成的图像中每行每列的像素值,确定图像黑色边缘区域与其非黑色区域的边界,然后基于这个边界取其最大内切矩形,并将这个矩形内的图像区域进行规范化处理形成最终的酒标图像。图10 展示了基于视点变换的酒标图像数据增强算法中后处理过程。其中图(a)中的红线表示图像黑色边缘区域与其非黑色区域的边界线,绿线表示非黑色区域的最大内切矩形。图(b)代表算法去除黑色边缘区域并规范化后最终得到的酒标图像。
4 实验
4.1 数据集和评价准则
本文的实验所用到的数据集主要有两个:酒标分割数据集和酒标检索数据集。酒标分割数据集专门用于训练预处理部分中的酒标分割模型。它是经过专业性的收集、选择和标注的酒标图像数据集[17]。该数据集共包含9000酒标图像,每个酒标图像都被人工标注为酒标区域和背景区域。其中5000 个图像用来微调训练FCN 分割模型,剩下的4000 个图像用来测试FCN 模型的酒标分割性能。其中,分割性能的评价准则是均交并比[17](mean Intersection over Union,mIoU)。
酒标检索数据集主要用于评估本文提出的数据增强算法的性能。它是由睿寻科技(北京)有限公司提供的。该数据集一共包含217970 个酒标图像。每个图像都被标注为一个主品牌(生产厂家)和一个子品牌(酒的种类)。共52309 个酒标主品牌(生产厂家),155673 个酒标子品牌(酒的类型)。这个数据集中的所有图像都是用户使用手机或其他电子拍摄设备随意拍摄得到的。所有图像的大小均为500×375,并且所有的图像都为RGB 格式。图像中包含许多干扰因素,如背景变化、光线变化、对比度变化、图像旋转等。图11展示了酒标检索数据集中的部分样例。表1给出了该酒标检索数据集上主品牌的相关信息。由表1 可以看出,该酒标检索数据集类样本量极不均衡,并且每个类的样本量不足,每个酒标主品牌的样本量最多不超过10 个,甚至很大部分的酒标主品牌的样本量仅有1个。
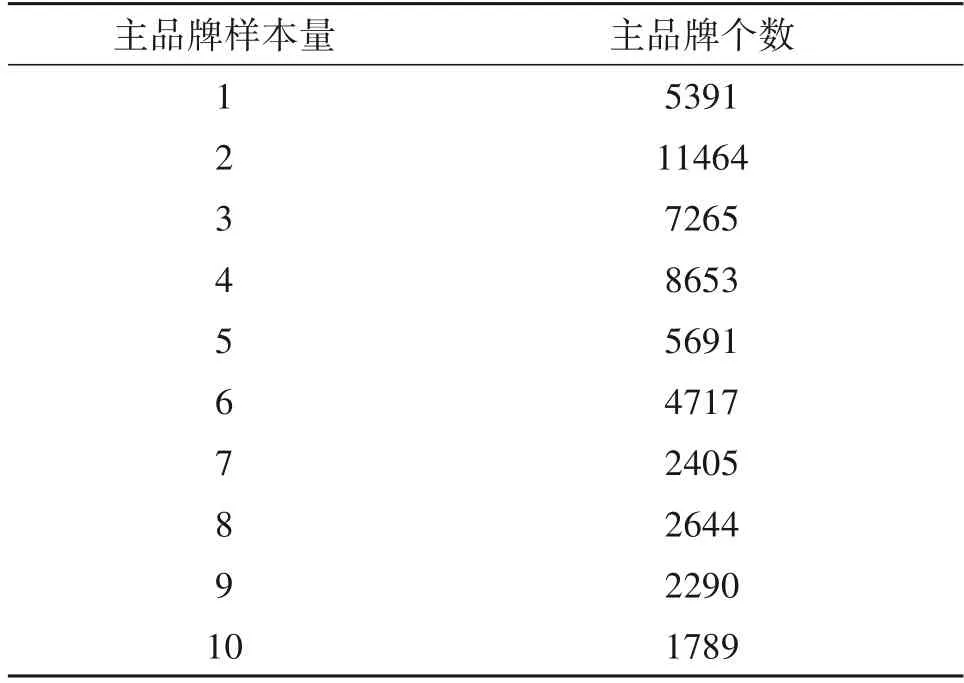
表1 酒标检索数据集主品牌信息Tab.1 Main brand information of the wine label retrieval dataset
本文使用数据增强后的训练集训练出来的酒标检索模型的酒标检索性能作为增强算法的评估标准。并且我们使用平均精确率(Mean Precision,MP)表示对于酒标检索模型的性能。精确率(Precision,P)的定义为:
上式中,TP(True Positives)代表将正类预测为正类数,即检索系统准确检索到的相关图像的数量;FP(False Positives)代表将负类预测为正类数,即检索系统错误检索到的图像的数量,那么TP+FP 就是检索系统所有检索到的图像总数。为了减少测量误差,本文每个实验都运行100 轮,第i轮实验获得的精确率记为Pi,每个算法的MP是该算法实验100次获得的P的平均值。
在没有特殊说明的情况下,我们的实验均是在Ubuntu 16.04 中基于Python 代码完成的。实验所用服务器的硬件配置如下:显卡为NVIDIA Tesla M40,内存为24GB GPU,处理器为E5-2620 v4 @2.10 GHz s×2。在数据增强后,我们使用CSCFM 算法[16]作为后续的酒标检索模型。且CSCFM 算法中的δ和M2这两个参数分别设置为90%和5。此外,实验中的深度网络都先在VOC2012 数据集上预先训练。然后再分别在各自任务下的酒标数据集进行微调。其他关于学习率及其他参数的设定均参考CSCFM在原始论文[16]中的设置。在基于变换的增强算法中,为了算法的实用性。如果视角变换和去除黑边部分都需要采用逐像素检查的方式,运行速度相对较慢。所以在实验采用了多进程并行的方式进行算法加速,加大优化力度,提高算法的实用性。
4.2 实验结果
我们在酒标检索任务上评估了多种数据增强算法,这些数据增强算法包括两类,一类是传统的数据增强算法,分别是:数据复制、数据翻转、数据旋转、添加高斯模糊、改变数据对比度与亮度、添加噪声和本文提出的基于视点变换的数据增强算法,另一类基于深度学习的数据增强算法,分别为DAGAN 算法[18]和Fast AutoAugment 算法[19]。其中,DAGAN 算法通过训练一个GAN,输入已有的数据,生成新的与输入数据属于同一类的数据。Fast AutoAugment 算法对于给定数据集,通过学习其特征探索出最优的数据增强策略组合。在酒标检索任务中,我们选用所有酒标主品牌样本量大于等于2的酒标数据组成我们实验用的数据集。因此,该数据集一共有212579 个酒标数据,共46918 个酒标主品牌。并且对该数据集中的每个酒标主品牌都随机选择一个样本组成测试集,剩下的所有图像作为原始的训练集。在这个原始的训练集上分别使用不同的数据增强算法进行数据增强,使得增强后的数据集中每个主品牌下的样本量都约为20。接下来使用数据增强后的训练集训练CSCFM检索模型,在测试集上评估模型的酒标检索性能,从而评估数据增强算法的有效性。
表2列出了使用不同数据增强策略后的训练集训练出来的酒标检索模型在测试集上的评测结果。从实验结果可以看出使用不同的数据增强算法训练出来的酒标检索模型的性能不一样。使用数据翻转比使用单纯的数据复制策略训练出来的模型对酒标主品牌的识别精确率低2.4%,这是因为,对于酒标检索数据来说,用户拍摄酒标时,一般是正持酒瓶拍摄,得到的酒标数据也是正的。数据翻转,无论是正反翻转,还是左右镜面翻转后的图像在酒标数据集中几乎不存在。因此,使用数据翻转增强的图像不但没有增加模型的泛化能力,反而可能会对模型训练造成干扰,因此酒标主品牌的识别准确率会低。在用户拍摄酒标数据时,由于拍摄环境的不同,噪声、光线的强度、拍摄设备都是一些重要因素,影响酒标图像的拍摄。因此,在酒标数据增强过程中,添加噪声,改变酒标图像的对比度与亮度等都是很有效的。相比于单纯的数据复制,使用添加噪声和改变对比度与亮度这两种数据增强策略训练出来的模型对酒标主品牌的识别精确率分别提高了1.5%和1.9%。DAGAN 算法的数据增强效果和数据复制的增强效果相似,对酒标检索准确率的提高有限。而Fast AutoAugment 算法在提高酒标图像检索准确率方面明显优于数据复制、数据翻转、数据旋转、添加高斯模糊、改变数据对比度与亮度、添加噪声等算法。这是因为,在Fast Auto-Augment 算法中的子策略设置中已经包含了上述所有的策略,通过学习得到的增强策略组合则集中了各个单一增强策略的优势。我们提出的基于视点变换的数据增强算法对应的模型相对于数据复制对应的模型,对酒标主品牌的识别精度率显著提高了4.1%,在所有的数据增强策略中表现最优。这主要是因为,基于视点变换的数据增强算法充分考虑了酒标数据的特性,将酒瓶看作圆柱体,不同用户拍摄酒标图像时,视点往往不一样,视点左右移动、上下移动、远近移动都是很常见的现象。因此,基于视点变换的酒标数据增强算法是非常有效的。
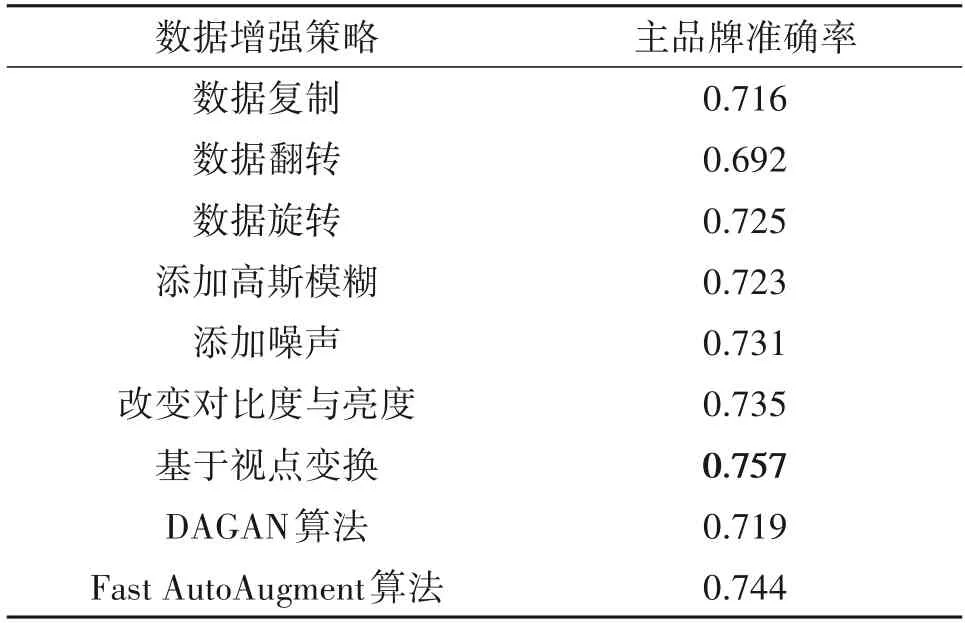
表2 使用不同数据增强策略训练的酒标检索模型在测试集上的评测结果Tab.2 Evaluation results of wine label retrieval models trained with different data augmentation strategies on the test dataset
我们挑选了增强测试集中的部分酒标图像,用于展示本文提出的数据增强算法在不同试点变换下的酒标图像增强效果。图12 展示的是基于视点左右移动的数据增强效果,其中图12(a)为原始图像,图12(b)和图12(c)分别为视点向左移动和视点向右移动后的增强图像。从后两幅图像可以看出,基于视点左右移动的增强效果是比较自然和真实的,能够比较好的模拟现实生活中酒标图像的拍摄。图13 展示了基于视点前后移动的数据增强效果。其中,图13(a)为酒标样本原图,13(b)和13(c)分别是视点往后移动和往前移动下生成的增强图像。图14 展示了基于视点上下移动的数据增强效果。其中,图14(a)为酒标样本原图,14(b)和14(c)分别是视点往下移动和往上移动生成的增强图像。从这些图像也可以看出,本文提出的基于视点变换的图像增强算法能够自然真实地模拟在不同视点下拍摄的酒标图像,能够有效地实现对酒标数据的增强。
5 结论
针对现有的酒标数据集存在着类别样本量不均衡、多类样本量很少的实际情况,本文提出了一个专门针对于酒标图像进行变换和扩展的数据增强算法。首先,我们通过FCN 模型去除原始酒标图像中的复杂背景干扰,得到只含有酒标区域的分割图像。然后,我们将酒标表示在圆柱体酒瓶的表面上,即将酒标进行圆柱体表示,并通过一个拍摄视点投影到柱面切平面而形成了酒标图像。这样则可通过一幅图像对酒标进行柱面建模,并通过对拍摄视点的上下、左右、远近移动来对柱面酒标进行投影变换而生成新酒标图像。进一步,通过对其进行后处理得到有效的规范化酒标图像样本。我们最后在一个大规模酒标数据集上进行了酒标图像检索实验。实验结果表明,我们提出的基于视点变换的数据增强算法能够有效地实现对酒标数据的扩展,并且显著提高了酒标图像检索模型的检索性能。
