一种支持多数据块混合处理的FFT优化方法
2022-02-13洪钦智王志君郭一凡梁利平
洪钦智,王志君,郭一凡,梁利平
(1.中国科学院微电子研究所,北京 100029;2.中国科学院大学 集成电路学院,北京 100049;3.北京邮电大学 集成电路学院,北京 100876)
快速傅里叶变换(Fast Fourier Transform,FFT)是一种用来实现时域到频域转换的计算方法,被广泛应用于各种通信系统中。当前许多基于正交频分复用技术(Orthogonal Frequency Division Multiplexing,OFDM)的通信系统,如4G LTE(Long Term Evolution)/LTE-A[1]、无线本地局域网(Wireless Local Area Network,WLAN)[2],以及正在推广的5G NR(New Radio)系统[3],都使用了FFT技术。随着无线通信标准的演进,通信系统对FFT技术的要求也越来越高[4-5]。未来的高质量多模通信系统[6-8]要求FFT处理器适配多种点数模式的FFT处理和离散傅里叶变换(Discrete Fourier Transform,DFT)处理,并且能够达到极高的吞吐率和处理效率。
传统的FFT处理器主要包括流水线型和存储器型两种实现结构,流水线型结构较难同时满足高吞吐率和较多点数模式的支持[9],而面向多模通信应用的FFT处理器主要采用存储器型结构[10-13]。文献[11]采用素因子算法实现了128~2 048点FFT处理和12~1 296点DFT处理。文献[12]提出了一种针对任意点数的无冲突地址策略,并通过高基底的方式来减少运算周期。文献[13]通过设计高效的并行运算部件及改进数据并行访问策略等方法有效地支持了多点数处理(54种模式)和较高的1R(基1归一化)吞吐率。但是这些设计依然存在不同模式下吞吐率不均衡、绝对吞吐率较低等问题。
面向以4G/5G为代表的高性能多模通信应用,笔者通过有效的优化设计实现了一种支持60种点数模式的高性能FFT处理器。设计了一种基于WFTA(Winograd Fourier Transform Algorithm)算法的深度流水蝶形运算单元,支持1个基9/ 2个基8/ 3个基5/ 4个基4/ 5个基3的高吞吐率蝶形运算;提出了一种支持多FFT数据块混合处理的计算方法(REPEAT模式),有效解决了深度流水线气泡导致的吞吐率降低问题,实现了各种点数模式下的吞吐率均衡;还完成了支持多FFT数据块混合处理的块浮点处理电路的设计,并以此为基础完成了多模高性能FFT处理器的实现。相比现有的设计,笔者设计的FFT处理器实现了更多点数模式的支持,并且在增加有限资源的情况下较大幅度提高了处理器性能。
1 设计思路与理论分析
面向4G/5G小基站芯片中的FFT/DFT运算加速需求,以及需要支持64~4 096点的FFT/IFFT(Inverse FFT,快速傅里叶逆变换)和12~3 240点的DFT/IDFT(Inverse DFT,离散傅里叶逆变换)的运算需求(共计60种点数模式);同时,4G/5G小基站的基带信号处理需要满足极高的吞吐率要求。考虑到需要同时满足高吞吐率和对多种点数模式的支持,笔者设计采用基于存储器的实现结构。
基于存储器结构的FFT处理器在完成一个N点FFT的运算过程中,总的周期数由运算周期和数据搬运周期构成,数据搬运周期包括数据搬入(存储器)周期和数据输出(存储器)周期。当存储器采用2N的乒乓结构时,数据输入、数据输出可以流水执行。假设数据输入、输出和运算的存储器访问并行度为s,则对于一个N点FFT运算,输入周期和输出周期为N/s。对于2N结构,数据输入和数据输出可以流水执行,总的输入输出周期C0=N/s。对于采用混合基算法的FFT运算,N点FFT可以分解成k级的混合基运算L0×L1×…×Lk-1,其中第i级的运算需要执行基为Li的蝶形运算,运算个数为L0×L1×…×Li-1×Li+1×…×Lk-1。假设各级运算过程中,从存储器中读出的数据都可以进行蝶形运算,则第i级每个周期可以执行基Li蝶形运算的个数为s/Li。完成第i级所需的周期数如式(1)所示,完成各级运算的总周期为kN/s。
(1)
考虑到蝶形运算单元并不能保证每个周期都满负荷地完成并行度s的点数计算,假设运算单元的平均资源利用率为p1,则实际的运算并行度为p1s,完成各级的总运算周期C1=kN/(p1s)。另一方面,处理流程中还有许多因素会消耗额外的周期,包括为了确保处理器能在一定的频率下,数据通路需要插入一定流水级引入的流水周期和在不同的寻址方式下存储器访存需要引入的调度周期等。假设每级运算额外引入的周期开销为Cp,则k级运算引入的额外周期数为C2=kCp。定义额外消耗周期与运算周期比p2=C2/C1,则总周期数为
(2)
FFT处理器的性能指标主要包括吞吐率和1R吞吐率,其中吞吐率表示单位时间可以完成FFT计算的点数,1R吞吐率则是表征电路工作在1 Hz下的吞吐率。由式(2)可得吞吐率的计算公式为
(3)
由式(3)可知,FFT处理器的吞吐率与并行度、运算频率成正比,还受混合基的分解级数、运算部件的资源利用率p1和表征时序周期效率的因子p2影响。
2 一种支持多数据混合运算的可配置高性能FFT处理器
基于前述对影响FFT处理器性能的因素进行的建模与分析,笔者以面向4G/5G小基站基带处理的FFT运算加速为目标,通过优化设计提高FFT处理过程的资源利用效率和时序利用效率来优化处理器性能。
设计的FFT处理器整体架构如图1所示,采用并行度为16的存储器架构,计算位宽为16I+16Q。FFT运算数据和相应的配置参数通过数据接口进行传输。控制通道根据接收到的配置参数来控制FFT运算的整体流程。FFT运算数据首先存入PPmem中(PPmem0/PPmem1,乒乓存储器),而后根据执行的FFT运算模式从PPmem中寻址出数据并送入蝶形运算单元进行运算。旋转因子生成模块根据配置信息寻址出对应的旋转因子来参与运算。蝶形运算单元基于当前的控制信息配置成相应的运算模式。在完成相应的蝶形运算后,数据通过乒乓选通逻辑写回到PPmem中。与此同时,块浮点处理单元用来完成运算过程中FFT指数的更新操作。
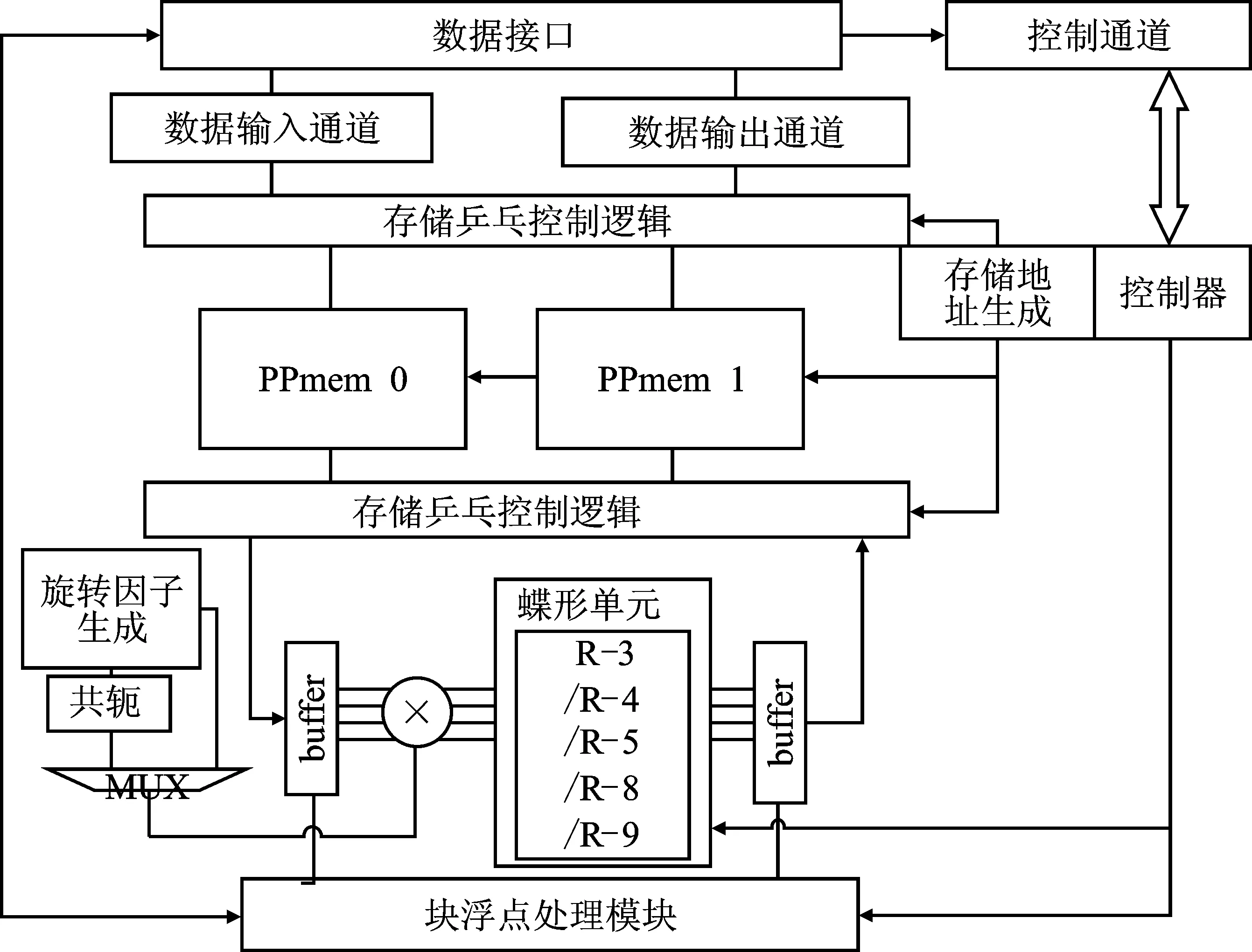
图1 FFT处理器结构图
2.1 基于WFTA算法的可配置蝶形处理单元
通过对所需支持的60种点数进行分解,需要至少支持基3、基4、基5的蝶形运算,并且对出现较多的多级基3和基4进行合并,通过支持基8、基9来减少级数。WFTA算法[14]是一种能有效控制蝶形运算资源的算法,笔者以统一的WFTA分解来完成基3、基4、基5、基8、基9蝶形运算单元的设计。
根据各种基下的WFTA算法运算流程,抽象出蝶形运算电路的基本结构,如图2所示,该结构包含了前级加法运算,中间级常数乘法运算和后级加法运算。以级联计算最复杂的基9 WFTA运算为例,包含了9个输入数据,前级加法进行了3轮加法运算,中间级进行常数乘法运算,后级加法进行了3轮加法运算,而后并行输出9个运算结果数据。其它的基8、基5、基4、基3 WFTA蝶形运算的整体运算流程类似,通过控制相应的数据选通,蝶形运算单元将复用这些运算器重构成相应基的WFTA蝶形运算电路。
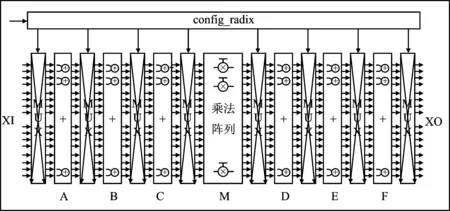
图2 WFTA蝶形单元结构图

表1 不同基底运算器资源占用
基于统一的WFTA算法,各种基底下的运算流程统一,实现的电路结构化,可以很好地进行复用和流水化处理。单元电路在复用的运算部件上完成了一路基9、两路基8、三路基5、四路基4、五路基3的功能实现,并根据延时数据进行较为均衡的流水线化处理,在55 nm工艺下运算电路工作频率达到500 MHz,确保了较高的运算性能。不同基底(Radix-X表示基X)占用的运算资源如表1所示。从表1可以看出,采用这样的复用关系,在运算器配置成不同基底的运算模式时,所需的运算资源比较接近。因此,采用这样的复用结构,可以确保在不同的运算模式下,空间效率因子保持较高的值。表2给出与其它文献的蝶形单元完成一次蝶形运算(各种基)所需的周期对比。

表2 蝶形单元计算周期对比
2.2 一种支持多数据块混合运算的FFT计算方法
为了提高处理器的吞吐率性能,通过对蝶形单元数据通路进行流水线化操作来提高整体电路的运行频率。但是基于混合基算法的FFT处理各级蝶形运算之间存在数据相关性,即后级的蝶形运算需在前一级蝶形运算全部完成后才能进行,这种数据相关性会降低基于存储结构的FFT处理器运算器的时间利用率,特别是当数据通路的流水级数较多时会引入较多的流水线气泡而降低处理器性能。
笔者提出了一种新的FFT计算方法,采用多FFT数据块混合运算来提高FFT处理器的时间利用效率,称这种计算方法为REPEAT模式。该模式通过实现多个FFT数据的混合计算,解决了传统计算方法下基于存储器结构的FFT处理器因为混合基算法不同级间数据运算相关和流水线气泡导致的吞吐率下降问题。
图3为REPEAT模式的执行流程,通过同时将多个相同点数的FFT数据块存入存储器中,并且顺序地完成不同FFT数据块的混合基中相同级的蝶形运算,解决同一个FFT数据块不同级间的数据相关导致的流水线气泡问题。为了支持REPEAT模式,FFT处理器需要对多个FFT数据进行混合蝶形运算。笔者充分利用所支持最大点数(4 096)对应的存储器MEM空间来提供不同的并行度支持。表3为笔者设计支持的60种模式的点数列表以及相应的REPEAT模式并行度。基于此设计,支持REPEAT模式的FFT处理器不需要增加额外的存储器MEM空间和运算资源,只需要通过寻址控制来选通相应的数据。

图3 REPEAT模式执行流程

表3 FFT处理器支持点数及REPEAT模式并行度
以12点FFT运算为例来阐述REPEAT模式的优化过程。图4(a)为12点FFT数据从MEM读出,通过数据通路再写回MEM的流水线图。12点FFT根据混合基算法分解为基3和基4两级运算,其中第1级包含了4个基3运算,第2级包含了3个基4运算。蝶形运算单元可以支持5个基3或4个基4的并行运算,因此12点FFT的第1级运算和第2级运算都只需1个计算周期完成。如图4(a)所示,第1个周期从存储器取出12个点FFT数据并进行第1级4个基3运算,由于深度流水线的影响,需等到第10个周期,数据才能写回存储器,而后数据再次从存储器读出,进行第2级的3个基4运算。
从图4(a)可以看出运算单元的利用率很低,10级流水中只有1个周期处于有效运算状态,其他周期都处于空闲状态。基于存储器结构的FFT处理器,在进行混合基算法处理时,每级运算都需等待上一级运算完成后才能开始;这种数据依赖关系导致了运算单元无法被充分利用,数据通路流水线引入气泡。
图4(b)为REPEAT模式的处理流程。在第1个周期读取第1个FFT数据块进行第1级蝶形运算后,第2个周期读取第2个FFT数据块进行第1级蝶形运算,同样,顺序读取不同FFT数据块进行第1级蝶形运算,直到完成所有FFT数据块的第1级蝶形运算;以此类推,顺序读取不同FFT数据块进行第2级蝶形运算,以此顺序完成所有FFT数据块的各级蝶形运算。对比图4(a)的单个点数FFT处理,图4(b)的REPEAT模式流水线中有效运算周期的占比明显提升。
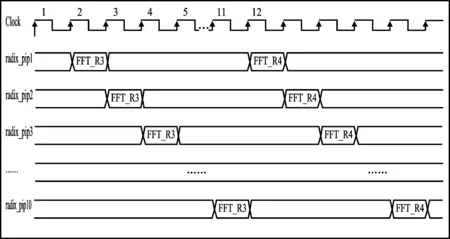
(a) 单数据模式
结合式(2)、式(3)推导可以分析各种点数模式下的普遍情况。对时间效率因子进行分析,p2=C2/C1。对于12点FFT运算,当p1/p2都为最高效率时(p1=1,p2=0),吞吐率为5.3R,而当p2下降到9时(p1=1),吞吐率下降为0.76R。基于式(3)考虑p2对吞吐率的一般性影响,假设p1=1(即空间资源利用率最高),可得
(4)
根据式(4),当p2=0时可得各点数下的理想吞吐率。考虑实际p2值可得p2影响下的吞吐率。如图5(a)对不同点数的理想吞吐率和受p2影响得到的1R吞吐率进行比较(横坐标为60种点数,由小到大排列)。可以看出流水线气泡导致的吞吐率下降,这也是许多已有研究里不同点数吞吐率不均衡,一些点数的吞吐率存在明显短板的主要原因。并且,随着流水线深度的加深,流水线气泡导致的吞吐率下降会越发明显,导致了基于存储器结构的FFT处理器难以提升工作频率。图5(b)为REPEAT模式和单数据模式下,60种点数FFT运算的1R吞吐率对比;可以明显看出,REPEAT模式可以很好地均衡各点数下的吞吐率,确保在所有点数模式下硬件处理都具有较高的效率。

(a) p2对吞吐率的影响
2.3 支持REPEAT模式的快浮点处理电路架构
当前的FFT处理器往往采用块浮点处理,可以在不需过多增加硬件资源的情况下提高FFT处理的精度。传统的块浮点处理系统只能处理同一个FFT数据。笔者提出了一种可以支持不同FFT数据混合运算的块浮点处理电路架构,以支持REPEAT模式的混合数据处理。
FFT数据从存储模块中取出进入蝶形运算单元,完成蝶形运算后写回存储模块。块浮点处理单元侦测每周期蝶形运算单元的计算结果并进行块浮点的定标移位值计算,在完成某FFT数据的某级蝶形运算后,块浮点处理单元将最终计算的定标移位值存入移位值寄存器堆,同时块浮点处理单元利用计算完成的定标移位值来同步更新指数值,并存入指数寄存器堆。由于块浮点处理的指数是共用的,只有当完成某个FFT的一级蝶形运算后才能得到该FFT数据的共同移位值(对应指数的更新值),中间的蝶形运算结果直接写回存储模块,只在下一级蝶形运算取数时进行移位处理。基于图3所示REPEAT模式的执行时序,当采用不同FFT数据进行混合运算时,在同一级FFT运算时会顺序地执行各个FFT数据在该级的蝶形运算。笔者设计了相应的移位值更新电路和指数值更新电路来实现FFT数据混合运算下的块浮点处理
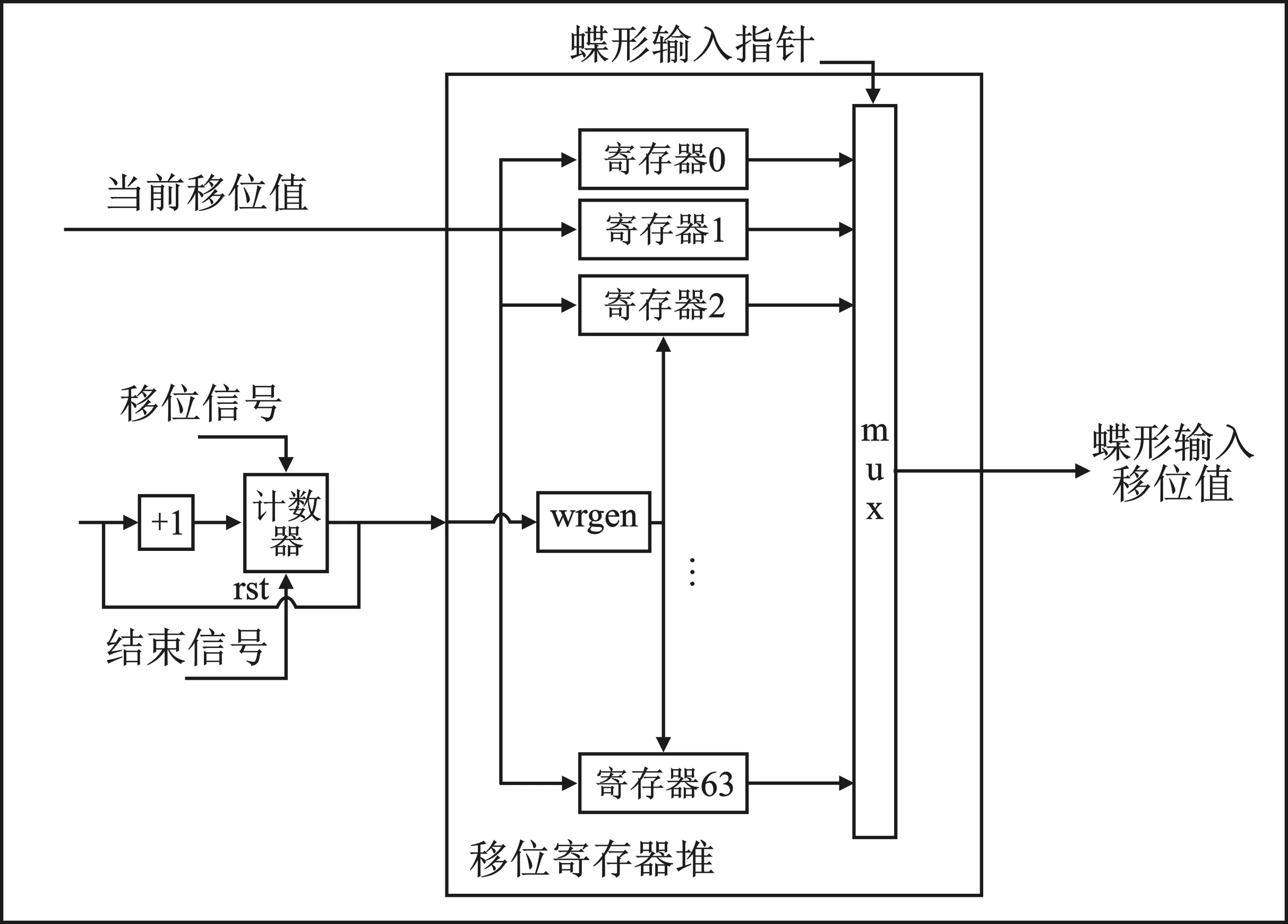
(a) 移位值更新电路结构
如图6(a)所示,移位值更新电路在混合基运算的每级蝶形运算内,根据当前处理的是第几个FFT数据来使能移位值寄存器堆中对应的移位值寄存器,并按照更新规则进行移位值运算和更新。每次FFT数据切换时产生相应的片选信号来切换对应的移位值寄存器。在蝶形运算读数阶段,控制单元会根据当前读取的是第几个FFT数据来生成蝶形输入指针,移位值更新电路根据蝶形输入指针输出所需移位值。
图6(b)为指数值更新电路,用来更新和存储不同FFT数据相对应的指数值。在FFT数据输入阶段,各FFT数据相应的指数值按顺序写入到指数值寄存器堆中。在进行FFT运算过程中,当每次完成一个FFT数据的移位值更新时,相应从指数值寄存器堆中取出该FFT数据对应的指数值,与当前移位值进行运算,而后将运算结果写回指数值寄存器中。
3 实现结果和讨论
采用中芯国际55 nm CMOS工艺对设计进行了流片验证,图7为设计实现的物理版图。FFT处理器的内核面积为1.59 mm2。最高工作频率达到500 MHz。此外,提出的优化方法已经应用在最新的4G/5G小基站基带SoC芯片中。

图7 FFT处理器版图
笔者对提出的设计在各种点数模式下进行了仿真实验,收集了执行各种点数FFT运算的周期数,表4给出了典型点数下文中设计与文献[11]、文献[13]的周期数对比。从表4中可以看出,文中设计大部分点数所需的计算周期都更少。当采用REPEAT模式进行FFT计算时,等效总周期数明显降低,特别是对于运算周期数占比较小的点数,性能可以获得数倍的提升,与理论分析和设计考量一致。表5给出了在典型点数下文中设计的FFT吞吐率与文献[11]、文献[13]的对比,可以看出文中设计的吞吐率性能有较大提升,REPEAT模式下各种点数的吞吐率也更为均衡。
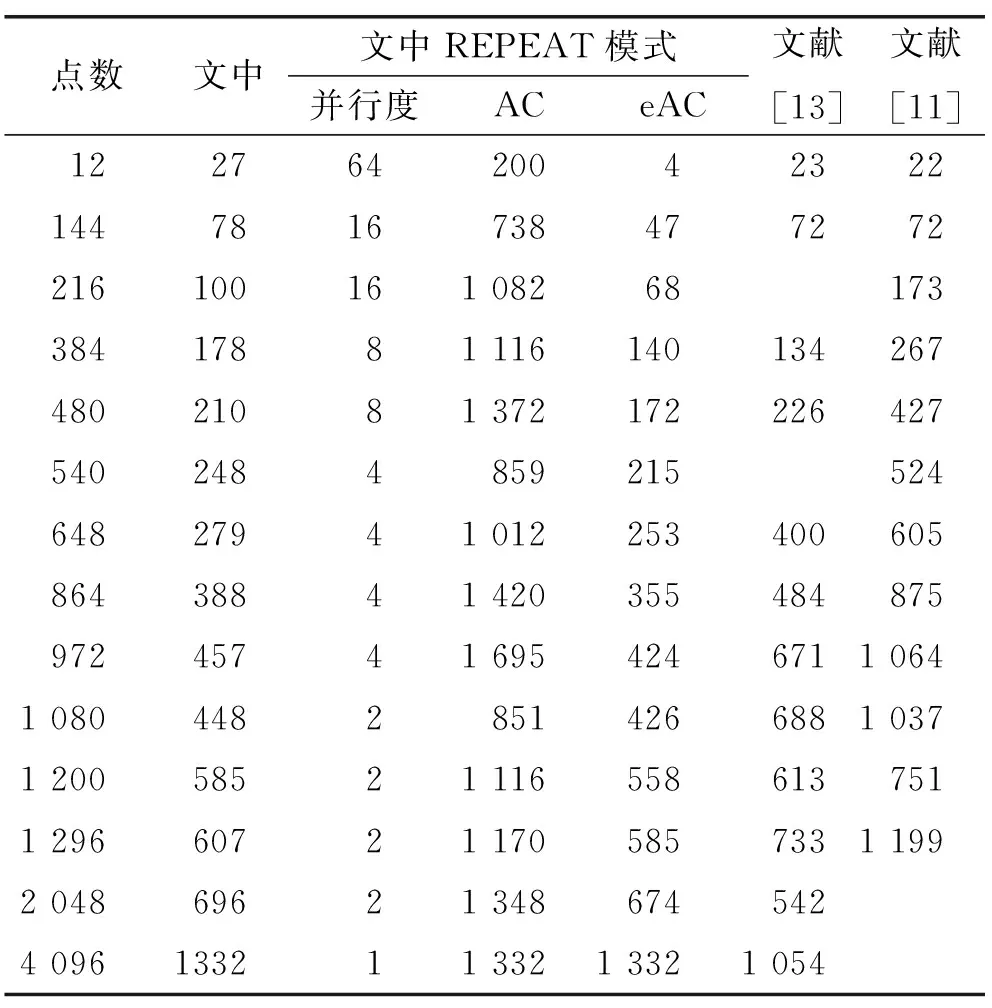
表4 典型点数下FFT处理周期比较

表5 典型点数下FFT吞吐率对比
为了对不同工艺、计算位宽、电压、运行频率下的处理器进行对比,笔者采用文献[13]给出的归一化方法对吞吐率进行面积、功耗层面上的归一化处理,分别如式(5)、式(6):
(5)
(6)
表6是文中设计各项指标与文献[11-13]的设计进行的对比。从表6可以看出,基于笔者提出的优化方法设计的FFT处理器在增加有限资源开销的情况下,能够支持更多的计算模式,吞吐率也有较大的提升,且1R吞吐率在各种点数模式下也更为均衡。

表6 FFT处理器实现指标对比
4 总 结
面向4G/5G基带处理对FFT计算提出的高吞吐率、多模式的应用需求,提出了一种可以同时支持多个FFT数据混合处理的优化方法。该方法可以有效解决基于存储器架构的FFT处理器因为计算通路流水线气泡而导致的性能损失以及由此带来的不同点数的吞吐率均衡问题。在设计了一种高效的深度流水线可配置蝶形处理单元和支持REPEAT模式的块浮点处理电路的基础上,实现了一种高性能多模式FFT处理器。在增加较少资源的情况下,比起其他文献只能在部分模式下达到较高的归一化性能。笔者设计的FFT处理器实现了各种点数模式下较为均衡的归一化性能,并且在相同工艺条件下较大幅度提高了吞吐率性能,同时支持更多的点数模式。
