基于ResNeXt与迁移学习的干制哈密大枣果梗/花萼及缺陷识别
2022-02-13喻国威张原嘉马本学
李 聪 喻国威 张原嘉 马本学,2
(1. 石河子大学机械电气工程学院,新疆 石河子 832003;2. 农业农村部西北农业装备重点实验室,新疆 石河子 832003)
哈密大枣是新疆传统名优特产之一,个大肉厚、外观紫红且具有光泽,是药食同源的滋补食品和药用食品[1]。由于缺陷枣的表面具有与果梗/花萼相似的特征,导致在红枣实际分级过程中难以对果梗/花萼和缺陷枣进行区分。海潮等[2]采用Blob分析算法进行红枣与背景的分离以及红枣表面缺陷的识别,缺陷果识别准确率可达90%以上,但无法对缺陷枣进行定位。张萌等[3]提出了一种亮度快速矫正算法,大大增强了红枣表面缺陷特征,提升了红枣检测与分级的实时性。曾窕俊等[4]提出了一种基于帧间最短路径搜索的目标定位方法,实现了红枣位置坐标随视频时间序列更新和传递。Wu等[5]采用高光谱成像技术获取反射图像,以实现常见缺陷如裂纹、虫害和淤伤的识别。
随着互联网时代大数据的爆发,深度学习已被广泛应用于人脸识别、语音识别和行人检测等[6-8]。杨志锐等[9]提出了一种基于网中网卷积神经网络对红枣进行缺陷检测的方法,该方法优于基于常规SVM的视觉检测方法和基于AlexNet网络的分类方法。方双等[10]采取多尺度卷积神经网络对黄皮枣、霉变枣、破头枣和正常枣进行了检测,模型在AlexNet卷积神经网络上进行了改进,增加了深度和宽度,提高了模型的检测准确率。Ju等[11]通过嵌入SE模块,用三重损失函数和中心损失函数代替softmax损失函数,对原始残差网络模型进行改进,并利用迁移学习技术实现了缺陷枣的检测与分类。Xu等[12]提出了一种基于特征关注度的多标签枣缺陷分类关系网络,实现了对同一红枣多种缺陷类别的检测与识别。而目前有关红枣果梗/花萼与缺陷枣识别的研究尚未见报道,缺陷枣与果梗/花萼区域有相似的灰度,易将果梗/花萼区域误判为缺陷。
文章拟以干制哈密大枣为研究对象,利用图像处理结合深度学习的方法,探索能快速、准确识别干制哈密大枣果梗/花萼及缺陷的有效方法,为后续研发干制哈密大枣在线检测与分级装置提供理论依据。
1 材料与试验
1.1 试验材料
干制哈密大枣:新疆哈密地区哈密市花园乡闪电农产品专业合作社。
鉴于鸟啄与虫蛀是干制哈密大枣中最常见的缺陷类型,在购买的干制哈密大枣通货(包含正常枣和缺陷枣)中挑选缺陷枣(鸟啄和虫蛀)和正常枣样本各200个。图1 为干制哈密大枣样本图像及其灰度特征图像,其纹理特征均很相似,且果梗/花萼和缺陷特征也比较相似。
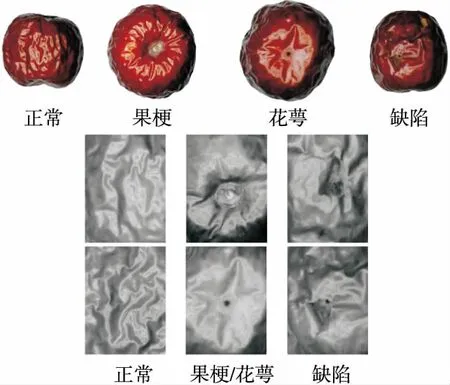
图1 干制哈密大枣样本
1.2 机器视觉图像采集系统
机器视觉图像采集系统由封闭暗箱装置、LED环形光源、HDMI工业相机(4~12 mm工业变焦镜头,1 200万像素)及笔记本电脑组成。镜头和实物距离为23.5 cm。经对原始图像质量筛选(将人为拍摄失误导致的对焦不准、曝光时间过长,以及拍摄表面与标签不一致去除)后,最终得到正常枣、缺陷枣和果梗/花萼图像各200幅,并将其尺寸批量调整为224 Pixel×224 Pixel。
1.3 试验平台
试验平台由计算机硬件和开发平台两部分组成。计算机硬件:处理器(CPU)为Intel(R) Core (TM) I7-8700 CPU @3.20GHz,图形处理器(GPU)为NVIDIA GeForce RTX2060。开发平台:Windows10操作系统上的Pytorch深度学习框架,配置NVIDIA CUDA Toolkit10.1 和深度神经网络加速库NVIDIA CUDNNv8.0.4;编程语言为Python 3.7.4。
2 图像预处理
2.1 图像增强
图像分类时,有效的图像数据增强可以进一步提高分类精度[13]。图像数据增强方法包括旋转、平移、翻转、随机裁剪等。鉴于干制哈密大枣更换不同方向角度观察都不会改变其特征的特点,为增加训练样本数据量,采用线下图像扩充和实时扩充的图像数据增强方法。模型训练前对数据样本进行随机翻转和随机旋转;训练过程中使用预先的神经网络对数据样本实时扩充,包括随机剪裁和尺寸变换。经图像扩充后训练样本数量增加8倍,加上训练过程中实时扩充后,极大扩充了训练样本的多样性。
2.2 感兴趣区域提取
为研究图像感兴趣区域提取后是否有利于深度学习模型更好地学习特征,对拍摄的干制哈密大枣感兴趣区域进行批量预处理,为了规范化数据集,利用Python语言调用OpenCV库编写图像预处理程序,对干制哈密大枣图像依次进行如下预处理:
(1) 提取干制哈密大枣RGB图像中B通道,采用阈值分割算法去除背景,阈值设置为130。
(2) 填充干制哈密大枣目标区域孔洞,形成目标掩膜。
(3) 利用中值滤波器,对图像边缘平滑去噪。
(4) 将掩模与原始图像相乘以获得彩色区域。
(5) 采用最小矩形框算法提取目标区域。
3 分类方法
3.1 迁移学习
迁移学习是一种在相似或不同领域快速实施学习的过程,文中采用迁移学习技术,通过对原始模型在ImageNet数据集上进行预训练得到模型参数文件,然后对改进模型的网络权值进行全局微调并初始化,最终得到新的模型参数文件。
3.2 残差网络
在深度卷积神经网络训练过程中,通常会出现梯度消失的问题,随着训练的进行,早期层的梯度幅度迅速降低到零。为解决这一问题,He等[14]提出了残差网络(ResNet)学习模型。ResNet在网络中引入残差结构,通过捷径连接的方式形成跳跃式结构,为解决深层卷积神经网络模型的错误率不降反升的难题提供了新的方向。
图2为残差模块学习示意图,假设某段神经网络的输入样本是x,期望输出是H(x),以往的卷积神经网络模型都试图通过堆叠不同的层找到可将输入x映射为输出H(x)的函数,然而残差网络的思想是构建等式(1)。

图2 残差模块学习示意图
F(x)=H(x)-x,
(1)
式中:
x——网络输入;
F(x)——堆叠的非线性层,使得H(x)表示为F(x)+x。
每个ResNet块都包含一系列层,如图3中有两个权重层,每一个权重层的输出和堆叠的权重层最终输出见式(2)和式(3)。

图3 ResNeXt网络残差模块结构
F(x)=W2δ(W1x),
(2)
H(x)=W2δ(W1x)+x,
(3)
式中:
δ——线性激活函数ReLU;
H(x)——最终输出(其中x的维度和F必须一致);
W1、W2——第一层和第二层的权重。
GoogLeNet模型中提出的一种通过“分解—转换—融合”的策略,即“Inception模块”,采用多尺度卷积核提取特征,以提高模型的非线性表达能力,提升模型性能。ResNeXt网络借鉴了“Inception模块”的策略,通过在残差结构中增加独立路径的数量即“基数”的超参数来增加网络的维度。网络结构中基数采用分组卷积的思想,将获得的特征图输入分成不同组,分别进行正常的卷积操作,最终将卷积后的结果进行合并。与“Inception模块”不同的是分组卷积层并不是使用不同的结构,而是采用相同的结构,因此需要微调的超参数只有一个,大大简化了网络结构[15]。如图3所示为ResNeXt网络残差模块结构。
3.3 模型结构
文中的分类模型是在ResNeXt-50网络结构的基础上进行进一步的改进。通过观察ResNeXt-50网络结构可知,输入主干是由一个7×7的卷积核等组成,其中卷积层的计算成本为卷积核宽度或者卷积核高度的平方,因此一个7×7卷积核的计算量是3个3×3卷积核计算量的5~6倍。文中将输入主干中的7×7卷积核替换成3个3×3的卷积核,其中第一个卷积核步幅为2,输出通道大小为32,最后一个卷积核输出通道大小为64,在保证和原始网络输出主干信息一致的情况下大幅度降低了计算成本,同时减少网络模型参数数量。同时,文中将原始模型架构中7×7的全局平均池化层替换成2个步长为2的3×3卷积核,采用批量归一化处理,并将全连接层输出维度设置为3,对应3种类别。在保证卷积层细节不被丢失的前提下,还可以减小网络模型参数数量,提高模型精度。
4 结果与分析
4.1 图像识别模型性能对比
为验证试验提出的模型在干制哈密大枣果梗/花萼及缺陷分类识别上的优越性以及感兴趣区域提取是否有利于模型更好地学习有用特征,按80%和20%的比例将2 400幅图像随机用于训练与验证。相同试验条件下与ResNet-50、VGG-19、GoogLeNetInception v2和ResNeXt-50深度卷积神经网络标准模型进行试验对比,并将改进的ResNext-50模型分别对感兴趣区域提取前、后的干制哈密大枣样本图像进行实验验证,图4为感兴趣区域提取效果。

图4 感兴趣区域提取效果
VGGNet将两个3×3卷积核的卷积层代替以往深度学习模型中一个5×5卷积核的卷积层,全部使用3×3小卷积核来加深网络的深度,但VGGNet含有3个全连接层,参数量极大,耗费更多计算资源[16]。GoogLeNet参考VGGNet使用多个小卷积核替代大卷积核的方法,通过引入Inception模块,使用多个尺度的卷积核提取特征,同时采用批量归一化的方法,使模型更加轻量化,但存在计算次数太多,效率不足的问题[17]。ResNet在VGGNet的基础上引入跨层连接,使用残差模块构造更加复杂的网络,由于使用全局平均池化操作而不是全连接层,所以ResNet模型的参数更少,但传统ResNet面向上千种分类,训练小样本时,存在冗余参数,降低训练与识别速度。ResNeXt结合GoogLeNet的Inception模块和ResNet残差结构的优点,但模型参数仍有待优化。文中提出改进的ResNeXt-50网络结构,将主干网络上的7×7卷积核用3个3×3卷积核替代,将原始模型架构中7×7的全局平均池化层替换成2个步长为2的3×3卷积核,并采用批量归一化处理,不仅提高了模型精度,而且极大地减少了网络计算成本。综合考虑硬件性能和训练时间,经多次调试后,Batchsize设置为32,采用Adam优化器进行模型训练优化,初始学习率设置为0.001。经100轮训练后,各模型的识别准确率与损失函数曲线如图5所示。

图5 不同模型在测试集上的准确率和损失曲线
由图5可知,同等试验条件下,VGG-19、GoogLeNet Inception v2、ResNet-50和ResNeXt-50 4种深度学习模型对于干制哈密大枣果梗/花萼及缺陷数据集的识别能力相差不大,在模型训练初始阶段准确率均能达到60%以上,且均取得了较低的损失值,但难以收敛。文中提出的X-ResNext-50相比其他网络,当迭代次数为20时,准确率第一次达到90%以上,且在准确率与收敛方面均有一定的提升。使用图像感兴趣区域提取后,模型的表现能力得到了较大提升,在训练初始阶段基本可保持准确率在80%以上,表明感兴趣区域提取有利于网络更好地提取一些有效特征,并帮助模型更快收敛。
4.2 基于迁移学习的模型性能对比
由于迁移学习加载了预训练模型,模型在训练的初始阶段就可以获取较好的训练参数,因此模型能更快收敛。迁移学习模型TL-ROI-X-ResNeXt-50与ROI-X-ResNeXt-50模型的准确率与损失曲线如图6所示,迁移学习对于网络模型收敛有极大的促进作用,模型在训练初始阶段就已迅速收敛,且有着较低的损失值和较高的准确率,在第5次迭代后,模型的准确率基本与ROI-X-ResNeXt-50模型收敛时相同,且损失值更低,表明TL-ROI-X-ResNeXt-50模型可以较好地识别干制哈密大枣果梗/花萼及缺陷。

图6 不同模型在测试集上的准确率与损失曲线
4.3 模型验证
为验证模型的实用性,结合维视图像试验装置开发了一款干制哈密大枣果梗/花萼及缺陷检测系统进行实验验证。系统界面如图7所示,后台处理通过编写Python语言调用OpenCV打开相机,并通过光电传感器控制相机拍摄获取图像,调用Pytorch深度学习框架实现干制哈密大枣果梗/花萼及缺陷识别。通过实时采集图像进行实验验证,正常、果梗/花萼及缺陷样本分别随机挑选40个进行检测。

图7 系统界面
经测试,120个干制哈密大枣样本中,检测正确样本数为113个,识别准确率为94.17%,干制哈密大枣果梗/花萼及缺陷系统验证的混淆矩阵结果如图8所示。由图8 可知,40个果梗/花萼样本中6个被误判为缺陷类别,1个被误判为正常类别,表明果梗/花萼的特征与缺陷特征确实容易混淆,果梗/花萼容易被误识别为缺陷枣;此外,40个正常与缺陷样本全部判断正确,较好地避免了缺陷枣果被误判为正常枣果的危害,表明改进的网络结构能够较好地识别干制哈密大枣缺陷特征。综上,文中建立的检测系统可以实现干制哈密大枣果梗/花萼及缺陷判别。
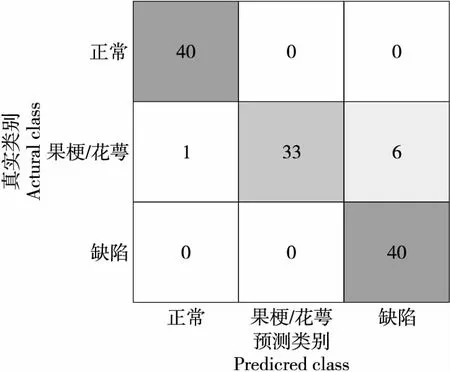
图8 混淆矩阵
5 结论
在改进ResNeXt-50深度学习模型基础上,采用感兴趣区域提取方法和迁移学习技术提出了一种TL-ROI-X-ResNeXt-50分类模型,实现了干制哈密大枣果梗/花萼及缺陷分类。结果表明,改进的X-ResNeXt-50网络结构可以减少模型计算成本,促进模型收敛。感兴趣区域提取方法和迁移学习技术有助于模型更快地学习一些有用的特征,提高准确率并加速网络模型收敛。为验证检测模型的实用性,结合维视图像装置开发了干制哈密大枣果梗/花萼及缺陷检测系统,其识别准确率可达94.17%,初步满足干制哈密大枣果梗/花萼及缺陷在线检测装备的生产需求,后续可以考虑在深度学习网络模型中加入图像感兴趣区域提取预处理模块,提高检测效率。
