基于嵌入式GPU的水声信号处理平台研究
2022-02-12刘建涛张海彬
刘建涛 张海彬
(1.海装沈阳局驻沈阳地区第三军事代表室 沈阳 110003)(2.沈阳辽海装备有限责任公司 沈阳 110003)
1 引言
声纳是海军舰艇的重要装备,而信号处理是声纳装备从海洋干扰背景中提取信息的关键过程。近年来,随着国防发展的需要,对声纳装备的性能要求日益提高。信号处理需要处理的数据量越来越大,算法复杂度越来越高。以DSP芯片为运算核心的第三代信号处理平台在处理大规模数据和更复杂的算法时,不得不使用更多的硬件来弥补运算力的不足,随之而来的则是软件编程的难度进一步提高[1]。
GPU具有大规模并行运算的特点,在处理大量数据的复杂运算时具有速度优势。同时其具有相对DSP更低的功耗和体积。因此,GPU已经成为下一代信号处理平台的主要研究方向[3~4]。
本文通过分析GPU硬件结构,CUDA软件编程模型和并行架构,研究嵌入式微型GPU平台作为水声信号处理系统。该系统体积非常小,作为信号处理设备可以应用于无人艇,UUV,声纳浮标等小型水声探测平台,其运算量也支持其应用于大型声纳系统。科学实验使用该系统替代DSP平台可以节约大量经费,减少负担。该GPU平台也支持数据库和深度学习模块[5~6]。
2 Jetson agx xavier GPU平台
Jetson系列是英伟达开发的微型嵌入式平台,主要应用于移动AI设备,如配送物流自主机器人,UAV,工厂系统等。该平台具有高运算量(每秒32万亿次运算),低功耗(30W),高速I/O性能(750Gbps),体积小(100 mm×105mm)的特点,可以完成如视觉测距、传感器融合、定位与地图绘制、障碍物探测,以及对新一代机器人至关重要的路线规划算法等。
研究在该平台上开发波束形成,目标识别等算法作为信号处理系统,以及嵌入数据库,机器学习模块。对于水声信号处理平台的微型化,数据化,智能化具有重要意义。
2.1 硬件介绍
Jetson agx xavier嵌入式平台硬件配置如表1所示。

表1 Jetson agx xavier硬件配置
该平台CPU采用了8核64位ARM,在保证低功耗的情况下,完全可以满足信号处理程序调度部分需求。GPU主要负责信号处理程序运算部分,深度学习和计算机视觉任务上达到30Tops的运算速度。512核的Volta GPU支持张量核和混合精度计算,能够达到11 TFLOPS FP16或22 TOPS INT8计算。Jetson AGX Xavier的双NVDLA能够实现5TOPS INT8或2.5 TFLOPS FP16性能。内存方面,CPU内存和GPU显存共用32GB LPDDR4,在根本上解决了CPU与GPU的数据传输瓶颈问题,在使用cudaMemcpy进行数据传输时理论速度达到137GB/s,完全满足信号处理需求。功耗方面,该平台功耗最高只有30W,并提供多种模式供设置。在风扇开启的情况下,即便满载运行,设备温度也可以保持在30℃左右,而且噪音相当低,非常适合小型平台或者无人平台。
2.2 Jetson agx xavier和TMS320C6678
TMS320C6678带有四片TI最新KeyStone多核心架构的TMS320C6678型DSP处理器,每片处理器含有8个DSP内核,主频为1GHz,单核峰值浮点运算能力为16GFLOPS,整板峰值浮点运算能力可达512 GFLOPS。模块上每片处理器外接2GB的DDR3,整板外部存储容量为8GB;板内两簇处理器(4片)间可直接进行4×SRIO交换,链路线速率默认3.125Gbps,数据传输不小于800MB/s;板间处理器通信:板卡对外提供2路4×SRIO链路(每簇处理器各占1路),链路线速率默认3.125Gbps,数据传输不小于 800MB/s[9]。
由表2可知,在单精度运算能力上一块Jetson agx xavier的提供的理论运算能力约等于9个整板TMS320C6678。

表2 Jetson agx xavier与TMS320C6678对比
在存储空间上,Jetson agx xavie为编程人员提供了整片32GB的显存,相比于TMS320C6678分配在各个芯片上的模式,在内存分配上更加方便。
在传输速度上,Jetson agx xavier内部137GB/s的传输速度远高于DSP的板内3.125Gbps的速度。
以上可知,在主要硬件指标上,Jetson agx xavier相比于TMS320C6678拥有较大的优势。
3 CUDA编程模型
CUDA是英伟达公司在2006年1月推出的一种通用的编程模型,CUDA是一种将GPU作为数据并行计算设备的软硬件体系。CUDA这种计算模型是以CPU+GPU的一种异构模式来工作的。CPU负责整体程序的串行逻辑控制和任务调度,GPU则用于执行一些能够被高度并行化的并行计算任务[7]。即让GPU与CPU协同工作,更确切的说是CPU控制GPU工作。同时CUDA采用了SIMT(单指令多线程)的执行模型,即成千上万的线程执行同一条指令[8]。
3.1 CUDA存储体系
可编程内存:
寄存器(Regiester):对线程私有,数量有限,线程运行时动态获得。
局部存储器(Local Memory)逻辑上等同于寄存器,但是物理存储空间位于显存中,其访存延迟与全局存储器相当。
共享存储器(Shared Memory)为线程公有内存,一般总大小为64KB。
全局存储器(global memory)可以在任何SM设备上访问到,是GPU中最大,延迟最高,最常使用的内存。
常量内存(const memory)驻留在设备内存中,并在每个SM专用的常量缓存中缓存。
纹理内存,驻留在设备内存中,并在每个SM的只读缓存中缓存。
不可编程内存:一级缓存。二级缓存,只读常量缓存和只读纹理缓存。
每个SM都有一个一级缓存,所有的SM共享一个二级缓存,一级和二级缓存都被用来存储本地内存和全局内存中的数据,也包括寄存器溢出的部分。每个SM也有一个只读常量缓存和只读纹理存缓存,它们用于在设备内存中提高来自内存空间内的读取性能[9~10]。
3.2 CUDA并行架构
CUDA编程模型,包含两个并行逻辑层,分别是block层和thread层,在执行时block映射到SM,thread映射到SP,如何在实际应用程序中高效地开发这两个层次的并行是CUDA编程与优化关键。
CUDA并行基于kernel实现,Kernel函数是指在GPU上执行的函数。在CPU端配置相应的线程块(维度),共享存储容量和CUDA流等信息。
Kernel函数映射到GPU上执行,kernel具有三维的线程网格(grid)-线程块(block)-线程(thread)结构,在执行kernel时,一个kernel函数对应一个grid,对应的block映射到SM,thread映射到SP,GPU通过频繁的线程切换来实现硬件资源的分时使用,切换开销极小[11]。
3.3 频域波束形成算法的并行设计
本部分根据GPU特点和CUDA编程模型设计频域波束形成算法的GPU实现。
CUDA程序并行架构分为三级,分别是数据级并行,核间级并行和任务级并行。数据级并行是指通过线程分配在kernel内部实现数据与数据间的并行。核间级并行是指利用流并发技术实现kernel间的并行。任务级并行是指利用CPU多线程机制实现多个信号处理任务的并行。
软件工程中有自顶向下和自下向上两种设计方法,根据并行架构特点,选择自下向上的设计方式设计声纳信号处理算法。即首先根据信号处理任务相关性,对数据级并行进行设计和优化,再分别处理核间级和任务级并行。如对于频域波束形成算法来说,每个通道的FFT可以设计为一个kernel。多个kernel并行设计为核间级并行。进行优化并单元测试后,多路通道的FFT运行时间极短,因此将FFT与数据与预处理合并为同一任务,在一个CPU线程中运行。对于算法时延补偿部分,数据级并行即为每个基元的通道时延补偿,核间级并行为多个基元并行进行时延补偿。后置处理任务因为时间较短,且分支运算较多,可以布置在CPU上运行。
4 CUDA并行优化
4.1 影响GPU性能的主要因素
1)数据传输
Jetson agx xavier内部137GB/s,可以满足大部分工程要求。但是由于PCIE总线带宽的限制,GPU与CPU,CPU与IO的交互速度都会受到限制,也是GPU延迟的主要因素。
PCIE2.0一般有16通道,每通道速度约为500MB/s,由于数据的额外开销,8GB/s理论带宽能达到6GB/s。如果软件要求在CPU和GPU之间频繁的进行大规模数据交互,会严重影响性能。
2)线程束分化
CPU拥有复杂的硬件执行分支预测以保证分支运算只付出很小的性能代价,但是GPU是相对简单的设备,没有分支预测机制,一个线程束(32线程)中所有线程在同一周期中必须执行相同的指令,因此分支运算会在GPU中产生线程束分化,即一个线程束会执行每一个分支路径。线程束分化会导致性能明显下降,因此在软件编程过程中,需要尽量避免线程束分化[12~13]。
3)bank conflict
共享存储由交替排列的存储体(bank)构成,每个bank大小为4B,如果线程束中多个线程同时访问同一存储体的不同地址将会引发存储体冲突。一般来说共享存储的bank数和线程束内线程数量是一致的[12~13]。
存储体冲突的后果是在GPU中,不同bank组可以同时访存,若产生存储体冲突,多个线程要求访问同一个bank,每次仅有一个线程能访问bank,多个线程间要串行访存,因而导致性能损失。
4.2 提升GPU并行性能的方法
1)页锁定与零拷贝
页锁定内存在内存分配和释放过程中不可换页,因此不会被换除内存空间,换出到虚拟内存中。其传输速度是常规可分页内存的两倍,可以有效提升CPU与GPU的数据交换速度。
利用页锁定原理,将该页面映射到设备地址空间中,实现零拷贝CPU和GPU都可以直接访问内存地址。
2)分支优化
在kernel中,分支操作会产生分支优化,浪费GPU性能,因此采取合理的方式优化分支操作,可以提升kernel性能。
3)高度并行架构设计
一般来说算法并行度越高,性能越好。但是由于CUDA自带的加速库不是针对信号处理算法所设计,因此使用cufft,cublas等加速库并不能有效提升性能。
针对信号处理算法特点自行设计高度并行架构可以有效提升算法性能。
5 试验结果
试验环境:
GPU平台:Jetson agx xavie,Ubuntu 18.04操作系统
CPU:Intel i7-9700k;
DSP平台:TMS320C6678
试验测试不同长度数据的向量乘法,向量加法在CPU和GPU上的运行时间。波束形成和一次积累分别在DSP和GPU上运行时间。

表3 GPU和CPU性能对比
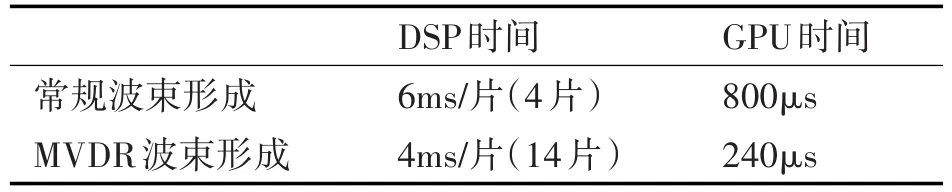
表4 GPU和DSP时间对比
6 结语
Jetson agx xavie相比于DSP信号处理平台在运算速度上具有很大的优势,一个Jetson agx xavie上可以实现多个信号处理板才能实现的信号处理算法。硬件上,在功耗、散热、体积三个指标上,Jetson agx xavie也明显占优。
更重要的是,Jetson agx xavie可内置数据库模块和深度学习模块,对新一代信号处理平台的数据化,智能化具有重要意义,也是后续研究的重要方向。
