基于可扩展外部知识的分词模型研究*
2022-02-12陈世友
王 泽 陈世友
(中国船舶集团有限公司第七〇九研究所 武汉 430205)
1 引言
当前,无人作战平台已经普遍使用,无人化作战形式正在成型。无人平台首先需要接收作战命令,然后理解作战命令要传达的作战意图,最后根据作战意图执行行动。其中无人平台接收的作战命令是一个中文文本,是一个字的序列,中文的书写不像英文的书写,词与词之间没有空格间隔,又因为词是承载语义的基本单位,因此理解作战命令的第一步就是中文分词,中文分词的好坏直接影响作战命令的理解。
目前,中文分词普遍使用的方法有基于规则的方法、基于机器学习的方法和基于深度学习的方法。基于规则的方法准确率高,但是移植性、泛化性差,以及成本昂贵等不足;基于机器学习的具有准确率高,泛化性强,移植性弱等特点,依然需要许多人工特征;基于深度学习的方法不但具有高准确率,而且具有良好的泛化性,最重要的是深度网络具有提取深度特征的优势,减轻了手工构建特征等方面带来的压力。特别是预训练模型使用,使得模型具有较好的移植性,在具体领域的少量有监督语料上微调即可获取优秀的分词结果。
自从C&W提出关于基于序列标注的统一框架[1],将中文分词作为基于字符的序列标注任务并使用基于C&W提出深度学习框架进行中文分词的相关研究越来越多[2~6],通过不断优化编码器,优化表示学习,融入更多特征,使得模型的效率不断提高。例如使用双向长短期记忆网络(Bi-LSTM)编码上下文信息,基于自注意力机制的预训练用于表示学习等。然而,未登录词问题依然是中文分词面临的一个重大问题,例如一个地点名词“无名高地”,如果无法获取词的上下文依赖信息,就无法提供词边界信息,就不能正确分词,很可能就将其划分为“无名”“高地”二词。
字序列是指出现在句子中n-gram,然而并不是所有的字序列可以成为词,只有那些承载一定意义的字序列才是词。词范畴信息是一种上下文信息,用于衡量字序列成为词的程度。邻接变化数是词范畴信息的一种,根据词是具有特定语义的字序列的特点,使用字序列在不同上下文环境中出现的次数衡量字序列是词的程度。因此在大量无监督语料中使用词范畴信息,从而得到相关词范畴词典。若是“无名高地”字序列出现在词典中,说明“无名高地”字序列在语料中的不同上下文环境中多次出现,这样才能被词范畴信息捕捉到,帮助模型识别未登录词。由上述可知,词范畴信息有助于识别未登录词。
同时,近年来在模型中融入外部知识增强模型性能成为一种趋势[7~9],所以在基于深度学习的中文分词模型中融入字序列的词范畴信息无疑可以有效提高中文分词的未登录词召回率。Tian等使用键值记忆网络融入字序列的词范畴信息进行中文分词[10],受到Tian等另一篇文章的启发,双路注意力机制[11]可以克服键值记忆网络忽略键中可能提供的信息,所以本文使用双路注意力机制融入词范畴信息,可以融入更多的词范畴信息。
2 模型介绍
模型的整体架构如图1。图的底部是从一个字序列的词典N,是获取的词范畴信息的结果。图的顶部是基于字符标注的深度模型的骨架,包括编码器、熟双路注意力机制模块、解码器。分词流程如下。
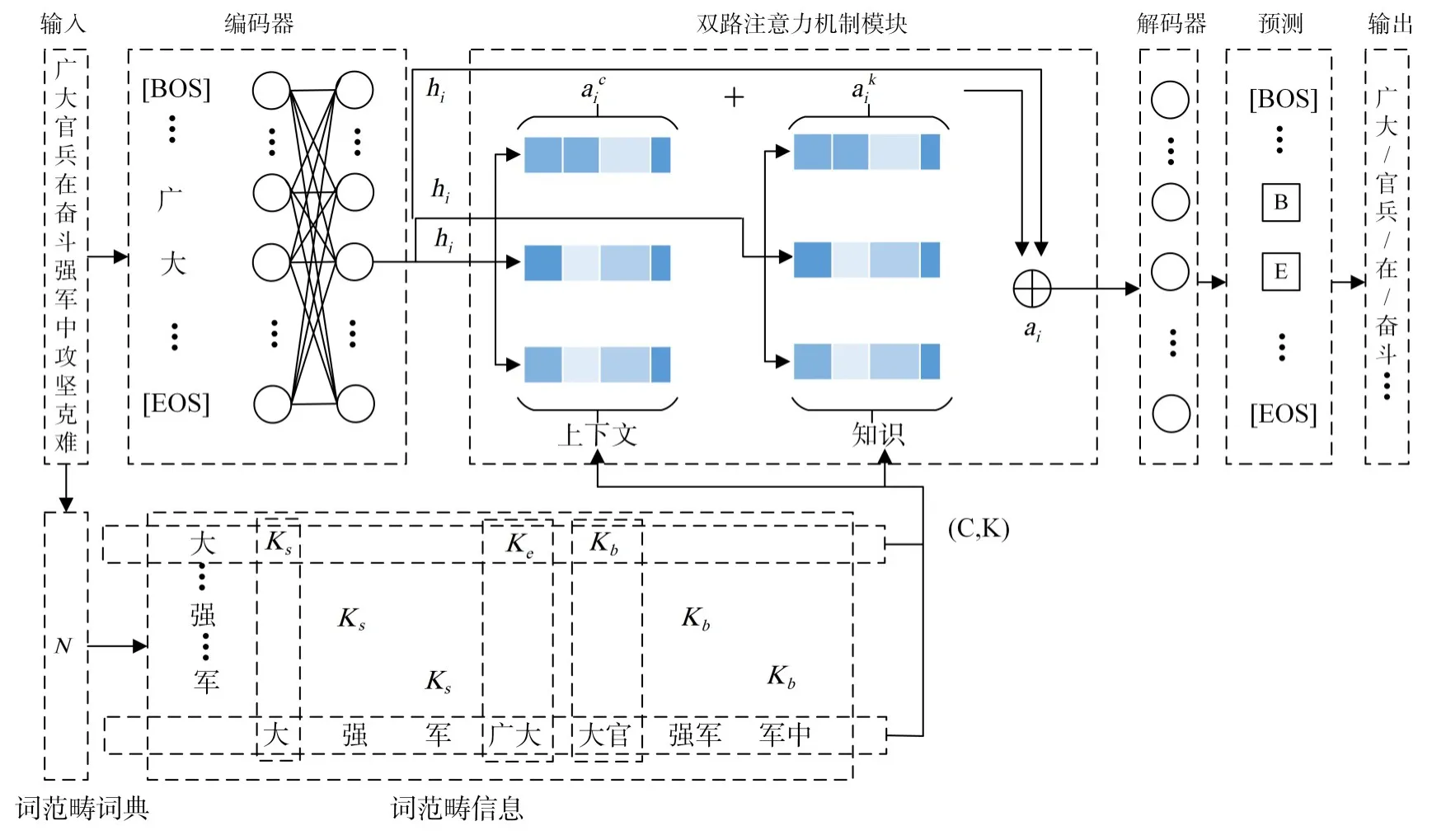
图1 中文分词模型结构图
给定输入的句子:
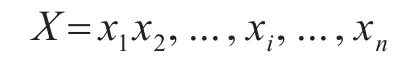
其中xi是每一个字。标记序列表示为
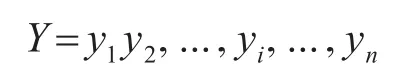
因此,分词模型的条件概率可形式化为
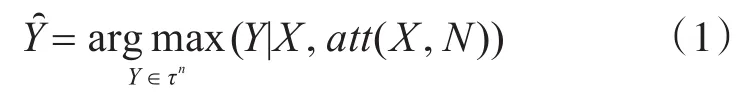
其中Y是标记序列的集合,标记B、I、E、S分别代表字在词的开头、中间、结尾和单字成词等词边界标记。n表示输入句子X的长度。是根据模型选择最可能的序列。att是使用双路注意力机制在模型中融入词范畴信息。最后输出最大概率的标记序列。
在接下来的几小节分别描述模型的每个部分。
2.1 编码器
对于使用深度神经网络进行分词最为基础与重要就是字符级的向量表示,将字符映射成向量的过程称为编码,映射的方法称为编码器。
依据编码的结果,现在广泛使用的编码器可以分为两类,离散型编码器和分布式编码器。离散型编码器定义为生成字符向量的离散表示,分布式编码器定义为生成字符的分布式表示的编码器。离散表示方法是一种简单的表示方法,特点是容易获取,可解释性强,但是无法表示字符间的关系。例如目前被广泛使用的独热编码(One-hot)。分布式表示是一种使用稠密向量表示字符的方法,特点是不易获取,不可解释性强,但是可以建模字符之间的关系。例如目前广泛使用的编码器有Bi-LSTM和BERT。
本文使用BERT[12]作为编码器,将输入的文本序列中的每个字表示成向量:
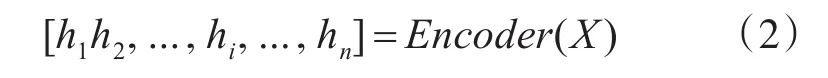
2.2 获取词范畴信息
邻接变化数(Accessor Variety)[13]是一种词范畴信息,在大量无监督语料上统计获取。将AV识别的词作为辅助特征,这样可以从统计上捕获更多的关于词的边界信息,从而进一步提升模型性能。
在一个句子中,以任意两个位置为边界的字序列都可能是一个词,那么那些字序列才是一个真正的词呢?实际上,如上文所述,词作为承载语义的基本单位,即使用特定的字序列表示语义,因此词可以出现在不同的上下文环境中而不会改变词中的字和字顺序,所以可以通过统计字序列的不同上下文环境的数量作为判断字序列是一个词的特征。这个方法就是邻接变化数(AV)。
邻接变化数可以表征字序列是一个词的程度,如果字序列的邻接变化数越大,那么这个字序列就越可能可能成为一个词,换句话说,即一个特定的字序列在按不同的上下文环境出现的次数越多,那么这个字序列就可能是一个词。据上所述,AV的定义如下:
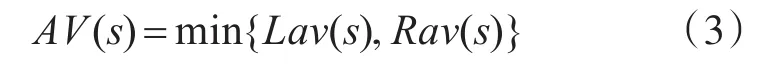
式中,Lav(s)表示字序列s的左邻接变化数,左邻接变化数被定义为字序列s在句子中左侧第一个字符不同的数量的字序列出现在句子首的次数;Rav(s)表示字序列s的右邻接变化数,右邻接变化数被定义为字序列s在句子中右侧第一个字符不同的数量和字序列出现在句子结尾的次数。例如:
1)攻击敌军阵地;
2)突破敌军防线;
3)消灭敌军有生力量。
在这三句话中,“敌军”二字组成的字序列就很大的可能是一个词,“敌军”的左邻接变化数是3,右邻接变化数也是3,所以“敌军”的邻接变化数是3,因此在不同上文中,“敌军”字序列能有效地结合在一起,成为词的可能性就变大了。
2.3 双路注意力机制
注意力机制(Attention)已经被证明在NLP系统中融入外部知识是有效的。键值记忆网络可以将键值对这样成对出现的知识融入到模型中,但是键值记忆网络计算键与隐藏层的注意力分布,并将注意力分布作为值的权重进行求和,这个过程中必然损失键中一些信息。因此本文采用双路注意力机制,使用自注意力机制[14]分别编码在词范畴词典中包含输入中字的所有的字序列以及该字在字序列中的位置,能在模型中融入更多词范畴信息。
例如,输入句子中“攻”字,在词范畴词典中包含该字的序列,如“攻击”字序列,“攻”字该在字序列的开头,我们将这种位置信息称为知识(Knowledge),标记K。知识有下表中的四种。同时将“攻击等出现在词范畴词典中的字序列称为上下文特征C(Context feature)。

表1 知识与标记
对于输入句子中每一个字xi,在输入的句子有包含该字的字序列,若是出现在词范畴词典中,则保留,否则丢弃,那么就可以得到输入句子中每一个字xi的上下文特征集合:

xi是字序列ci,j中的一个字,对应可得到知识集合为
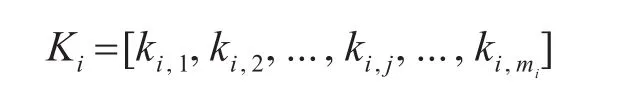
其中元素是四种知识标记的一种。例如“大”字在输入句子中“陆军部队广大官兵在奋斗强军中攻坚克难”中的字序列有{“大”,“广大”,“大官”,“队广大”,“广大官”,“大官兵”},字序列最长长度设为3。假设在构词范畴词典N中有{“大”,“广大”,“大官”},那么“大“”字的上下文特征集合为:

则知识
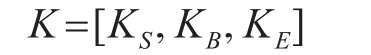
因此,关于上下文特征的自注意力机制可被形式化为
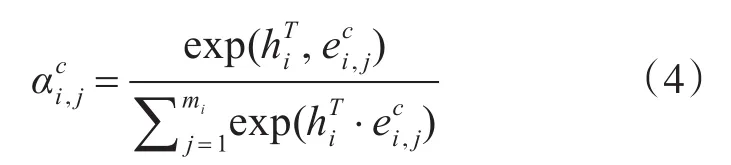
式中hi是编码器将字映射到向量的结果,是词ci,j的词嵌入。然后我们可以获得上下文特征C以自注意力分布为权重的编码:
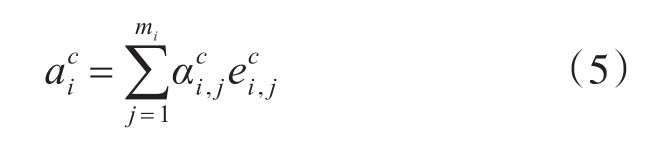
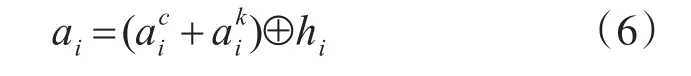
2.4 解码器
与编码器相反,将字向量映射到词边界标记的过程称为解码,映射的方法称为解码器。序列标注实质上是一个多分类任务,因此,一般广泛使用的解码器有条件随机场(CRF)和softmax。
在使用模型为输入句子的每一个字符生成在ai后,模型中解码器以ai为输入生成相应的标记。可形式化如下:

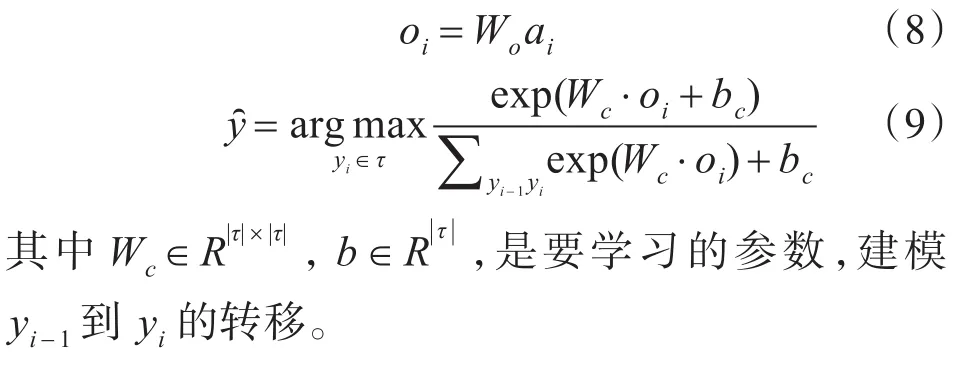
3 实验与分析
3.1 实验设置
论文实现了融入词范畴信息的中文分词模型。在实验中用到的开发工具和环境如表2所示。
表2 实验环境
由于没有领域内关于作战命令的数据集,本文收集了作战命令共计4718句。首先采用ICTCLAS工具进行分词,然后进行人工修正,最后作为中文分词的语料集。在实验当中,选择其中的80%句子作为训练集,20%作为测试集。
实验通过召回率R、精确率P、F值以及未登录词(out-of-vacabulary,OOV)召回率四个指标进行评测。计算法方式如下:

BERT使用Google发布的Chinese base model,12层,768隐藏单元,多头注意力设置成12,共有110M参数。双路注意力机制模块的上下文特征与知识使用768维向量编码,参数随机初始化。解码器需要学习的参数随机初始化。使用负对数似然函数作为损失函数。使用邻接变化数的参数选择长度不超过5个字的字序列,以及邻接变化数的阀门设置为2。批处理大小设置为8,采用adam优化器,在数据集上的学习率设置为0.00001。
3.2 实验结果与分析
实验选取BERT+CRF作为基线,然后使用双路注意力机制(BERT+BW-Attention+CRF)进行分词,最后使用消融的方法研究上下文特征与知识分别对模型的作用,只加入上下文特征(BERT+CW-Attention+CRF)和只加入知识(BERT+KW-Attention+CRF),在分词的过程中使用收集的专有名词词典。
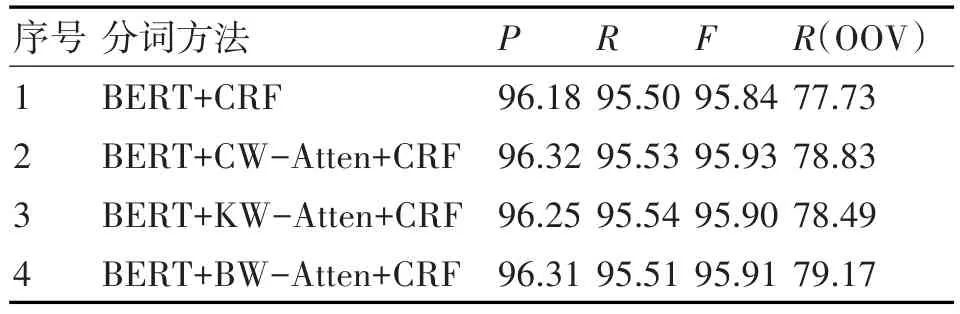
表3 不同模型在语料集上的结果
从实验结果来看,实验1和实验4对比,发现使用双路注意力机制融入词范畴信息对作战文书的分词是有提升效果的,尤其是未登录词的识别,从77.73提升至79.17。相信如果使用大规模数据集,可以捕获更多的词范畴信息,提升效果会更加明显。对比实验1和实验2、3,可以发现分别加入两个因素对分词的提升是由效果的,相对来说,上下文特征加入使得模型的分词的效果增福较大。对比实验2、3和实验4,可以发现实验2的F1要高于实验4,这是因为实验4双路注意力机制的参数偏多,导致过拟合,使得F1稍微下降,换句话说,即是融入词范畴信息过多,稍微影响了F1值。实验4的未登录词的召回率最优,说明模型可以学习到更多的知识,用于未登录词识别。
与使用键值记忆网络融入词范畴信息的模型对比。

表4 键值网络在语料集上的结果
对比实验2、3和实验5,发现实验2、3的F1和Roov值都略低于实验5,这是因为实验2、3只融入了两个因素的单个因素,即是键值网络损失一些信息,但依然可以获得相对单个因素更多信息。而对比实验4和实验5,可以发现实验5的F1高于实验4,这说明名了实验4出现了过拟合,但是,实验5的Roov比实验4的Roov的低,这个充分说明了实验4可以学更多的知识,同时也说明了上文中提到使用键值记忆网络会损失部分信息。
4 结语
本文研究了在作战文书的中文分词任务,构建了中文分词语料集,并实现了使用双路注意力机制融入词范畴信息的中文分词模型。文中使用字序列邻接变化数作为词范畴信息,双路注意力机制使用自注意力分别对上下文特征与词边界知识编码。实验表明,文中提出模型比基线模型在F1值以及未登录词的召回率上都有明显提升,相对于使用键值记忆网络融入词范畴信息的中文分词模型,保持F1基本不变的条件下,提高未登录词的召回率。
从实验中可以发现上下文特与知识对中文分词的效果都有提升的作用,但是提升的效果不同,因此可以研究在模型中以不同程度加入二者带来的提升,例如加入第二层自注意力机制。此外,可以看到军事领域的分词任然存在巨大的挑战,如未登录词的识别,我们还可以从融入不同外部知识提升中文分词模型效果,如向模型中加入如词性标记、句法等先验知识,或者融合基于模板的知识,或者知识图谱来提高中文分词在军事领域的效果。
