图注意力自编码器
2022-02-07谢成心侯冀超温秀梅
谢成心 侯冀超 陈 威 温秀梅,2*
(1.河北建筑工程学院,河北 张家口 075000;2.张家口市大数据技术创新中心,河北 张家口 075000)
0 引 言
在广泛的机器学习任务图中节点的低维向量表示中已被证明可用性.这些任务主要包括节点分类、推荐系统、社交网络以及链接预测等方面.因此,为了更好的学习节点特征表示,研究者们进行了大量研究.但是早期的大多数方法更多的只是利用图的结构特征却忽略了节点特征以及图中节点之间存在的关系,而实质上图中的节点都是具有很多的特征信息.现实生活中最常见是社交网络中的用户、论文的引用以及生物网络中的蛋白质分子等,都包含了很多特征信息.
为了利用图中的节点特征,研究者做出了大量的努力.最成功的方法是应用在图卷积网络以及图注意网络等方面,这些方法更依赖于标签信息[1],但是在现实生活中很多节点数据是不存在标签或者标签缺失的情况.
自编码器能够堆叠非线性层可以获得输入特征之间的复杂关系,因此在无监督学习中广泛应用[2].但传统的自编码器无法利用图结构数据中的存在关系.为了利用图结构数据中存在的关系,研究者们提出了不同的图自编码器.传统的图自编码器模型中的编码器虽然使用输入的图结构信息,但解码器却忽略了重构图的结构以及节点特征,不能很好的利用图数据.
注意机制是另一个成功的案例,它在许多机器学习任务中都非常重要尤其在深度学习等方面应用十分成功.目前最先进的注意机制是自我注意力机制以及多头注意力机制.本文利用图注意力自编码器通过堆叠自我注意机制的编码器或解码器层来重构输入的图结构以及节点嵌入表示.将原始的节点特征作为编码器的节点的嵌入表示,每层通过注意力机制获取邻居节点的特征来生成节点在下一层的嵌入表示.最后再通过解码器将编码器的过程反过来重构节点特征表示[3].现在注意力机制在深度学习以及图神经网络有着重要研究意义,利用注意力机制能够更好的学习其他高质量节点的特征,从而更好的实现节点的嵌入表示.
1 相关工作
1.1 自编码器
自编码器是无监督学习的一种典型模型,可分为三层.分别是:输入层、隐藏层以及解码器层.自编码器能够重构节点特征,可以更好地学习隐藏层的节点特征表示,并且加入了反向传播机制,不断优化参数能够使得目标值与输入值近似相等,使得损失值最小.CF-NADE自动编码器将节点随机排序,并将输入消息随机分为两组,但只保留一组[4].因此,在某些情况下,CF-NADE自动编码器可以看作是一种降噪的自动编码器.在每次迭代过程中,一些数据会在输入空间中随机丢失,从而降低模型过拟合的风险.日常生活中最常见的自动编码器包括降噪自动编码器、稀疏自动编码器、牵引自动编码器、栈桥自动编码器、变分自动编码器以及多层自动编码器等.
自编码器最先在深度学习领域使用,后研究者推广到图神经网络.自编码器实现节点特征的输入经过非线性变换重构节点特征,自编码器最本质的作用是利用非线性变换实现节点特征的降维.
1.2 图自编码器[13]
图自编码器(Graph Auto Encoder,GAE)能够实现链路预测任务.和自编码器类似,GAE能够将节点之间的邻接关系进行重构.GAE可分成编码器(Encoder)和解码器(Decoder).
(1)Encoder
本文采用图卷积网络(GCN)模型.GAE采用GCN作为编码器,获取节点的嵌入表示.在本文中,编码器使用用户项目的节点特征和邻接矩阵,并通过叠加生成节点的嵌入表示.具体定义如下公式(1)所示:
Z=GCN(X,A)
(1)
其中,Z代表所有结点的嵌入表示,X代表节点的特征矩阵,A代表邻接矩阵.利用GCN将X和A作为输入,得到输出Z.
GCN具体定义如下公式(2)所示:
(2)
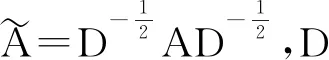
(2)Decoder
GAE利用内积表示节点之间的邻接关系来重构原始图,具体定义如下公式(3)所示:
(3)

1.3 图注意力自编码器
对于编码器Encoder而言,编码器将节点特征作为原始节点的特征表示,通过堆叠层利用图结构来生成节点的嵌入表示[5].基于注意力机制的图自编码器整体框架是采用了多个编码器层,主要原因是当我们使用更多的编码器层能够使得该模型层次更深,从而提高了学习能力.其次,利用图结构可以获得更好的节点嵌入表示[6].每个编码器层是根据节点的关联性聚合周围邻居节点的信息来生成节点的嵌入表示.原论文作者是基于Velickovic等人的工作的基础上,解决了如何求节点和邻居之间的注意力系数的问题,在同一层节点之间使用了基于共享参数的注意力机制[7].在第k个编码器层,节点j与节点i的关联性计算见公式(4)所示:
(4)
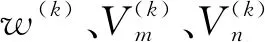
(5)
其中,Ni则是i节点本身以及周围所有邻居节点的集合.将节点本身特征视为初始节点的嵌入表示,则第k个编码器层生成第k层中节点i的表示,具体定义见公式(6)所示:
(6)
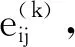
(7)
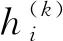
(8)
经过L个解码器层之后,最后一层的输出则是重构之后的节点的特征表示.
1.4 损失函数
图数据包括节点的属性特征以及图自身的结构信息,要保证重构之前节点的特征表示和重构之后的节点表示的损失值最低.但这只是其中一部分损失,图数据中还存在图结构损失.虽然节点之间可能并不存在边但可能存在类似的图结构,故而图中的另一部分损失利用图结构表示节点的相似性.综合以上两方面,最终的损失函数具体可见公式(9)所示:
(9)
2 实验结果与分析
2.1 实验数据集
基于注意力机制的图自编码器使用的是Cora数据集,该数据集是图神经网络模型较为经典的数据集.Cora数据集共有七大类机器学习相关的论文构成包括基于案例、遗传算法、神经网络、概率方法、强化学习、规则学习以及理论等方面论文构成.并且所有论文都是被其他论文引用过至少一次.该数据集中的所有论文均是由0和1的词向量构成,表示相应的词是否存在还是缺失.该词典所有论文均是由1433个特征构成,且所有特征只是用0和1来表示.
其中,ind.cora.x文件表示训练集节点的特征表示,ind.cora.tx文件表示测试集节点的特征表示,ind.cora.allx文件表示所有节点的特征表示,ind.cora.y文件表示训练集节点的标签,ind.cora.ty文件表示测试集节点的标签,ind.cora.ally文件表示所有节点的标签,ind.cora.graph文件表示图中边的信息以及ind.cora.test.inde文件表示测试集节点的索引信息.
2.2 实验结果及分析
下表是基于归纳式学习各个经典模型在Cora数据集上的分类准确度详情.其中X表示节点的特征,A表示邻接矩阵,Y表示标签.从各个模型的对比结果可以看出加入了注意力机制的图自编码器的分类准确度效果较好,准确度可达82.5%.本文在原有的基于注意力机制的自编码器的基础上优化参数本文用GATE+OP表示,将其中的Sigmoid激活函数替换为Relu激活函数实验结果表明是可行的,在原有的分类准确度的基础上优化了0.9%,准确度可达83.4%.目前在大多数图表示学习的模型中,优化之后的分类准确度能够达到较高的水平.
在图神经网络当前的几个经典模型中,通过对比加入了注意力机制的图自编码器获得更好的实验效果.本文是基于归纳式学习的模型,训练了100次使用了1000个节点用于测试,同时额外使用了500个节点作为验证集,更好的衡量了模型的性能.通过对比其他模型我们能看到GATE+OP模型在Cora数据集的分类准确度最高,而GraphSAGE-LSTM模型的分类准确度最低.具体的模型对比结果可见下表1所示.
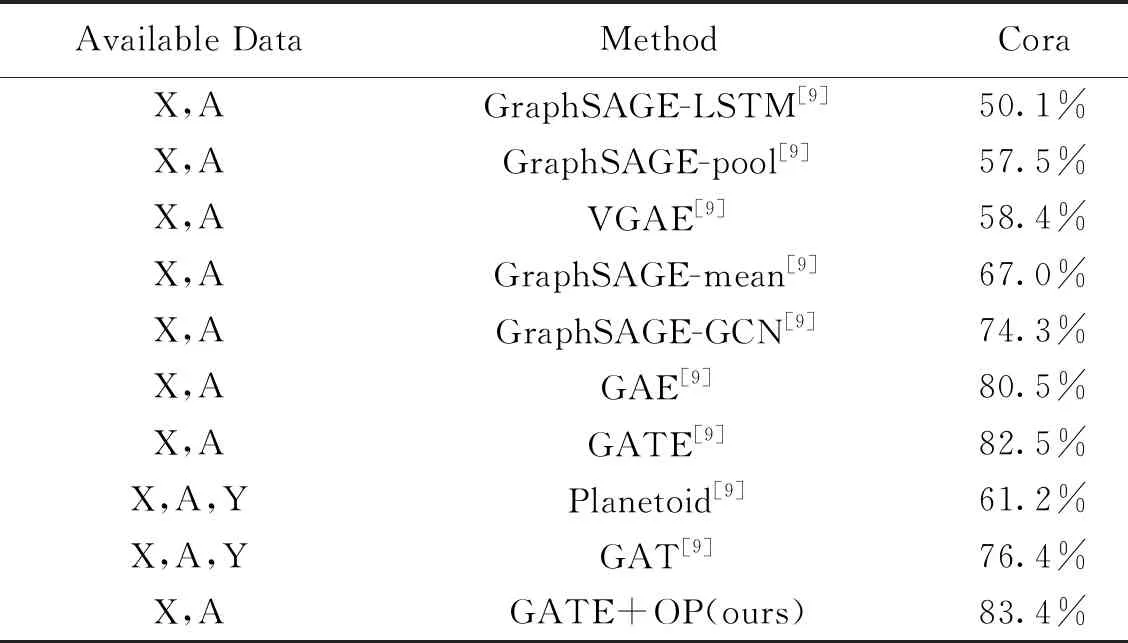
表1 基于Cora数据集的模型对比结果
3 结 语
图神经网络是当下又一个“后起之秀”,已经越来越受到学者们的关注.图自编码器作为图神经网络的一个子领域同样是研究的重点,图自编码器在社交网络、推荐系统以及图聚类等方面都存在应用.但图自编码器忽略重构之后的图的结构特征以及图的节点属性,为解决图自编码器存在的问题Amin Salehi等人加入了注意力机制,从而更好的利用图数据获取节点的嵌入表示.
本文通过优化相关的参数替换了损失函数里的激活函数,实验证明优化后获得了更好的分类效果,在原始模型的基础上分类效果提高了0.9%.图神经网络在社交网络、分子结构以及交通预测都有着广泛的应用.加入了注意力机制的图自编码器未来可在社交网络以及聚类方面考虑相关的应用.读者也可考虑将注意力机制加入图变分自编码器中或其他编码器,使得模型获取更好的性能.
