深度卷积神经网络的柔性剪枝策略
2022-02-12陈靓钱亚冠何志强关晓惠王滨王星
陈靓,钱亚冠,何志强,关晓惠,王滨,王星
研究与开发
深度卷积神经网络的柔性剪枝策略
陈靓1,2,钱亚冠1,2,何志强1,2,关晓惠3,王滨4,王星4
(1. 浙江科技学院理学院/大数据学院,浙江 杭州 310023;2. 海康威视−浙江科技学院边缘智能安全联合实验室,浙江 杭州 310023; 3. 浙江水利水电学院信息工程与艺术设计学院,浙江 杭州 310023;4. 浙江大学电气工程学院,浙江 杭州 310063)
尽管深度卷积神经网络在多种应用中取得了极大的成功,但其结构的冗余性导致模型过大的存储容量和过高的计算代价,难以部署到资源受限的边缘设备中。网络剪枝是消除网络冗余的一种有效途径,为了找到在有限资源下最佳的神经网络模型架构,提出了一种高效的柔性剪枝策略。一方面,通过计算通道贡献量,兼顾通道缩放系数的分布情况;另一方面,通过对剪枝结果的合理估计及预先模拟,提高剪枝过程的效率。基于VGG16与ResNet56在CIFAR-10的实验结果表明,柔性剪枝策略分别降低了71.3%和54.3%的浮点运算量,而准确率仅分别下降0.15个百分点和0.20个百分点。
卷积神经网络;网络剪枝;缩放系数;通道贡献量
0 引言
从最初的8层AlexNet[1],到上百层的ResNet[2],深度学习技术的发展得益于日益加深的网络结构,但同时受其制约。一个152层的ResNet有超过6 000万个参数,在推断分辨率为224dpi×224 dpi的图像时需要超过200亿次浮点运算(floating point operation,FLOP)。尽管这在拥有大量高性能GPU的云平台上不成问题,但对于移动设备、可穿戴设备或物联网设备等资源受限的平台是无法承受的。然而,集中化的云端推理服务存在带宽资源消耗大、图像数据隐私泄密严重、时效性难以保证等问题[3]。因此,如何在边缘端部署深度神经网络模型是解决问题的关键。
为此学术界提出了很多压缩卷积神经网络的方法,包括低秩近似[4]、网络量化[5]和网络剪枝等,其中剪枝技术被证实是一种有效的方法。剪枝方法按照移除的粒度大小可以被分为两大类:权重剪枝和结构化剪枝。权重剪枝[6]也被称作非结构化剪枝,可以剪除网络中的任意连接权重。尽管它具有较高的剪枝率,但稀疏权重矩阵的存储和关联索引需要特定的计算环境,在实际中难以实现硬件加速[7-8]。结构化剪枝[9-12]直接减小权重矩阵的大小,同时保持完整矩阵的形式,因此它可以更好地兼容硬件进行加速,成为目前的主流研究方向。
早期的剪枝方法[12-14]通常根据权重重要性决定哪些通道被剪除,忽略权重重要性之间相互联系,从而容易造成过度剪枝或剪枝不足的问题,导致剪枝后模型性能不可复原地下降。最新的研究通常使用渐进的迭代剪枝方法[15],或将网络结构搜索问题转化为优化问题[16],逐步逼近最佳的网络架构。然而当这些方法应用于大剪枝率时,受到网络稀疏程度的影响,在实际剪枝过程中会带来额外的计算量。
为了能够更高效地剪枝得到最佳的模型结构,本文提出一种柔性剪枝策略。该方法以通道为单位剪枝,首先结合批归一化(batch normalization,BN)层的缩放系数值及其分布情况,计算通道贡献量作为衡量通道重要性的依据,并初步估算每层的剪枝比例。然后通过模拟剪枝调优剪枝策略,以此快速逼近最佳的网络架构。最后根据得到的架构对每一层分别剪枝,获得紧凑的模型。本文提出的剪枝方法,采用全局的结构化剪枝方式,过程中不需要对局部手动调参,剪枝后的模型无须特定的环境支持,是一种高效的模型压缩方法。
1 相关工作
剪枝作为网络压缩的有效方法之一,通过裁剪网络中不重要的权重,在不影响性能的情况下,提升网络运算速度,减少存储容量。早在1989年,LECUN等[17]就指出神经网络中存在大量冗余,删除网络中不重要的权重能够获得更好的泛化能力,消耗更少的训练和推理时间。文献[6]通过修剪网络中的不重要连接,减少网络所需要的参数,减少内存和计算消耗。尽管权重剪枝在降低网络参数上有显著的效果,但会导致模型的非结构化,很难实现硬件加速[7-8]。
为兼容现有的硬件加速,近期的剪枝工作[9-12]集中在结构化剪枝上,通过修剪整个通道或者卷积核以保持结构的规则性,并提出了多种重要性度量标准。文献[9]使用卷积核的L1范数作为重要性度量,计算卷积核中所有权值的绝对值之和,从而规则地删除数值较小的卷积核避免稀疏连接。文献[10]通过计算激活层后神经元中数值为0的比例衡量神经元的重要性。文献[11]根据删除一个通道后对下一层激活值的影响衡量该通道重要性,寻找这一层输入的最优子集代替原来的输入,得到尽可能相似的输出,剪除子集外的通道。文献[12]提出网络瘦身(network slimming,NS)方法,用BN层的缩放系数作为通道重要性的评价标准,根据全局阈值剪除缩放系数小于阈值的通道。
NS方法[12]是一种经典的自动化剪枝方法[18],可以根据整体剪枝率自动地生成剪枝后的网络架构,无须人为设计每层的剪枝比例。文献[19]指出,NS方法中基于预定义的全局阈值(optimal thresholding,OT)的设计忽略了不同层之间的变化和权重分布,并提出一种最优阈值设定策略,根据不同层的权重分布设计各层的最优阈值。文献[20]同样基于NS方法,提出了一种极化正则化器(polarization regularizer,PR),通过调整稀疏化训练的策略,对不同重要性的通道进行区分。
常规的剪枝方法是一个不可逆过程,被剪除的通道或者卷积核不参与后续训练过程,也被称为“剪枝”。文献[21]和文献[15]提出“剪枝”法,在训练期间将被剪除的卷积核参数重置为零,并在后续训练阶段持续更新,以此降低过度剪枝风险。文献[22]在此基础上提出ASRFP方法,渐进地修剪卷积核,使得训练和剪枝过程更加稳定。文献[23]提出BN-SFP方法,根据BN层缩放系数进行软剪枝,实现性能的提升。
最新的研究工作通过自动搜索最优子网络结构实现网络剪枝,文献[24]预先训练大型PruningNet预测剪枝模型的权重,通过一种进化搜索方法搜索性能良好的修剪网络。文献[25]提出了近似的Oracle过滤器剪枝,用二分搜索的方式确定每层的剪枝数。文献[26]基于人工蜂群算法,搜索最优的剪枝架构。
相比于以往的剪枝方法通过去除冗余或者结构搜索的方式,渐进地逼近目标压缩模型,柔性方法的优越性体现在,通过分析模型的权值分布和对目标压缩模型的快速模拟,以少量计算成本获得高性能的压缩模型架构。
2 方法描述
神经网络的前向传播是一个连续过程,剪除其中一部分权重必然对后续的计算产生影响。原先的NS方法中基于预定义全局阈值的设计忽略了权重的关联性。另外,网络架构的改变会对权重的分布产生影响,即当对神经网络模型进行迭代剪枝时,每轮迭代后的模型由于架构发生改变,权重分布也会相应发生变化。当网络架构越接近于最佳的剪枝后架构时,权重分布也越接近。据此本文提出柔性剪枝策略,结合BN层缩放系数的分布情况,构建一个新的通道重要性评价指标——通道贡献量。并提出一种通道等效重组方法,对剪枝后的网络架构进行模拟,获得接近于最佳网络架构的权重分布。
柔性剪枝算法的流程如图1所示,整个流程可以分为获取架构和获取参数两个部分。通过计算通道贡献量、通道等效重组和适配调整缩放系数3个步骤获取压缩模型的架构,即剪枝后模型各层剩余的通道数。然后以此进行硬剪枝,微调获取压缩模型参数。其中,通道贡献量的计算包括阈值函数平滑和位序相关性加权两步,本文将在下面详细地阐述实施细节。需要指出的是,本文提出的柔性剪枝在模拟训练过程中提供了更多的网络架构调整机会,有效地避免一次性剪枝带来的过度剪枝问题。

图1 柔性剪枝的流程
2.1 阈值函数平滑


由于缩放系数局限于反映单个通道的重要性,因此在缩放系数的基础上提出通道贡献量,以便于扩展到对整个层的度量。通道贡献量的设计初衷是用于抑制通道的输出,实现模拟剪枝。NS方法根据全局阈值,剪除缩放系数小于全局阈值的通道,保留缩放系数大于全局阈值的通道。其剪枝过程可以视为将通道输出乘以一个关于缩放系数的阈值函数,类似于阶跃函数,即缩放系数小于阈值的通道输出乘以0,缩放系数大于阈值的通道输出乘以1。然而这会造成被剪除部分信息不可恢复的损失,并且无法体现不同通道的重要性差异,因此为便于对剪枝后架构的模拟,将其改造成平滑度可控的函数。
首先,根据通道缩放系数的大小,设计一个平滑函数:

图2 不同平滑系数下的平滑函数

2.2 位序相关性加权

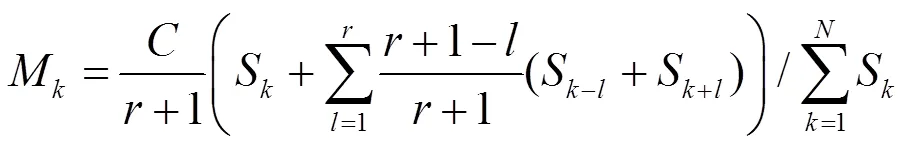
其中,表示在加权过程中使用了当前通道位序前后项的值,体现了序列中的相邻通道对于当前通道贡献量的影响程度。
2.3 通道等效重组



使用通道贡献量对初始模型进行等效重组的过程,可以视作一种模拟剪枝方法,此时虽然保留了模型所有信息的完整,但是各层的输出近似于被剪枝之后的输出。

图4 通道等效重组的过程示意图
2.4 缩放系数的适配调整


2.5 微调
通过上述步骤,能够获取目标剪枝率下压缩模型的架构。根据各层的剩余通道数,分别进行硬剪枝,根据此时各通道通过式(5)得到的缩放系数大小,剪除数值较低的部分通道。由于柔性剪枝是一步式的剪枝方法,因此最后的训练过程根据剪枝率的大小,提供两种方案。当剪枝率较小时,对剪枝后的模型微调。当剪枝率较大时,考虑使用压缩模型架构直接从头训练(train from scratch)。
3 实验与分析
本文实验代码采用Pytorch编程框架,所使用的GPU为NVIDIA RTX 2080Ti。本节将结合实验验证深度卷积神经网络柔性剪枝策略的实际性能。
3.1 实验数据与评价指标
实验采用CIFAR-10/100[28]数据集,其被广泛应用于评价网络剪枝方法。CIFAR-10/100数据集都包括50 000个训练数据和10 000个测试数据,每张图像的大小是32 dpi×32 dpi,分别有10个和100个类。按照文献[12]的方法对CIFAR-10/100进行预处理图像。
本文选取经典的VGG[27]和ResNet[2]作为剪枝的预训练网络。这两个网络分别作为无跨层连接和有跨层连接的代表,能够最直观地反映出网络压缩对于一般网络模型的效果。需要指出的是,当对ResNet上的跨层连接进行剪枝时,通过剪枝得到一个钱包型(wallet)[29]的结构会更有利于剪枝后的网络架构。因此,本文设计一种相对保守的剪枝策略:对于跨层连接的通道,以每次跨层连接前后的BN层缩放系数中的最大值作为它的重要性度量,再计算得到跨层连接所需要的通道数。相比于NS剪枝完全不对跨层的通道进行裁剪,通过这一策略能够在最大程度保证剪枝后准确率不会骤降的同时,对跨层连接的通道进行裁剪。
实验主要通过剪枝后模型的准确率、浮点运算量和参数量3个评价指标与其他剪枝方法对比。准确率指的是分类神经网络在测试数据集上的Top-1分类准确率。浮点运算量用于衡量模型的计算复杂度,浮点运算量越低说明模型实际运算所需的计算量越少,模型加速的效果越好。参数量表示模型占用的内存大小量,参数量的减少可以直接体现模型压缩的效果。
3.2 参数设定

稀疏训练:与NS[12]一样,通过对BN层缩放系数施加L1惩罚项进行稀疏化训练。在CIFAR数据集上,对于VGG16选择10−4作为稀疏率,ResNet56则选择10−5。所有其他设置与正常训练保持一致。
3.3 CIFAR10/100上VGG16的剪枝实验
在CIFAR10/100数据集上修剪VGG16的比较结果见表1。为了保证数据的准确性,直接使用文献[19-20, 25]中的实验数据与柔性剪枝方法进行对比。由于NS[12]最先提出使用BN层的缩放系数作为衡量通道重要性的度量,OT[19]、PR[20]是基于NS的最新改进工作,AOFP降低剪枝过程的运算成本,这些都与柔性剪枝有一定关联,因此后续实验主要与这些工作进行比较。首先修剪VGG16模型使其减少与PR方法相当的浮点运算量,实验结果显示在CIFAR10/100数据集上,柔性剪枝方法在浮点运算量较基线模型分别降低55%和45%时,准确率为94.04%和74.33%,分别比PR提高0.12%和0.08%,比OT提高0.17%和0.71%。其中在CIFAR10数据集上,柔性剪枝比AOFP多减少14%的浮点运算量,但准确度基本一致。

表1 在CIFAR10/100数据集上修剪VGG16的比较结果
大剪枝率下CIFAR10数据集上修剪VGG16的比较结果见表2。为公平地比较压缩模型网络架构的性能,分别使用文献[18]提出的两种训练方法Scratch-E、Scratch-B对各网络架构进行从头训练。其中,Scratch-E表示使用与预训练相同的160个训练轮次,Scratch-B则使用相同计算预算,如剪枝后的网络比初始模式减少了一半的浮点运算量,则用两倍的训练轮次。表2中依次展示通道剪枝率为74%、76%、80%和86%时柔性剪枝后压缩模型的网络架构。与OT相比,当剪枝率相同时,柔性剪枝方法(剪枝率74%)得到的架构准确率更高,但浮点运算量更大。而当浮点运算量相当时,柔性剪枝方法(剪枝率76%)与OT[19]的结果准确率非常接近。从架构上看,柔性剪枝方法(剪枝率76%)与OT在前6层的通道数非常接近,每层的通道数差别都在10以内,而在后面几层,柔性剪枝方法则保留了更少的通道。RBP[30]是一种在贝叶斯框架下的层递归贝叶斯剪枝方法,与其相比,在相同的浮点运算量下,柔性剪枝方法(剪枝率80%)在两种训练方法下的准确率比RBP分别提高了0.49%和0.53%。在相同的剪枝率下,柔性剪枝方法(剪枝率86%)虽然在Scratch-E训练下的准确率比RBP降低了0.51%,但在Scratch-B训练下的准确率提高了0.17%。其主要原因是柔性剪枝方法(剪枝率86%)得到的架构浮点运算量太低,只有RBP架构的一半。实验结果表明,在大剪枝率下,柔性剪枝方法得到的网络架构性能超过了一些当下最新的剪枝方法。

表2 大剪枝率下CIFAR10数据集上修剪VGG16的比较结果
3.4 CIFAR10/100上ResNet56的剪枝实验
在CIFAR10/100数据集上修剪ResNet56的比较结果见表3。为了保证数据的准确性,使用文献[12,15,20-21,23,26]中的实验数据与柔性剪枝方法对比,其中,NS[12]、PR[20]、BN-SFP[23]是基于BN层缩放系数的剪枝方法,SFP[21]、BN-SFP、ASFP[15]是软剪枝方法,与柔性剪枝方法存在一定关联。从表3中可以看出,在相同浮点运算量下,柔性剪枝方法在CIFAR10/100数据集上分别比NS[12]提高了0.58%和1.11%,而与PR的方法结果非常接近,仅提高了0.02%和0.08%。与软剪枝方法对比中,柔性剪枝具有一定优势,在CIFAR10数据集上的准确率分别比SFP、BN-SFP、ASFP提高了0.25%、0.31%、0.48%。除此以外,柔性剪枝方法在浮点计算量减少48%时,准确率达到93.85%,优于一些其他最新剪枝ABCPruner[26]、DCP[31]、DeepHoyer[32]、LPEC[33]。

表3 在CIFAR10/100数据集上修剪ResNet56的比较结果
3.5 超参数分析
3.6 迭代训练分析
为了进一步验证柔性剪枝策略的高效性,本节设计实验分析柔性剪枝方法所需的迭代次数以及每次迭代后再训练的轮次对剪枝效果的影响,如图6所示。首先,如图6(a)所示,固定总训练轮次为80轮,分别测试1次、2次、4次迭代,每次迭代后再训练轮次相同。结果显示,迭代次数的增加不会对柔性剪枝的性能产生较大影响。其次,如图6(b)所示,测试更多的总训练轮次是否导致更好的剪枝效果,实验中分别测试80次、160次、240次总训练轮次。结果显示,随着总训练轮次的增加,剪枝性能没有显著提升。通过迭代训练的实验可知,柔性剪枝方法的优越性在于,与传统的迭代剪枝方法不同,柔性剪枝的过程不需要重复“剪枝−再训练”的过程,仅需要消耗较少的运算成本,获得高性能的压缩模型架构。
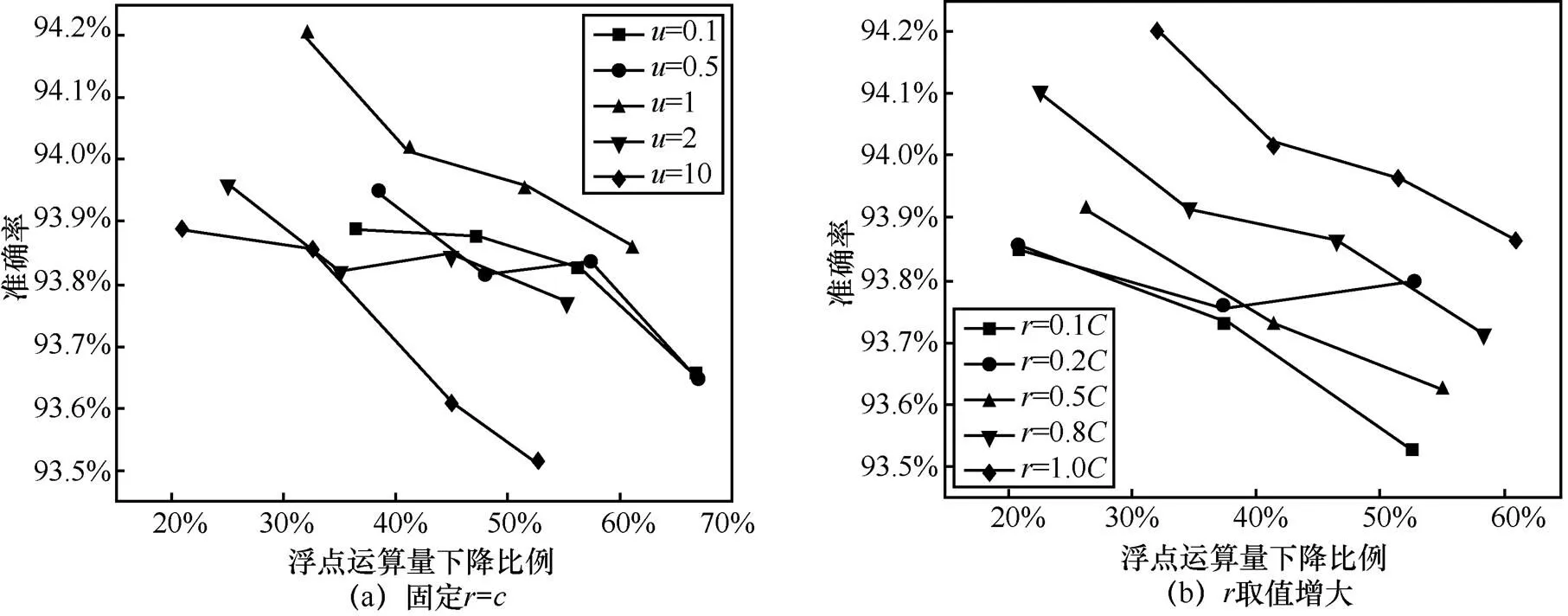
图5 超参数对剪枝的影响

图6 迭代训练对剪枝的影响
3.7 重构实验分析
柔性剪枝方法不仅适用于网络压缩,同时还可以在浮点运算量相同的条件下,对原网络重构,提高分类准确率。具体地,通过先将原网络架构等比例放大,再对其进行剪枝,从而获得与原网络浮点运算量相同的网络架构,并使得其中一些层的通道数多于原网络中该层的通道数。以此在不减少网络计算的同时调整其各层的通道数,获得更高的准确率。在CIFAR10/100数据集上重构VGG16、ResNet56的效果见表4,对VGG16和ResNet56进行重构后,再重新训练得到的准确率提升。结果显示,相比原始网络架构,在同等的浮点运算量下,柔性剪枝方法重构的VGG16准确率分别提升超过0.32%和0.37%,重构的ResNet56准确率分别提升超过0.24%和0.23%。通过重构实验说明,人工预定义的网络架构对于特定的分类任务往往不是最优的,通过剪枝的方法可以获得同等浮点运算量下准确率更高的架构。

表4 在CIFAR10/100数据集上重构VGG16、ResNet56的效果
4 结束语
本文提出了一种柔性剪枝策略,一方面,结合神经网络模型中的权重分布情况,设计了通道贡献量作为通道重要性评价指标,以层的视角宏观地设计整层的剪枝方案;另一方面,创造性地提出了一种模拟剪枝方案,使用较少的计算消耗获取高性能的网络架构。在公开数据集上的对比实验表明,柔性剪枝后模型架构的性能优于其他最新的剪枝方法,是一种非常高效的剪枝方法。在后续的工作中,将进一步测试在跨层连接上的剪枝策略,以及将柔性剪枝策略应用于其他最新的轻量级网络。
[1] KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks[J]. Communications of the ACM, 2017, 60(6): 84-90.
[2] HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE Press, 2016: 770-778.
[3] 唐博恒, 柴鑫刚. 基于云边协同的计算机视觉推理机制[J]. 电信科学, 2021, 37(5): 72-81.
TANG B H, CHAI X G. Cloud-edge collaboration based computer vision inference mechanism[J]. Telecommunications Science, 2021, 37(5): 72-81.
[4] WANG Y, BIAN Z P, HOU J H, et al. Convolutional neural networks with dynamic regularization[EB]. 2019.
[5] COURBARIAUX M, BENGIO Y, DAVID J P. Binary Connect: training deep neural networks with binary weights during propagations[J]. CoRR, 2015.
[6] HAN S, POOL J, TRAN J, et al. Learning both weights and connections for efficient neural networks[J]. CoRR, 2015.
[7] WEN W J, YANG F, SU Y F, et al. Learning low-rank structured sparsity in recurrent neural networks[C]//Proceedings of 2020 IEEE International Symposium on Circuits and Systems (ISCAS). Piscataway: IEEE Press, 2020: 1-4.
[8] HE Y H, ZHANG X Y, SUN J. Channel pruning for accelerating very deep neural networks[C]//Proceedings of 2017 IEEE International Conference on Computer Vision (ICCV). Piscataway: IEEE Press, 2017: 1398-1406.
[9] LI H, KADAV A, DURDANOVIC I, et al. Pruning filters for efficient ConvNets[EB]. 2016.
[10] HU H Y, PENG R, TAI Y W, et al. Network trimming: a data-driven neuron pruning approach towards efficient deep architectures[EB]. 2016.
[11] LUO J H, WU J X, LIN W Y. ThiNet: a filter level pruning method for deep neural network compression[C]//Proceedings of 2017 IEEE International Conference on Computer Vision (ICCV). Piscataway: IEEE Press, 2017: 5068-5076.
[12] LIU Z, LI J G, SHEN Z Q, et al. Learning efficient convolutional networks through network slimming[C]//Proceedings of 2017 IEEE International Conference on Computer Vision (ICCV). Piscataway: IEEE Press, 2017: 2755-2763.
[13] YE J B, LU X, LIN Z, et al. Rethinking the smaller-norm-less-informative assumption in channel pruning of convolution layers[EB]. 2018.
[14] IOFFE S, SZEGEDY C. Batch normalization: accelerating deep network training by reducing internal covariate shift[J]. CoRR, 2015.
[15] HE Y, DONG X Y, KANG G L, et al. Asymptotic soft filter pruning for deep convolutional neural networks[J]. IEEE Transactions on Cybernetics, 2020, 50(8): 3594-3604.
[16] LIN M B, JI R R, ZHANG Y X, et al. Channel pruning via automatic structure search[C]//Proceedings of Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence. California: International Joint Conferences on Artificial Intelligence Organization, 2020.
[17] LECUN Y, DENKER J S, Solla S A. Optimal brain damage[C]// Proceedings of the Advances in Neural Information Processing Systems. Berlin: Springer, 1989: 598-605.
[18] LIU Z, SUN M J, ZHOU T H, et al. Rethinking the value of network pruning[EB]. 2018.
[19] YE Y, YOU G M, FWU J K, et al. Channel pruning via optimal thresholding[M]//Communications in Computer and Information Science. Cham: Springer International Publishing, 2020: 508-516.
[20] ZHUANG T, ZHANG Z X, HUANG Y H, et al. Neuron-level structured pruning using polarization regularizer[C]// Advances in Neural Information Processing Systems. 2020: 1-13.
[21] RONG J T, YU X Y, ZHANG M Y, et al. Soft Taylor pruning for accelerating deep convolutional neural networks[C]//Proceedings of IECON 2020 The 46th Annual Conference of the IEEE Industrial Electronics Society. Piscataway: IEEE Press, 2020: 5343-5349.
[22] CAI L H, AN Z L, YANG C G, et al. Softer pruning, incremental regularization[C]//Proceedings of 2020 25th International Conference on Pattern Recognition (ICPR). Piscataway: IEEE Press, 2021: 224-230.
[23] XU X Z, CHEN Q M, XIE L, et al. Batch-normalization-based soft filter pruning for deep convolutional neural networks[C]//Proceedings of 2020 16th International Conference on Control, Automation, Robotics and Vision (ICARCV). Piscataway: IEEE Press, 2020: 951-956.
[24] LIU Z C, MU H Y, ZHANG X Y, et al. MetaPruning: meta learning for automatic neural network channel pruning[C]// Proceedings of 2019 IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway: IEEE Press, 2019: 3295-3304.
[25] DING Y X, ZHAO W G, WANG Z P, et al. Automaticlly learning featurs of android apps using CNN[C]//Proceedings of 2018 International Conference on Machine Learning and Cybernetics (ICMLC). Piscataway: IEEE Press, 2018: 331-336.
[26] LIN M B, JI R R, ZHANG Y X, et al. Channel pruning via automatic structure search[C]//Proceedings of Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence. California: International Joint Conferences on Artificial Intelligence Organization, 2020: 673-679.
[27] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[J]. CoRR, 2014.
[28] KRIZHEVSKY A, HINTON G. Learning multiple layers of features from tiny images[J]. Handbook of Systemic Autoimmune Diseases. 2009,1(4).
[29] LUO J H, WU J X. Neural network pruning with residual-connections and limited-data[C]//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE Press, 2020: 1455-1464.
[30] ZHOU Y F, ZHANG Y, WANG Y F, et al. Accelerate CNN via recursive Bayesian pruning[C]//Proceedings of 2019 IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway: IEEE Press, 2019: 3305-3314.
[31] PENG H Y, WU J X, CHEN S F, et al. Collaborative channel pruning for deep networks[C]//Proceedings of the International Conference on Machine Learning. New York: ACM Press, 2019:5113-5122.
[32] YANG H R, WEN W, LI H. DeepHoyer: learning sparser neural network with differentiable scale-invariant sparsity measures[EB]. 2019.
[33] HE Y, DING Y H, LIU P, et al. Learning filter pruning criteria for deep convolutional neural networks acceleration[C]//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE Press, 2020: 2006-2015.
A flexible pruning on deep convolutional neural networks
CHEN Liang1,2, QIAN Yaguan1,2, HE Zhiqiang1,2, GUAN Xiaohui3, WANG Bin4, WANG Xing4
1. School of Science/School of Big-data Science, Zhejiang University of Science and Technology, Hangzhou 310023, China 2. Hikvision-Zhejiang University of Science and Technology Edge Intelligence Security Lab, Hangzhou 310023, China 3. College of Information Engineering & Art Design, Zhejiang University of Water Resources and Electric Power, Hangzhou 310023, China 4. College of Electrical Engineering, Zhejiang University, Hangzhou 310063, China
Despite the successful application of deep convolutional neural networks, due to the redundancy of its structure, the large memory requirements and the high computing cost lead it hard to be well deployed to the edge devices with limited resources. Network pruning is an effective way to eliminate network redundancy. An efficient flexible pruning strategy was proposed in the purpose of the best architecture under the limited resources. The contribution of channels was calculated considering the distribution of channel scaling factors. Estimating the pruning result and simulating in advance increase efficiency. Experimental results based on VGG16 and ResNet56 on CIFAR-10 show that the flexible pruning reduces FLOPs by 71.3% and 54.3%, respectively, while accuracy by only 0.15 percentage points and 0.20 percentage points compared to the benchmark model.
convolutional neural network, network pruning, scaling factor, channel contribution
TP183
A
10.11959/j.issn.1000−0801.2022004
2021−08−04;
2021−12−13
国家重点研发计划项目(No.2018YFB2100400);国家自然科学基金资助项目(No.61902082)
The National Key Research and Development Program of China (No.2018YFB2100400), The National Natural Science Foundation of China (No.61902082)
陈靓(1995−),男,浙江科技学院硕士生,主要研究方向为网络剪枝。

钱亚冠(1976−),男,博士,浙江科技学院副教授,主要研究方向为深度学习、人工智能安全、大数据处理。
何志强(1996−),男,浙江科技学院硕士生,主要研究方向为网络剪枝。
关晓惠(1977−),女,博士,浙江水利水电学院副教授,主要研究方向为数字图像处理与模式识别。
王滨(1978−),男,博士,浙江大学研究员,主要研究方向为人工智能安全、物联网安全、密码学。
王星(1985−),男,博士,浙江大学在站博士后,主要研究方向为机器学习与物联网安全。
