5个联合诊断模型对非小细胞肺癌诊断价值的比较
2022-02-12陈小红杨渝伟
陈小红 杨渝伟 徐 鹏 阳 伍
电子科技大学医学院附属绵阳医院检验科,四川绵阳 621000
肺癌是严重威胁人类健康的恶性肿瘤,其发病率和死亡率居肿瘤疾病首位[1]。其中,约85%为非小细胞肺癌(non-small cell lung cancer,NSCLC),5年生存率仅18%且晚期或转移性NSCLC 的存活率仅有4%,故早期诊断及治疗至关重要[2]。糖类抗原125(carbohy drate antigen 125,CA125)和神经元特异性烯醇化酶(neuro specific enolase,NSE) 通常被认为是较为特异的肺癌辅助诊断标志物,同时临床发现癌胚抗原(carcino-embryonic antigen,CEA)、甲胎蛋白(alpha fetoprotein,AFP)和糖类抗原199(carbohydrate antigen 199,CA199)也常在肺癌患者中增高,但单项诊断或传统串联/并联诊断模式,预测分析效能均欠佳[3-4]。近年来,多种模式识别技术如人工神经网络(artificial neural network,ANN),决策树,经典判别分析(classical discriminant analysis,CDA)等模型也被用于肺癌的鉴别诊断,为肿瘤诊断提供了新的模式[5-7]。本研究基于血清5 项肿瘤标志物,构建多层感知器-ANN(multiplayer-ANN,MPL-ANN)、径向基函数-ANN(radial basis function-ANN,RBF-ANN)决策树、logistic回归分析和CDA 五种模式,初步探讨不同模式对NSCLC 的诊断和预测价值。
1 资料与方法
1.1 一般资料
回顾性选取2015年1月11日至2019年10月28日电子科技大学医学院附属绵阳医院413 例NSCLC 患者作为肺癌组,其中男279 例,女134 例;平均年龄(66.3±11.6)岁;鳞癌219 例,腺癌186 例,大细胞癌8 例。随机选取同期723 例肺部良性疾病患者为良性组,其中男468 例,女255 例;平均年龄(67.7±12.2)岁;肺结核92 例,肺脓肿69 例,肺炎100 例,间质性肺病82 例,慢性阻塞性肺病169 例,支气管炎211 例。纳入标准:①年龄>18 岁;②原位癌或原发肺部疾病;③未接受任何方式的治疗;④肺癌诊断符合NCCN 之诊疗标准[8],良性疾病诊断符合各类肺病的相关标准[9];⑤肺癌和良性疾病患者均经影像学或病理学确诊。排除标准:①临床资料不完整的患者;②肿瘤发生转移或复发的患者; ③接受放疗或化疗的患者;④合并严重肝、肾或心功能不全的患者。另选取282 例健康体检者为对照组,其中男167 例,女115例;平均年龄(66.3±12.2)岁,对照组血常规检查,肝肾功能和肿瘤标志物检验均未见异常。三组的一般资料比较,差异无统计学意义(P>0.05)。本次试验为回顾性研究,依据《体外诊断试剂临床研究指导原则》规定[10],未提交伦理审查。
1.2 实验方法
空腹静脉采血3~5 ml,以3000 r/min 半径13.5 cm,离心10 min,分离血清检测。5 项肿瘤标志物均采用化学发光法,其中CEA、AFP、CA125 和CA199(Abbott,美国)在雅培i2000 化学发光仪上检测;NSE(Sorin,意大利)在Liaison 化学发光仪上检测。所有检测均在室内质控在控的情况下进行。说明书项目参考范围为:CEA<5.0 ng/ml,AFP<7.29 U/ml,CA125 为<35.0 U/ml,CA199<37.0 U/ml,NSE<13.0 μg/L。
1.3 统计学方法
采用SPSS 19.0 统计学软件进行数据分析,并建立MPL-ANN、RBF-ANN、决 策 树、logistic 回 归 和CDA 模型。对于符合正态分布的计量资料,用均数±标准差(±s)表示,多组间比较采用单因素方差分析。对于不符合正态分布的资料,用中位数(下四分位数,上四分位数)[M(P25,P75)]进行描述,多组间差异分析采用Kruskal-Wallis 检验,多重比较采用Kruskal-Wallis 检验事后平均秩检验,以校正P 值(Adj.P)作为显著性水平判断依据。训练集和测试集间率的比较,采用χ2检验。各指标及模型的诊断效能采用ROC 曲线分析,以AUC 及最大约登指数下的灵敏度和特异度综合判断,以P<0.05 为差异有统计学意义。
2 结果
2.1 血清肿瘤标志物的诊断效能比较
5 项肿瘤标志物中,CEA 对肺癌的诊断效能最高,其AUC 为0.76,95%CI 为0.74~0.78,灵敏度为64.9%,特异度为89.7%(表1)。

表1 血清CEA、AFP、CA125、CA199 和NSE 的ROC 曲线比较
2.2 基于血清5 项肿瘤标志物的MPL-ANN 和RBF-ANN 模型分析
随机抽取70%样本建立诊断模型(训练集),30%样本进行预测分析(测试集)。MPL-ANN 模型的最佳层数为3 层,RBP-ANN 模型的最佳隐含层数为10层,二者的训练集和测试集中,其错误预测率及对肺癌和非肺癌患者的诊断正确率比较,差异均无统计学意义(P>0.05)(表2)。进一步经ROC 分析(图1),MPL-ANN 模型的AUC、灵敏度和特异度分别为0.91(95%CI:0.89~0.93),75.3%和91.1%;RBF-ANN 模型的AUC、灵敏度和特异度分别为0.86(95%CI:0.82~0.88),75.0%和87.3%。
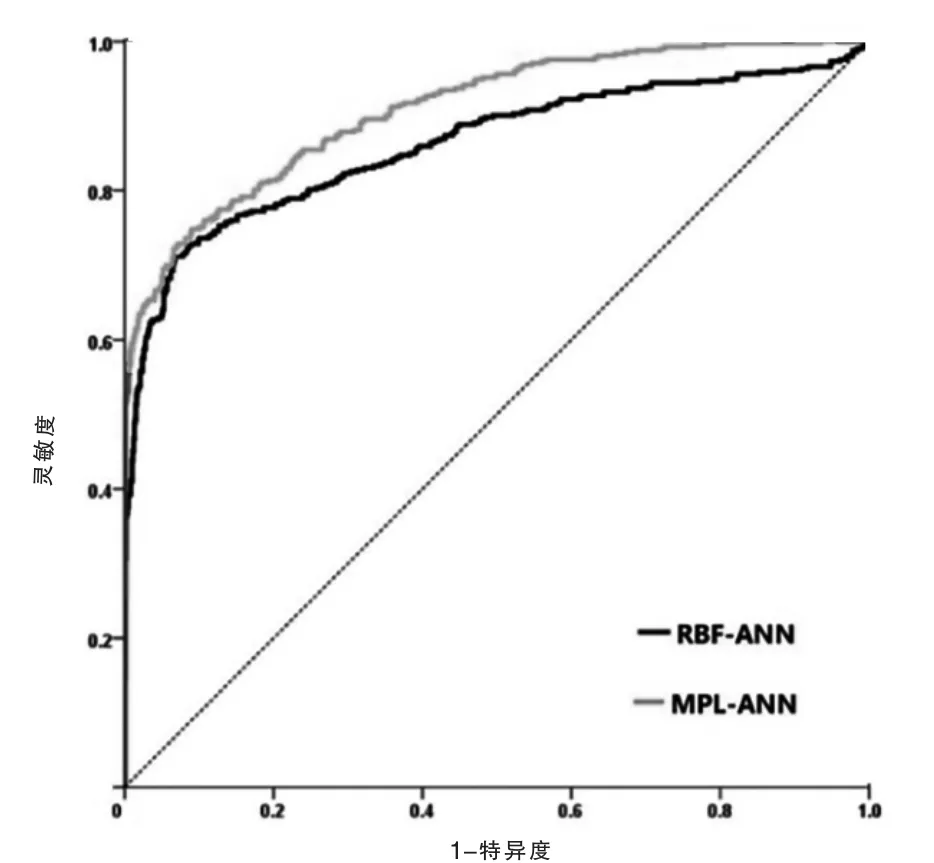
图1 基于血清5 种肿瘤标志物的MPL-ANN 和RBF-ANN 模型的ROC 曲线分析

表2 MPL-ANN 和RBF-ANN 模型中训练集和测试集的差异分析
2.3 基于血清5 项肿瘤标志物的决策树分析
同样随机选取70%样本为训练集,30%样本为测试集,预测模型如图2。在训练集和测试集中,该模型对肺癌组的诊断正确率分别为64.8%和63.4%(χ2=0.075,P=0.784),对非肺癌组的预测正确率分别为91.7%和92.8%(χ2=0.356,P=0.551)。进一步经ROC分析,该模型的AUC、灵敏度和特异度分别为0.82(95%CI:0.80~0.85)、54.5%和91.8%。

图2 基于血清CEA、AFP、CA125、CA199 和NSE 的决策树-预测模型
2.4 基于血清5 项肿瘤标志物的logistic 回归模型分析
logistic 回归模型为X=0.210×lnCEA+0.073×lnAFP+0.007×lnCA125+0.018×lnCA199+0.06×lnNSE-3.62。其对肺癌组和非肺癌组的预测总正确率分别为96.4%(969/1005)、65.1%(269/413)。进一步经ROC 分析,logistic 回归模型的AUC、灵敏度和特异度分别为0.90(95%CI=0.88~0.92)、74.6%和90.0%。
2.5 基于血清5 项肿瘤标志物的CDA 模型分析
联合五项标志物建立CDA 模型方程为:Y肺癌=0.068×CEA+0.028×AFP+0.008×CA125+0.006×CA199+0.125×NSE-3.130。其对肺癌组和非肺癌组的预测总正确率分别为97.1%(976/1005)、58.1%(240/413)。进一步经ROC 分析,CDA 模型的AUC、灵敏度和特异度分别为0.89(95%CI:0.88~0.81)、74.8%和88.9%。
2.6 基于血清CEA、AFP、CA125、CA199 和NSE 的5 种模型比较
5 种模型AUC 由高到低依次为MPL-ANN 模型(0.91)>logistic 回归分析(0.90)>CDA 模型(0.89)>RBFANN 模型(0.86)>决策树模型(0.82)。MPL-ANN 模型鉴别诊断肺癌的灵敏度为75.3%,特异度为91.1%,该模型对肺癌组和非肺癌组的鉴别诊断正确率分别为67.8%和95.8%(表3)。

表3 基于血清CEA、AFP、CA125、CA199 和NSE 的5 种模型比较
3 讨论
肿瘤标志物是早期辅助诊断肺癌的有效手段,具有简单、快速、微创等优点。CEA 最常用于NSCLC 的筛查,以及预测NSCLC 患者生存状况[11]。CA125、CA199与NSCLC 的治疗效果和预后密切相关[12]。AFP 有助于肺癌的病理分型[13]。此外,NSE 水平增高也预示NSCLC 的转移或预后不良[14]。本研究中,肺癌组患者血清CEA、NSE 和CA125 水平均显著高于良性组和对照组,有助于肺癌的鉴别诊断。五项标志物的诊断效能均较低(AUC<0.90),故需联合检测以提高诊断效能。
与传统的串联或并联模型相比,MPL-ANN、RBF-ANN、决策树和CDA 模型是常用的、带有监督功能的、能够进行多维数据分析的模式识别技术,可避免单一指标对临床的误导,结论更科学、合理[15],从而解决精准医学在肺癌诊断中遇到的问题[16]。相对于
单层感知器,MPL-ANN 和RBF-ANN 能更好地处理非线性分类问题,在肺癌的鉴别诊断中具有一定的应用潜力。Hanai 等[17]采用年龄、性别、是否吸烟指数、肿瘤大小等指标构建MPL-ANN 模型,该模型能实现83%的NSCLC 患者生存期的精准预测。目前有关MPL-ANN 和RBF-ANN 模型的报道显示,能对80.7%和82.3%的肺癌患者准确诊断和预测分析[18],对肺癌、肺良性疾病和胃肠肿瘤具有较好地鉴别能力[19]。本研究中MPL-ANN 对肺癌和非肺癌的诊断准确率分别为67.8%和95.8%,总体结果与以上报道相似。决策树分析、logistic 回归分析和CDA 也常用于多维数据处理和预测分析。尽管文献报道[20],以血清Cyfra21-1、CEA、CA125 及鳞状细胞癌抗原建立的决策树模型,可实现对90.8%~100% NSCLC 患者的鉴别诊断。但是,本研究通过CEA、AFP、CA125、CA199 和NSE 建立的决策树模型,诊断NSCLC 的效果次于MPL-ANN、logistic回归分析、CDA 和RBFANN 模型,可能与本研究纳入的肿瘤标志物的类型和数量有关。
本研究基于肺癌常见标志物(CEA、AFP、CA125、CA199 和NSE)构建了五种数据挖掘模型,其中MPLANN 模型在肺癌的诊断和预测中显示了更优的效果。然而,本研究检测的血清肿瘤标志物的种类有限,对NSCLC 诊断的正确率最高仅有75.3%,还需后续增加更多指标、增大样本量进行模型优化和验证。另外,本研究中研究对象主要为NSCLC 患者,其结论是否适用于其它肿瘤,尚需进一步进行对比研究,以使结论更加科学、合理。
综上所述,联合多个肿瘤标志物的数据挖掘模型,有利于提高临床对NSCLC 的诊断能力。相比而言,非线性MPL-ANN 模型,可能更加适用于NSCLC患者肿瘤标志物的数据挖掘。
