基于决策树的莜面近红外光谱定性分析研究
2022-02-07王翊同李子熠张天宇李鸿强
王翊同 邹 其 李子熠 张天宇 李鸿强
(河北建筑工程学院,河北 张家口 075000)
0 引 言
裸燕麦又称莜麦,是我国北方局部地区所特有的主食之一,富含各类脂肪酸、维生素、矿物质、氨基酸等营养物质,其在蛋白、脂肪含量等方面均位列谷物前列.我国种植莜麦的历史悠久,但由于莜麦种植对气候温度比较挑剔,所以全国种植面积并不算太大,但由于其非常高的营养价值和对身体非常好的功效,莜麦也成为了最安全和健康的粮食.
莜面富含多种营养物质,由于莜面营养成分高,且种植面积较小,这也导致产量并没有想象中的那么大,所以市场上存在一些莜面掺假并以高质量莜面售卖的情况.河北省张家口部分地区正是莜麦的主要产区之一,当地莜面也是主要食用主食之一.
但传统的检测方法存在效率低、成本高、不易操作等缺点.近红外光谱具有效率高、成本低、速度快,以及可以建立无损分析模型等优点,且近红外光谱近年来广泛应用于品质鉴定、品种分类等方面.然而近红外光谱是一种重叠、宽而弱的信号,没有特别显著的单个特征,所以有必要结合机器学习算法来提取光谱信息中细微、有价值的信息.高婧娴等[1]结合机器学习算法和近红外光谱对鲍鱼品种进行了分类研究,李伟等[2]结合机器学习算法和近红外光谱技术对玉米单倍体的鉴别提供了思路,汪六三等[3]利用机器学习算法和近红外光谱技术对大豆种皮裂纹识别做出研究,为机器学习与近红外光谱技术的结合提供了借鉴.
本研究正是以张家口地区莜面面粉和莜面面粉掺玉米淀粉为研究对象,以近红外光谱仪为研究设备,使用一阶导数、二阶导数和多元散射校正对光谱数据进行去噪,使用主成分分析法进行数据降噪,并结合决策树算法来建立出无损的莜面面粉检测模型.
1 材料与方法
1.1 样本收集和制备
在市场购买莜面面粉和玉米淀粉适量,并制作出纯莜面面粉样本30份,莜面掺百分之十玉米淀粉、掺百分之二十玉米淀粉、掺百分之三十玉米淀粉、掺百分之四十玉米淀粉、掺百分之五十玉米淀粉样本(决策树中分别用1-6顺序代表这六类)各30份,总计180份样本.
1.2 光谱采集
将样本放入观察器皿内,用近红外光谱仪分别对180份样本进行了光谱采集,将获取的光谱数据进行整理、总结.
1.3 光谱去噪处理
莜面面粉样本测量结果会因为光谱仪仪器本身的磨损和外界的干扰,而产生随机噪声和多元散射.为了减轻这些误差的影响,需要对180份样本进行去噪处理,本研究采用一阶差分求导、二阶差分求导和多元散射校正三种方法对原始光谱数据进行预处理.
1.4 数据降维处理
PCA主成分分析方法,是一种统计方法,是考察多个变量间相关性的一种多元统计方法,研究如何通过少数几个主成分来揭示多个变量间的内部结构,即从原始变量中导出少数几个主成分,使它们尽可能多地保留原始变量的信息,且彼此间互不相关,并将其作为新的综合指标.
本文使用了一阶导数、二阶导数和多元散射校正对180份样本进行去噪处理后,光谱数据维度相对于数据量来说,依然太高,所以本研究需要提炼出维度更低的且代表性更强的特征,本研究采用PCA方法(主成分分析)来对数据进行降维处理,使研究的数据变成维度更低且更具有代表性的数据特征.使得后续研究的算法处理起来更加高效,且时间代价更低.
1.5 决策树
决策树是机器学习中一个普通的方法,传统意义上有很多表现方式,比如ID3、C4.5等算法.本研究最终将进行了去噪和降维的光谱数据带入ID3决策树,来最终决定样本归类.
2 数据分析及模型建立方法
将主成分分析处理后的六类样本数据各30份分成20份和10份分别作为训练集和测试集,然后建立决策树模型.
决策树算法是机器学习中非常经典的分类算法,通过非常简单且容易理解的机制建立决策树,有非常强的可解释性,所以其应用范围也十分广泛.正常来说,建立决策树有三个基本步骤,分别是特征选择、决策树构建和剪枝.而决策树有三种实现算法:ID3算法,CART算法和C4.5算法,本研究选用的为国际上最有影响力的示例学习算法ID3算法,是相对容易实现并且机制相对简单的决策树算法,其中的首创性工作还是在决策树的学习算法中引入了信息论中信息增益的概念,以之作为属性选择的标准.
3 模型评估
本研究采用测试集样本的预测准确率来进行模型效果评估,用测试集带入模型得出测试集测试分类,与测试样本实际类型进行对比,得出测试准确率,作为模型的评估指标.计算公式为:
accuracy=n/N
(1)
公式中,accuracy为准确率;n为测试集正确预测的样本数;N为测试集样本总数.
4 实验部分
本研究最终定性都将采用决策树的方式来进行,而降维处理都会使用主成分分析方法来进行处理.去噪处理会分别用一阶导数、二阶导数和多元散射校正进行三次处理,并得出最终结果分析,确认哪一种去噪处理最适合用在对莜面和玉米淀粉定性的模型中.
下面显示了180份样本的原始光谱数据的光谱图,见图1.
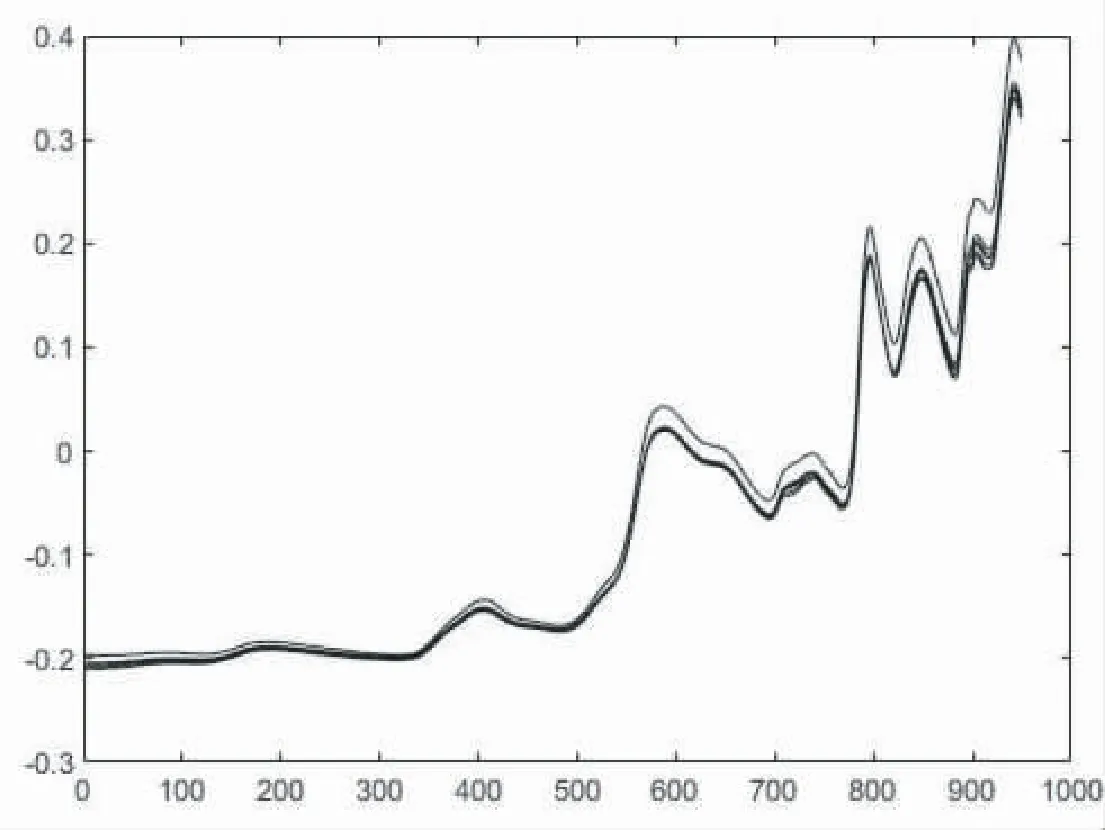
图1 原始光谱图
由图可以看出大体上光谱波长基本稳定,变化幅度不大,有一定偏移可能是因为仪器噪声问题.所以才需要用一阶导数、二阶导数和多元散射校正来处理原始光谱数据使光谱数据的结果受仪器的影响降低,使数据对本研究来说更加具有研究意义和可解释性,接下来将原始数据代入MATLAB程序中运行三种去噪处理并将图像画出,这里就不穷举三种去噪后的光谱数据图了,论文例举出一阶导数和二阶导数处理后的数据光谱图,来展示去噪效果,见图2和图3.
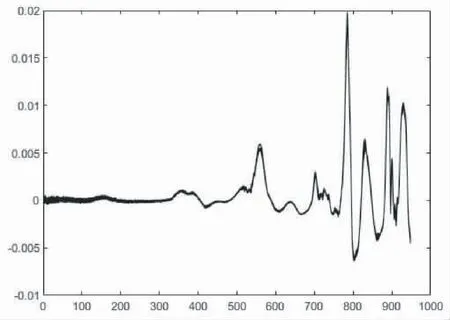
图2 一阶导数处理光谱图
可以看出经过一阶导数处理后的光谱数据图,光谱线条之间波动程度更小,显著降低了样本数据收集光谱时所受仪器的误差影响,这对后续的定性有很大的帮助.而根据实验结果来看二阶导数处理的结果与一阶导数有类似效果,降低了原始数据的噪声,使得数据更好进行分析,且数据整体趋近于0.
后将三种去噪方法处理后得到的数据再次进行主成分分析,并代入程序列出前几主成分分析结果的贡献率,为了统一形式,研究都取前三主成分作为用来决策树用来决策的属性.每种方法前三主成分贡献率和累计贡献率分别如下表,见表1.
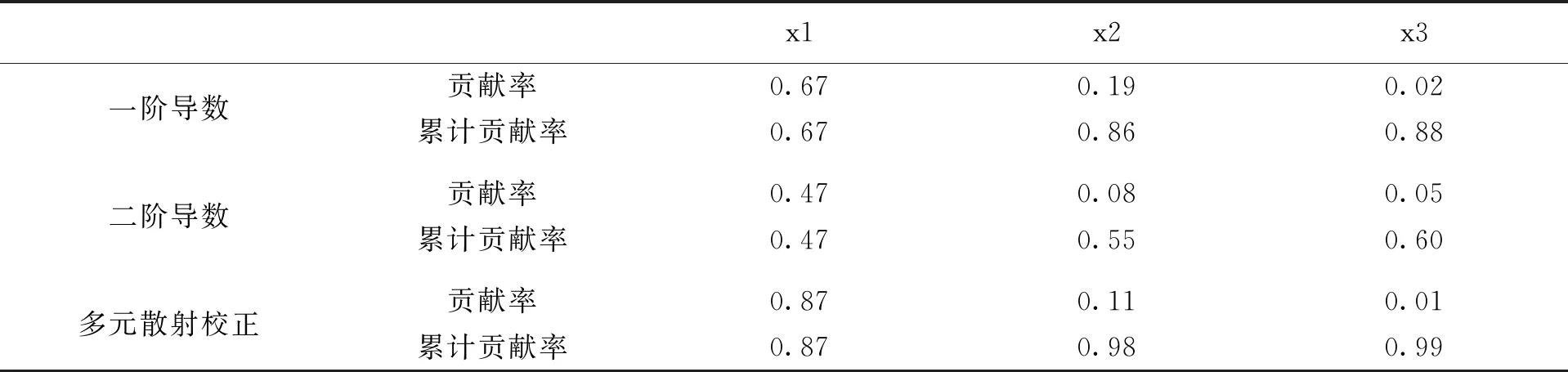
表1 三种不同去噪方法后PCA前三主成分贡献率及累计贡献率
可以从上述结果看出,一阶导数去噪后做主成分分析,贡献率最高的成分贡献率为67%,贡献率第二的主成分贡献率为19%,贡献率第三的主成分贡献率仅有2%,一阶导数前三主成分累积贡献率为88%,整体效果还算不错;二阶导数去噪后做主成分分析,贡献率最高的成分贡献率为47%,贡献率第二的主成分贡献率为8%,贡献率第三的主成分贡献率仅有5%,二阶导数前三主成分累积贡献率为60%,总得来说,效果很一般;多元散射校正去噪后做主成分分析,贡献率最高的成分贡献率为87%,贡献率第二的主成分贡献率为11%,贡献率第三的主成分贡献率仅有1%,多元散射校正处理后数据做主成分分析前三主成分累积贡献率为99%,整体来看,效果最佳.可以看出,二阶导数前三主成分代表样本数据效果最差,前三主成分的累计贡献率只有60%,而效果最好的是多元散射校正去噪后的数据,前三主成分的累计贡献率就可以到达99%,而不好也不差的一阶导数去噪后经过主成分分析方法处理后前三主成分累计贡献率可以达到88%,虽然不比二阶导数的效果好不少,但并不如多元散射校正后做主成分分析的效果.
根据主成分分析得到的前三主成分为决策属性,用提前划分好的训练集建立决策树进行训练.训练好后,将划分好的测试集代入决策树,得出测试集的预测结果并与测试集的实际属性进行比较.这里拿出一阶导数-主成分分析的前三主成分建立的决策树进行举例.
下图是一阶导数-主成分分析得到的前三主成分训练得到的决策树拓扑结构图,见图4.
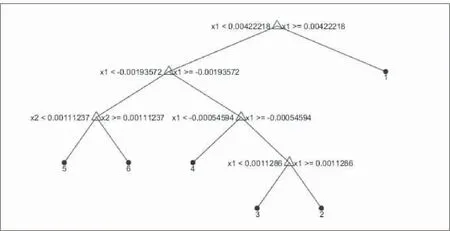
图4 决策树拓扑结构图
最终准确率accuracy=96.67%.可以看出用一阶导数-主成分分析法建立的决策树对于当前训练集来说,准确率较高,有很好的效果.而二阶导数-主成分分析组合的模型准确率相对低一点,只有95.00%,而多元散射校正-主成分分析组合的模型准确率同为96.67%.
5 结果与讨论
利用光谱仪采集了莜面与玉米淀粉混合样本的近红外光谱数据,使用一阶导数、二阶导数和多元散射校正三种方法对数据进行去噪处理,使用主成分分析方法进行降维处理,最后使用决策树方法建立定性模型.我们研究了三种光谱去噪方法对最终决策树定性准确性的影响,对比分析了最终准确率的高低.使用一阶导数-主成分分析-决策树组合准确率为96.67%,使用二阶导数-主成分分析-决策树组合准确率为95.00%,使用多元散射校正-主成分分析-决策树组合准确率为96.67%,研究表明在当前前提条件下,使用一阶导数和多元散射校正对原始光谱数据进行处理,建立的决策树准确率最高.但本身样本数量不大,不足够有极强的普遍性或存在一些研究未考虑到的误差影响因素,使得模型不能完全适用于所有情况.
