基于网络文本挖掘的生态旅游满意度评价研究
2022-02-08孙宝生敖长林王菁霞赵明阳
孙宝生, 敖长林, 王菁霞, 赵明阳
(东北农业大学 管理科学与工程系,黑龙江 哈尔滨 150030)
0 引言
“十二五”以来,我国旅游业持续快速发展,国家旅游局发布的中国旅游业统计公报显示,2018年国内旅游人数达到55.39亿人次,约占全球国内旅游人次(108.2亿)的一半,比去年同期增长10.8%。作为旅游业发展最快的旅游形式之一[1],生态旅游因其具有亲近自然、保护环境的优势逐渐成为人们外出旅游的重要选择[2]。虽然生态旅游比大众旅游更注重对当地自然和文化的保护,但是生态旅游的快速发展不可避免的会给旅游目的地(如自然保护区)的可持续发展带来严峻的挑战[3]。如何保证生态旅游目的地的可持续发展成为亟待解决的现实问题,引起了学者、旅游地管理者和政策制定者的高度关注[4],一个重要的应对措施是对生态旅游地的游客满意度进行评价研究[5,6]。游客满意度作为旅游目的地发展情况的重要标准之一,是衡量旅游地经济与社会效益的综合性指标,对游客满意度进行评价有助于合理配置旅游资源、改善旅游服务质量以及满足游客旅游需求等[7]。因此,评价生态旅游目的地的游客满意度对旅游地健康可持续发展、管理决策以及政策制定具有重要意义。
游客满意度评价研究通常采用传统的定性、定量或混合方法(如问卷调查和焦点小组)确定满意度的维度,并通过Likert测量量表获取样本数据[8]。然而,这些传统方法往往成本高,样本有限,而且来自几个封闭问题的有限信息并不能为更复杂的分析提供丰富的数据[6]。随着Web 2.0技术的快速发展,用户生成内容(user-generated content, UGC)显著增加,作为UGC数据的重要组成部分,在线旅游评论已经被广泛应用于旅游相关行业,例如旅游目的地和酒店业[9]。在线旅游评论具有易获取、范围广、成本低、客观等特性,是对传统调研数据有益拓展。与数值型问卷数据相比,在线旅游评论属于文本型数据,具有大数据的特点,包含了大量有价值的信息,超出了传统计量经济学和统计学方法(如回归模型)的分析能力[8]。伴随着大数据和自然语言处理技术的不断发展,主题模型、语义关联分析和情感分析等文本挖掘方法逐渐被应用于分析在线旅游评论,以发现隐藏于数据背后的有用信息[9]。
目前,国内外学者对游客满意度的评价研究已取得较为丰硕的理论与实践成果,但基于在线旅游评论和网络文本挖掘技术的研究成果尚存在以下不足:一是研究对象主要集中于酒店,关于旅游目的地的研究较少,特别是关于生态旅游地的研究较为罕见;二是采用情感分析方法计算游客情感值时,通常使用现有的公共情感词库,而没有构建适合于旅游领域的情感词库,忽视了旅游活动的特点。针对现有不足,本研究的主要贡献为:首先,基于LDA模型建立生态旅游游客满意度评价指标体系;其次,基于20800条在线旅游评论和BosonNLP词典,构建旅游情感词库;在此基础上,建立情感分析方法与游客满意度评价模型;最后,以开展生态旅游的扎龙国家级自然保护区为研究案例地,一方面对现有案例地进行拓展,另一方面为扎龙生态旅游的可持续发展提供建议和参考,同时对其它生态旅游地的健康发展具有一定的借鉴意义。
1 研究方法
1.1 研究设计
为科学评价生态旅游满意度,本文提出了一种基于在线旅游评论数据和网络文本挖掘技术的分析框架,如图1所示。首先,使用Python网络爬虫采集在线旅游评论数据,并进行数据预处理,包括中文分词、词性标注等。其次,使用LDA模型进行主题识别,并从所有提取的主题中选择关键主题作为游客满意度评价指标。再次,建立情感分析方法,包括旅游情感词库构建、语义逻辑规则建立、规则短句提取以及规则短句情感值计算。一方面,通过构建的情感分析方法量化在线旅游评论数据以获得游客情感;另一方面,基于情感分析结果计算各评价指标的比例权重,并使用层次分析法(AHP)进行权重修正进而得到最终权重。在此基础上,结合各评价指标和指标权重,构建生态旅游游客满意度评价指标体系(包括目标层、准则层和评价因子层)。最后,建立游客满意度评价(TSE)模型对生态旅游游客满意度进行定量评价,分析影响游客满意度的优势与劣势因素,并提出发展策略。

图1 分析框架
1.2 LDA模型
有关研究表明[8],潜在Dirichlet分布(LDA)模型作为一种主题概率模型,能够从大量非结构化文本数据中有效发现潜在维度。因此,本文采用LDA模型进行影响游客满意度潜在维度的提取。LDA模型是由Blei等[10]在2003年提出的一种文档主题生成模型,属于无监督的机器学习技术,其包含文档、主题和词三层结构,因此也被称作三层贝叶斯概率模型。假设语料库D包含K个主题和M篇文档,D={W1,W2,W3,…,WM}表示语料库D中M篇文档的集合,文档W=(w1,w2,…,wN)表示由N个词组成的序列,wn表示序列中第n个词,则LDA模型生成文档的过程如下所示:
1) 选择N~Poisson(ξ);
2) 选择θ~Dirichlet(α);
3) 对于每个词wn:
i)选择主题zn~Multinomial(θ);
ii)从多项式概率p(wn|zn,β)中选择词wn。
步骤1)中,Poisson(ξ)为泊松分布,表示文档长度N服从泊松分布。步骤2)中,α为Dirichlet分布参数;θ表示k维的Dirichlet随机变量,具有以下概率密度:
(1)
公式(1)中,Γ(·)为Gamma函数。步骤3)中,β为Dirichlet分布参数;由公式(1)和多项式概率p(wn|zn,β)可得到变量θ、主题Z和文档W的联合分布为:
(2)

(3)
最后,将单个文档的边际分布相乘,可得到语料库D的概率分布:
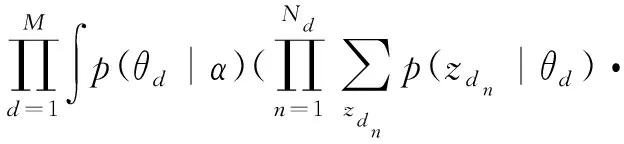
p(wdn|zdn,β))dθd
(4)
LDA模型的主题数K、Dirichlet分布参数α和η为待定参数,本文采用困惑度[10](Perplexity)指标确定最优主题数K;采用通用参数设置[11]确定α和β,即α=50/K,η=0.01;同时,采用Gibbs采样算法进行模型求解[12]。困惑度计算公式为:
(5)
1.3 情感分析
相比于通过传统问卷调查方法收集的便于量化的Likert量表数据,在线旅游评论属于文本型数据,量化分析较为困难。随着自然语言处理(NLP)技术的发展,运用情感分析方法量化在线旅游评论,进而评估游客情感已成为旅游研究中一种新的尝试。情感分析,也称为观点挖掘,其目标是从文本型数据中挖掘或分析出观点所表达的正面或负面情感及情感强度[13],包括基于机器学习算法和基于情感词典等分析方法。有关研究表明,机器学习方法无法依据旅游活动的特征进行针对性地解释,因而并不适用于旅游现象的解析[14],而基于情感词典的方法具有良好的泛化能力[11]。因此,本文采用基于情感词典的情感分析方法探究生态旅游目的地的游客情感,遵循“旅游情感词库构建—语义逻辑规则建立与规则短句提取—规则短句情感值计算”的设计思路建立情感分析方法。
1.3.1 旅游情感词库构建
情感词库是文本情感分析的基础,主要包括情感词典,修饰词典和否定词典。当前研究采用的中文情感词典主要为知网HowNet词典[15]、大连理工大学词典[11]等,而本研究使用的是BosonNLP词典。与其它情感词典相比,BosonNLP词典[16]是基于微博、新闻、论坛等上百万篇情感标注数据构建而成,包含114766个词汇,并且涵盖了较多网络用语,适合用于分析在线评论数据,但是与HowNet词典一样[17],BosonNLP词典同样忽视了旅游活动的特点。因此,本文在BosonNLP词典的基础上构建了更适用于分析在线旅游评论的旅游情感词库,具体步骤如下:
步骤1旅游情感词库数据采集
为构建一个泛化能力较强、适合分析包括生态旅游在内的多种旅游类型的旅游情感词库,依据国家旅游局发布的《旅游景区质量等级的划分与评定》政策中旅游景区的分类,选取位于东北三省(黑龙江省、吉林省、辽宁省)的风景区、文博院馆、寺庙观堂、旅游度假区、自然保护区、主题公园、森林公园、地质公园、动物园、植物园等10种类型的旅游景区作为数据采集点,同时选择国内最大、知名度最高的旅游网站-携程网作为数据来源网站[18],利用Python语言编程共采集20800条有效评论,约106万字,具体如表1所示。

表1 旅游情感词库数据说明
步骤2基于TextRank算法的关键词提取
由于旅游情感词库数据包含20800条在线旅游评论,超过100万字,数据规模较大且噪声数据过多,因此本文采用TextRank算法进行关键词提取以降低数据维度、提高数据质量,共获得11256个关键词。
TextRank算法是一种基于图的词排序算法[19],常用于文本挖掘领域,其公式为:
(6)
其中,vi表示评论中第i个单词对应的图中节点,d表示阻尼系数(Damping Factor),其通常设置为0.85,H(vi)表示vi的得分,In(vi)表示vi的入链集合,Our(vj)表示vj的出链集合,|Our(vj)|表示vj的出链数量。
步骤3情感词筛选与旅游情感词库构建
采用现有研究通常使用的人工标注的方法[9],对基于TextRank算法从20800条在线旅游评论中提取的11256个关键词进行情感词筛选,共获得402个可用于表达游客情感的词汇,通过对比BosonNLP词典,新增232个(正面情感词121个,负面情感词111个)词汇。在此基础上,删除BosonNLP词典中包含的程度副词与否定词,共删除47个程度副词、8个否定词,剩余114711个词汇,然后将两部分词典合并构建旅游情感词典,共包含114943个(正面情感词83177个,负面情感词31766个)情感词汇。在修饰词典与否定词典构建方面,修饰词典由51个程度副词构成,分为情感增强词和情感减弱词,情感增强词包含21个“最”级别程度副词以及19个“较”级别程度副词,情感减弱词包含11个“稍”级别程度副词;否定词典则由21个含有否定意义的词构成。旅游情感词库部分示例如表2所示。

表2 旅游情感词库(部分示例)
1.3.2 语义逻辑规则构建与规则短句提取
研究表明,情感词主要是形容词,但部分名词或动词也可以表达情感信息[13],因此基于先验知识和词性标签构建可能包含观点情感的语义逻辑规则,如表3所示,并使用正则表达式提取已词性标注的在线旅游评论中符合规则的短句。正则表达式是计算机科学领域的一种常用方法,通常用于检索、匹配和提取符合模式或规则(如语义逻辑规则)的文本[13]。

表3 语义逻辑规则
1.3.3 规则短句情感值计算
在参考相关文献[17]的基础上,对提取的规则短句进行情感值计算,即将正面和负面情感词分别赋值为1和-1,同时将“最”级别、“较”级别和“稍”级别程度副词的系数分别设置为2、1.5和0.5倍。此外,若规则短句中否定词的数量为奇数,则该规则短句的整体情感值取反;否则,整体情感值保持不变。
1.4 TSE模型
在基于情感分析方法量化在线旅游评论数据获得游客情感的基础上,为进一步得到通过LDA模型提取的游客满意度评价指标的满意度值,本研究依据游客满意度评价指标体系第3层(评价因子层)各评价因子的特征将已赋值的规则短句(即情感短句)进行分类,并基于线性加权原理构建游客满意度评价(Tourist Satisfaction Evaluation,TSE)模型,即:

(7)
其中,TStotal表示游客总体满意度,WBi表示评价指标体系第2层(准则层)的准则Bi的权重,SBi表示准则Bi的满意度,WCij表示准则Bi中评价因子Cij的权重,SCij表示评价因子Cij的满意度,NCij表示属于评价因子Cij的情感短句的数量,Xijk表示第k个属于评价因子Cij的情感短句的情感值,r表示准则层包含准则的数量,m表示评价因子层包含评价因子的数量。
2 实证研究
2.1 数据来源与预处理
本文以扎龙国家级自然保护区为案例地进行实证研究,扎龙是中国最大、世界闻名的湿地生态系统类型的自然保护区[20],位于齐齐哈尔市东南部,1992年被列入中国首批“世界重要湿地名录”。作为国家4A级生态旅游景区,扎龙生态环境良好,丹顶鹤等鹤类资源丰富,素有“鹤的故乡”之称。2017年,扎龙生态旅游景区被评为国家湿地旅游示范基地。然而,随着游客数量的不断增加、游客需求的日益增长以及游客偏好的不断变化,扎龙仍面临着生态旅游可持续发展的挑战[21]。因此,选择扎龙自然保护区作为实证研究区域具有一定的代表性和典型性。
现有文献主要从单一网站采集研究数据[18],为了获得更加全面的数据,本文的研究数据来自国内两种类型网站:团购类和旅游类网站,并根据以下两个原则选择符合要求的网站作为数据来源:1)每一类型中百度搜索指数排名前十;2)评论数量大于100条。根据以上原则,最终选取了两个团购类网站以及六个旅游类网站,并利用Python语言编程采集带时间属性的在线旅游评论,共计4847条。为保证数据质量,首先利用文本去重、删除缺失值等方法,进行数据清洗;然后,选取近五年(2014年1月1日~2019年5月10日)的评论数据作为研究数据,共选取有效数据3550条,24万余字,具体如表4所示。

表4 研究数据说明
所有有效的研究数据均采用以下三种方法进行预处理:中文分词、词性标注(POST)和去停用词。在中文分词与POST方面,本文采用的是Jieba中文分词工具,其在准确率、效率和未登录词识别等方面具有良好效果[9],例如评论“风景非常好,空气质量很棒,放飞丹顶鹤真的是非常壮观”,Jieba中文分词与词性标注结果为“风景/n非常/d好/a,/x空气质量/n很棒/a,/x放飞/v丹顶鹤/nr真的/d是/v非常/d壮观/a”。其中,POST集采用北大POST集作为标准规范。在去停用词方面,利用哈尔滨工业大学中文停用词表对在线旅游评论数据中出现的诸如“了”、“的”、“在”、“和”等停用词汇进行过滤[9]。
2.2 实证结果与分析
2.2.1 生态旅游游客满意度评价指标体系
依据困惑度公式计算LDA模型主题数为1到100的困惑度,得到困惑度-主题数曲线如图2所示。由图2可得,随着主题数量的增加,困惑度逐渐减小且下降速度变慢,当主题数量大于50时,困惑度趋于平稳,继续增加主题数量所获得的收益小于增加主题数量的投入[22],因此确定LDA模型的最优主题数为50,即K=50。同时,设置Dirichlet分布参数α=50/50=1,β=0.01,Gibbs采样迭代次数为1000次。
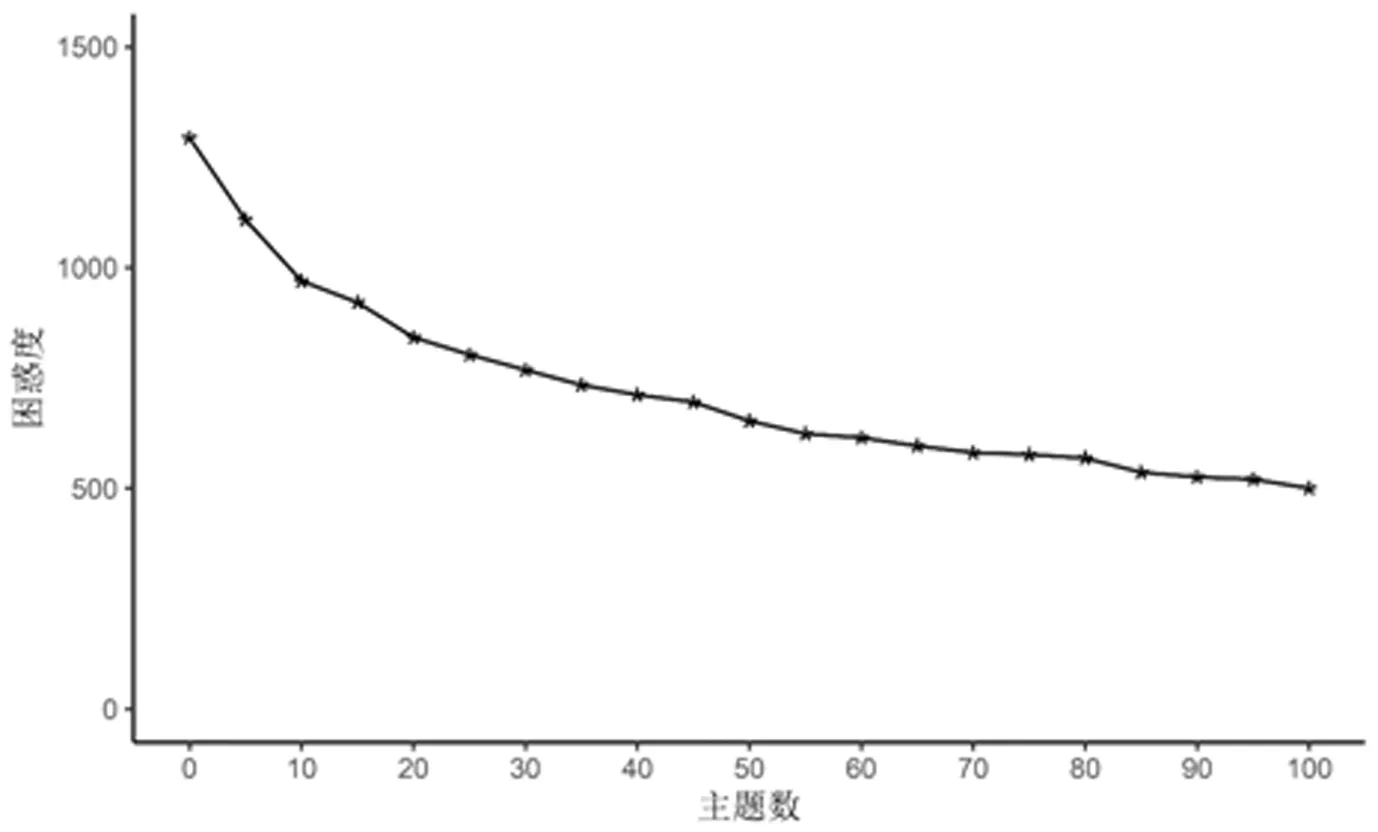
图2 困惑度-主题数曲线
通过应用LDA模型提取了50个主题,对提取的主题进行分析发现部分主题并没有实际意义,部分主题与生态旅游无关。因此,需要对主题进行筛选并命名。首先由一名研究人员进行主题筛选与命名,然后由另外两名研究人员进行确认,三名研究人员均熟悉生态旅游。其中,在主题命名方面,采用的是常用的主题命名方法[8,11],即识别每个主题所包含的概率值较大的词的含义以及词与词之间的逻辑关系。通过上述处理过程,最终识别并命名了11个与ZNNR生态旅游相关且有意义的主题,如表5所示,受篇幅所限,各主题均选取概率值排名前5的词表示。
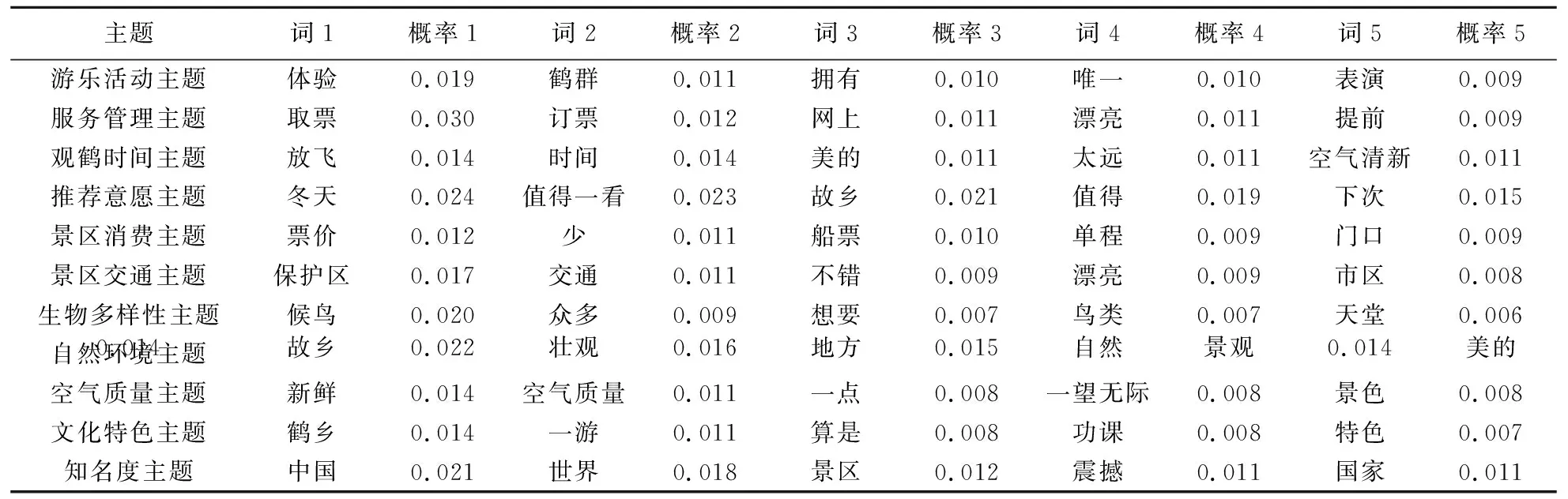
表5 LDA模型的主题命名结果
在此基础上,将选取的11个主题作为生态旅游游客满意度评价指标体系第3层(评价因子层)的11个评价因子;通过对评价因子进一步分析,将11个评价因子划分为3个类别,即生态旅游体验、自然资源和文化资源,作为评价指标体系第2层(准则层)的3个准则;游客总体满意度则作为评价指标体系第1层(目标层)的唯一目标。
在运筹学和管理学上,层次分析法(AHP)是一种成熟、科学、系统、有效的权重确定方法[23],因此本文采用AHP确定评价指标权重,即先计算各评价指标的比例权重,然后使用AHP方法进行权重修正,最终获得通过一致性检验的修正权重和层次总排序权重。具体而言,在计算比例权重方面,首先采用正则表达式提取已词性标注的在线旅游评论中符合语义逻辑规则的规则短句,共计9944句,如表6所示;其次,依据规则短句的情感值计算方法对提取的规则短句赋值,共获得6804句情感短句,与BosonNLP相比,所构建的旅游情感词库比BosonNLP多计算出239句情感短句,说明本文所构建的旅游情感词库更加有效;在此基础上,根据11个评价因子的特征(即11个主题及其主题词)采用正则表达式将6804句情感短句进行分类;同时,为确保分类结果的准确性,将四名研究人员分成两组分别进行验证并对验证结果进行一一对比分析,若两组验证结果不一致,则与专家进行讨论并确定最终分类结果,具体分类情况如表7所示;最后,依据情感短句的分类情况计算各评价指标的比例权重。
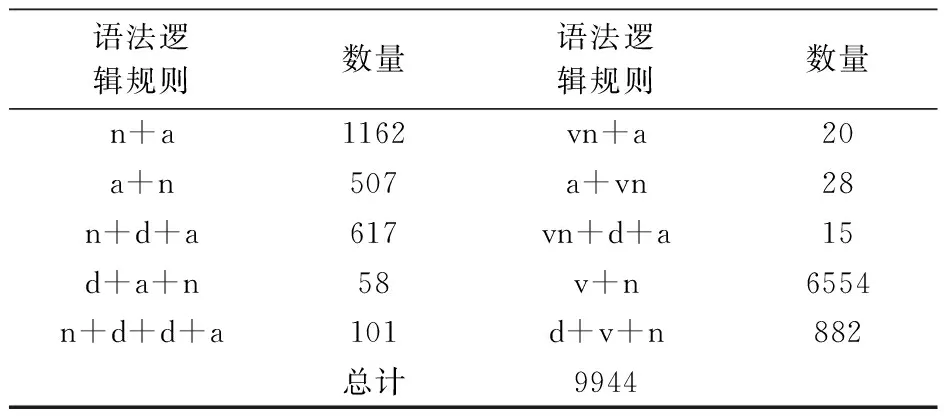
表6 语法逻辑规则的情感短句数量

表7 评价因子的情感短句数量
在计算修正权重和层次总排序权重方面,首先基于比例权重和Saaty 1~9级标度法[24]构造判断矩阵A、B1、B2和B3,并使用一致性指标CI、同阶平均随机一致性指标RI和随机一致性比率CR对判断矩阵进行一致性检验,结果如表8所示。

表8 一致性检验结果
然后,分析各判断矩阵和层次总排序的CR值发现,均小于0.1,说明判断矩阵通过一致性检验[24],具有满意的一致性。在此基础上,得到了各评价指标的修正权重和层次总排序权重。最终,本文构建了包括1项目标、3项准则和11项评价因子的3层生态旅游游客满意度评价指标体系,如表9所示。
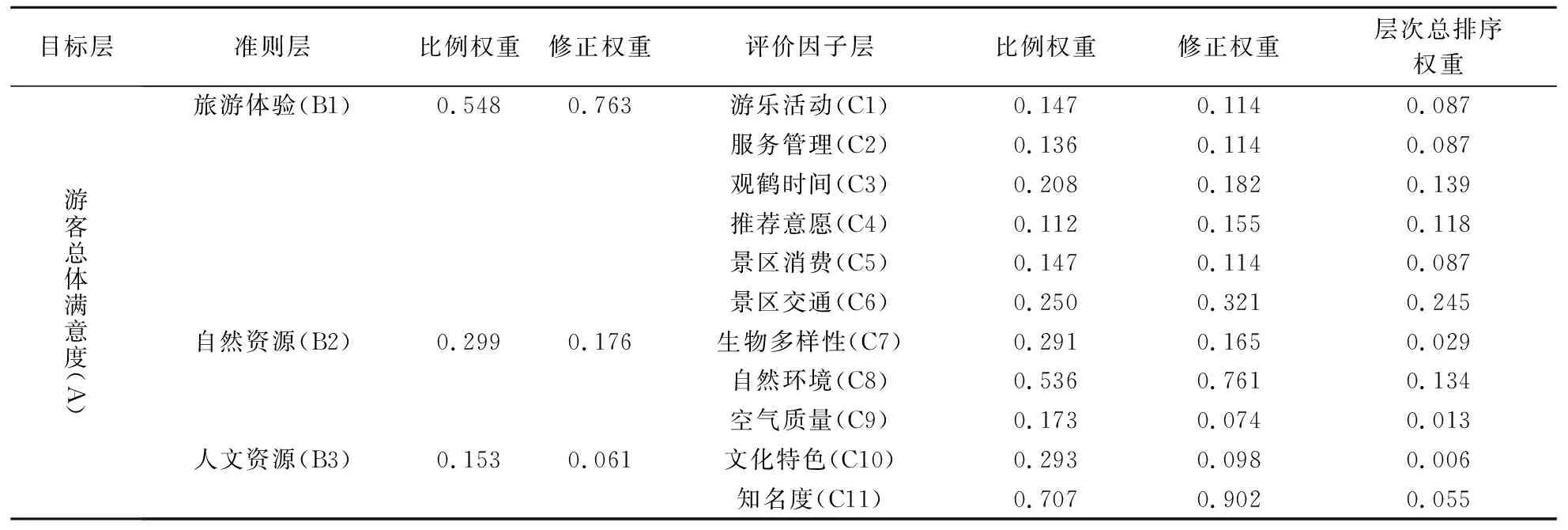
表9 游客满意度评价指标体系
3.2 生态旅游游客满意度评价结果与分析
依据构建的生态旅游游客满意度评价指标体系与评价模型计算各评价指标的满意度以及总体满意度,评价结果如图3所示。生态旅游游客满意度的最大区间为[-2,2],参考Likert 5级量表的赋值规则,本文将“-2”、“-1”、“0”、“1”、“2”依次命名为“非常不满意”、“比较不满意”、“一般满意”、“比较满意”、“非常满意”。通过分析可以得出,游客总体满意度为0.614,处于“一般满意”与“比较满意”水平之间,为基本满意水平,表明景区仍有较大的提升空间。准则层中,3个准则按照满意度高低依次为人文资源(1.519)、自然资源(1.160)和旅游体验(0.416)。人文资源与自然资源的满意度均达到比较满意水平且远高于总体满意度,而旅游体验的满意度最低且低于总体满意度,仅处于一般满意水平,亟需改善。评价因子层中,知名度、自然环境与空气质量的满意度较高,而景区消费、景区交通与观鹤时间的满意度较低。例如评论“景点门票太贵”、“交通不太方便”以及“就是放鹤时间太短了”等都是游客的真实反映。因此,景区管理者应在保持现有人文资源与自然资源的基础上,正确把握游客偏好并采取合适的管理策略以促进生态旅游满意度的提升。

图3 游客满意度评价结果
3 结论与讨论
本文以扎龙国家级自然保护区为例,基于在线旅游评论数据和网络文本挖掘技术,构建游客满意度评价指标体系和评价模型,定量评价游客的生态旅游满意度。研究结果表明:游客生态旅游总体满意度为0.614,达到基本满意水平,仍存在较大提升空间。特别的,通过实证研究验证了本文所提出的基于在线旅游评论数据和网络文本挖掘技术的分析框架具有一定的可行性与有效性。此外,扎龙景区可通过加强交通设施建设、合理安排观鹤时间、有效控制消费水平、融合自然资源与人文资源、开展特色生态旅游等途径提升游客生态旅游体验满意度,进而促进景区健康与可持续发展。
在线旅游评论为游客满意度评价的研究提供了新的数据来源。相较于传统问卷和访谈数据,在线评论具有易获取、范围广、成本低和客观性等特点,可有效避免因问卷质量、研究人员主观因素和受访人员理解偏差等引起的数据偏差问题[25]。但研究仍存在一些不足,首先在线评论覆盖的用户大部分是受过教育的、年轻的、可接触到网络的人群[17],可能会产生样本偏差。其次,本文仅分别收集了约5000条和20000条在线旅游评论数据,研究结果可能与真实情况存在一定差异,未来研究可从更多网站获取数据来进一步验证与拓展本文的研究结果。最后,旅游相关网站可能存在虚假评论的现象,由于携程网、大众点评网等网站已经制定了相关规则且采取了一定措施以有效避免虚假评论,同时考虑到虚假评论检测的困难性[13],因此本文并未对在线旅游评论的真实性进行进一步的检测,未来研究可以考虑通过检测虚假评论以提升数据质量。
