基于近红外光谱技术的4种樟属植物识别技术研究
2022-02-09涂白连谢阳志伍艳芳郑永杰刘新亮张月婷徐海宁
涂白连,谢阳志,伍艳芳,,郑永杰,刘新亮,张月婷,徐海宁★
(1.江西农业大学·林学院,江西 南昌 330045;2.江西省林业科学院·国家林业草原樟树工程技术研究中心,江西 南昌 330013)
树种识别技术从来都是林学学科的重点研究内容[1]。传统的树种识别主要依靠树木的形态学特征对其进行准确识别,需具备较为全面的专业知识和经验,并对树木分类学有着很深入的研究和认识[2]。除此之外,细胞学鉴定[3-4]、生物化学鉴定[5-6]、分子标记[7-9]等方法也可用于树种识别。但以上几种方法均存在一些弊端,如识别过程复杂、持续时间长、准确率难以保证等[10],因此多数研究者开始寻求一种更为便捷、快速、准确的树种识别方法——近红外光谱分析技术(NIRS)。
近红外光谱分析技术是一种新型光学检测技术,主要是由分子振动的非谐振性使分子振动从基态向高能级跃迁时产生的,记录的主要是含氢基团X-H(X=C、N、O)振动的倍频和合频吸收[11]。不同基团(如甲基、亚甲基、苯环等)或同一基团在不同化学环境中的近红外吸收波长与强度都有明显差别,NIR光谱具有丰富的结构和组成信息,非常适合用于碳氢有机物质的组成与性质的测量。由于这些含氢基团的吸收特征性强,受分子内外环境的影响小,且光谱特性稳定,获取光谱容易,因此近红外光谱分析技术有着“分析巨人”之美誉[12]。植物鲜叶中的化学成分主要是水分和一些有机成分,化学式主要由C-H、O-H键组成,与近红外光谱分子振动基团相符合。叶片是有机化合物的复杂组合,不同的物种因此会表现出不同的光谱特征,其内部结构和生化组分都会影响其光谱变化。杨玉杰等[13]利用PROSPECT模型[14]来模拟樟树叶片在400~2 500 nm波段内的实测光谱,以分析植物叶片结构和组分对其反射光谱的影响,研究表明,叶绿素主要影响植物叶片反射光谱的可见光波段(400~780 nm),会形成“绿峰”和“红边”两个独特的光谱特征,但不影响近红外和短波近红外波段(780~2 500 nm),这与梁守真等[15]、郭利等[16]、王晶等[17]的研究结果均一致;植物叶片叶肉结构的变化会使叶片在400~2 500 nm全波段范围内的反射率产生变化,但其改变并不会对叶片反射光谱的形状和特征造成影响。因此,近红外光谱分析技术可用于植物种类的鉴别,且目前近红外光谱分析技术在植物种类鉴别方面已开展多项研究[10,18-19]。王逸之等[20]使用便携式光谱仪结合偏最小二乘判别分析法(PLS-DA)对人面竹(Phyllostachys aurea)、矢竹(Pseudosasa japonica)、淡竹(Ph.glauca)、巴山木竹(Bashania fargesii)4个竹种叶片的野外实测光谱建立判别模型,利用所建模型对验证集竹种叶片进行判别,识别率均为100%。汪紫阳等[2]利用PLS-DA结合多列识别变量矩阵对9种树叶建模,识别准确率达到99.58%,进一步显示了利用近红外光谱技术识别树种的可行性。目前,我国利用树种叶片结合近红外光谱分析技术进行树种鉴别的研究并不多[2]。
猴樟(Cinnamomum bodinieri)、黄樟(C.parthenoxylon)、油樟(C.longepaniculatum)、银木(C.septentrionale)均为樟科(Lauraceae)樟属(Cinnamomum)植物,猴樟和银木为我国特有种[21-22],4者皆为集材用、油用、观赏、绿化等多功能于一身的优良树种[23-25]。在形态方面,樟属植物大都极为相似,一般人仅通过比较形态难以正确识别该属植物,需具备一定的专业知识[26-27]。因此,本研究提出利用近红外光谱仪采集猴樟、黄樟、油樟、银木4种樟属植物叶片的光谱信息,结合PCA聚类分析(PCA-Cluster)[28-29]和偏最小二乘判别分析法(PLS-DA),对这4种植物进行判别分析,以期为樟属植物的快速准确识别提供一种新方法。
1 材料与方法
1.1 样品采集与制备
试验所用的样品均来源于江西省林业科学院资源保存基地(28°44'41″N,115°48'46″E)。2021年7月,随机选择猴樟、油樟、黄樟和银木4种植物的多年生成年植株各5株,每单株采集40片树叶,每个树种分别采集得到200片树叶。采摘时选择叶面完整、无虫眼、无破损的当年生成熟期功能叶,采集后的树叶及时带回实验室进行光谱采集。
1.2 近红外光谱采集
光谱采集仪器为瑞士步琦(BUCHI)公司生产的傅立叶变换近红外光谱仪NIRFlex N-500,及配套的Operator光谱采集软件和NIRCal分析软件,仪器光谱范围为4 000~10 000 cm-1,分辨率为8 cm-1。研究表明,树叶表面的灰尘会对光谱采集的反射率产生一定的影响[30-31],因此在进行光谱采集前,需将叶片表面的灰尘擦拭干净,以免其影响模型效果。叶片有腹面和背面,光谱采集时,分别对叶片的腹面和背面进行光谱扫描,每个面取上、中(叶脉主脉上)、下3个部位进行光谱采集。每片树叶得到6条光谱,取这6条光谱的平均光谱作为该叶片的表征光谱。
1.3 样本集的划分
剔除因保存不当等原因造成叶面破损的样品及因操作不当等原因造成的异常光谱,最终扫描得到646条叶片的近红外光谱信息。每个树种随机选取10片叶片作为未知样品,用于模型的外部验证,即外部验证集。余下的样品随机划分至建模集和验证集,其中建模集样品占所有样品的2/3,验证集样品占1/3,验证集样品不参与建模,用于模型的内部验证。样品具体分布情况见表1。
1.4 定性鉴别模型的建立
1.4.1 PCA-Cluster判别模型
该步骤在仪器配套分析软件NIRCal中完成。将采集得到的光谱数据导入配套软件Management console中,对其赋值,赋值后的光谱导入软件NIRCal中进行化学计量学分析。选择NIRCal软件中的聚类分析(Cluster)方法建立模型,主成分分析(PCA)算法将用于该模型的计算。选择不同建模波段、不同预处理条件进行建模,根据模型评价指标属性单一聚类(Cluster per Property)、光谱残差值(Spectra Residual)、属性残差(Property Residual)3个指标和模型对建模集和验证集样品的识别率对模型进行评价[28]。属性单一聚类等于1时,表示每个属性只有一个聚类。光谱残差值等于0时,表示无光谱残差异常值。属性残差指属性原始特性和预测特性之间的差异:其值为0时,表明全部样品的光谱图均被正确识别;其值为+1时,表明该光谱未被识别;其值为-1时,表明该光谱未被正确识别[28,32]。观察比较这3个评价指标,确定最优鉴别模型。

表1 样品信息及样本集划分Tab.1 Sample information and sample set division
1.4.2 PLS-DA判别模型
该步骤在Matlab 2018b软件中完成。PLS-DA是一种用于判别分析的多变量统计分析方法。主要经3个步骤完成:1)建立建模集样本分类变量;2)对分类变量和光谱数据进行PLS分析,建立PLS模型;3)根据建模集样本建立的分类变量和光谱特征的PLS模型,计算验证集样本的分类变量值(Yp),根据Yp判定样本类别,具体判定标准为:①Yp>0.5,偏差<0.5时,样本属于该类;②Yp<0.5,且偏差<0.5时,样本不属于该类;③偏差>0.5时,判别模型不稳定[33-34]。
2 结果与分析
2.1 光谱分析
以1 100 nm(约9 000 cm-1)为分界线,近红外光谱可以划分为短波近红外光谱段和长波近红外光谱段,波长大于1 100 nm的即为长波近红外光谱段[35],本试验光谱仪器所采集的样品光谱范围是4000~10 000 cm-1,属于长波近红外光谱段。长波近红外光谱段主要是含氢基团的一级或二级倍频吸收,常用于分析粉末、固体颗粒、织物等不规则样品,适用于漫反射光谱分析,有利于开展叶片光谱分析[19]。
4个树种树叶的原始光谱如图1所示。总体看,4个树种叶片近红外光谱的整体变化趋势基本相同,但可观察到在4 400~4 800 cm-1、5 400~6 600 cm-1和7 800~10 000 cm-1这3个波段范围内均有较高的反射率,且在4 400~4 800 cm-1、5 400~6 600 cm-1这两个范围内存在明显的波峰,在5 200 cm-1、7 000 cm-1附近有非常明显的波谷。
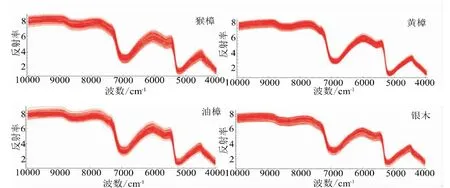
图1 4种樟属植物所有样本原始光谱图Fig.1 Original spectrograms of all samples of four Cinnamomum plants
2.2 主成分分析
以猴樟、黄樟、油樟和银木4种植物的近红外光谱信息为变量,运用PCA方法进行光谱数据降维,让原先多维空间的大部分信息能够由恰当的主成分数组成的二维或三维空间展示出来[28,32]。由图2可知,主成分1(PC1)和主成分2(PC2)分别能解释93.2%和4.4%的信息量,主成分3(PC3)解释1.5%的信息量,前3个主成分的累积能解释99.1%的信息量。观察图2,发现4种植物样品均具有一定的聚集范围,总体看4种植物样品信息均存在重叠部分,尤其在二维空间,这表明在原始光谱上的PCA聚类效果不佳,不能清晰地区别4种植物,需对原始光谱进行预处理,以提高其聚类效果。

图2 4种樟属植物的主成分二维得分图(左)和三维得分图(右)Fig.2 Two-dimensional(left)and Three-dimensional(right)score chart of principal component of four Cinnamomum plants
2.3 PCA-Cluster判别模型的建立与验证
采用NIRCal软件选择不同的预处理方法,对不同的波段范围和主成分数分别建立定性鉴别模型,经过多种建模条件试验,最终建立性能较好6个定性鉴别模型,结果如表2和图3所示。由表2可看出,对于建模集样品,所建模型均能准确识别,但对验证集样品存在一定的误判。对比不同条件下所建模型对于验证集样品的识别率可以得出:在4 400~4 800 cm-1、5 400~6 600 cm-1、7 800~10 000 cm-1波段范围内所建模型的识别率均高于90%,且经ds2(Segment 5 Gap5的3点二阶泰勒求导)预处理后的模型识别率最高,为96.42%。图3是不同条件下所建模型的评价参数属性残差结果图,可看出,编号6条件下所建模型未被识别和未被正确识别的光谱图最少,即该条件下所建的模型鉴定效果最佳。图4和图5分别表示的是编号6条件下所建模型的属性单一聚类值和光谱残差值。

表2 建立4种樟属植物识别模型的条件和对应结果Tab.2 The conditions and results of four species of Cinnamomum recognition model
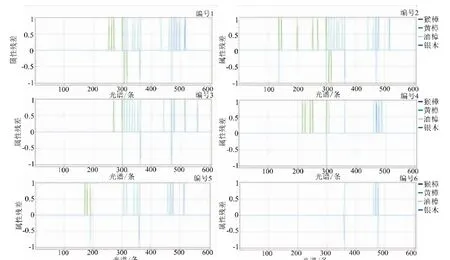
图3 不同条件下所建模型的属性残差值Fig.3 Property residual values of the models under different conditions

图4 属性单一聚类值Fig.4 Cluster per property

图5 光谱残差值Fig.5 Spectra residual
用外部验证集样品对所建模型的实际鉴别能力进行检验,验证结果如表3所示。由表3可知,模型对外部验证集中的猴樟、黄樟、油樟的识别率为100%,均准确识别,仅对银木样品产生了一个错判,未成功识别,总识别率达到97.5%。

表3 外部验证结果Tab.3 External validation results
2.4 PLS-DA判别模型的建立与验证
第一步根据样品的实际类别特征,对建模集样品赋予分类变量值,如表4所示。第二步利用PLS回归方法对校正集样品光谱和样品对应的分类变量值进行回归分析,建立近红外光谱特征和样品分类变量间的PLS回归模型。

表4 4种樟属植物样品的分类变量Tab.4 Category variables of four species of Cinnamomum
对校正集样品进行不同的预处理,并结合PLSDA方法建立判别模型,不同预处理下建立的判别模型的预测效果如表5和图6所示。由表5可知,选择4 000~8 000 cm-1波段,经一阶导数和5点平滑两种预处理方法相结合后所建模型效果最好,即该条件为最佳建模条件,其校正集相关系数最高,为0.9230,内部验证均方根误差最小,为0.1202,对校正集样品识别率为100%。
图6为建模集样品分类变量的PLS预测值和实测值回归图。由图6可看出,分散在参考分类(即实测值)等于1的线上的樟属植物样品点均能和参考分类等于0的线上的其余3个樟属植物明显分开,说明所建模型具有较高的可靠性,能够清晰地区分4种樟属植物。
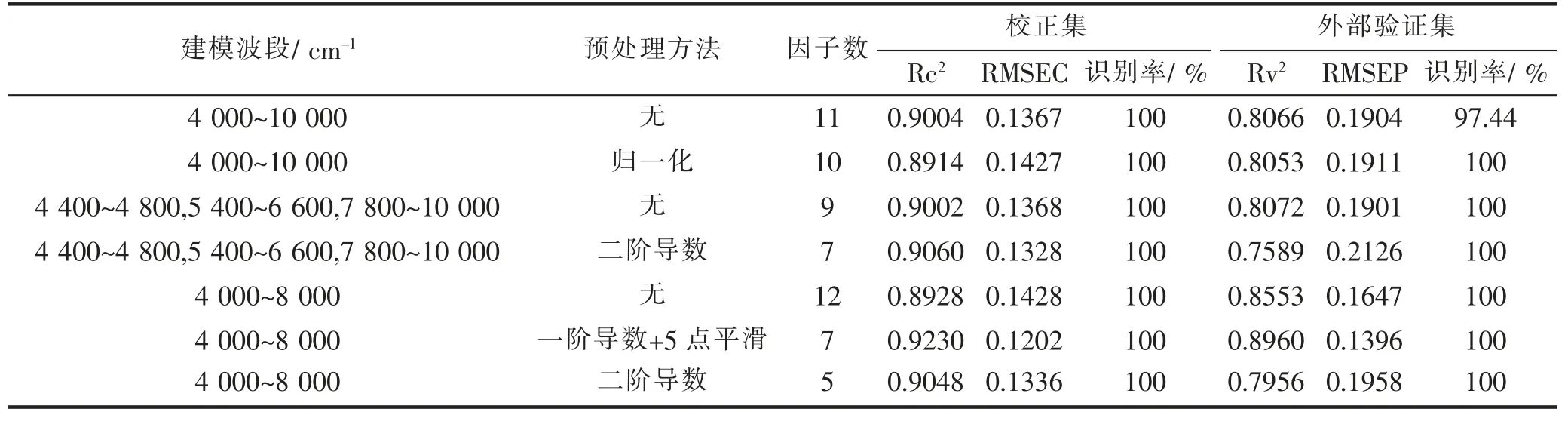
表5 不同光谱预处理下的PLS-DA判别模型预测效果Tab.5 Predictive effect of PLS-DA discrimination model with different preprocessing methods
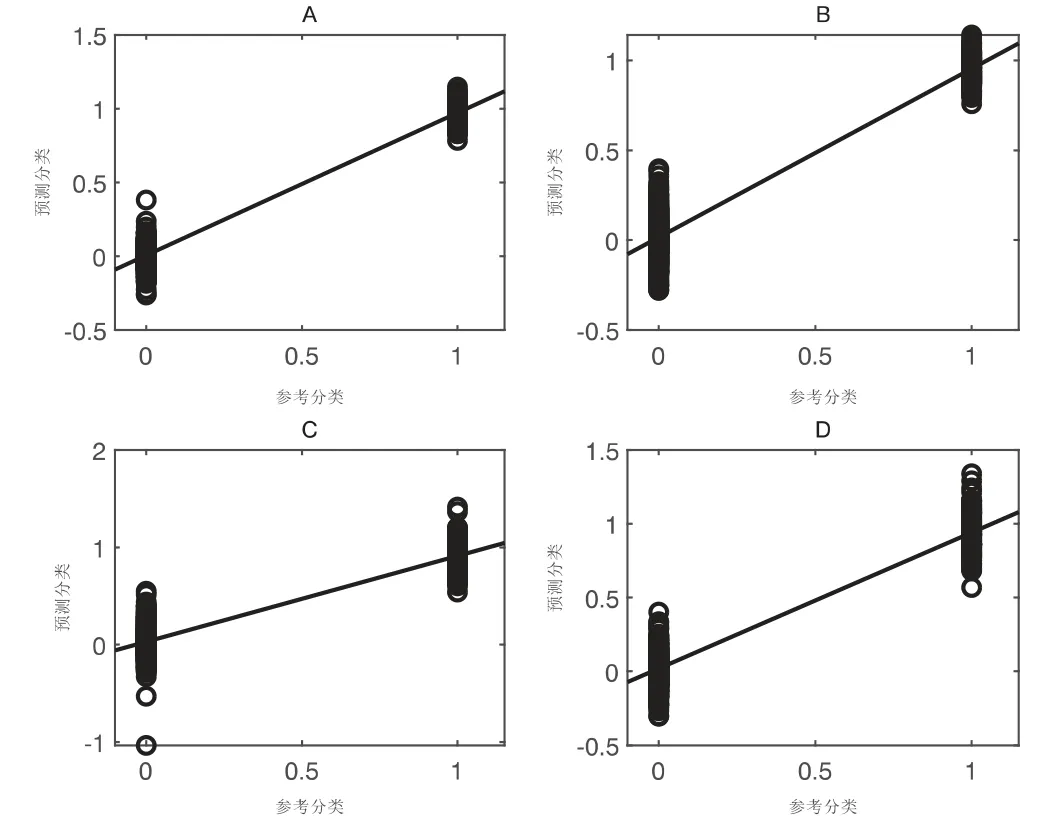
图6 PLS-DA判别模型样品分类变量的PLS预测值和实测值的回归图Fig.6 Regression plots of reference and prediction category variables of sample by PLS-DA model
选择最佳建模条件建立PLS-DA判别模型,利用所建模型对未参与建模的外部验证集样品进行判别分析,结果如图7和表5所示。图7A为验证集中猴樟样品的预测结果,从图中可看出,外部验证集中猴樟所有样品的预测值都在1附近,且偏差较小,而黄樟、油樟和银木三类样品的预测值均在0附近,偏差小于0.5。据1.4.2所述的判别准则可知,模型对猴樟样品的识别率为100%,同理观察图7B、7C、7D可知,模型对验证集中的黄樟、油樟和银木样品均能准确识别。由表5可知,最佳条件下所建模型对外部验证集样品的相关系数最高,为0.8960,预测均方根误差最小,为0.1396,对外部验证集样品的识别率为100%。

图7 外部验证集中4种樟属植物样品的PLS-DA模型判别结果Fig.7 Discriminant results of four species of Cinnamomum in validation set by PLS-DA models
3 结论与讨论
3.1 建模波段的选择
该试验光谱采集的波段范围是4 000~10 000 cm-1,该波段主要是含氢基团(X-H,X=C、N、O等)的倍频和合频吸收带,谱带宽且信息量大。选用全光谱参与建模会在一定程度上影响建模的精确度和准确度[36-39],需要对全光谱波段进行特征波长选择,从中提取包含有意义信息的光谱波段,除去噪声光谱和无意义的光谱波段,提高建模效率和模型精度[40]。孙晓明等[41]选择4 000~10 000 cm-1全光谱波段,建立了水蜜桃(Prunus persica)产地溯源模型;王澄林[28]通过软件优化选择5 000~10 000 cm-1波段成功建立了不同栽培方式金线莲(Anoectochilus roxburghii)鉴别模型,本研究首先运用PCA-Cluster方法建模,经建模软件NIRCal选择不同波段范围,进行多种尝试,通过软件自动优化,结果表明在4 400~4 800 cm-1,5 400~6 600 cm-1,7 800~10 000 cm-1组合波段内建立PCA-Cluster判别模型效果最好。运用PLS-DA方法建模时,同样对不同的波段范围进行建模,结果表明在4 000~8 000 cm-1范围内建立的PLS-DA判别模型性能最佳。由此可得出,最佳建模波段并不是一成不变的,要根据不同的样品和实际情况恰当的选择建模波段,以获得最优模型。
3.2 预处理方法的选择
采集得到的样品光谱包含了大量物理、化学和生物等信息,包含建模所需的相关信息和影响模型精度的无关信息,同时也包括了因光谱仪器、所处环境或操作人员等原因造成的光谱基线偏移、高频噪音等偏差信息,这均会对模型的建立产生影响,增加近红外光谱分析的难度[42-44],因此需要对原始光谱进行预处理。浦宇文等[45]通过先采用标准正态变量变换(SNV)再结合多元散射校正(MSC)预处理的方法建立机采名优茶识别模型,所建模型训练集准确率达98.5%,验证集准确率达98.1%;汪紫阳等[2]使用一阶导数+平滑的预处理方法,使用单列识别变量矩阵的PLS-DA方法建立4个树种的树叶识别模型,模型准确率达100%。本研究中,通过采取不同的预处理方法对光谱数据进行处理,选择ds2(Segment 5 Gap5的3点二阶泰勒求导)结合PCA-Cluster方法建立最优识别模型,对未知样品识别率达96.42%;选择一阶导数+5点平滑预处理方法建立PLS-DA判别模型,模型对未知样品的识别率为100%。
3.3 关于方法改进和模型优化的探讨
近红外光谱分析技术是1980年代以来发展最快、最受关注的一项光谱分析技术,具有强大的分析能力[11],它在植物品种鉴定方面的应用,改善了利用形态学、细胞学等植物鉴别方法的不足之处,提高了植物鉴别的速度和准确度。但近红外光谱分析技术本身存在一定的时限性,样品所处时间和空间的改变可能会对模型的精度和准确度产生一定的影响,因此需要对模型进行不断的维护和扩充[10],确保模型能够更加适用于日常分析工作。本试验用于建模的样品均取自同一地点和时间,在后续的使用中,应当不断的对模型进行升级和优化,收集来自不同地点和时间的样品扩充模型,增加其适应性。除了本文所涉及的4种樟科植物外,笔者对樟科常见种香樟(C.camphora)5种化学型的近红外光谱识别方法也进行了研究(尚未发表),初步建立了近红外光谱识别模型。
应用近红外光谱分析技术结合PCA-Cluster和PLS-DA两种方法对猴樟、黄樟、油樟、银木4种樟属植物叶片光谱建立近红外光谱识别模型,两种方法均成功地建立了判别模型,结果显示所建模型具有较高的识别能力,能够准确识别校正集样品。外部验证方面,PCA-Cluster模型对外部验证集样品的识别率为97.5%,PLS-DA判别模型的识别率为100%,说明应用近红外光谱分析技术能够用于4种樟属植物的识别。这对进一步利用近红外光谱分析技术进行樟科植物的识别研究或者其他树种树叶的识别研究是具有一定的参考价值的。
