茶油掺伪定性鉴别模型的对比分析
2022-02-08孙婷婷钟瑾璟刘剑波任佳丽钟海雁
孙婷婷,钟瑾璟,刘剑波,任佳丽,钟海雁,周 波
(林产可食资源安全与加工利用湖南省重点实验室1,长沙 410004) (中南林业科技大学食品科学与工程学院2,长沙 410004) (岳阳市质量计量检验检测中心食品检验所3,岳阳 414000) (海普诺凯营养品有限公司4,长沙 410004)
目前准确快速鉴别食用植物油掺伪的研究大部分是首先利用先进的实验仪器和检测技术获得大量复杂的结构化量测数据,然后采用各种数学方法从数据中挖掘和提取出掺伪鉴别所需的特征信息[1]。目前使用较为广泛的检测技术和方法包括常规理化检测法[2]、色谱法[3,4]、核磁共振法[5]、近红外光谱法[6,7]、拉曼光谱法[8]、荧光光谱法[9,10]、电子鼻技术[11]及稳定同位素比质谱法[12]等,常规理化检测法获取数据较为简单,但数据在掺伪后特征变化不明显,使掺伪鉴别具有一定局限性;近红外光谱法具有获取数据简单便捷、没有污染、对样品不易破坏等优点,但当样品量较小时,效果相对不佳;核磁共振和稳定同位素比质谱等大型仪器设备操作复杂繁琐,无法满足市场快速检测的需求;电子鼻技术获得的数据不稳定;而色谱法具有灵敏度高、选择性强、分析速度快、操作简便、样品用量少等优势,是目前广泛应用在植物油掺伪鉴别中的量测数据获得方法。
基于先进和成熟的检测技术和方法获得大量复杂的结构化量测数据后,根据鉴别需求和问题性质,需要采用不同的机器学习算法来挖掘和提取出掺伪鉴别所需的特征信息。食品的掺伪鉴别问题分为两类,分别是定性掺伪鉴别和定量掺伪预测,二者分别属于分类问题和回归问题。目前用于食品掺伪量预测的机器学习算法主要包括人工神经网络(ANN)[13-17]、偏最小二乘回归(PLSR)[18-20]、多元线性回归(MLR)[21]等。ANN对掺伪量的预测准确率高,低掺样本预测能力强,但训练操作耗时且复杂,计算复杂度较高,模型可解释性差,训练所需数据规模大;PLSR模型综合考虑了多种特征性物质与掺伪含量的映射关系,但其只能拟合线性相关关系,掺伪量数值与作为特征物质的含量值间非线性因素增强会影响鉴别结果;MLR模型可以拟合掺伪量值与掺伪油脂的多个特征性变量之间的线性相关关系,模型原理简单易于理解,但当变量之间存在非线性相关性时模型的适用性较差,并且当自变量个数较多时计算较为复杂[22]。此外,掺伪鉴别方法的准确率不仅取决于所采用的机器学习算法,在很大程度上还受到实验样本数据的影响,如当实验样本的覆盖性较弱时,训练集无法充分反映掺伪样本的全部特征,在此基础上训练得到的不同机器学习算法模型的鉴别准确性就会受到影响,无法对训练集未覆盖的样本做出准确的掺伪鉴别,同时在没有充分训练实验样本的前提下,训练得到的机器学习模型对于新出现的新品种油脂(化合物组成种类和含量不同)的检测精度受到影响[22]。
茶油是来源于山茶科(Theaceae)山茶属(Camellia)的植物种子制备而成的一种营养丰富的食用植物油脂,主要生产地在湖南、江西、浙江、广西和贵州等地,与橄榄油、棕榈油和椰子油并列世界四大木本油脂[23]。茶油的营养功能价值和商品价格要高于其他食用植物油脂,导致市场上用低质低价食用植物油掺伪茶油的现象较普遍[24],严重损害了茶油生产者和消费者的利益,所以建立快速、精准的检测技术和方法来鉴别茶油掺伪是保障我国茶油生产和销售市场正常秩序以及实现茶油高质量发展的必然需求。本研究基于脂肪酸和甘油三酯的色谱数据,运用Python语言建立并对比分析偏最小二乘回归模型和多元线性回归模型应用于掺伪茶油掺伪量的定量预测效果,以期为鉴别掺伪茶油纯度及定量分析调和茶油配比提供参考。
1 材料与方法
1.1 实验材料
1.1.1 主要试剂及仪器
脂肪酸甲酯标准品(FAMEs)、色谱纯乙腈和色谱纯异丙醇、甘油三酯标准品。
BSA124S电子分析天平(0.000 1 g),GC 2014气相色谱仪,VORTEX-5涡旋混匀仪,LC-20AD高效液相色谱仪(配备有CMB-20A控制器,LC-20AD二元泵,SIL-20A自动进样器和CTO-10AS柱温箱,蒸发光散射检测器-2000ES),ZORBAX SB-C18色谱柱(4.6 mm×250 mm;5 μm)。
1.1.2 茶油及其他掺伪植物油脂肪酸和甘油三酯
茶油及其他掺伪植物油脂肪酸和甘油三酯的实验数据是基于本实验室已报道的研究[25,26]。
1.2 掺伪茶油样本的设计
设计茶油 (n=53) 中分别掺入米糠油、玉米油、棕榈油、葵花籽油、大豆油、花生油、棉籽油及葡萄籽油的掺伪模型,设计2个掺伪梯度,自定为高掺伪梯度(10%、15%、20%、40%、60%、80%)和低掺伪梯度(2%、4%、6%、8%、10%)。高和低掺伪茶油样本数据量为318条和265条。各掺伪浓度均含53条数据,每条数据包含对应掺伪浓度下该种类掺伪茶油的14个脂肪酸和甘油三酯特征性物质指标含量数据。
1.3 机器学习算法
运用Python语言,利用sklearn.cross_decomposition库中的PLS回归函数和Linear回归函数对数据分别构建偏最小二乘回归(Partial Least Squares Regression, PLSR)模型和多元线性回归模型(Multiple Linear Regression, MLR)。2种模型都采用5-折交叉验证法进行训练和评价,使得每个样本都有机会作为测试集进行掺伪量的预测。采用的指标包括决定系数(Coefficient of Determination,R2)、均方根误差(Root Mean Squared Error, RMSE)和相对误差 (Relative Error, RE)来评价PLS和多元线性回归模型对掺伪茶油掺伪量预测的精度。
1.4 据预处理及编程平台
本研究所有模型和算法均基于Python 3.7编程语言在PyCharm 2018 IDE平台 (JetBrains (Prague), Czech Republic) 进行程序编写,所有实验均在一台苹果 (Apple Computer Inc.) 笔记本上开展,详细配置为因特尔酷睿i5 CPU (Intel (R) Core (TM) @1.70GHz),4 GB内存,NVIDIA GeForce 320M显卡。
2 结果与分析
2.1 偏最小二乘回归模型和多元线性回归模型掺伪量预测精度分析
高掺伪梯度下,PLS回归模型对茶油掺伪量定量预测的平均R2值高达0.994,但平均RMSE值较差,为1.99,尤其是对葵花籽油、葡萄籽油、菜籽油和棕榈油,PLS回归模型的RMSE值都在2.2以上(表1),这表明PLS回归模型的预测掺伪量与真实掺伪量之间的误差相对较大,准确率较低。低掺伪梯度下,PLSR模型对茶油掺伪量的定量预测效果较差,PLS回归模型对茶油掺伪量定量预测的平均R2值为0.889,平均RMSE值为0.907,尤其是对棕榈油的掺伪量预测能力最差(平均R2值=0.748,平均RMSE值=1.418)。PLS回归模型对于高掺伪梯度下茶油掺伪量定量预测的精准率高,但准确率差,而低掺伪梯度下精准率和准确率都较差,故PLS回归模型不能很好的实现茶油掺伪量的定量预测。
高和低掺伪梯度下,ML回归模型对茶油掺伪量定量预测的平均R2值分别达到了0.999和0.994,平均RMSE值分别达到了0.146和0.136(表1),ML回归模型的精准度和准确度都要高于PLS回归模型,ML回归模型相比于PLS回归模型能更好的实现茶油掺伪量的定量预测。
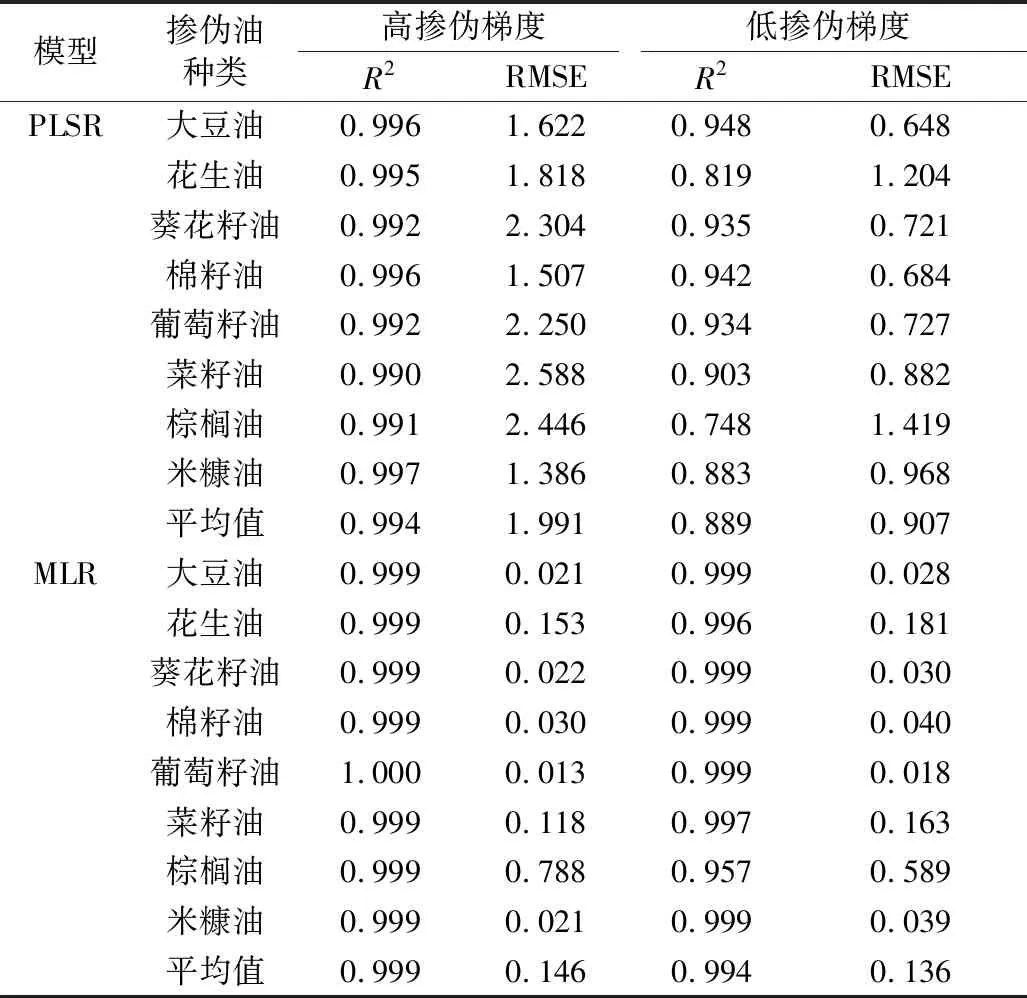
表1 不同掺伪梯度下PLS回归模型和ML回归模型的掺伪量预测精度指标值
针对高/低掺伪梯度下多元线性回归模型,得到不同植物油掺伪量预测的多元线性回归函数方程(表2)。
同时,从各类掺伪茶油样本中的掺伪量预测结果进行分析表明,无论高掺伪梯度还是低掺伪梯度,PLS回归模型对大部分样本的预测值与真实值之间的相对误差均较大(0.1~0.3),个别样本的相对误差甚至达到了0.5以上,预测效果欠佳,尤其是掺伪质量分数越低,相对误差越大,在0.3左右,个别甚至达到1.7。ML回归模型对不同种类掺伪茶油样本的预测值与真实值的相对误差普遍较小(0.001~0.01),许多样本的相对误差接近于0,预测效果较好。
2.2偏最小二乘回归模型和多元线性回归模型掺伪量预测结果的“真实掺伪量-预测掺伪量”散点图分析
为了更为直观地展示掺伪量预测结果,以掺入大豆油和花生油为例,基于PLS回归模型和ML回归模型对掺伪茶油的定量预测结果的“真实掺伪量-预测掺伪量”散点图进行分析。散点图中横坐标代表样本的真实掺伪量,纵坐标代表模型对样本掺伪量的预测值。图中每个点代表一个样本,样本点的坐标由其真实掺伪量和预测掺伪量共同决定,当样本点越接近直线y=x,表示模型对样本掺伪量的预测效果越好。

表2 不同掺伪梯度下多元线性回归模型的掺伪量预测函数
高掺伪梯度下,PLS回归模型定量预测的预测值相对于真实值存在一定程度的浮动,其中掺伪质量分数为10%、15%、20%的样本浮动区间较大,掺伪质量分数为40%、60%、80%的样本的浮动程度逐渐降低,预测值与真实值较为接近(图1a和图1b),低掺伪梯度下,PLS回归模型定量预测的预测值相对于真实值之间的浮动程度更大(图1c和图1d)。结果表明PLS回归模型对茶油掺伪的定量预测能力较差,且随着掺伪质量分数和掺伪梯度的下降定量预测能力更差。
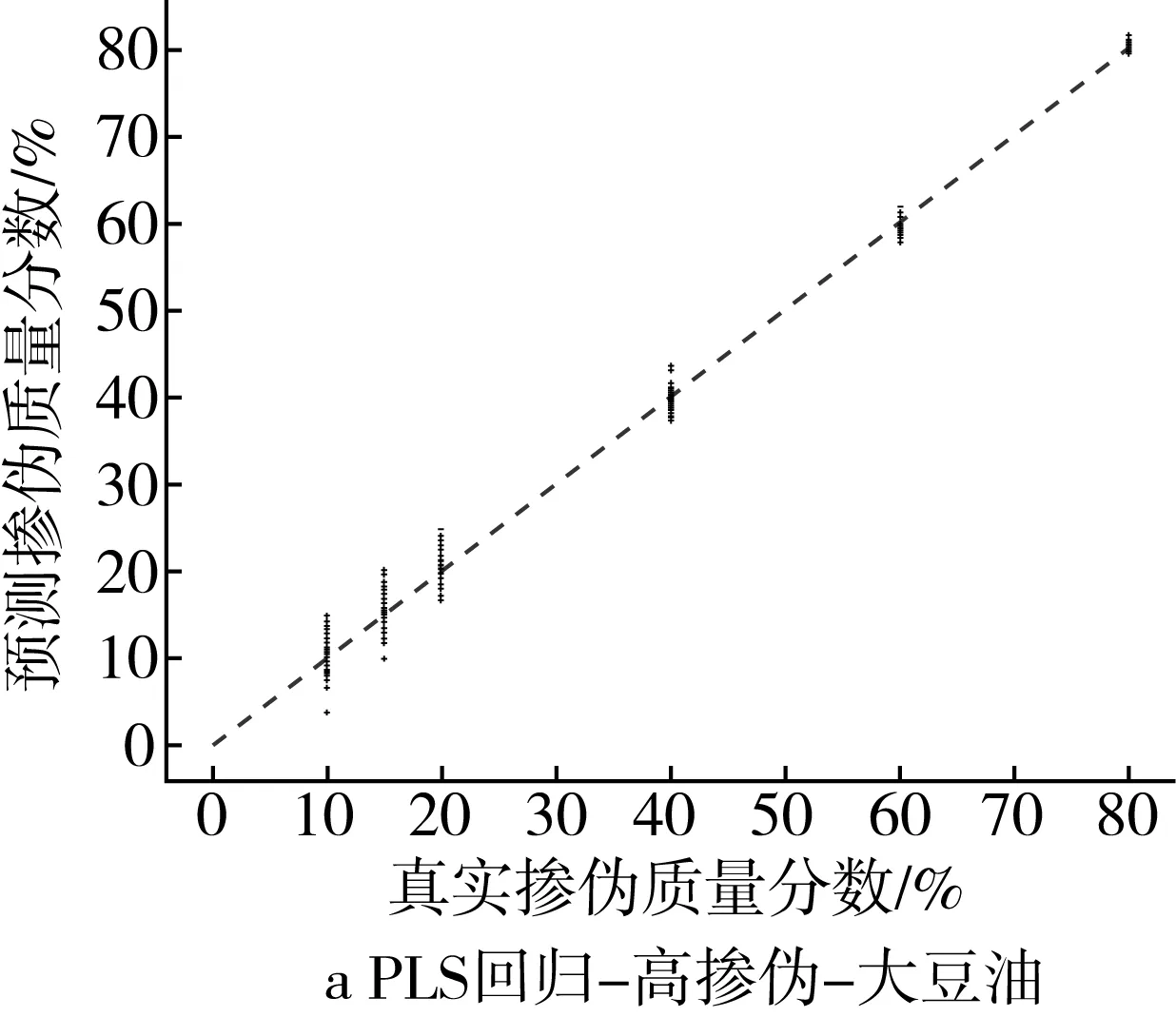
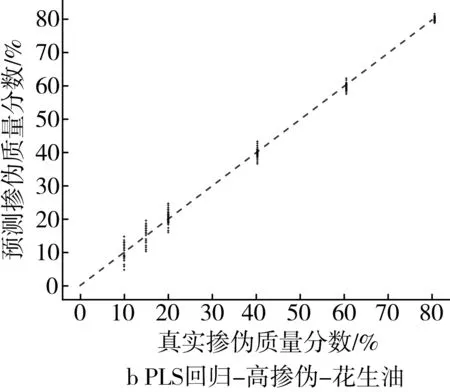
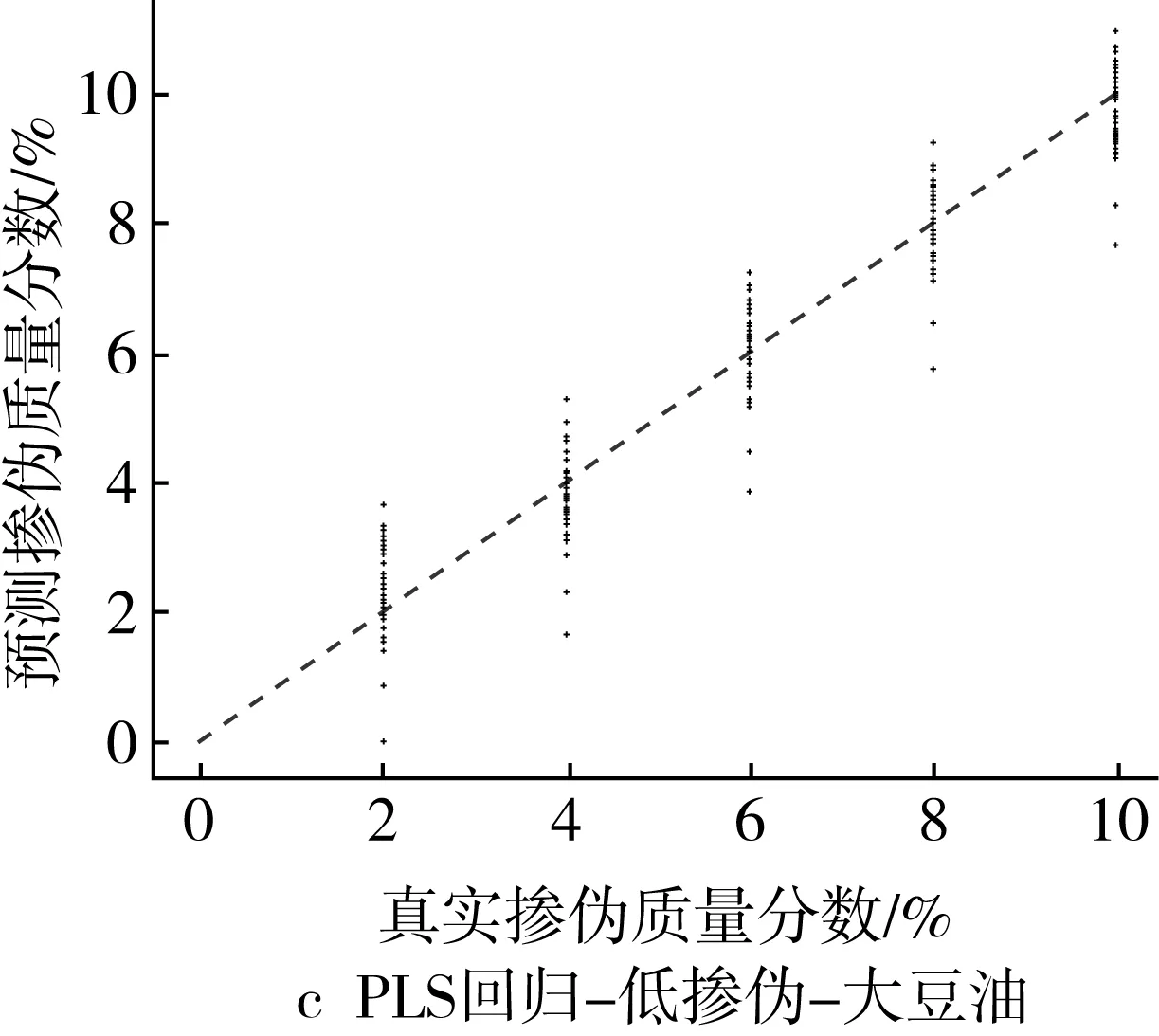
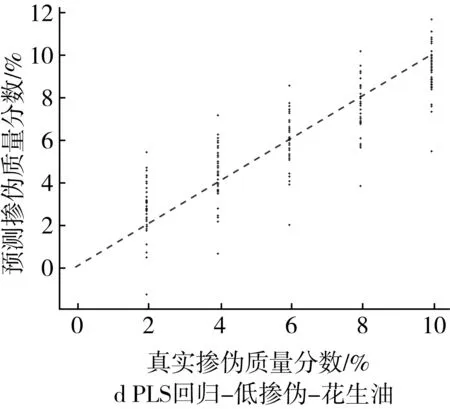
图1 高掺伪和低掺伪梯度下PLS回归模型定量预测结果的散点图
高掺伪梯度下,ML回归模型对掺伪茶油掺伪量的预测值和真实值之间的浮动程度较小,所包含的样本点基本上分别汇聚在一条直线上(图2a和图2b)。与PLS回归模型相比(图1a和图1b),浮动程度明显减小,这说明在高掺伪梯度下ML回归模型对掺伪茶油的定量预测的相对误差小,结果准确率高。
低掺伪梯度下,ML回归模型对掺伪茶油掺伪量的预测值和真实值之间的浮动程度较小,所包含的样本点基本上分别汇聚在一条直线上(图2c和图2d)。与PLS回归模型相比(图1c和图1d),ML回归模型对掺伪大豆油和花生油的茶油样本的预测值与真实值之间的浮动程度明显减小,这说明ML回归模型能很好的实现对掺伪茶油掺伪量的定量预测。
2.3 偏最小二乘回归模型和多元线性回归模型掺伪量预测结果的箱型图分析
在高掺伪梯度下,PLS回归模型对掺入米糠油、棉籽油的茶油样本的定量预测效果最好,样本的预测掺伪量与真实掺伪量之间的相对误差大部分集中在0~0.5之间(图3a),对掺伪菜籽油、棕榈油、葵花籽油和葡萄籽油的茶油的定量预测效果较差,其中对掺伪菜籽油的茶油的定量预测相对误差结果中有接近1.4的离群点样本(图3a)。低掺伪梯度下PLS回归模型对掺伪茶油定量预测的相对误差普遍较高(>0.5),对掺伪花生油、菜籽油、棕榈油、米糠油的茶油的掺伪量预测的相对误差都在2.0以上,其中对掺伪棕榈油的茶油样本的定量预测的相对误差结果中有接近3.0的离群点样本(图3b)。这进一步说明PLSR模型对掺伪茶油的定量预测能力较差。
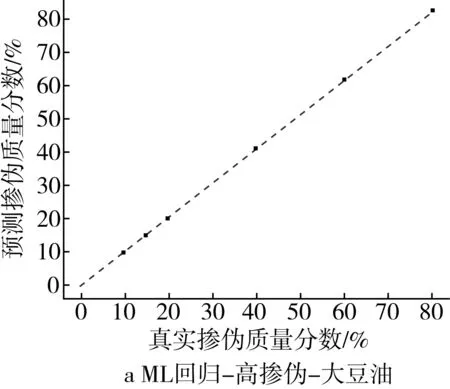
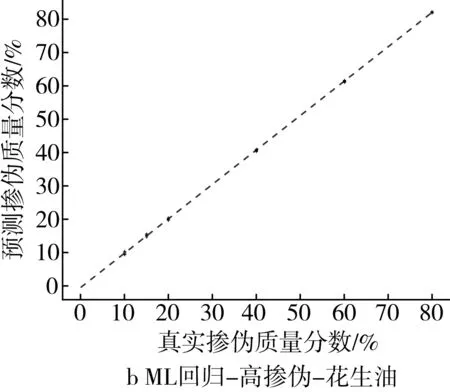

图2 高掺伪和低掺伪梯度下ML回归模型定量预测结果的散点图
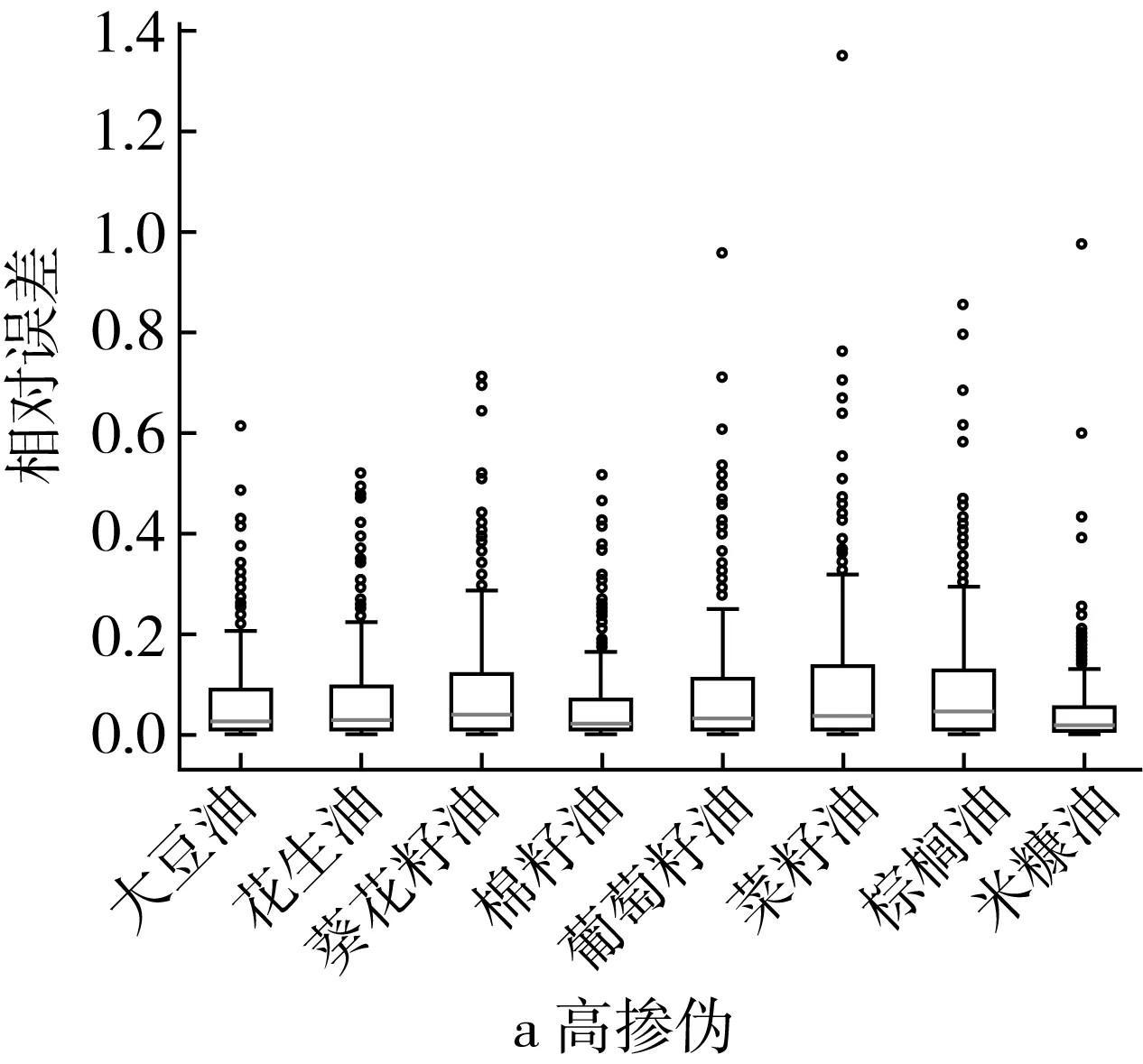
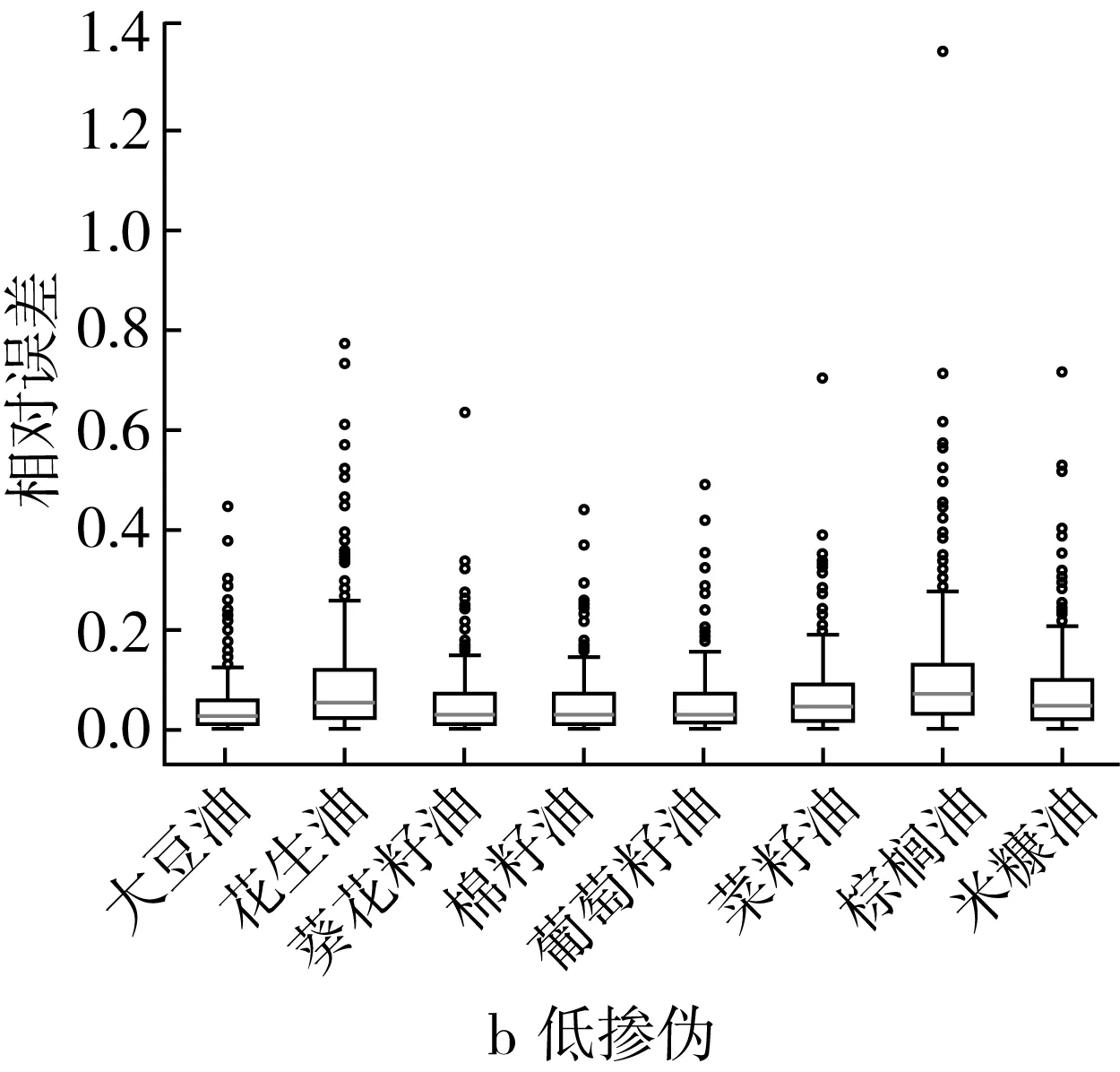
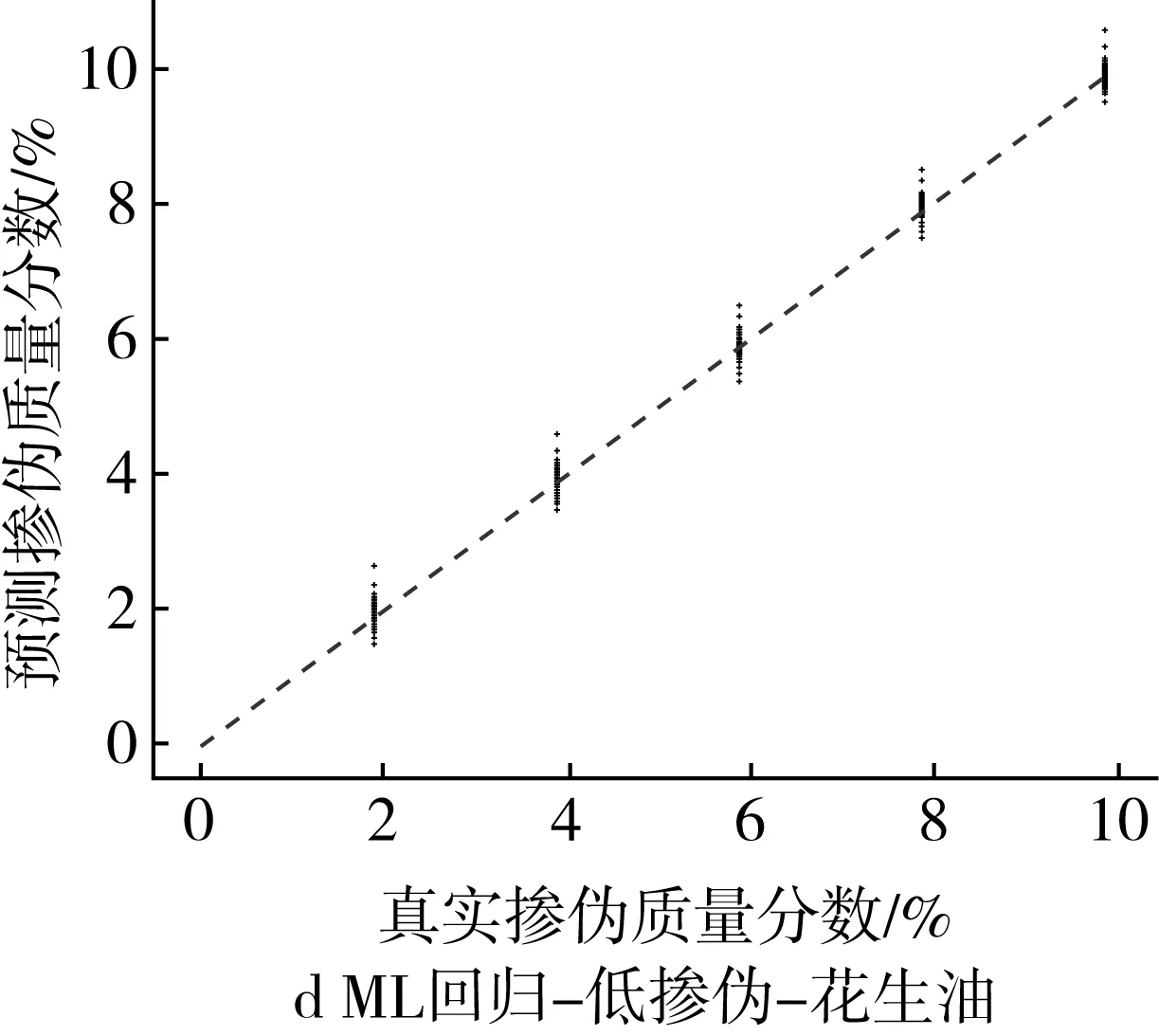
图3 高掺伪和低掺伪梯度下PLS回归模型定量预测相对误差箱型图
高掺伪梯度下,ML回归模型对棕榈油掺伪量的定量预测效果稍差(相对误差≤0.25),其次是花生油(0.05≤相对误差≤0.1)和葡萄籽油(相对误差≤0.05),其他掺伪茶油样本的定量预测结果相对误差集中在0~0.05之间(图4a)。ML回归模型对掺伪大豆油、葵花籽油、棉籽油、葡萄籽油、米糠油的定量预测效果最好,明显优于PLS回归模型的定量预测效果,相对误差大大降低(ML回归模型的最大相对误差接近0.05,PLS回归模型的最大相对误差接近1.4)(图3a和图4a)。低掺伪梯度下,ML回归模型对棕榈油掺伪量的定量预测效果稍差(相对误差0.8左右),其次是花生油(0.2≤相对误差≤0.4)和葡萄籽油(0.2≤相对误差≤0.3),其他掺伪茶油样本的定量预测结果相对误差集中在0~0.3之间(图4b)。ML回归模型对大豆油、葵花籽油、棉籽油、葡萄籽油、米糠油的定量预测效果最好,明显优于PLS回归模型的定量预测效果,相对误差大大降低(ML回归模型的最大相对误差接近1.0,PLS回归模型的最大相对误差接近3.0)(图3b和图4b)。
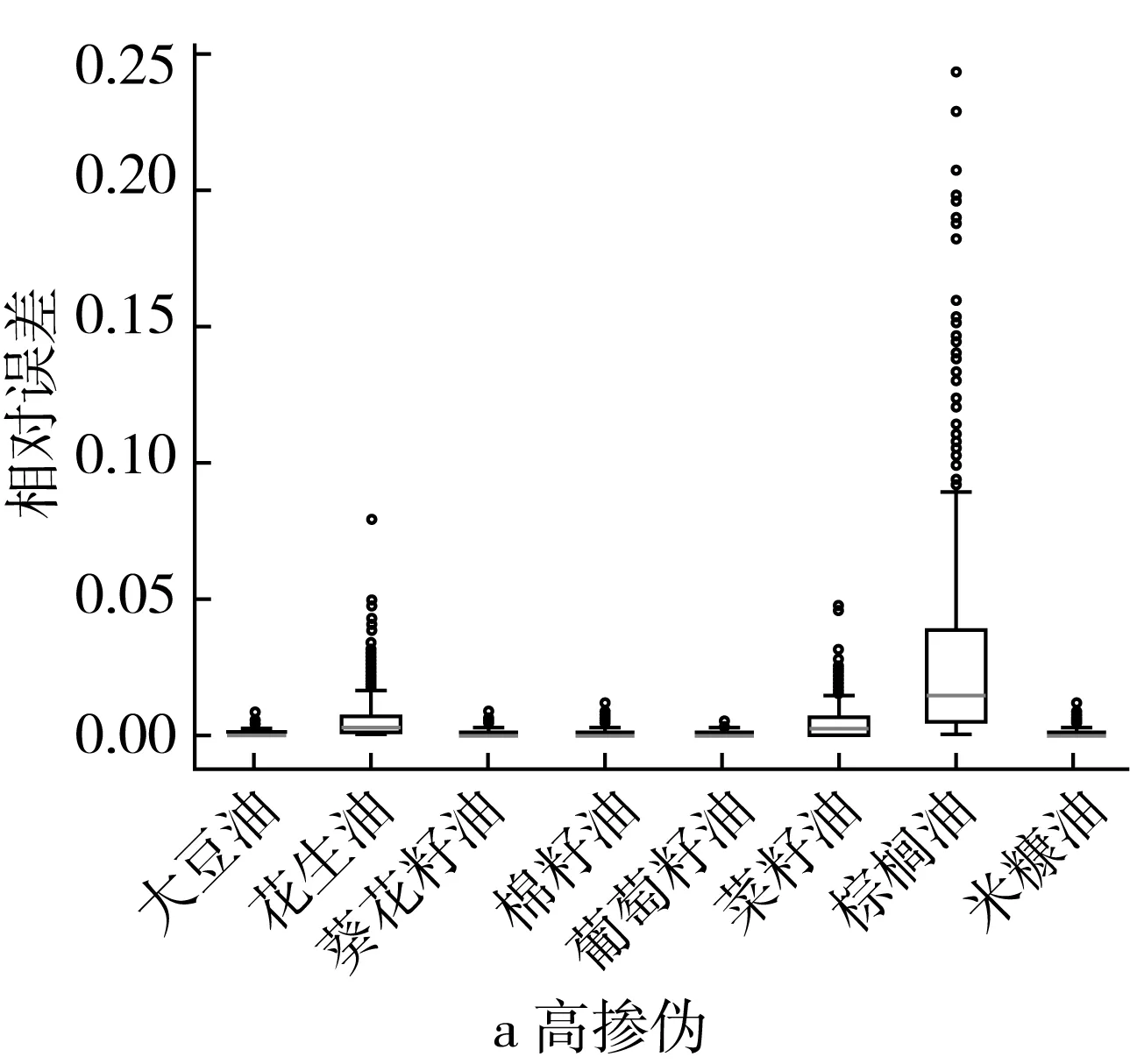
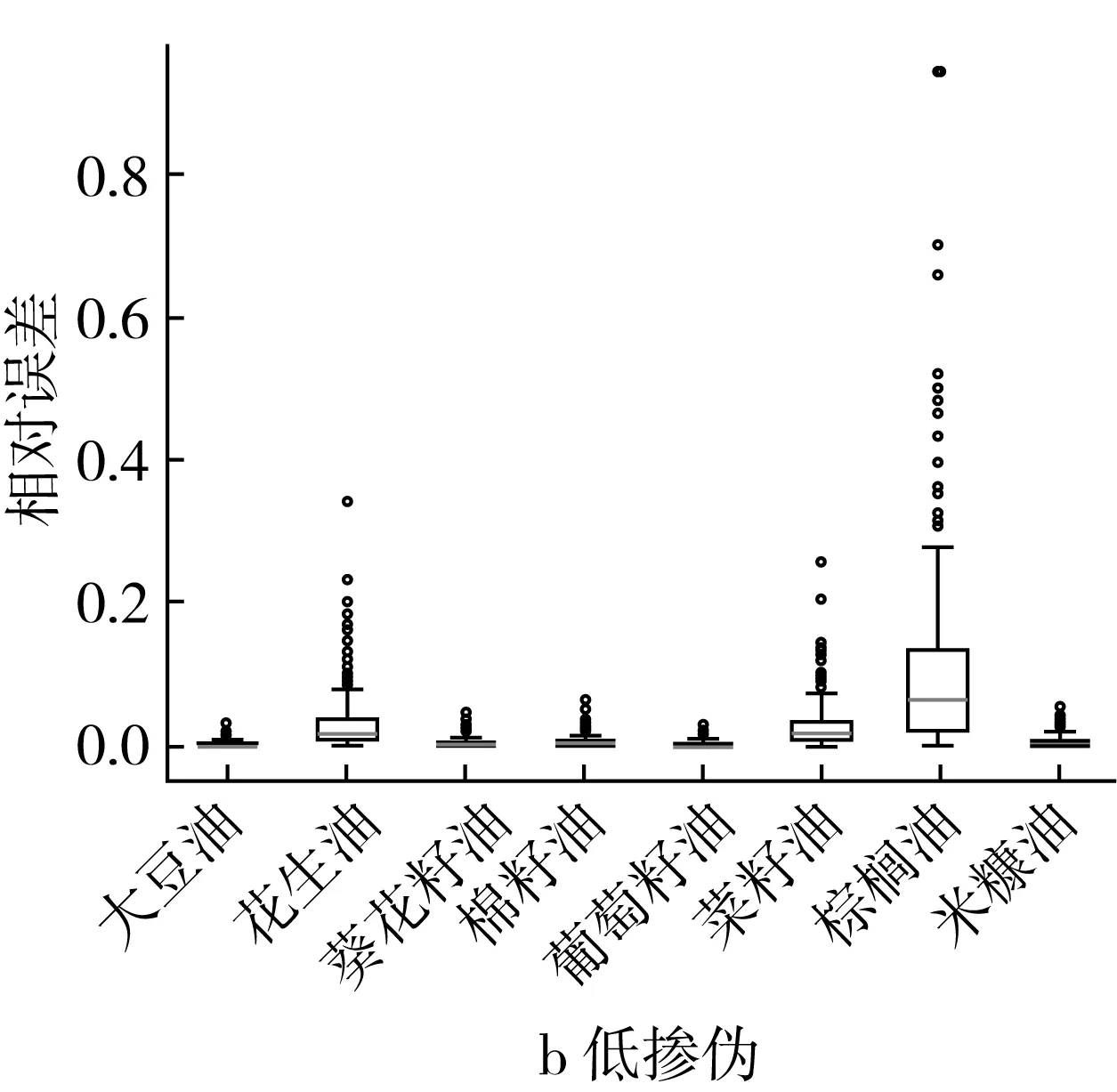
图4 不同掺伪梯度下ML回归模型定量预测相对误差结果的箱型图
结果进一步说明ML回归模型对掺伪茶油油样的定量预测能力较强,在不同掺伪质量分数和掺伪梯度下对掺伪茶油的掺伪量预测效果较好。
3 结论
本研究面向掺伪不同种类食用植物油的茶油掺伪量预测问题,基于14个特征性脂肪酸和甘油三酯指标,运用Python语言构建并对比分析了偏最小二乘(PLS)回归模型和多元线性(ML)回归模型用于掺伪茶油掺伪量的定量预测的效果。实验结果显示ML回归模型的掺伪量预测能力更强,可用于不同掺伪含量和掺伪梯度茶油样本的定量预测。
本研究构建的掺伪量预测模型可在实际的掺伪量预测场景中得到应用。基于现有掺伪茶油样本的特征物质含量和掺伪量实验数据对茶油掺伪量预测模型进行训练。待模型训练完毕后,面向掺入特定品种食用植物油的掺伪量待测定茶油样本时,测定样本的脂肪酸和甘油三酯含量数据,代入事先训练好的掺伪量预测模型中,即可得到掺伪量预测值。
后续可对我国油茶籽油和常见食用植物油的甘油三酯结构开展系统性研究,以期提高油茶籽油掺伪鉴别模型的效果和能力。
