基于Spark的实时数据采集与处理
2022-02-07高丽婷
黄 涛 高丽婷
(河北建筑工程学院,河北 张家口 075000)
0 引 言
大数据的时代背景下,数据越来越重要,如何把数据的最大价值挖掘出来是一个不可避免的问题.为挖掘数据的最大价值,对数据的分析被分为对历史数据的分析和实时数据分析.实时数据处理应用的场景也越来越多,如文献[1]分析了实时数据分析在工业方面的作用.Spark是实时数据分析中常用的一种平台,它提供流式处理框架用于实时数据的处理.本文借助Spark搭建完整的大数据平台来完成本次实验分析.本方案以分析学习网站用户喜好为目标,主要完成对网络实时数据进行采集与实时分析的实现.使用Flume对网站日志文件进行实时监控与数据采集,并将数据下发给Kafka组件.再由Spark streaming对采集到的信息进行过滤与统计处理,将处理后的数据存入到Hbase中持久化数据加以利用.
1 系统结构设计
该方法主要包括三个模块,分别是Flume模块、Kafka模块、Spark streaming流处理模块.Flume模块处于系统顶层中,主要负责对文件的监控与分发.置于中间层的是Kafka模块,主要负责接收上层的消息并提供一个给下一层使用的消息队列.底层是Spark streaming流处理模块,主要负责实时处理消息流数据与转存处理好的数据.通过三个模块互相协调,各个组件之间的消息通信,完成了实时日志数据的产生到监控,最后统计整理存入到数据库中加以利用.
1.1 Flume模块
Flume是一个用于大数据平台的文件采集,聚类和传输的系统.可作用于分布式系统中.Flume工作是基于Agent的.Agent又包含了Source、Channel、Sink.这三个组件是Flume的核心组件,表1分别对其进行说明.

表1 Flume组件说明
1.2 Kafka模块
Kafka,一种消息发布与订阅系统.可以将Kafka理解为一种消息队列,且特别是用来处理大数据量的一种消息队列.Kafka处理消息的核心组件有生产者(producer),消费者(consumer),主题(topic).Producer,消息的生产者,负责源源不断的产生消息,本文的消息来源是上一级的Flume.Topic,消息处理主题,可以理解为一个队列.Producer产生的消息要确定是发给哪一个主题来处理,同样消费者在消费时也要根据主题来确定消费的是哪里的数据.Consumer,消息消费者,从确定的主题队列中得到消息并处理.
Kafka的生产者产生的消息可以被消费一次或多次,由此衍生了Kafka的两种消费模式.第一种为一对一,即消息只会被消费一次,之后会被删除.而另外一种为一对多,即消息被消费多次,首次消费该消息后,消息不会被删除,继续保留在消费队列中,等待再次消费,且可以是不同的消费者来消费.
1.3 Spark streaming流处理模块
Spark streaming是一款可以使用复杂算子来处理流数据的实时数据处理工具,可以使用高级函数或者是机器学习算法来处理实时数据.
Spark streaming工作原理,是使用微批次处理的思想将接收到的实时数据抽象为Dstream,即离散化数据流.其核心本质就是将数据流根据时间节点的不同来划分为很多的批次,对每个批次进行处理,做出快速响应分析来达到实时处理的效果.使用streaming模块具有下一优势,首先spark streaming具有动态负载均衡的特点,即根据每个节点的特性来动态的分配任务,这样就可以合理利用每个节点的计算资源.其次spark streaming有很高的容错性,streaming作业会被拆分为在任何地方都能运行,运行后合并的结果不会产生变化的小任务,它能够并行处理,容错性较高.然后由于spark还具有很好的可扩展性,每台主机只要经过相应的配置就可以加入到指定的spark集群中去,所以在streaming中可以根据作业所需的计算资源动态的调整集群中的主机数量,合理利用每个计算资源,减少不必要的资源浪费.
2 实时数据集的模拟
2.1 实时数据背景
本文想要模拟出一个学习网站中课程点击次数以及使用哪种搜索引擎的比例.要分析学习网站课程点击与搜索引擎的使用,需要对其日志进行分析,需要提取日志中的关键信息包括IP地址、时间、请求方式、请求的课程、请求的协议、状态码及使用的搜索引擎.根据以上分析,时间可以使用本地时间,由于请求方式和协议对结果没有影响,默认全部为”GET”和”HTTP1.1”.还需要五个数组来定义其他关键信息,然后随机组合产生完整的日志信息.
2.2 实时数据产生
创建以下五个数组用来模拟实时数据,各数组的功能与描述如表2所示.

表2 数组功能与描述
创立目标数组后,对所有日志关键信息进行拼接形成完整的日志信息.一条完整的日志信息格式为:{64.156.29.632022-04-24 13:52:35"GET /class/500.html HTTP/1.1"200http://www.baidu.com/s?wd=Linux进阶}.本条日志信息表示ip为64.156.29.63的主机在2022年4月24日的13点52分点击了课程编号为500的课程,使用的HTTP请求和GET方式访问,响应的状态码为200,并且使用了百度搜索引擎搜索了关键字为Linux进阶的网页信息.
实时效果模拟.为达到实时数据模拟的效果.在Linux的终端环境下,使用命令crontab来定期执行任务的.设置定期执行的间隔,每隔指定时间产生运行一次脚本来产生数据达到实时数据模拟的效果.可以根据实际需求来设置定时执行的间隔和每次执行使产生多少实时日志数据,部分实时数据如图1所示.

图1 部分实时日志数据
3 实验分析
3.1 实验环境
由于Spark是基于Hadoop的运行的,所以实验环境必须搭建Hadoop作为基础,而Kafka也依赖与Zookeeper运行,要搭建Zookeeper保证Kafka的运行.在搭建好所有组件后,确保每个组件的配置文件的修改都生效并可以成功运行,想要集群正常运行还需配置hosts主机名与主机地址的映射,配置SSH免密登录.本实验所依赖的运行平台环境整体如表3所示.
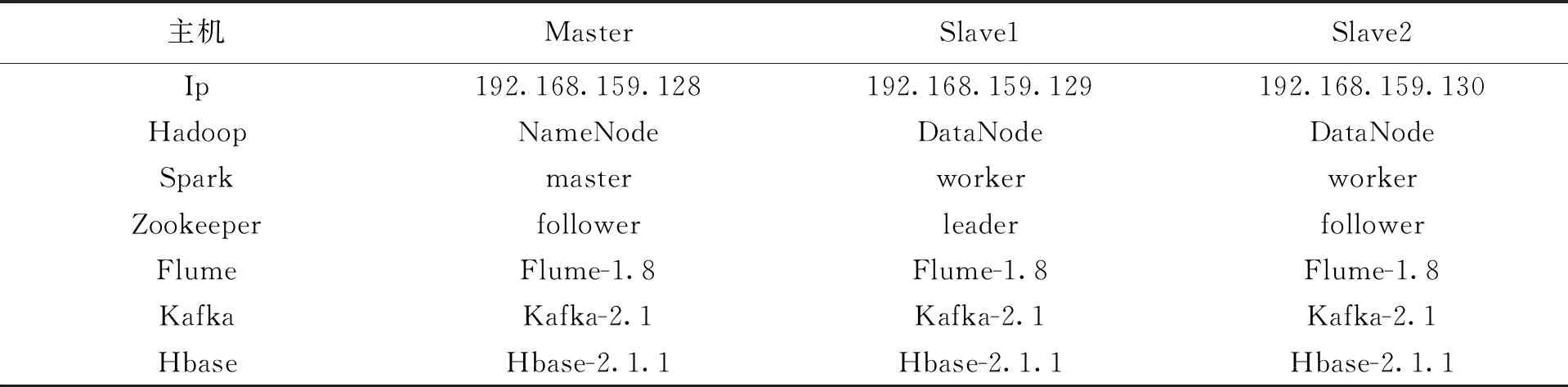
表3 实验整体环境
3.2 实验结果
启动整个实验环境,确保环境中的每个组件都正常运行,且在统一分布式的环境下.启动一个flume事件来监控日志文件,当日志文件被写入日志时就会被监控.之后创建一个Kafka的topic来接收所监控的日志文件.之后启动Spark streaming实时处理Kafka所得到的日志,对其筛选,统计等操作之后存入Hbase数据库令其持久化,以便后续分析与操作.在Linux的终端中周期性的运行日志产生的脚本,flume会实时监控日志是否被产生新的日志,日志文件发生变化,flume就会给Kafka新的数据流处理,就可以达到预期的实时处理的效果,成功对实时产生的日志进行了实时处理并存储到了Hbase中.实时数据分析效果如图2、图3所示.

图2 搜索引擎统计表

图3 课程统计表
在图2中,左边是搜索引擎的列表,由时间和搜索引擎的名字组成,右边是时间戳和具体值,某一行的内容表示某搜索引擎的使用次数.通过分析对应搜索引擎标签的具体点击次数就可以得知哪种搜索引擎是使用最多次数的,哪种是最不喜欢的,对应着使用次数最少.达到分析搜索引擎喜好的目标.
在图3中,左边的一列是时间加上课程的编号,右边同样是具体时间戳和次数的值,某一行的内容表示该课程共被点击了多少次.根据课程编号还原对应的课程,在结合具体的使用数值,可以清楚的分析出哪种课程学习人数最多,最受喜爱,哪种课程学习人数最少,不受欢迎.达到分析出课程的受欢迎程度.
4 结 论
本文从环境搭建,到分析实时日志,做了完整的实验.编写了脚本实时产生日志数据文件,使用了Flume对文件进行实时监控,交由Kafka进行消息整合与分发,最后交付给spark streaming处理,发现Spark在实时数据处理中具有很高的运算能力,它的streaming流处理框架特别适用于实时数据的处理.如今的环境下,数据量越来越高,正是需要高处理能力的大数据处理平台.数据的实时分析也越来越重要,在实时分析中还可以处理异常数据,并将处理的数据转存到其他的数据库中持久化使用.
